Автор: Денис Аветисян
Новое исследование представляет WebSeek — расширение для браузера, которое объединяет возможности человека и искусственного интеллекта для более эффективного анализа данных.
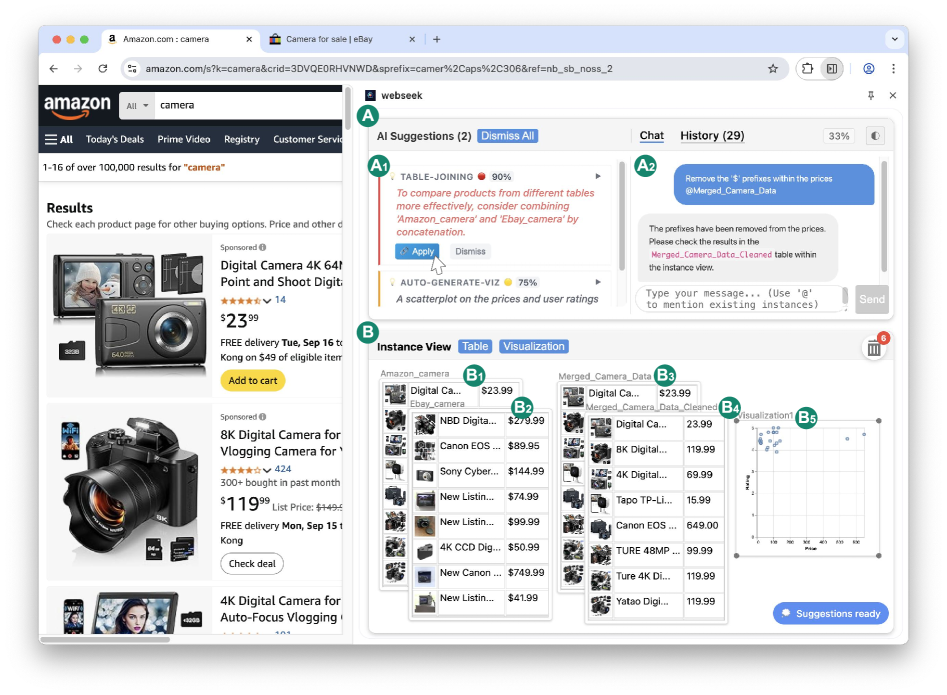
WebSeek предоставляет пользователям интерфейс для непосредственной работы с данными и получения интеллектуальной поддержки в процессе принятия решений.
Несмотря на растущую популярность веб-агентов, таких как ChatGPT Agent и GenSpark, они по-прежнему ограничены текстовым вводом и не поддерживают проактивное понимание намерений пользователя или интерактивный анализ данных. В статье ‘Facilitating Proactive and Reactive Guidance for Decision Making on the Web: A Design Probe with WebSeek’ представлено расширение для браузера WebSeek, обеспечивающее совместный анализ данных человеком и искусственным интеллектом посредством манипулирования данными и получения интеллектуальной поддержки. Проведенное исследование с \mathcal{N}=15 участниками выявило разнообразные стратегии анализа и подчеркнуло потребность в прозрачности и контроле при взаимодействии с ИИ. Какие новые возможности открывает подобный смешанный подход для принятия обоснованных решений в веб-среде?
От информационного хаоса к ясности: вызовы современного мира
Современный интернет представляет собой бескрайний океан информации, и пользователи всё чаще сталкиваются с проблемой информационного перегруза. Огромный объем данных, доступный в сети, парадоксальным образом затрудняет принятие взвешенных решений. Постоянный поток новостей, статей, социальных публикаций и прочих материалов создает когнитивную перегрузку, приводя к усталости и снижению способности к анализу. В результате, даже при наличии необходимой информации, люди испытывают трудности в ее обработке и выделении действительно значимых фактов, что негативно сказывается на эффективности работы и качестве принимаемых решений. Стремление к получению полной картины часто оборачивается рассеянностью и неспособностью сконцентрироваться на приоритетных задачах.
Традиционные методы анализа данных зачастую требуют значительных усилий и глубокой экспертизы, что создает серьезный барьер для широкого круга пользователей. Для проведения полноценного анализа необходимо владение статистическими методами, умение работать со сложными программными пакетами и навыки интерпретации результатов. Это предъявляет высокие требования к квалификации специалистов и делает процесс извлечения ценной информации из данных трудоемким и дорогостоящим. В результате, многие организации и частные лица сталкиваются с трудностями при попытке самостоятельно анализировать данные, что ограничивает их возможности для принятия обоснованных решений и использования потенциала информации, доступной в сети.
В условиях экспоненциального роста объемов информации, доступной в сети, потребность в оптимизированном процессе преобразования необработанных веб-данных в практически применимые сведения становится первостепенной задачей. Существующие методы анализа часто требуют значительных усилий и специализированных знаний, что затрудняет извлечение полезной информации для широкого круга пользователей. Эффективный, автоматизированный подход к анализу веб-источников позволяет не только сократить время, необходимое для получения ценных сведений, но и значительно расширить возможности принятия обоснованных решений в различных сферах деятельности — от бизнеса и науки до государственного управления и повседневной жизни. Разработка подобных систем, способных быстро и точно извлекать, обрабатывать и представлять информацию, является ключевым фактором для успешной адаптации к современной информационной среде.
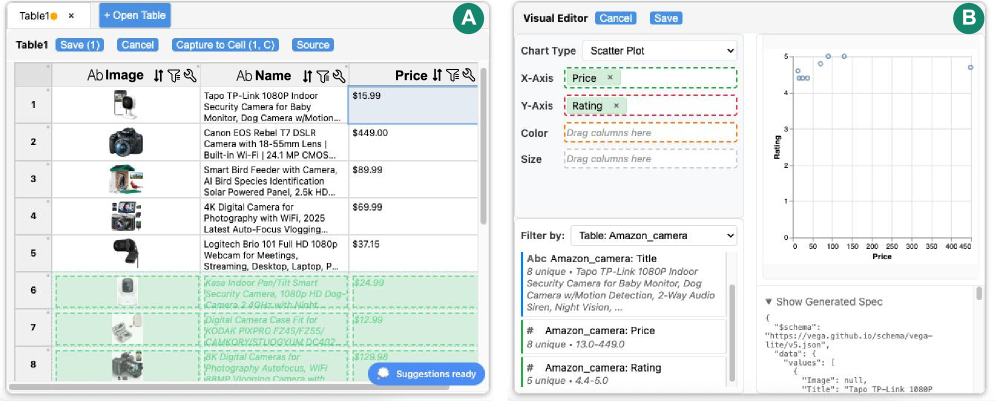
WebSeek: Инструмент прямого манипулирования данными и интеллектуальной поддержки
WebSeek — это расширение для веб-браузеров, разработанное для принятия решений на основе данных и использующее принцип непосредственного манипулирования информацией. В отличие от традиционных интерфейсов, требующих последовательного выполнения команд, WebSeek позволяет пользователям напрямую организовывать и взаимодействовать с данными, визуально представляя их и упрощая процесс анализа. Это достигается путем предоставления возможности перемещать, связывать и фильтровать данные непосредственно в интерфейсе расширения, что способствует более интуитивному и эффективному исследованию и принятию обоснованных решений.
В основе WebSeek лежит интерфейс Canvas, представляющий собой интерактивное рабочее пространство для организации и непосредственного взаимодействия с элементами данных. Пользователи могут произвольно размещать и компоновать различные артефакты данных — такие как таблицы, графики, текстовые фрагменты и результаты запросов — на Canvas, создавая визуальную репрезентацию своей аналитической работы. В отличие от традиционных интерфейсов, где данные обычно представлены в виде структурированных списков или отчетов, Canvas обеспечивает гибкость в организации информации и позволяет пользователям устанавливать прямые связи между различными элементами данных посредством визуальных манипуляций, что способствует более интуитивному и эффективному анализу.
Интегрированный помощник на основе большой языковой модели (LLM) в WebSeek предоставляет поддержку пользователей в процессе анализа данных как в проактивном, так и в реактивном режимах. Проактивная поддержка включает в себя предоставление контекстных подсказок и предложений на основе текущего состояния Canvas Interface и типа анализируемых данных. Реактивная поддержка активируется запросами пользователя, выраженными в естественном языке, позволяя задавать вопросы о данных, получать разъяснения по поводу действий и получать помощь в выполнении сложных операций. LLM обрабатывает запросы, используя контекст текущего анализа и доступные данные, предоставляя релевантные ответы и рекомендации, что повышает эффективность и скорость принятия решений.
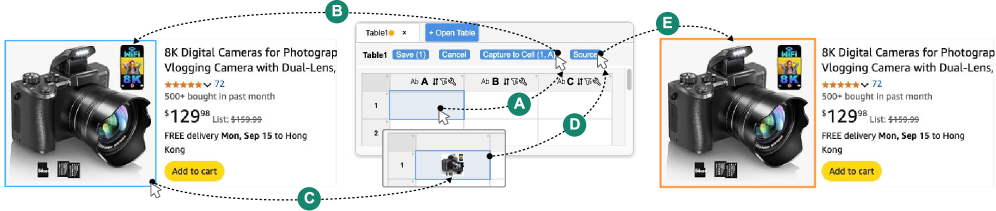
Как работает WebSeek: Извлечение, анализ и визуализация данных
WebSeek использует технологии извлечения данных (Data Extraction) для автоматизированного сбора информации со страниц веб-сайтов. Этот процесс включает в себя идентификацию и извлечение структурированных и неструктурированных данных, таких как текст, таблицы и изображения. Для обеспечения точности и надежности результатов, система WebSeek обрабатывает типичные проблемы качества данных, включая неполные данные, дубликаты, несоответствия форматов и ошибки ввода. Механизмы очистки и нормализации данных позволяют WebSeek предоставлять пользователям достоверную и полезную информацию, извлеченную из различных источников в сети.
Ассистент на базе больших языковых моделей (LLM) в WebSeek использует технологию LLM-промптинга для интерпретации действий пользователя и предоставления персонализированных рекомендаций. Это достигается путем преобразования действий пользователя — таких как запросы, выделение данных или навигация по интерфейсу — в структурированные запросы (промпты) для LLM. LLM обрабатывает эти промпты, анализируя контекст и намерения пользователя, и генерирует соответствующие ответы или предлагает дальнейшие шаги. Используемые промпты оптимизированы для конкретных задач WebSeek, обеспечивая релевантность и точность предоставляемой помощи, что позволяет пользователям эффективно взаимодействовать с извлеченными данными и визуализациями.
Основным способом взаимодействия с WebSeek являются данные в виде артефактов — таблиц и визуализаций, созданных посредством инструментов визуализации данных. Вместо традиционных текстовых интерфейсов, пользователи оперируют структурированными данными, представленными в наглядной форме. Это позволяет не только эффективно анализировать информацию, извлеченную из веб-страниц, но и упрощает процесс исследования и поиска закономерностей. Таблицы служат для организации и фильтрации данных, а визуализации — для быстрого выявления трендов и аномалий, что значительно повышает продуктивность работы с большими объемами информации.
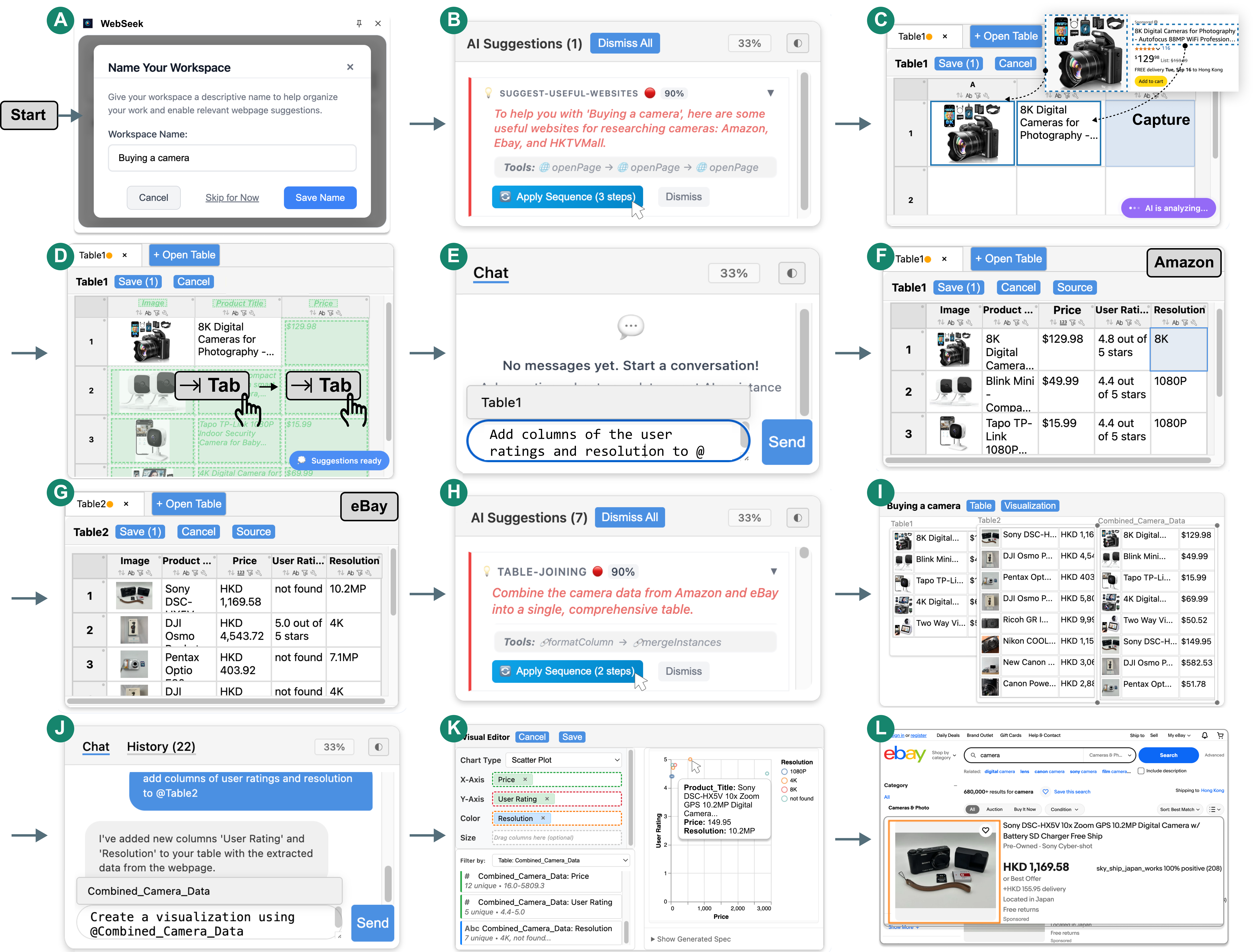
Гарантия доверия и прозрачности: Отслеживание происхождения данных
WebSeek не ограничивается простой демонстрацией данных, внедряя поддержку отслеживания происхождения данных (Data Provenance). Эта функция позволяет проследить весь путь информации — от первоначального источника и этапов обработки до текущего состояния. Система фиксирует все преобразования, которым подвергались данные, включая алгоритмы, параметры и ответственных лиц. Такой подход обеспечивает полную прозрачность и позволяет пользователям не только видеть результат, но и понимать, как он был получен, что критически важно для оценки достоверности и принятия обоснованных решений на основе данных.
Каждый экземпляр данных, входящий в состав цифрового артефакта, неразрывно связан со своим источником происхождения. Эта взаимосвязь позволяет пользователям не только удостовериться в точности представленной информации, но и проследить весь путь ее трансформации — от момента сбора до текущего состояния. Подобный подход обеспечивает полную прозрачность и возможность верификации данных, что крайне важно для принятия обоснованных решений и формирования доверия к системе. Благодаря отслеживанию происхождения каждого элемента данных, пользователи могут оценить его надежность и убедиться в отсутствии несанкционированных изменений или искажений.
Приверженность прозрачности данных является ключевым фактором для формирования доверия пользователей. В условиях всеобщего доступа к информации, возможность отследить происхождение и все изменения, внесенные в конкретные данные, позволяет оценить их достоверность и надежность. Такое отслеживание не просто демонстрирует ответственность разработчиков, но и позволяет пользователям самостоятельно принимать обоснованные решения, опираясь на проверенную информацию. Уверенность в происхождении данных способствует более эффективному анализу, снижает риски, связанные с неверными интерпретациями, и, в конечном итоге, повышает ценность предоставляемой информации для каждого пользователя.
Будущее исследования данных: Ориентированный на пользователя искусственный интеллект
В основе разработки WebSeek лежит концепция пользовательского искусственного интеллекта, ставящая во главу угла контроль, прозрачность и самостоятельность пользователя. В отличие от традиционных систем, где алгоритмы зачастую действуют как «черный ящик», WebSeek стремится предоставить пользователю полное понимание логики работы и возможность влиять на процесс исследования данных. Это достигается за счет интуитивно понятного интерфейса, позволяющего легко отслеживать этапы анализа, а также механизмов, дающих возможность корректировать параметры и направлять систему в соответствии с индивидуальными потребностями. Подобный подход не только повышает эффективность работы с информацией, но и способствует формированию доверия к инструменту, поскольку пользователь ощущает себя не пассивным наблюдателем, а активным участником процесса познания.
Исследование продемонстрировало высокий показатель удобства использования системы, оцениваемый по шкале System Usability Scale (SUS) в 73.11 из 100. Данный результат свидетельствует о том, что система интуитивно понятна и эффективна для пользователей, обеспечивая комфортный опыт взаимодействия. Высокий SUS-балл указывает на то, что пользователи способны легко освоить функциональность системы и успешно выполнять поставленные задачи, что является важным фактором для широкого внедрения и принятия технологии. Этот показатель подтверждает, что разработанный подход к пользовательскому интерфейсу и взаимодействию оказался удачным и отвечает потребностям целевой аудитории.
В ходе исследования было установлено, что среднее время выполнения первого задания пользователями составило 14.60 минут, а второго — 12.65 минут. Эти показатели зафиксированы как базовый уровень производительности, позволяющий оценить эффективность разработанного инструментария для анализа данных. Полученные результаты служат отправной точкой для дальнейшей оптимизации интерфейса и алгоритмов, направленной на сокращение времени, необходимого для достижения поставленных задач, и повышения удобства работы с большими объемами информации. Сравнение с будущими итерациями разработки позволит оценить прогресс в улучшении пользовательского опыта и общей эффективности системы.
Исследование выявило, что подавляющее большинство — 82,8% — пользовательских сессий активно использовали встроенные подсказки (in-situ guidance). Данный факт подчеркивает высокую востребованность данной функции, предоставляющей помощь непосредственно в контексте решаемой задачи. В то же время, периферийные подсказки (peripheral guidance), предлагающие информацию вне основного рабочего пространства, использовались значительно реже — лишь в 13,8% сессий. Такое распределение указывает на предпочтение пользователей получать помощь непосредственно в процессе работы, а не отвлекаться на внешние источники информации, что свидетельствует об эффективной реализации принципов удобства использования в разработанной системе.
Исследование, представленное в статье, стремится к упрощению взаимодействия человека и искусственного интеллекта при анализе данных. Авторы предлагают WebSeek — расширение для браузера, позволяющее пользователю непосредственно манипулировать данными и получать интеллектуальную поддержку. Этот подход, направленный на создание прозрачного и интуитивно понятного интерфейса, находит отклик в словах Клода Шеннона: «Информация — это не количество, а выбор». WebSeek как раз и предоставляет пользователю возможность выбора, предлагая конкретные экземпляры данных для анализа и позволяя отсечь лишнюю сложность, фокусируясь на существенном. Очевидно, что подобный дизайн способствует более эффективному принятию решений, ведь ясность представления данных — залог успеха.
Что дальше?
Представленная работа, стремясь к ясности в сложном взаимодействии человека и искусственного интеллекта, обнажает не столько ответы, сколько глубину нерешенных вопросов. Вместо добавления новых слоев сложности, необходимо сосредоточиться на радикальном упрощении. Интерфейс, манипулирующий “осязаемыми” данными, — это шаг, но вопрос о том, как именно эта осязаемость влияет на когнитивные процессы и принятие решений, остается открытым. Полагаться на иллюзию контроля, даже если он подкреплен искусственным интеллектом, — рискованная затея.
Будущие исследования должны сместить акцент с проактивной “помощи” на создание систем, способных признавать собственную некомпетентность. Искусственный интеллект, осознающий границы своих возможностей, может предложить не готовые решения, а инструменты для более осознанного анализа данных пользователем. Истинная ценность не в предсказании, а в предоставлении возможности самому прийти к выводу, освобожденному от предвзятости алгоритмов.
В конечном счете, успех подобных систем будет определяться не их технической сложностью, а способностью исчезнуть из поля зрения пользователя, оставив лишь чистоту мысли и ясность понимания. Стремление к совершенству — это не добавление функций, а их безжалостное удаление, пока не останется лишь самое необходимое.
Оригинал статьи: https://arxiv.org/pdf/2601.15100.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-01-22 22:49