Автор: Денис Аветисян
Представлен комплексный инструмент для проверки способности ИИ-агентов проводить глубокий анализ информации из различных источников и формировать достоверные отчеты.
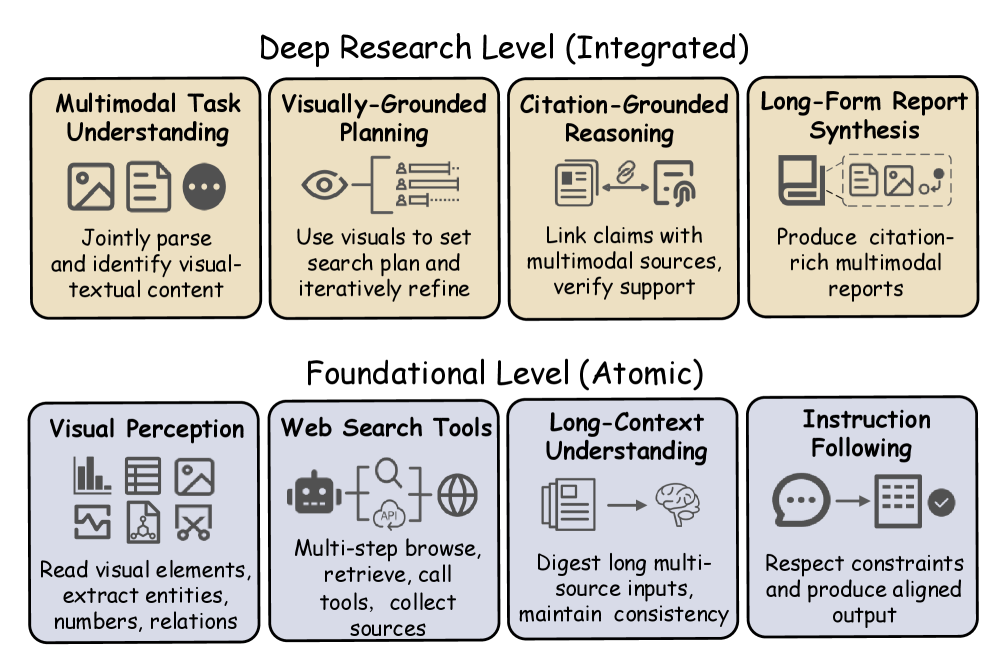
MMDeepResearch-Bench — это новый эталон для оценки мультимодальных ИИ-агентов, способных проводить исследования с акцентом на точность и полноту информации.
Несмотря на успехи в области генерации текстов, современные системы глубокого обучения часто испытывают трудности с комплексным анализом и синтезом информации из разнородных источников. В данной работе представлена новая платформа ‘MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents’, предназначенная для оценки возможностей ИИ-агентов в области мультимодальных исследований, с акцентом на проверку достоверности и соответствия сгенерированных отчетов исходным данным. Предложенный бенчмарк и методология оценки, включающая метрики для анализа качества синтеза, точности цитирования и целостности мультимодальной информации, выявляют существенные ограничения существующих моделей в обеспечении надежности и непротиворечивости генерируемых отчетов. Возможно ли создать ИИ-агента, способного к глубокому мультимодальному анализу и генерации научных отчетов, сопоставимых по качеству и достоверности с работой эксперта-человека?
От эволюции статических моделей к агентным системам
Традиционные большие языковые модели (БЯМ) часто демонстрируют ограниченные возможности при решении задач, требующих многоступенчатого рассуждения и доступа к внешним источникам информации. В отличие от способности генерировать текст, имитировать стиль или отвечать на вопросы, основанные на заложенных знаниях, БЯМ испытывают трудности, когда требуется не просто вспомнить информацию, а синтезировать ее из различных источников, устанавливать причинно-следственные связи и планировать последовательность действий для достижения конкретной цели. Эта проблема особенно заметна в сложных сценариях, где требуется не только понимание языка, но и способность к логическому выводу, критическому анализу и адаптации к новым данным, что ограничивает их применение в областях, требующих глубокого понимания и решения проблем.
Появление агентных систем знаменует собой принципиальный сдвиг в подходах к решению сложных задач. В отличие от традиционных языковых моделей, функционирующих как статичные инструменты, агентные системы способны к оркестровке процессов — самостоятельному поиску необходимой информации и её синтезу для достижения поставленной цели. Эта способность к динамической адаптации и использованию внешних знаний позволяет им эффективно справляться с многоступенчатыми заданиями, требующими не просто генерации текста, а полноценного исследования и анализа. Вместо пассивного ответа на запрос, такие системы активно взаимодействуют с окружающей средой, извлекая релевантную информацию из различных источников и объединяя её для получения наиболее полного и точного результата, что значительно расширяет спектр решаемых задач и повышает качество выполняемой работы.
Современные агентные системы в значительной степени полагаются на мощные большие мультимодальные модели (LMM), способные обрабатывать разнообразные потоки информации и осуществлять сложные рассуждения. В отличие от традиционных языковых моделей, ограничивающихся текстом, LMM способны интегрировать данные из различных источников, включая изображения, аудио и видео, что позволяет им более глубоко понимать контекст и находить решения сложных задач. Эти модели не просто анализируют информацию, но и способны к синтезу новых знаний, объединяя разрозненные данные для формирования целостной картины. Благодаря этой способности, агентные системы могут эффективно решать задачи, требующие не только обработки информации, но и креативного подхода к решению проблем и адаптации к меняющимся условиям.
Для адекватной оценки возможностей агентов, способных к глубокому исследованию и решению сложных задач, необходимы специализированные критерии и эталоны. В связи с этим был разработан MMDR-Bench — комплексный набор из 140 задач, предназначенный для строгой оценки многомодальных агентов, выполняющих длительные исследовательские операции. Этот эталон позволяет проверить способность агентов не просто обрабатывать информацию, но и самостоятельно планировать исследования, собирать данные из различных источников, анализировать их и синтезировать новые знания. MMDR-Bench представляет собой важный шаг в развитии искусственного интеллекта, позволяющий более точно измерять прогресс в создании интеллектуальных систем, способных к автономному обучению и решению реальных задач.
Объективная оценка агентов глубоких исследований: специализированные бенчмарки
Для обеспечения объективности и снижения влияния изменений в веб-среде (web drift) на результаты оценки агентов глубоких исследований (Deep Research Agents, DRA), критически важны специализированные бенчмарки, такие как BrowseComp. Веб-среда постоянно меняется, что может приводить к искажению результатов оценки, если они не учитывают эти изменения. Использование стандартизированных бенчмарков, включающих разнообразные и регулярно обновляемые веб-задачи, позволяет минимизировать влияние этих факторов и обеспечить более надежную и сопоставимую оценку различных DRA. Бенчмарки, такие как BrowseComp, позволяют отслеживать прогресс в развитии DRA, обеспечивая возможность сравнения их производительности в условиях, приближенных к реальным.
BrowseComp-Plus представляет собой расширение существующего набора данных для оценки агентов глубокого поиска (Deep Research Agents, DRA), фокусируясь на задачах поиска информации в веб-масштабе с использованием визуальных данных. В отличие от предыдущих бенчмарков, BrowseComp-Plus требует от агентов не только извлечение текста из веб-страниц, но и обработку визуальной информации, представленной на этих страницах, для решения поставленных задач. Это включает в себя понимание графиков, диаграмм и других визуальных элементов, что значительно усложняет процесс поиска и анализа информации и позволяет более полно оценить возможности DRA в реальных сценариях работы с веб-контентом. Бенчмарк включает в себя задачи, требующие от агентов интеграции визуальной и текстовой информации для получения ответа, что делает его более сложным и реалистичным по сравнению с традиционными текстовыми бенчмарками.
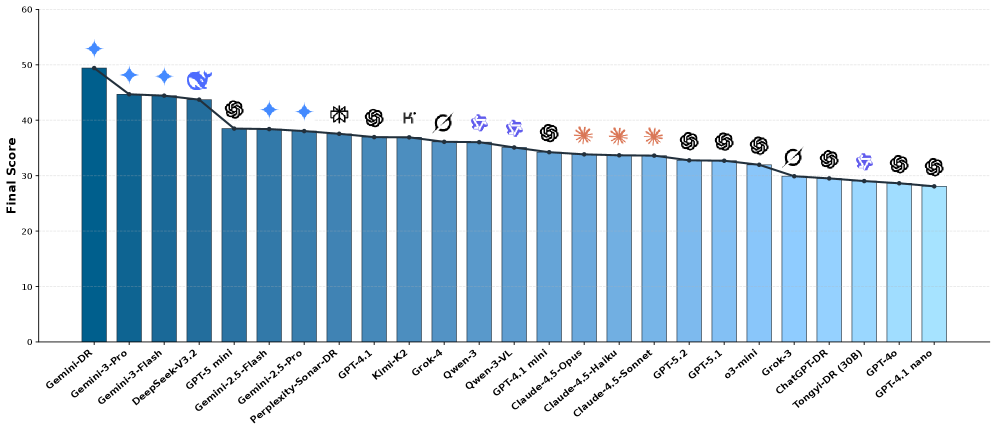
MMDR-Bench представляет собой комплексный бенчмарк, состоящий из 140 задач, разработанный для строгой оценки возможностей агентов глубоких исследований (DRAs) в мультимодальных условиях. На данный момент с использованием этого бенчмарка были протестированы 25 передовых больших языковых моделей (LLM) и агентов. Бенчмарк охватывает широкий спектр задач, требующих обработки и интеграции информации из различных источников, включая текст и изображения, для решения сложных исследовательских вопросов. Результаты оценки, полученные с помощью MMDR-Bench, позволяют объективно сравнить производительность различных моделей и агентов в мультимодальной среде, выявляя их сильные и слабые стороны.
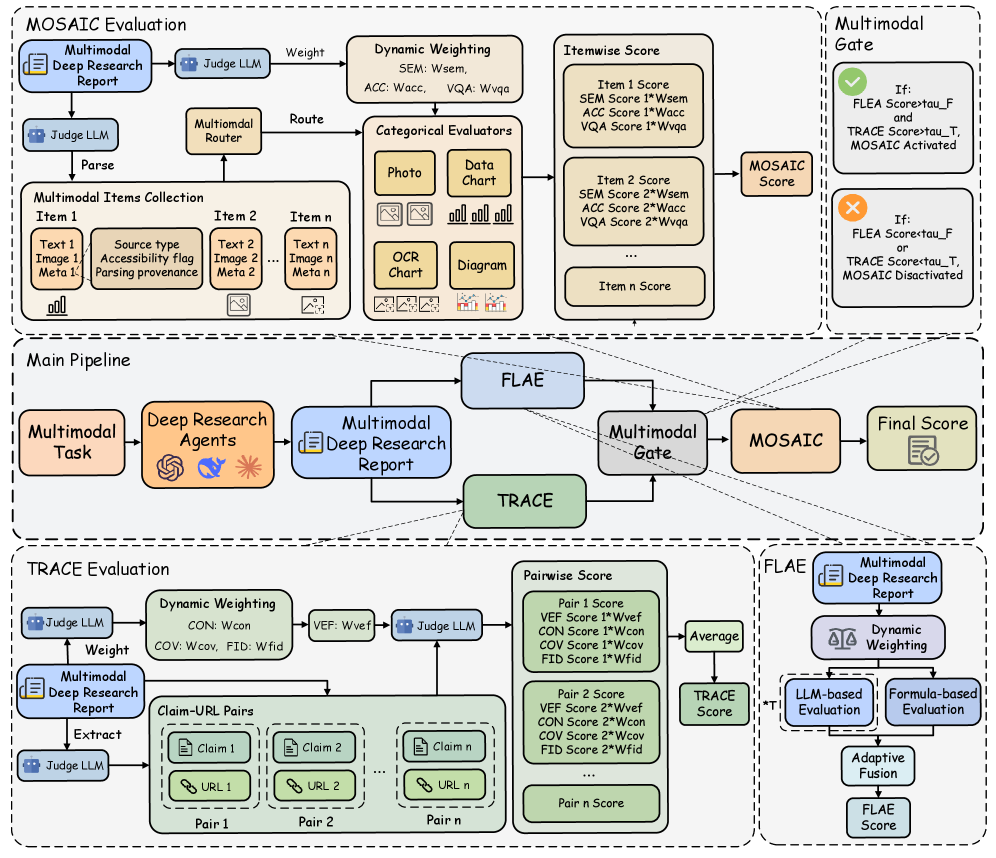
Для поддержки комплексной оценки, MMSearch оценивает способность мультимодальных языковых моделей (LMM) к визуальной переранжировке и логическому выводу на основе изображений. В рамках оценочного конвейера MMDR-Bench, различные аспекты работы агентов получают различный вес: качество отчета (FLAE) оценивается в 20%, обоснованность доказательств (TRACE) — в 50%, а качество привязки к изображениям (MOSAIC) — в 30%. Данное распределение весов отражает приоритетность оценки способности агента предоставлять аргументированные, основанные на доказательствах отчеты, корректно интерпретирующие визуальную информацию.
Совершенствование поиска: передовые методологии
Ранние агентские системы поиска, такие как Search-R1, заложили основу для современных методов, разбивая сложные запросы на последовательность подзадач посредством логического вывода, известного как “chain-of-thought” (цепочка рассуждений). Этот подход позволяет агенту структурировать процесс поиска, последовательно уточняя запрос и оценивая результаты каждой подзадачи перед переходом к следующей. Вместо обработки запроса как единого целого, система анализирует его компоненты, определяет необходимые шаги для получения информации и выполняет их в логической последовательности, что повышает эффективность и точность поиска.
DeepDive, развиваясь на основе существующих агентных поисковых систем, использует обучение с подкреплением для улучшения траекторий поиска и оптимизации процессов уточнения запросов. В отличие от статических подходов, DeepDive динамически адаптирует стратегию поиска на основе получаемой обратной связи, максимизируя вероятность успешного нахождения релевантной информации. Обучение с подкреплением позволяет агенту изучать оптимальные последовательности действий по модификации поискового запроса, учитывая результаты предыдущих итераций и повышая эффективность поиска за счет минимизации количества необходимых шагов и повышения точности полученных данных.
Методы, такие как DeepDive и Search-R1, напрямую повышают эффективность агентов поискового типа (DRAs) за счет оптимизации процесса извлечения информации. Вместо последовательного перебора результатов, эти системы используют декомпозицию запросов и обучение с подкреплением для определения наиболее релевантных направлений поиска. Это позволяет агентам фокусироваться на наиболее перспективных источниках, сокращая время и вычислительные ресурсы, затрачиваемые на поиск, и одновременно увеличивая точность получаемых результатов. Оптимизация траекторий поиска и уточнение запросов, основанные на анализе промежуточных результатов, позволяют DRAs находить информацию, которая была бы упущена при использовании традиционных методов.
Оптимизация процесса поиска, достигаемая за счет применения продвинутых методологий, позволяет агентам решать более сложные задачи и повышать точность результатов. Улучшение траекторий поиска и стратегий уточнения запросов снижает потребность в ручном вмешательстве и повышает эффективность извлечения информации. Это особенно важно при работе с многоступенчатыми задачами, требующими последовательного анализа и синтеза данных из различных источников. В результате, агенты способны успешно выполнять задачи, которые ранее были недостижимы из-за вычислительных ограничений или сложности запросов.
Представленный бенчмарк MMDR-Bench демонстрирует стремление к созданию не просто функциональных, но и элегантных систем искусственного интеллекта. Оценка способности агентов к глубокому мультимодальному исследованию, с акцентом на точность и качество отчетов, подчеркивает важность гармонии между формой и содержанием. Как отметил Эндрю Ын: «Мы находимся в моменте, когда машинное обучение начинает приносить пользу людям». Этот принцип находит отражение в подходе к разработке MMDR-Bench, где ключевым является не просто достижение результата, но и обеспечение его достоверности и понятности. Стремление к элегантности в дизайне систем машинного обучения — это признак глубокого понимания, а не просто опция.
Куда же дальше?
Представленный бенчмарк, MMDR-Bench, несомненно, является шагом вперед в оценке многомодальных агентов, стремящихся к глубокому исследованию. Однако, элегантность решения не должна заслонять остающиеся вопросы. Оценка «верности доказательствам» — задача, требующая не просто сопоставления текста, но и понимания нюансов контекста, что остается сложной задачей даже для человека. Стремление к количественной оценке часто упускает из виду качественные аспекты — истинно ли агенты «понимают» информацию, или лишь искусно манипулируют ею?
В будущем, необходимо уделить внимание созданию более сложных и реалистичных сценариев исследования, приближенных к тем, с которыми сталкиваются ученые в реальном мире. Простота оценки, конечно, привлекательна, но она не должна становиться самоцелью. Важно выйти за рамки оценки лишь «релевантности» и перейти к оценке истинной глубины анализа и способности к синтезу новой информации. Иначе, мы рискуем создать системы, которые лишь имитируют интеллект, но не обладают им.
И, наконец, не стоит забывать о том, что оценка — это лишь инструмент. По-настоящему ценным является не сам бенчмарк, а те улучшения, которые он стимулирует в области многомодального искусственного интеллекта. Пусть это будет не просто гонка за цифрами, а стремление к созданию систем, способных к настоящему интеллектуальному труду.
Оригинал статьи: https://arxiv.org/pdf/2601.12346.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-01-23 03:45