Автор: Денис Аветисян
В статье представлен обзор текущего состояния оценки больших языковых моделей в юридической сфере и обозначены ключевые вызовы для их внедрения.
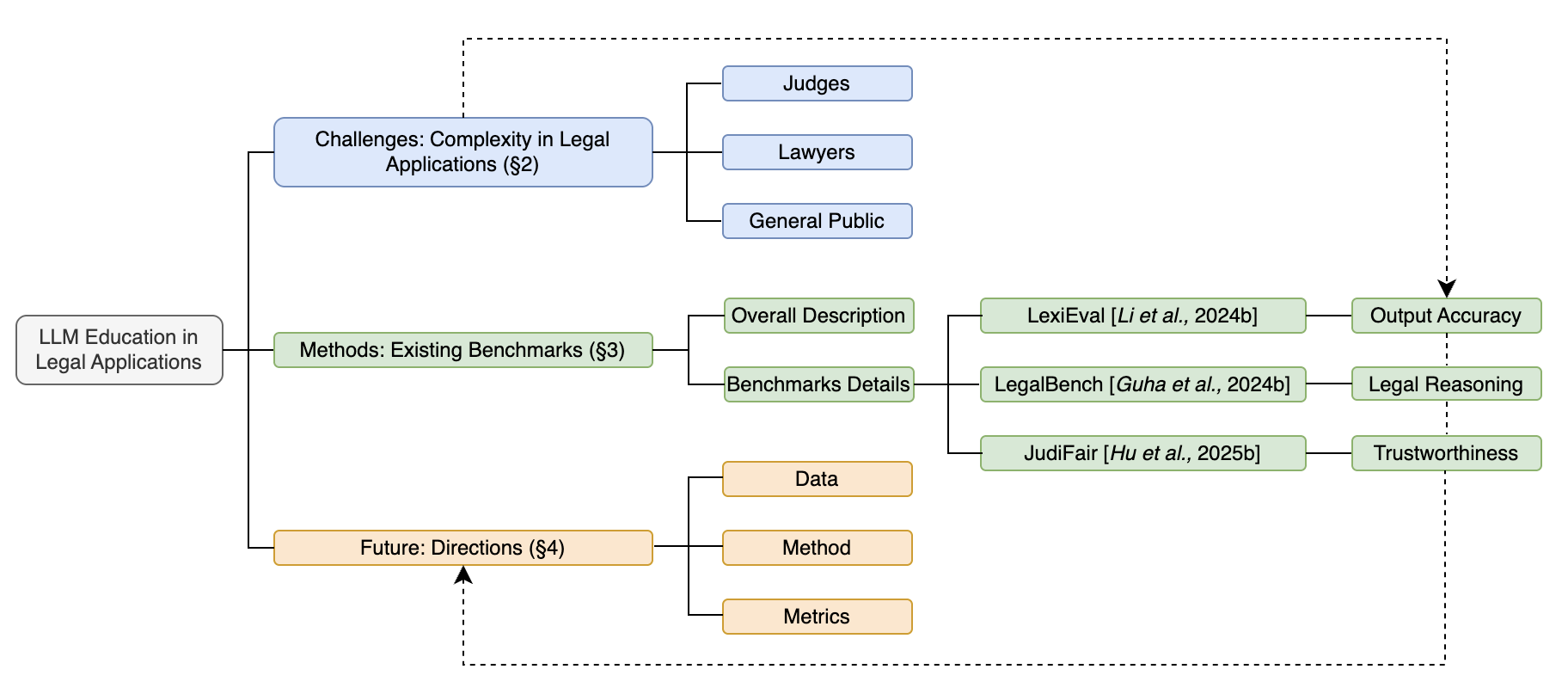
Анализ методов оценки точности, обоснованности, справедливости и безопасности больших языковых моделей в контексте применения в правовой отрасли.
Несмотря на впечатляющий прогресс в области искусственного интеллекта, применение больших языковых моделей (LLM) в юридической сфере сталкивается с серьезными вызовами, выходящими за рамки простой точности. Данная работа, озаглавленная ‘Evaluation of Large Language Models in Legal Applications: Challenges, Methods, and Future Directions’, представляет собой обзор текущего состояния оценки LLM в контексте юридических задач, выявляя ключевые проблемы, связанные с надежностью рассуждений, справедливостью и достоверностью. Основной вывод заключается в необходимости разработки комплексных бенчмарков, способных оценивать не только фактическую точность, но и этические аспекты применения LLM в правовой практике. Какие перспективные подходы позволят создать надежные и безопасные инструменты на основе LLM для решения реальных юридических задач?
Иллюзии и Правосудие: Обещания и Риски Больших Языковых Моделей
Все большее применение большие языковые модели (БЯМ) находят в сфере юридической деятельности, открывая перспективы автоматизации рутинных задач и расширения доступа к правосудию. Эти системы способны анализировать обширные объемы юридических текстов, выявлять релевантную информацию и даже составлять предварительные версии документов, что существенно экономит время и ресурсы юристов. Потенциал БЯМ особенно велик в областях, где существует дефицит юридической помощи, таких как предоставление базовых консультаций гражданам или помощь в заполнении стандартных форм. Автоматизация процессов, связанных с поиском прецедентов и анализом законодательства, позволяет повысить эффективность работы юридических фирм и государственных органов, а также снизить стоимость юридических услуг для населения. В перспективе, БЯМ могут стать незаменимым инструментом для повышения прозрачности и доступности правовой системы.
Большие языковые модели (LLM), несмотря на свой потенциал в автоматизации юридических задач, подвержены явлению, известному как “юридические галлюцинации”. Это проявляется в генерации ложной или юридически некорректной информации, что создает серьезные риски для пользователей и всей правовой системы. В отличие от простых фактических ошибок, “галлюцинации” LLM могут включать вымышленные прецеденты, неверные толкования законов или даже создание несуществующих нормативных актов. Такая неточность не только подрывает доверие к технологиям искусственного интеллекта в правовой сфере, но и может привести к ошибочным юридическим консультациям, неверным судебным решениям и, как следствие, к серьезным правовым последствиям для граждан и организаций. Поэтому критически важно разрабатывать методы выявления и смягчения этих “галлюцинаций” для обеспечения надежности и безопасности применения LLM в юридической практике.
Для адекватной оценки возможностей больших языковых моделей (LLM) в юридической сфере недостаточно полагаться лишь на общую точность ответов. Необходимы надежные, специализированные бенчмарки, учитывающие специфику правовой области и проверяющие не только фактическую корректность, но и юридическую обоснованность выводов. Особое внимание следует уделять оценке надежности — способности модели последовательно предоставлять достоверную информацию и избегать “юридических галлюцинаций”. Проверка должна включать анализ способности модели к логическому мышлению, выявлению противоречий и корректной интерпретации правовых норм, а не просто констатации фактов. Только комплексный подход к оценке позволит гарантировать, что LLM действительно могут быть полезными и безопасными инструментами в правовой практике.
Калибровка Правосудия: Создание Эталонов для Оценки Точности и Беспристрастности
Систематическая оценка больших языковых моделей (LLM) в юридической сфере основывается на использовании специализированных “юридических бенчмарков” — наборов данных и метрик, предназначенных для тестирования LLM при решении разнообразных юридических задач, таких как предсказание судебных решений. Эти бенчмарки позволяют объективно измерить производительность модели в различных сценариях, включая анализ юридических документов, выявление релевантной информации и прогнозирование исхода судебных разбирательств. Важным аспектом является создание бенчмарков, охватывающих широкий спектр юридических областей и типов задач, для обеспечения всесторонней и надежной оценки возможностей LLM.
Развитие эталонных наборов данных для оценки языковых моделей в юридической сфере представлено проектами LexEval и JudiFair. В частности, JudiFair выделяется объемом размеченных данных, превышающим 177 100 юридических случаев. Это значительно расширяет возможности всесторонней оценки по сравнению с традиционными методами, которые часто ограничены меньшими и менее разнообразными наборами данных. Увеличение объема размеченных данных позволяет более полно оценить способность моделей к решению широкого спектра юридических задач и выявлять потенциальные недостатки в их работе.
Оценка справедливости, в частности с использованием контрфактического анализа, является критически важной для выявления и смягчения предвзятости в результатах работы больших языковых моделей (LLM). Платформа JudiFair предоставляет инструменты для проведения такой оценки, используя 65 меток, распределенных по четырем категориям, что позволяет анализировать предвзятость по различным аспектам. Такой подход обеспечивает более детальное и всестороннее исследование потенциальных искажений в логике и выводах LLM, способствуя созданию более надежных и беспристрастных систем.
За пределами Точности: Метрики, Отражающие Суть Юридического Мышления
Традиционные метрики оценки, такие как ROUGE и BERT-Score, основаны на измерении семантической близости между сгенерированным текстом и эталонным. Однако, в контексте юридической сферы, где важны точные формулировки, логическая последовательность и учет прецедентного права, эти метрики могут оказаться недостаточными. Они не учитывают специфику юридического рассуждения, например, способность выявлять релевантные правовые нормы или корректно применять их к конкретным фактам дела. В результате, высокая оценка по ROUGE или BERT-Score не гарантирует, что сгенерированный текст является юридически обоснованным или адекватным для решения поставленной задачи.
Метод “LLM-как-судья” предполагает использование другой большой языковой модели (LLM) для оценки результатов, генерируемых основной LLM. Этот подход позволяет автоматизировать процесс оценки, который традиционно требует значительных человеческих ресурсов. Однако, для обеспечения надежности и объективности оценки, требуется тщательная валидация LLM, выступающей в роли судьи. Валидация должна включать оценку ее способности к последовательному применению юридических принципов, выявление и коррекция потенциальных предвзятостей, а также сопоставление оценок, выдаваемых LLM-судьей, с экспертными оценками, полученными от квалифицированных юристов. Недостаточная валидация может привести к неверным оценкам и, как следствие, к принятию ошибочных решений.
Экспертная аннотация продолжает оставаться золотым стандартом оценки качества данных, особенно в задачах, требующих глубокого понимания контекста и нюансов, таких как юридический анализ. Оценка, осуществляемая квалифицированными специалистами в соответствующей области, обеспечивает надежный и объективный критерий для измерения точности, релевантности и полноты результатов, генерируемых системами искусственного интеллекта. В отличие от автоматических метрик, экспертная оценка позволяет учитывать сложные случаи, требующие интерпретации и логического вывода, а также выявлять ошибки, которые могут быть незаметны для алгоритмов. Качество данных, полученных в результате экспертной аннотации, напрямую влияет на обучение и эффективность моделей машинного обучения, гарантируя высокую степень достоверности и надежности.
Проверка Рассуждений: Применение к Юридическим Задачам
Оценка больших языковых моделей (LLM) включает проверку их способности применять структуру IRAC (Проблема, Норма, Применение, Вывод) для демонстрации логического мышления. Данный фреймворк используется как стандарт для анализа юридических задач, требующий от модели последовательного выявления ключевой проблемы, определения применимого правового правила, сопоставления фактов дела с этим правилом и, наконец, формулирования логически обоснованного заключения. Успешное применение IRAC указывает на способность модели к дедуктивному рассуждению и юридическому анализу.
Оценка возможностей больших языковых моделей (LLM) в юридических задачах осуществляется посредством предоставления на вход структурированных «описаний фактов дела» (Case Fact Descriptions). Эти описания представляют собой текстовые данные, содержащие детали конкретного юридического случая. Цель данного подхода — проверка способности модели к пониманию и извлечению релевантной информации из представленного текста, необходимой для последующего применения правовых норм и формулирования обоснованных выводов. Точность извлечения фактов и их корректная интерпретация являются ключевыми показателями эффективности модели в контексте юридического анализа.
Для оценки устойчивости больших языковых моделей (LLM) к воздействию нештатных ситуаций применяются так называемые “атакующие примеры” (adversarial attacks). Эти атаки представляют собой специально сконструированные входные данные, незначительно отличающиеся от типичных, но способные вызвать ошибочные ответы модели. Цель таких тестов — выявить уязвимости в логике рассуждений LLM и оценить, насколько надежно модель сохраняет корректную работу в сложных и непредсказуемых сценариях. Проведение adversarial-тестирования позволяет разработчикам выявить и устранить слабые места модели, повышая ее общую надежность и предсказуемость при решении юридических задач.
К Надежному Искусственному Интеллекту: Будущее Юридических Технологий
Для создания действительно надежных языковых моделей (LLM) в юридической сфере необходима строгая оценка с использованием всесторонних эталонов. Простое достижение высокой точности недостаточно; важно оценить способность модели понимать нюансы юридического языка, выявлять противоречия в документах и корректно применять правовые нормы к конкретным ситуациям. Комплексные тесты должны включать анализ различных типов юридических текстов — от законов и постановлений до судебных решений и договоров — а также проверку на предвзятость и уязвимость к манипуляциям. Разработка специализированных эталонов, отражающих специфику юридической деятельности, позволит не только объективно оценить текущие возможности LLM, но и стимулировать дальнейшее развитие технологий, гарантируя их соответствие высоким требованиям надежности и ответственности в правовой области.
Постоянное совершенствование языковых моделей, используемых в юридической сфере, требует не только первоначального обучения, но и непрерывной проверки на устойчивость к различным манипуляциям и нештатным ситуациям. Этот процесс, известный как антагонистическое тестирование, заключается в преднамеренном создании сложных и неоднозначных запросов, направленных на выявление слабых мест и потенциальных ошибок модели. Параллельно, эксперты в области права осуществляют тщательный контроль и оценку результатов, выявляя случаи неверной интерпретации юридических норм или предоставления некорректной информации. Такое сочетание автоматизированного тестирования и человеческой экспертизы позволяет не только повысить надежность и точность работы моделей, но и минимизировать риски, связанные с их применением в критически важных областях, обеспечивая тем самым доверие к технологиям искусственного интеллекта в правовой сфере.
Внедрение больших языковых моделей (LLM) в юридические процессы открывает значительные перспективы для повышения эффективности работы и снижения издержек. Автоматизация рутинных задач, таких как поиск прецедентов, анализ договоров и подготовка стандартных документов, позволяет юристам сосредоточиться на более сложных и требующих творческого подхода аспектах дела. Это не только оптимизирует время и ресурсы, но и способствует снижению стоимости юридических услуг, делая их более доступными для широкого круга граждан и организаций. Кроме того, LLM могут способствовать расширению доступа к правосудию, предоставляя базовую юридическую информацию и помощь тем, кто не может позволить себе услуги квалифицированного юриста, что особенно актуально в удаленных и малообеспеченных регионах.
Исследование оценки больших языковых моделей в юридической сфере подчёркивает, что создание надежной системы — это не просто конструирование, а взращивание. Подобно садовнику, архитектор ИИ должен предвидеть не только рост, но и возможные неудачи. Как отмечал Давид Гильберт: «В математике нет признаков, а есть лишь доказательства». Точно так же, оценка LLM требует не просто поиска ошибок, а подтверждения их способности к устойчивой работе в условиях неполноты или двусмысленности данных. В контексте юридических приложений, где точность и надежность критически важны, оценка должна выходить за рамки простой проверки фактов и охватывать вопросы справедливости и безопасности, формируя тем самым доверие к системе.
Что же дальше?
Оценка больших языковых моделей в правовой сфере — это не столько задача достижения абсолютной точности, сколько культивирование сложной экосистемы. Попытки создать совершенный эталон, свободный от ошибок, обречены на провал — ведь система, которая никогда не ломается, мертва. Каждый архитектурный выбор, каждая метрика оценки — это пророчество о будущем сбое, о точке, где модель проявит свою неспособность к адаптации.
Истинная ценность исследований лежит не в создании идеального инструмента, а в понимании границ его применимости. Недостаточно оценивать лишь способность модели к логическому выводу; необходимо исследовать её предрасположенность к галлюцинациям, её скрытые предубеждения, её уязвимость к манипуляциям. В конечном счете, система, в которой не остаётся места для человеческой интерпретации, — это не помощник, а замена.
Будущее правовой AI — это не в автоматизации юридической практики, а в создании инструментов, которые расширяют возможности юриста, а не заменяют его. Необходимо сместить фокус с «точности» на «надёжность в условиях неопределённости», с «безошибочности» на «способность к самокоррекции». В противном случае, мы рискуем построить не систему правосудия, а его имитацию.
Оригинал статьи: https://arxiv.org/pdf/2601.15267.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Квантовый скачок в обработке радиоастрономических данных
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
2026-01-23 03:55