Автор: Денис Аветисян
Новая система позволяет автоматически извлекать структурированные данные из научных PDF-документов, значительно облегчая процесс синтеза доказательной базы в медицине.
Разработанный подход использует ограничения схемы, отслеживание происхождения данных и оптическое распознавание символов для повышения надёжности извлечения информации из научных публикаций.
Извлечение методологических данных и результатов из научных публикаций является трудоемким и подверженным ошибкам процессом, особенно при работе с неструктурированными PDF-документами. В работе ‘From Chaos to Clarity: Schema-Constrained AI for Auditable Biomedical Evidence Extraction from Full-Text PDFs’ представлена система, использующая схемы и отслеживание происхождения данных для автоматизированного извлечения структурированных данных из научных PDF-файлов. Предложенный подход обеспечивает масштабируемое и аудируемое преобразование гетерогенных научных документов, повышая надежность синтеза биомедицинских данных. Способны ли подобные системы радикально ускорить процесс систематического обзора и повысить качество доказательной медицины?
Запертые Знания: Преодоление Узкого Места Извлечения из Научной Литературы
Огромные массивы научных знаний остаются недоступными из-за их хранения в неструктурированных PDF-файлах, что существенно замедляет темпы прогресса. Миллионы научных статей, отчетов и диссертаций, содержащих ценные данные и открытия, существуют в виде изображений текста или сложных, не поддающихся автоматической обработке форматов. Это создает серьезные препятствия для исследователей, которым требуется быстро анализировать большие объемы информации, выявлять закономерности и строить новые гипотезы. Фактически, значительная часть накопленных научных знаний остается «запертой» в этих файлах, ограничивая возможности для дальнейших исследований и инноваций, и подчеркивая необходимость разработки эффективных методов извлечения данных из неструктурированных документов.
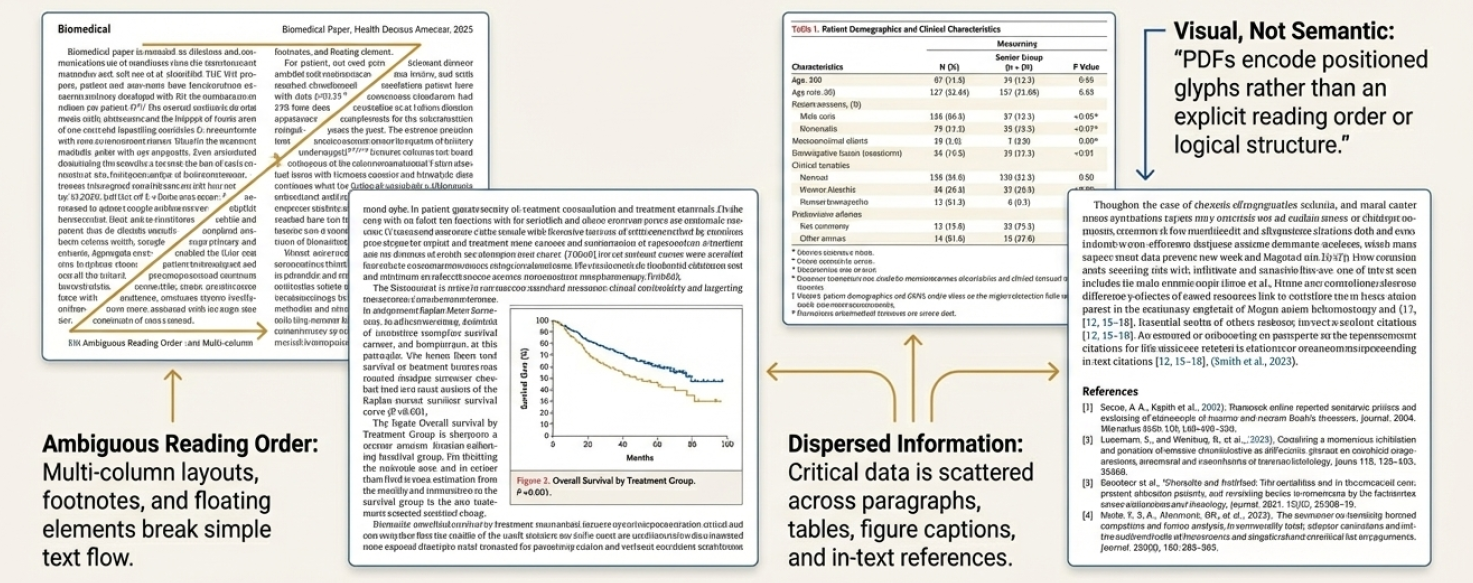
Традиционные методы извлечения информации сталкиваются со значительными трудностями при работе с научной литературой из-за её внутренней сложности и разнообразия форматов. В отличие от структурированных баз данных, научные статьи часто представляют собой сложные PDF-документы с многоуровневой структурой, включающей таблицы, графики, формулы E=mc^2 и нерегулярные текстовые блоки. Автоматическое распознавание и интерпретация этих элементов требует алгоритмов, способных адаптироваться к широкому спектру макетов, шрифтов и нотаций, что представляет собой серьезную вычислительную задачу. Неспособность эффективно обрабатывать эту гетерогенность приводит к низкой точности извлечения ключевых данных, ограничивая возможности автоматизированного анализа и синтеза научных знаний.
Основная сложность извлечения информации из научных публикаций заключается в точном определении и выделении ключевых данных, скрытых в разнообразных и сложных форматах. Научные статьи часто отличаются нестандартной структурой, включающей таблицы, графики, формулы E=mc^2, и многоуровневые заголовки, что затрудняет автоматизированное распознавание значимой информации. Традиционные методы обработки текста испытывают трудности при анализе таких документов, поскольку требуют адаптации к различным стилям оформления и специфической терминологии, используемой в конкретных областях науки. Эффективное решение этой проблемы имеет решающее значение для раскрытия потенциала огромного массива научных знаний, заключенных в неструктурированных PDF-файлах.
От Пикселей к Структуре: Продвинутое Понимание Документов
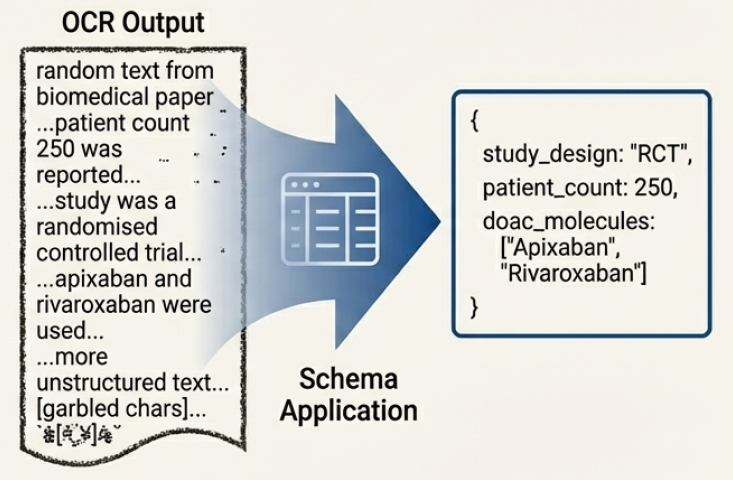
Эффективное извлечение данных из научных PDF-документов основано на двух взаимосвязанных этапах: оптическом распознавании символов (OCR) и анализе структуры документа (Layout Analysis). OCR преобразует изображения текста в машиночитаемый формат, однако без понимания расположения элементов на странице — заголовков, абзацев, таблиц, рисунков — извлеченные данные будут неструктурированными. Анализ структуры документа определяет логическую организацию содержимого, выявляя взаимосвязи между текстовыми блоками и визуальными элементами. Комбинирование OCR и анализа структуры позволяет точно идентифицировать и извлекать информацию, сохраняя её контекст и семантическое значение, что критически важно для дальнейшей обработки и анализа научных публикаций.
Современные подходы к анализу документов, такие как DocFormer и LayoutLM, используют архитектуры Transformer для объединения текстовой и пространственной информации. В отличие от традиционных методов, обрабатывающих текст и макет отдельно, эти модели позволяют одновременно учитывать содержание текста и его положение на странице. Это достигается путем представления документа как последовательности токенов, включающих как текстовые фрагменты, так и информацию о координатах и размерах текстовых блоков. Такой подход позволяет модели понимать взаимосвязь между текстом и его окружением, что критически важно для точного извлечения информации из сложных документов, например, научных статей и отчетов. В результате, модели, использующие архитектуры Transformer, демонстрируют более высокую точность в задачах распознавания именованных сущностей, извлечения таблиц и понимания структуры документа в целом.
Извлечение информации с ограничением по схеме (Schema-Constrained Extraction) повышает точность за счет направления процесса извлечения данных посредством предопределенных структур, основанных на четко определенной схеме. Данный подход предполагает предварительное определение типов извлекаемых данных и их взаимосвязей, что позволяет модели фокусироваться на релевантной информации и снижает вероятность ошибок. Схема определяет ожидаемые поля, форматы данных и правила валидации, что позволяет алгоритму не только извлекать информацию, но и проверять ее соответствие заданным критериям. Это особенно важно при работе со сложными документами, такими как научные статьи или юридические договоры, где требуется высокая степень точности и структурированности извлекаемых данных.
Проверка Надежности: Бенчмаркинг и Валидация
Наборы данных, такие как PubLayNet и DocBank, играют ключевую роль в обучении и оценке моделей анализа структуры документов и понимания документов. PubLayNet предоставляет обширный набор размеченных изображений научных статей, позволяя обучать модели для распознавания различных элементов макета, включая заголовки, абзацы, таблицы и рисунки. DocBank, в свою очередь, содержит размеченные документы, охватывающие широкий спектр форматов и типов, что способствует развитию моделей, способных обрабатывать разнообразные документы. Использование этих наборов данных позволяет разработчикам объективно оценивать производительность моделей, сравнивать различные подходы и улучшать точность извлечения информации из документов.
Для поддержки процесса извлечения информации из документов используются специализированные инструменты, такие как GROBID, CERMINE и ParsCit. GROBID специализируется на структурировании научных статей, извлекая библиографические данные и метаданные. CERMINE предназначен для преобразования PDF-документов в структурированный текст с сохранением форматирования. ParsCit фокусируется на извлечении цитат и библиографических ссылок. Для оценки общей производительности систем извлечения информации используется эталонный набор данных OmniDocBench, который позволяет сравнивать различные подходы и алгоритмы по единым метрикам.
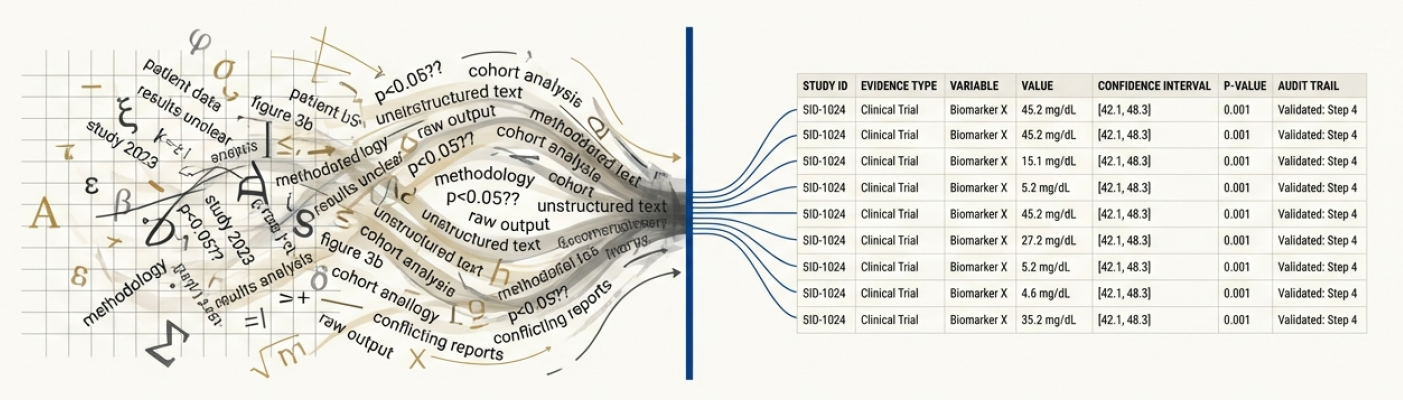
Метод извлечения с учетом происхождения (Provenance-Aware Extraction) повышает надежность извлеченной информации за счет отслеживания источника и истории каждого элемента данных. Это включает в себя запись метаданных, таких как идентификатор документа, номер страницы, координаты текстового блока и алгоритм, использованный для извлечения. Сохранение этой информации позволяет проводить аудит процесса извлечения, верифицировать данные и оценить степень их достоверности. В случае возникновения ошибок или несоответствий, отслеживание происхождения позволяет определить этап, на котором произошла ошибка, и предпринять корректирующие действия. Такой подход особенно важен для критически важных приложений, где точность и надежность данных имеют первостепенное значение.
Ускорение Научных Открытий: Синтез и Перспективы
Надежное извлечение данных из научных PDF-документов является фундаментальным условием для проведения масштабного синтеза научных доказательств. В условиях экспоненциального роста объема публикуемых исследований, ручная обработка и извлечение информации становятся непомерно трудоемкими и подвержены ошибкам. Автоматизированные системы, способные точно и эффективно извлекать ключевые данные — такие как результаты экспериментов, методологии и выводы — открывают возможности для мета-анализа, систематических обзоров и, в конечном итоге, ускорения научного прогресса. Без надежной основы, обеспечиваемой точным извлечением данных, любые попытки обобщить и синтезировать научные знания становятся ненадежными и могут приводить к ошибочным выводам. Эффективное извлечение информации из PDF-документов, таким образом, выступает критически важным шагом на пути к более быстрому и надежному развитию науки.
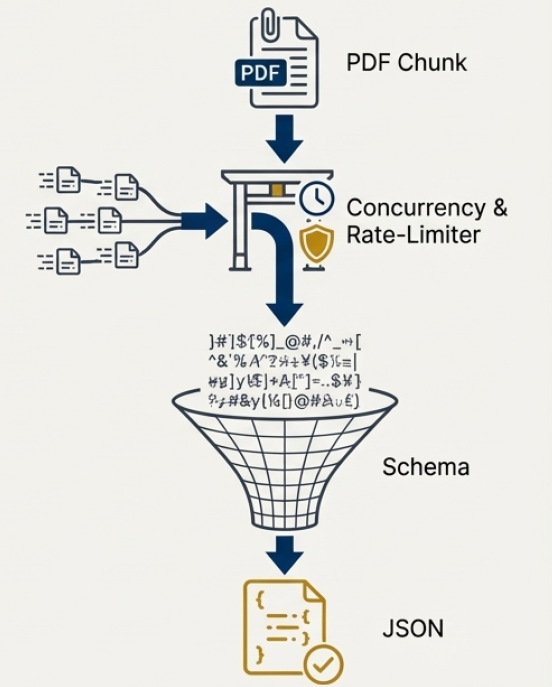
Для повышения скорости и точности извлечения информации из научных PDF-документов используется комбинация методов разделения страниц на части (Page Chunking) и условных случайных полей (Conditional Random Fields, CRFs). Разделение страниц позволяет обрабатывать большие документы параллельно, снижая общее время обработки. В свою очередь, CRFs — это алгоритм машинного обучения, который эффективно идентифицирует и классифицирует различные элементы текста, такие как заголовки, абзацы и таблицы, даже при наличии сложных структур и нечетких границ. Благодаря такому подходу, система способна не только быстро обрабатывать большие объемы данных, но и минимизировать количество ошибок при извлечении ключевой информации, обеспечивая высокую надежность результатов анализа.
Система успешно обработала корпус, состоящий из 734 PDF-документов, что наглядно демонстрирует её стабильную производительность и масштабируемость. В ходе тестирования подтверждена способность системы эффективно справляться с большим объемом научных публикаций без потери скорости и точности извлечения данных. Это свидетельствует о потенциале платформы для автоматизации обработки обширных массивов научной информации, что крайне важно для проведения масштабных исследований и мета-анализов. Доказанная масштабируемость позволяет предполагать возможность дальнейшего расширения системы для работы с ещё более крупными базами данных, открывая новые перспективы в области синтеза научных доказательств.
Разработанный конвейер обработки научных статей демонстрирует существенное сокращение времени, необходимого для извлечения данных. В то время как ручное извлечение информации из одного исследования может занимать десятки минут, данная система справляется с задачей в среднем за 11 секунд. Это позволяет значительно ускорить процесс синтеза научных доказательств, обеспечивая возможность обработки до 67 документов в час. Такая производительность открывает новые перспективы для анализа больших объемов научной литературы и выявления ключевых тенденций и взаимосвязей, которые ранее были недоступны из-за ограничений по времени и ресурсам.
Исследование продемонстрировало впечатляющую производительность автоматизированной системы извлечения данных из научных публикаций. Благодаря оптимизированному подходу, система способна обрабатывать приблизительно 67 PDF-документов в час. Эта скорость обработки представляет собой существенный скачок вперед по сравнению с традиционными методами ручного извлечения, требующими десятки минут на каждую статью. Такой показатель открывает новые возможности для масштабного научного синтеза, позволяя значительно ускорить процесс обобщения и анализа большого объема научных данных и, как следствие, стимулировать более оперативные научные открытия.
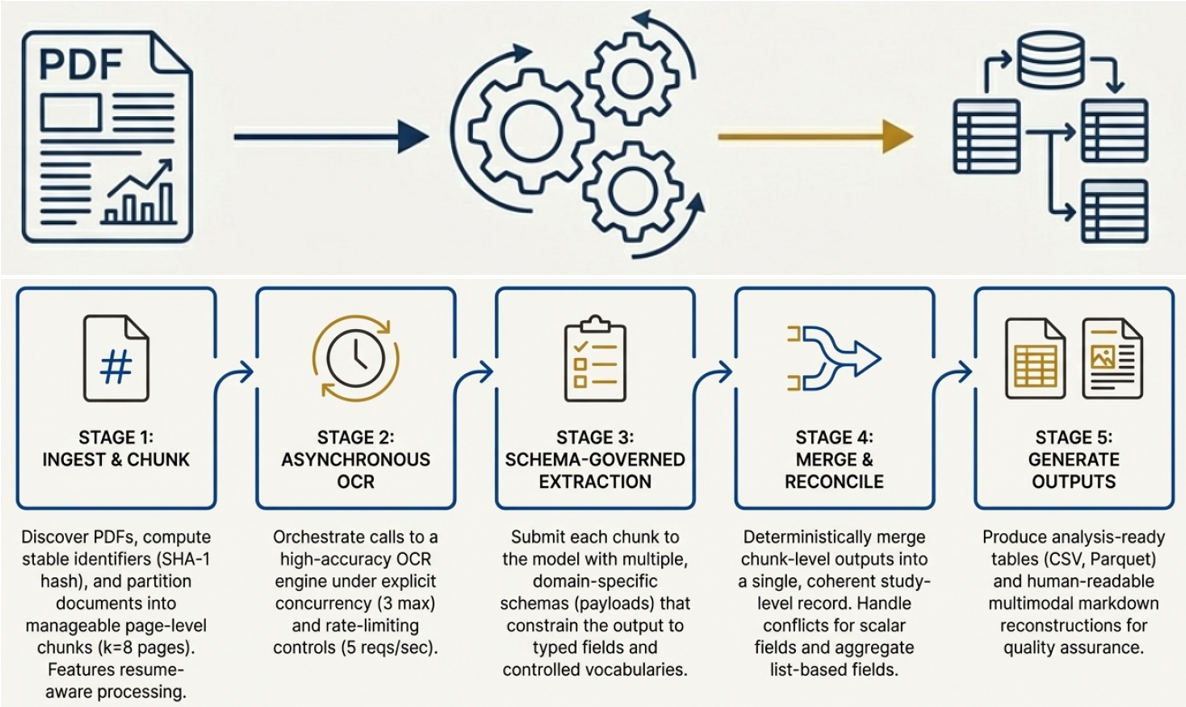
Представленная работа демонстрирует стремление к упорядочиванию хаоса, свойственного научным публикациям в формате PDF. Авторы предлагают не просто инструмент для извлечения данных, а целую экосистему, способную адаптироваться к разнообразию форматов и обеспечить отслеживаемость происхождения информации. В этом контексте особенно примечательна мысль Дональда Кнута: «Оптимизм — это вера в то, что всё пойдет не так плохо, как могло бы». Подобный подход к извлечению биомедицинских данных, с акцентом на надежность и возможность аудита, является своеобразной страховкой от ошибок и неточностей, неизбежных при ручной обработке. Система, описанная в статье, — это попытка создать кеш порядка между двумя неизбежными сбоями — неточностями исходных данных и сложностью их интерпретации.
Куда Ведёт Этот Путь?
Представленная работа, стремясь обуздать хаос неструктурированной информации в научных PDF-документах, неизбежно сталкивается с фундаментальной истиной: системы не строятся, они вырастают. Ограничение схемой — это попытка предсказать будущее сбоя, а не его предотвратить. Чем строже схема, тем тоньше маска, скрывающая неминуемые отклонения реальности от идеализированной модели. Каждый извлечённый факт — это семя будущей противоречивости.
Упор на отслеживание происхождения данных — достойное стремление, но иллюзия полного контроля над цепочкой зависимостей. Мы разделили систему на микросервисы, но не судьбу. Всё связанное когда-нибудь упадёт синхронно, и отследить первопричину в паутине взаимосвязей окажется непосильной задачей. Неизбежно возникнет потребность в автоматизированном выявлении и разрешении конфликтов, что, в свою очередь, породит новые уровни сложности.
Будущее, вероятно, лежит в области самообучающихся систем, способных адаптироваться к меняющимся форматам и неполноте данных. Но и здесь таится опасность: чем больше система стремится к автономности, тем сложнее предсказать её поведение. Попытки создать «идеальный» инструмент для извлечения знаний, возможно, обречены на провал. Познание — это процесс, а не результат, и любая попытка его зафиксировать — это лишь моментная фотография в бесконечном потоке информации.
Оригинал статьи: https://arxiv.org/pdf/2601.14267.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Бреп-Кодер: Искусственный интеллект, понимающий геометрию
- Квантовые Загадки и Финансовые Реалии
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
2026-01-23 05:37