Автор: Денис Аветисян
Представлена модель Qwen3-TTS, открывающая возможности высококачественного и быстрого преобразования текста в речь на нескольких языках.
Qwen3-TTS — семейство масштабных моделей преобразования текста в речь, демонстрирующих передовые результаты в клонировании голоса, управлении синтезом и потоковой генерации.
Современные системы синтеза речи часто сталкиваются с компромиссом между качеством, гибкостью управления и задержкой. В данной работе, представленной в ‘Qwen3-TTS Technical Report’, описывается семейство моделей Qwen3-TTS — передовых многоязычных систем преобразования текста в речь, демонстрирующих выдающиеся результаты в клонировании голоса, контроле над параметрами синтеза и потоковой передаче. Модели Qwen3-TTS, обученные на более чем 5 миллионах часов речи на 10 языках, используют двухпоточную LM-архитектуру и два токенизатора речи для обеспечения как высококачественного синтеза, так и минимальной задержки, вплоть до 97\,\mathrm{ms}. Смогут ли эти модели стать основой для создания принципиально новых интерактивных голосовых интерфейсов и приложений?
За пределами Форм Сигнала: Вызовы Естественной Речи
Традиционные системы синтеза речи зачастую выдают неестественное звучание, характеризующееся монотонностью и отсутствием эмоциональной окраски. Это связано с тем, что алгоритмы, используемые в этих системах, испытывают трудности в воспроизведении тонкостей человеческой речи — интонации, ударения, пауз и тембра голоса. В результате, сгенерированная речь воспринимается слушателем как роботизированная и лишенная выразительности, что существенно снижает ее естественность и затрудняет восприятие информации. Проблема заключается в том, что сложные акустические характеристики, формирующие просодию, трудно поддаются моделированию и воспроизведению с помощью стандартных методов синтеза речи.
Создание высококачественной и управляемой речи требует преодоления сложностей, связанных с моделированием комплексных акустических характеристик и долгосрочных зависимостей в речевом сигнале. Традиционные методы часто упрощают эти аспекты, что приводит к неестественному звучанию. Для достижения реалистичности необходимо учитывать тончайшие изменения в тембре, интонации и ритме, а также взаимосвязь между звуками на протяжении всей фразы. Исследования направлены на разработку моделей, способных улавливать эти сложные паттерны и воспроизводить их с высокой точностью, используя, например, рекуррентные нейронные сети или трансформеры, способные учитывать контекст и взаимосвязи между различными частями речи. Успешное моделирование этих характеристик открывает путь к созданию синтезированной речи, неотличимой от естественной, и позволит создавать голосовые помощники и приложения, обладающие более человечным и выразительным звучанием.
Современные системы синтеза речи часто сталкиваются с трудностями при адаптации к различным голосам, языкам и манерам речи. Существующие подходы, как правило, требуют значительных усилий для перенастройки и обучения при смене диктора или языковой модели, что делает их неэффективными в сценариях, требующих быстрого переключения между различными профилями речи. Недостаток гибкости проявляется в сложности точной имитации нюансов произношения, интонационных особенностей и акцентов, характерных для конкретного голоса или языка. Это ограничивает возможности создания реалистичной и персонализированной речи, способной эффективно передавать эмоции и поддерживать естественное взаимодействие с пользователем. Разработка более адаптивных алгоритмов, способных к быстрому обучению и обобщению, является ключевой задачей для дальнейшего совершенствования технологий синтеза речи.
Дискретные Токены и Эффективный Синтез
В Qwen3-TTS используется дискретная токенизация речи, представляющая звуковой сигнал в виде последовательности дискретных единиц, а не непрерывного сигнала. Этот подход обеспечивает повышенную стабильность процесса синтеза и более естественное звучание речи по сравнению с методами, оперирующими непрерывными представлениями. Дискретизация позволяет моделировать речь как последовательность токенов, что упрощает применение авторегрессионных языковых моделей для предсказания следующего токена на основе предыдущей последовательности, что, в свою очередь, улучшает качество синтезированной речи и снижает вероятность появления артефактов.
Применение токенизированного подхода позволяет использовать методы авторегрессионного языкового моделирования для синтеза речи. В рамках данной технологии, модель предсказывает следующий речевой токен на основе предшествующей последовательности токенов. Это обеспечивает генерацию связной и естественной речи, поскольку каждое предсказание зависит от предыдущих, формируя последовательность, отражающую лингвистические закономерности. Авторегрессионный подход позволяет модели учитывать контекст и генерировать речь, соответствующую заданному тексту и интонации.
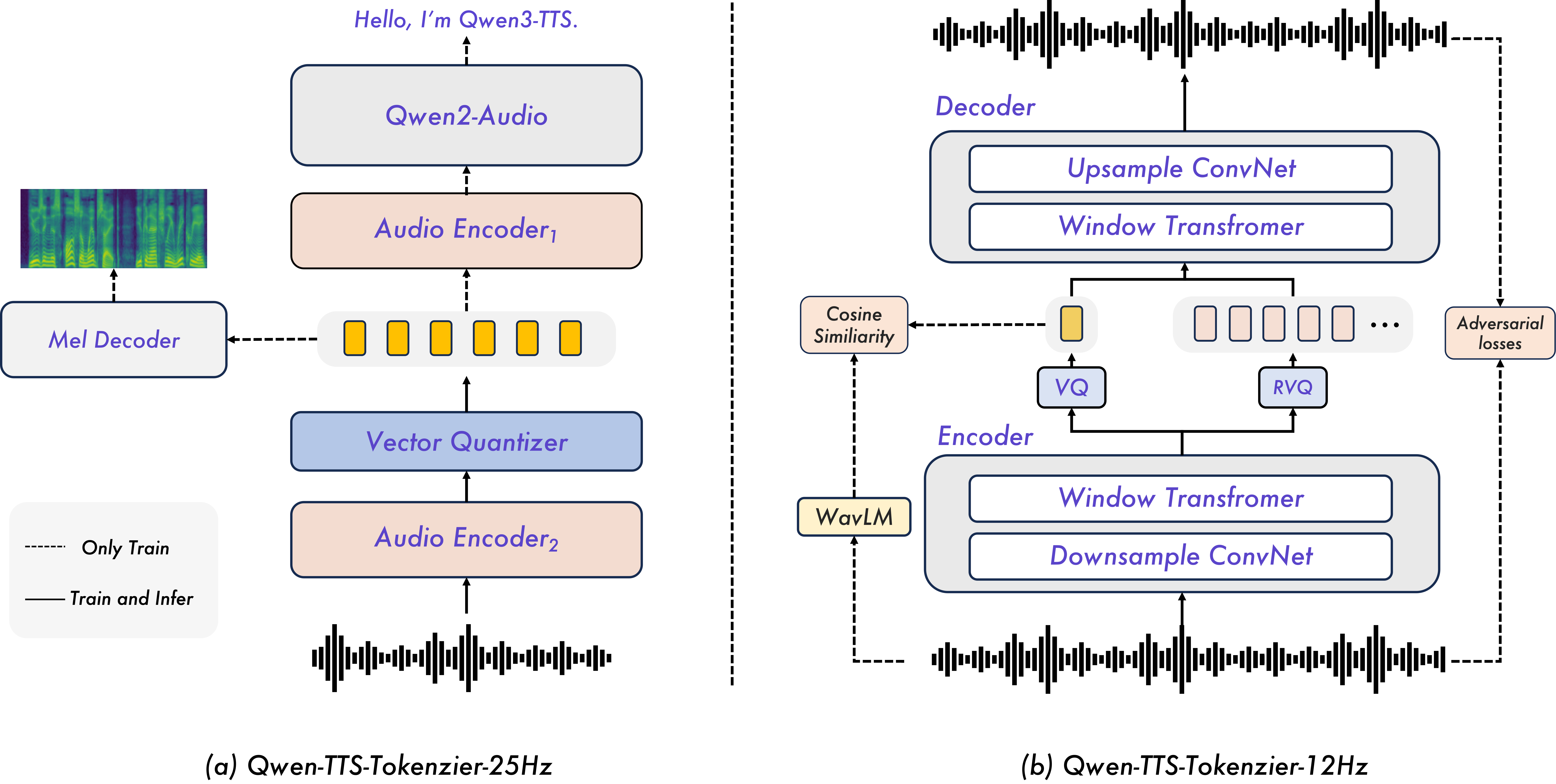
Модель Qwen3-TTS использует два различных токенизатора речи — Qwen-TTS-Tokenizer-25Hz и Qwen-TTS-Tokenizer-12Hz — каждый из которых оптимизирован для различных приоритетов синтеза. Токенизатор Qwen-TTS-Tokenizer-25Hz ориентирован на достижение семантической насыщенности синтезируемой речи, обеспечивая более высокое качество звучания, при этом демонстрируя задержку первого пакета данных примерно в 190 мс. В свою очередь, Qwen-TTS-Tokenizer-12Hz оптимизирован для потоковой передачи с низкой задержкой, поддерживая частоту токенов 12.5 Гц и обеспечивая задержку менее 320 мс. Выбор токенизатора позволяет адаптировать систему к различным сценариям использования, в зависимости от требований к качеству и скорости синтеза.
Двухпутная Архитектура и Продвинутые Методы
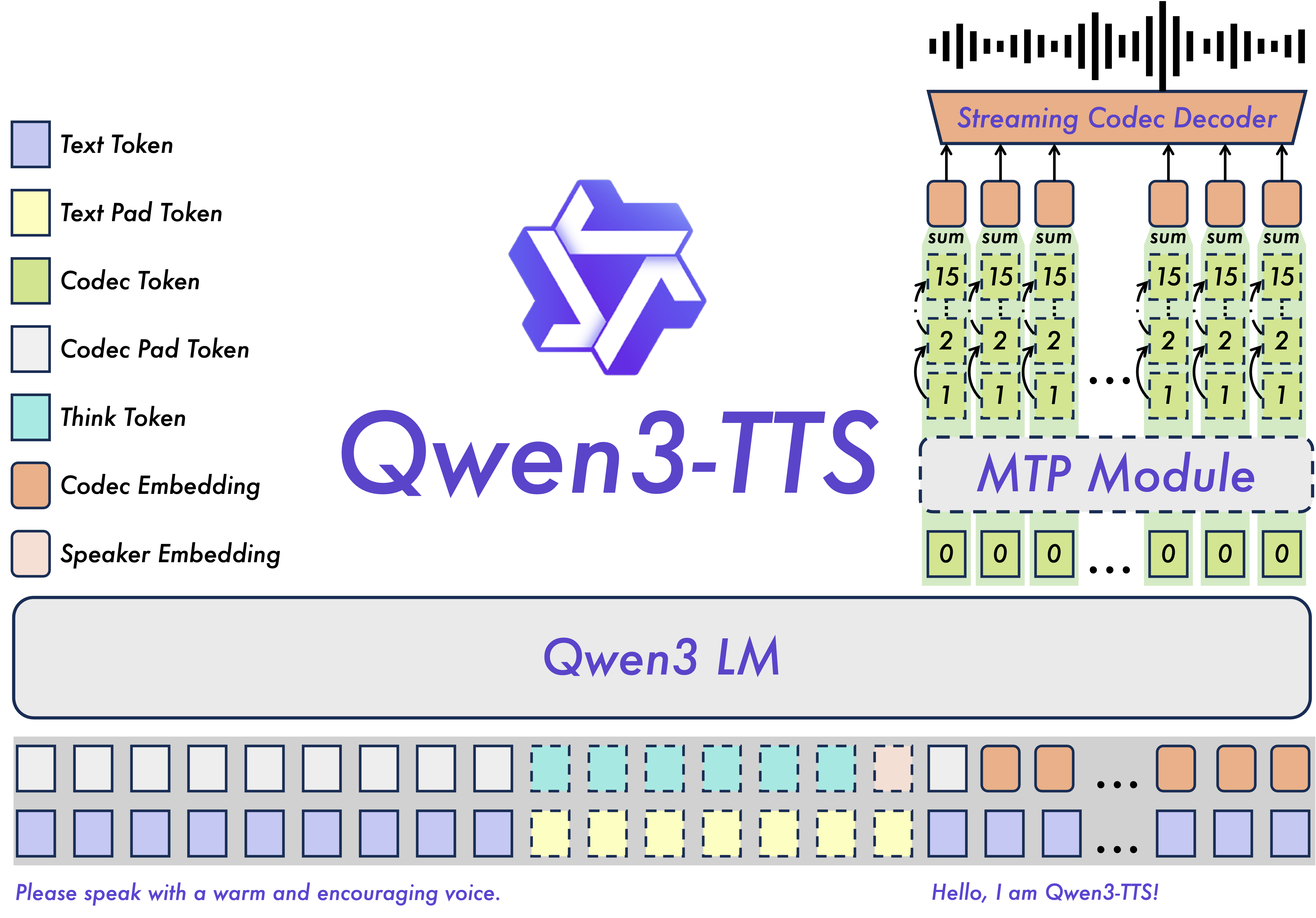
Архитектура Qwen3-TTS построена на одновременной обработке текстовых и акустических токенов, что позволяет существенно снизить задержку синтеза речи. Такой подход, известный как dual-track архитектура, обеспечивает параллельное выполнение операций над различными типами данных, необходимых для генерации речи. В отличие от последовательных методов, где обработка одного типа токенов должна завершиться перед началом обработки другого, параллельная обработка позволяет сократить общее время синтеза, что критически важно для приложений, требующих генерацию речи в реальном времени, таких как голосовые помощники и интерактивные системы.
Токенизатор с частотой 25 Гц использует архитектуру Diffusion Transformer (DiT) и метод Block-wise Flow Matching для реконструкции формы сигнала. DiT обеспечивает эффективное моделирование данных, а Block-wise Flow Matching — точное восстановление временной структуры аудио. В свою очередь, токенизатор с частотой 12 Гц применяет WavLM для извлечения признаков из аудио и Residual Vector Quantization (RVQ) для уточнения акустических деталей, повышая качество синтезируемой речи за счет более детального представления звуковых характеристик.
В рамках 12Hz токенизатора, технология Multi-Token Prediction (MTP) повышает эффективность моделирования за счет эффективной обработки последовательностей из нескольких кодовых книг. Вместо предсказания отдельных токенов, MTP позволяет модели предсказывать сразу несколько токенов, что снижает вычислительную нагрузку и ускоряет процесс синтеза речи. Это достигается за счет параллельной обработки и оптимизации предсказания взаимосвязанных акустических признаков, представленных в виде многокодовых последовательностей.
Контролируемый и Персонализированный Синтез Речи
Разработанная система Qwen3-TTS представляет собой значительный прорыв в области синтеза речи благодаря интеграции с большими языковыми моделями (LLM). Это позволяет не просто генерировать речь из текста, но и точно управлять её характеристиками — стилем, эмоциональной окраской и просодией. В отличие от традиционных систем, Qwen3-TTS способна следовать инструкциям, что открывает возможности для создания персонализированной речи, точно соответствующей заданным параметрам. Например, можно указать, чтобы речь звучала более формально, дружелюбно или с определенным акцентом, а также задать желаемый темп и интонацию, что делает синтезированную речь значительно более естественной и выразительной.
Модель Qwen3-TTS демонстрирует впечатляющую способность к клонированию голоса, позволяя пользователям воспроизводить уникальные стили речи на основе предоставленных аудиозаписей. Этот процесс не ограничивается одним языком — технология расширяет возможности клонирования голоса на межъязычной основе, то есть позволяет воспроизвести голос на одном языке, используя данные, полученные из другого. Данная функциональность открывает широкие перспективы для создания персонализированных голосовых помощников, озвучивания контента на разных языках с сохранением оригинальной манеры речи и адаптации голоса к различным творческим задачам, предоставляя пользователям беспрецедентный уровень контроля и гибкости.
Для достижения максимально естественного и привлекательного звучания синтезированной речи, в модели был применен метод прямой оптимизации предпочтений (DPO). Этот подход позволяет напрямую сопоставлять результаты работы модели с субъективными оценками людей, что значительно улучшает качество генерируемой речи. В ходе тестирования, применение DPO обеспечило достижение передовых результатов: показатель Word Error Rate (WER) составил 1.24 на тестовом наборе данных test-en. Особенно заметно улучшение в сложных сценариях, таких как генерация речи на корейском языке из китайского, где удалось снизить количество ошибок до 66% по сравнению с предыдущими моделями. Это свидетельствует о высокой эффективности DPO в адаптации синтезированной речи к человеческому восприятию и обеспечении её естественности.
Будущее Доступного и Выразительного Синтеза Речи
Модель Qwen3-TTS демонстрирует уникальную способность генерировать аудиопоток в реальном времени и обрабатывать поступающий текст также в режиме потока. Эта особенность делает её особенно ценной для приложений, требующих мгновенного взаимодействия с пользователем. В частности, речь идет о виртуальных ассистентах, способных немедленно реагировать на запросы, и системах синхронного перевода, обеспечивающих беспрепятственное общение между людьми, говорящими на разных языках. Благодаря этой архитектуре, Qwen3-TTS открывает новые возможности для создания более отзывчивых и интуитивно понятных интерфейсов, стирая границы в коммуникации и делая технологии доступнее для широкой аудитории.
Модель Qwen3-TTS демонстрирует впечатляющие возможности в области многоязыкового синтеза речи и клонирования голоса, открывая новые перспективы для преодоления коммуникационных барьеров. Благодаря способности генерировать речь на различных языках и воспроизводить тембр голоса, отличный от того, на котором модель обучалась, Qwen3-TTS способствует глобальной доступности информации и упрощает общение между людьми, говорящими на разных языках. Эта технология позволяет создавать персонализированные голосовые ассистенты, адаптированные к конкретным языковым потребностям, и обеспечивает более естественное и интуитивно понятное взаимодействие с цифровыми устройствами для пользователей по всему миру. Возможность клонирования голоса, не ограничиваясь исходным языком, представляет собой значительный шаг вперед в создании инклюзивных технологий, расширяющих возможности общения для людей с ограниченными возможностями и способствующих культурному обмену.
Текущие исследования сосредоточены на дальнейшем повышении выразительности, управляемости и эффективности модели Qwen3-TTS, что открывает путь к созданию все более естественных и привлекательных речевых взаимодействий. В частности, достигнутые значения Word Error Rate (WER) составляют 1.533 для синтеза продолжительной речи на китайском языке (long-zh) и 1.571 для английского языка (long-en), что демонстрирует значительный прогресс в точности и качестве генерируемой речи. Эти результаты свидетельствуют о потенциале модели для создания более реалистичных и понятных голосовых помощников, систем перевода в реальном времени и других приложений, требующих высококачественного синтеза речи.
Исследование Qwen3-TTS демонстрирует стремление к лаконичности и эффективности в области синтеза речи. Модель, будучи масштабной, стремится к минимизации задержек и максимальной управляемости, что соответствует принципу отсечения всего лишнего для достижения истинного смысла. Как однажды заметил Кен Томпсон: «Всё, что осталось, — и есть смысл». Эта фраза прекрасно отражает подход разработчиков Qwen3-TTS, которые, подобно скульпторам, оттачивали модель, удаляя всё ненужное, чтобы создать высококачественную и отзывчивую систему преобразования текста в речь. Акцент на потоковой синтез и клонировании голоса подчеркивает важность ясности и точности в передаче информации, что согласуется с философией простоты и элегантности.
Что дальше?
Представленная работа, хоть и демонстрирует впечатляющие результаты в области синтеза речи, лишь обнажает глубину нерешенных проблем. Стремление к «голосовой имитации» и «управляемости» неизбежно наталкивается на вопрос: что есть голос? Не просто набор акустических характеристик, но и отражение личности, эмоций, контекста. Упрощение этого сложного явления до набора параметров — это, по сути, признание собственного бессилия перед полнотой человеческого выражения. Система, требующая инструкций для воспроизведения «эмоциональной окраски», уже проиграла.
Дальнейшее развитие, вероятно, будет связано не с усложнением моделей, а с их очищением. Вместо погони за «многоязычностью» как самоцелью, стоит задуматься о принципиальной возможности адекватного переноса культурных нюансов и эмоциональной выразительности между языками. Понятность — это вежливость, и в данном контексте она означает признание границ собственного понимания. Оптимизация задержки синтеза важна, но истинное совершенство заключается в способности системы умолчать, когда ей нечего сказать.
Истинным вызовом является не создание «искусственного голоса», а понимание того, что делает голос голосом. И в этом смысле, текущая работа — это лишь еще один шаг на пути к осознанию собственной неполноты.
Оригинал статьи: https://arxiv.org/pdf/2601.15621.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Квантовый скачок в обработке радиоастрономических данных
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Ранжирование как разумный поиск: новая эра оптимизации
- Текстуры обмана: Как взломать ИИ, управляющий роботами
2026-01-23 07:08