Автор: Денис Аветисян
Исследователи представили VIOLA — систему, позволяющую быстро и эффективно обучать модели понимать видео нового типа, используя минимальное количество размеченных данных.

VIOLA использует стратегическое сочетание экспертной разметки и автоматически генерируемых псевдо-меток, основанное на уверенности и многообразных примерах, для адаптации больших мультимодальных моделей к новым видеодоменам.
Несмотря на успехи мультимодальных больших языковых моделей, их адаптация к новым видеодоменам затруднена из-за нехватки размеченных данных. В данной работе представлена система VIOLA («Video In-cOntext Learning with minimal Annotation») — фреймворк, эффективно сочетающий ограниченный объем экспертных аннотаций с большим количеством псевдо-меток, используя взвешенную выборку и оценку достоверности. Эксперименты на девяти различных бенчмарках с четырьмя MLLM показали, что предложенный подход значительно превосходит существующие методы в условиях ограниченных ресурсов. Возможно ли дальнейшее повышение эффективности адаптации моделей за счет более тонкой оценки и фильтрации псевдо-меток, а также интеграции дополнительных источников информации?
Вызов эффективности данных в видеоаналитике
Традиционные методы обучения с учителем в области видеоаналитики требуют колоссальных объемов размеченных данных, что существенно ограничивает их практическое применение. Создание таких наборов данных — трудоемкий и дорогостоящий процесс, поскольку каждое видео должно быть внимательно проанализировано и аннотировано специалистами. Необходимость ручной разметки каждого кадра или ключевого события в видеопотоке требует значительных временных и финансовых ресурсов, что делает разработку и внедрение систем видеоанализа сложной задачей, особенно для нишевых или быстро меняющихся сценариев. В результате, многие перспективные идеи в области видео ИИ остаются нереализованными из-за отсутствия доступных и качественных размеченных данных.
Значительные затраты на разметку данных становятся серьезным препятствием для широкого внедрения видеоаналитики в различных сферах применения. Процесс ручной аннотации видео, требующий от специалистов детальной маркировки объектов и действий в каждом кадре, не только требует значительных временных ресурсов, но и является дорогостоящим. Это особенно актуально для сложных сценариев, таких как анализ поведения в толпе или мониторинг производственных процессов, где требуется высокая точность и детальность разметки. В результате, многие перспективные проекты в области видеоаналитики сталкиваются с финансовыми и логистическими трудностями, что ограничивает их масштабируемость и практическую реализацию. Поэтому разработка методов, позволяющих снизить зависимость от больших объемов размеченных данных, является ключевой задачей для дальнейшего развития этой области.
Существующие методы искусственного интеллекта для обработки видео часто демонстрируют ограниченную способность к адаптации к новым, ранее не встречавшимся ситуациям. Это связано с тем, что модели, обученные на конкретном наборе данных, испытывают значительные трудности при обработке видеопотоков, отличающихся по условиям съемки, освещению или содержанию. Для обеспечения корректной работы в новых сценариях требуется существенная переподготовка модели, что связано со значительными вычислительными затратами и необходимостью получения новых размеченных данных. Такая потребность в постоянной перенастройке существенно ограничивает практическое применение видео ИИ в динамичных и непредсказуемых условиях, таких как автономное вождение или системы видеонаблюдения, где требуется надежная работа в различных ситуациях.
Контекстное обучение: новый подход к видеоаналитике
Метод обучения с учетом контекста (In-Context Learning, ICL) представляет собой перспективную альтернативу традиционному обучению с учителем. В отличие от последнего, требующего масштабной разметки данных и переобучения модели для каждой новой задачи, ICL позволяет адаптировать модель к новым задачам, предоставляя ей небольшое количество примеров — демонстраций — непосредственно в процессе инференса. Модель, обученная на большом объеме данных, использует эти примеры для понимания контекста задачи и генерации соответствующих результатов без изменения весов модели. Это значительно сокращает время и ресурсы, необходимые для адаптации к новым требованиям и сценариям использования.
Применение контекстного обучения (In-Context Learning, ICL) к видеоаналитике опирается на возможности крупных мультимодальных моделей, способных одновременно обрабатывать визуальную и текстовую информацию. Эти модели, обученные на обширных наборах данных, содержащих как видеопоследовательности, так и соответствующие текстовые описания, позволяют эффективно извлекать и комбинировать признаки из обоих источников. В результате, модель способна понимать не только что происходит в видео, но и как это связано с текстовым контекстом, что существенно повышает точность и гибкость анализа видеоданных без необходимости переобучения модели для каждой новой задачи.
Эффективность обучения с подсказками (In-Context Learning, ICL) в задачах анализа видео напрямую зависит от тщательного отбора и представления демонстрационных примеров. Качество и релевантность этих примеров оказывают существенное влияние на способность модели обобщать и правильно выполнять новые задачи. Неправильно подобранные примеры могут привести к снижению точности, непредсказуемым результатам или даже к полной неспособности модели адаптироваться. Оптимальное количество примеров также является критическим фактором; недостаточное количество может не обеспечить достаточной информации для обучения, а избыточное — привести к перегрузке модели и снижению производительности. Важным аспектом является и порядок представления примеров, поскольку модели могут демонстрировать повышенную чувствительность к последовательности обучения.
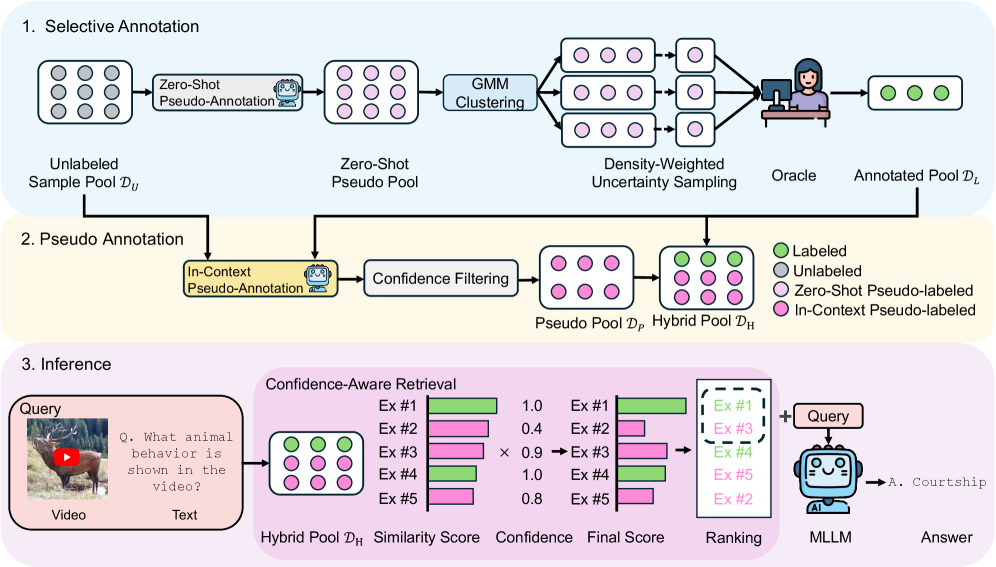
VIOLA: Эффективный отбор демонстраций и псевдо-аннотации
VIOLA — это новый фреймворк, разработанный для повышения эффективности обучения с подкреплением в видеоданных (In-Context Learning). Он объединяет в себе методы селективной и псевдо-аннотации для оптимизации процесса обучения. Селективная аннотация позволяет приоритизировать разметку наиболее информативных видеофрагментов, снижая общую нагрузку на разметчиков. Псевдо-аннотация, в свою очередь, использует обученную модель для автоматической генерации меток для неразмеченных данных, что позволяет увеличить размер обучающей выборки без дополнительных затрат на ручную разметку. Комбинация этих двух подходов направлена на повышение точности и снижение вычислительных затрат при обучении моделей для анализа видеоданных.
Селективная аннотация в рамках VIOLA использует Гауссовскую смесь моделей (Gaussian Mixture Model, GMM) для определения наиболее информативных выборок видеоданных, требующих ручной разметки. GMM оценивает плотность распределения признаков видео, выделяя образцы с высокой неопределенностью или диссонансом с существующим распределением. Приоритезация разметки именно этих выборок позволяет значительно снизить общий объем необходимой аннотации, поскольку модель получает максимальную информацию от каждого размеченного примера, эффективно уменьшая нагрузку на процесс ручной разметки и повышая эффективность обучения.
Псевдо-разметка в рамках VIOLA использует обученную модель для автоматической генерации меток для неразмеченных данных, что позволяет существенно расширить обучающую выборку. Этот процесс позволяет модели самостоятельно предсказывать метки для новых примеров, которые затем добавляются в набор данных для дальнейшего обучения. Такой подход снижает потребность в ручной разметке, сохраняя при этом объем данных, используемых для обучения, и потенциально повышая обобщающую способность модели.
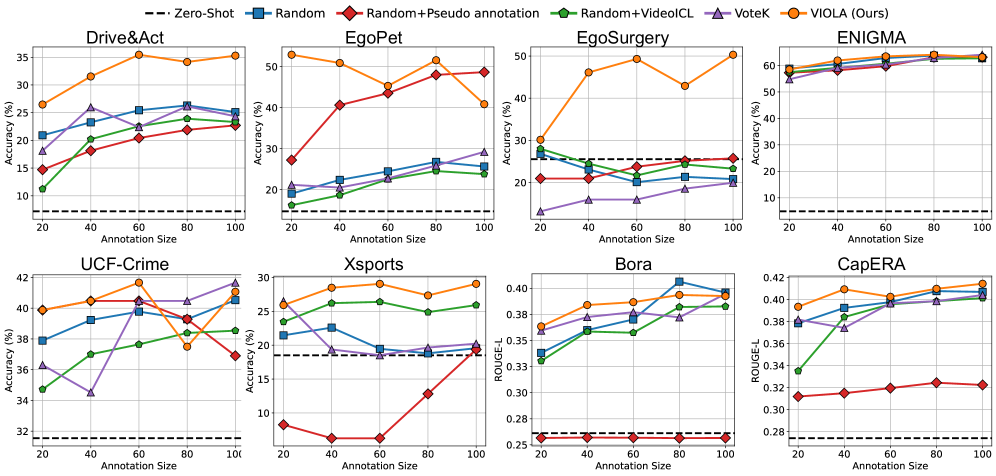
Применение методов выбора данных и промптинга, учитывающих уверенность модели, позволило добиться прироста точности в 10.3% на наборе данных Drive&Act. В рамках тестирования на бенчмарке EgoPet с использованием модели Qwen2-VL-7B, предложенный подход продемонстрировал увеличение точности до 40.0%. Данные результаты подтверждают эффективность разработанных техник в задачах видео In-Context Learning и свидетельствуют о значительном улучшении производительности модели при использовании ограниченного объема размеченных данных.
Расширение возможностей видео-ИИ: адаптация к домену и эгоцентричные виды
В основе системы VIOLA лежит эффективная стратегия обучения, позволяющая моделям, изначально подготовленным на одном наборе данных, успешно адаптироваться к совершенно новым условиям и средам. Этот подход к доменной адаптации значительно расширяет возможности применения видео-ИИ, поскольку избавляет от необходимости полной переподготовки модели при смене обстановки или типа данных. Вместо этого, VIOLA использует механизмы, позволяющие ей быстро извлекать полезную информацию из незнакомых видеопотоков и применять накопленные знания для точного анализа и интерпретации происходящего. Такая гибкость особенно ценна в динамичных и непредсказуемых реальных сценариях, где стандартные модели часто сталкиваются с трудностями.
Особое преимущество разработанной системы проявляется в задачах, связанных с видео от первого лица, так называемыми «эгоцентричными» видео. Это открывает широкие возможности для распознавания действий, выполняемых человеком, и, как следствие, для создания интеллектуальных систем помощи, в том числе в робототехнике. Благодаря способности эффективно анализировать видеопоток, зафиксированный с точки зрения оператора, система способна понимать контекст и предсказывать действия, что критически важно для надежной работы роботов-помощников и систем поддержки в реальном времени. Перспективные направления включают в себя автоматическое документирование рабочих процессов, обучение роботов выполнению задач путем демонстрации и создание более интуитивно понятных интерфейсов взаимодействия человека и машины.
Разработка VIOLA значительно упрощает внедрение видео-ИИ в практические приложения, существенно снижая потребность в трудоемкой и дорогостоящей переподготовке моделей. Традиционно, адаптация алгоритмов компьютерного зрения к новым условиям или специфическим задачам требовала обширных наборов данных и значительных вычислительных ресурсов. Однако, благодаря эффективной стратегии обучения, VIOLA позволяет использовать модели, обученные на одном наборе данных, в совершенно новых средах без необходимости полной перенастройки. Это открывает возможности для широкого спектра применений, особенно в задачах, связанных с видео от первого лица, таких как распознавание действий и помощь в роботизированных системах, делая передовые технологии видео-ИИ более доступными и экономичными для различных отраслей и разработчиков.
В ходе экспериментов разработанная система продемонстрировала улучшенные результаты в задаче автоматического создания текстовых описаний для видео. При оценке на наборе данных Bora с использованием модели Qwen2-VL, система достигла показателя ROUGE-L, равного 0.365. Это превосходит базовый уровень производительности в 0.338, что свидетельствует о значительном прогрессе в точности и информативности генерируемых описаний. Повышение метрики ROUGE-L указывает на улучшенное соответствие между сгенерированным текстом и эталонными описаниями, что особенно важно для приложений, требующих высокого уровня понимания видеоконтента.
Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных к адаптации и обучению на ограниченном объеме размеченных данных. Использование псевдо-меток в сочетании с экспертной разметкой, как реализовано в VIOLA, позволяет эффективно использовать неразмеченные данные для улучшения понимания видео. Это согласуется с убеждением, что истинное понимание системы проявляется в способности выявлять и воспроизводить закономерности, даже при недостатке информации. Как однажды заметил Джеффри Хинтон: «Я думаю, что мы находимся в начале очень большой волны». Данное утверждение подчеркивает потенциал развития систем, способных к самообучению и адаптации, что особенно актуально в контексте мультимодальных больших языковых моделей и видео-аналитики. Если закономерность нельзя воспроизвести или объяснить, её не существует.
Что дальше?
Представленный подход, позволяющий адаптировать большие мультимодальные модели к новым видеодоменам с минимальным объёмом аннотаций, открывает интересные перспективы. Однако, необходимо помнить: кажущаяся простота часто скрывает подводные камни. Эффективность VIOLA напрямую зависит от качества псевдо-меток, и тщательная проверка границ данных, чтобы избежать ложных закономерностей, представляется критически важной. Необходимо более глубокое исследование влияния различных стратегий отбора псевдо-меток и их сочетания с экспертными аннотациями.
Очевидным направлением дальнейших исследований является расширение области применения данного подхода за пределы текущих видеодоменов. Попытки адаптации модели к более сложным задачам, требующим понимания нюансов и контекста, могут выявить её ограничения. Стоит также рассмотреть возможность использования альтернативных методов оценки достоверности псевдо-меток, включая, например, байесовские подходы или методы активного обучения.
В конечном счете, настоящая ценность подобных работ заключается не в достижении абсолютной точности, а в понимании принципов, лежащих в основе адаптации моделей к новым данным. Разработка более универсальных и эффективных методов, позволяющих извлекать максимум информации из ограниченного объема аннотаций, остаётся ключевой задачей в области видеоанализа.
Оригинал статьи: https://arxiv.org/pdf/2601.15549.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-23 10:32