Автор: Денис Аветисян
Исследователи разработали метод, позволяющий представлять изображения и маски в виде текстовых токенов, открывая новые возможности для взаимодействия моделей искусственного интеллекта с визуальным миром.

SAMTok: дискретное представление масок для повышения эффективности многомодальных языковых моделей.
Несмотря на значительный прогресс в области мультимодальных больших языковых моделей, достижение пиксельной точности в задачах понимания изображений остается сложной задачей. В данной работе, озаглавленной ‘SAMTok: Representing Any Mask with Two Words’, представлен новый подход к токенизации масок, позволяющий представить любую область изображения всего двумя специальными токенами. Это позволяет обучать базовые мультимодальные модели, такие как QwenVL, пиксельному пониманию посредством стандартного предсказания следующего токена и обучения с подкреплением, без изменения архитектуры и специализированных функций потерь. Не откроет ли этот простой и масштабируемый метод новые возможности для взаимодействия с изображениями и решения сложных задач компьютерного зрения?
Разгадывая визуальный шепот: от пикселей к пониманию
Современные мультимодальные большие языковые модели (MLLM) зачастую испытывают трудности с детальным анализом визуальной информации, воспринимая изображения как единое целое, а не как совокупность отдельных элементов. Вместо того чтобы выделять и интерпретировать конкретные объекты или их характеристики, модели склонны к обобщениям, что снижает точность ответов на вопросы, требующие понимания нюансов изображения. Данный подход ограничивает возможности MLLM в задачах, требующих точного визуального рассуждения, таких как описание конкретных деталей на фотографии или ответы на вопросы о местоположении определенных объектов. По сути, модели оперируют скорее общим впечатлением от изображения, чем его фактическим содержанием, что создает барьер для достижения подлинного мультимодального интеллекта.
Существующие подходы к обработке изображений в контексте мультимодальных больших языковых моделей часто оказываются неспособны к детальному анализу отдельных областей на картинке. Вместо того чтобы понимать изображение как совокупность конкретных элементов, они склонны воспринимать его как единое целое, что ограничивает возможности точного взаимодействия и осмысленного ответа на вопросы, связанные с определенными частями изображения. Это затрудняет выполнение задач, требующих локализованного понимания, например, идентификацию конкретного объекта в перегруженной сцене или точное описание изменений в определенной области изображения, поскольку модели не могут эффективно «привязать» языковые описания к конкретным пикселям или регионам визуального пространства.
Для эффективного сопоставления языка и визуальной информации необходим механизм, способный представлять и обрабатывать данные на уровне отдельных пикселей. Существующие модели часто воспринимают изображения как единое целое, упуская важные детали и контекст, заключенные в конкретных областях. Способность анализировать изображение попиксельно позволяет установить более точную связь между языковым описанием и визуальным представлением, что критически важно для задач, требующих детального понимания сцены. Такой подход открывает возможности для решения сложных задач, таких как точное определение местоположения объектов, детальное описание изображений и интерактивное взаимодействие с визуальным контентом, где понимание даже мельчайших деталей играет ключевую роль.

SAMTok: Превращая визуальные маски в язык машин
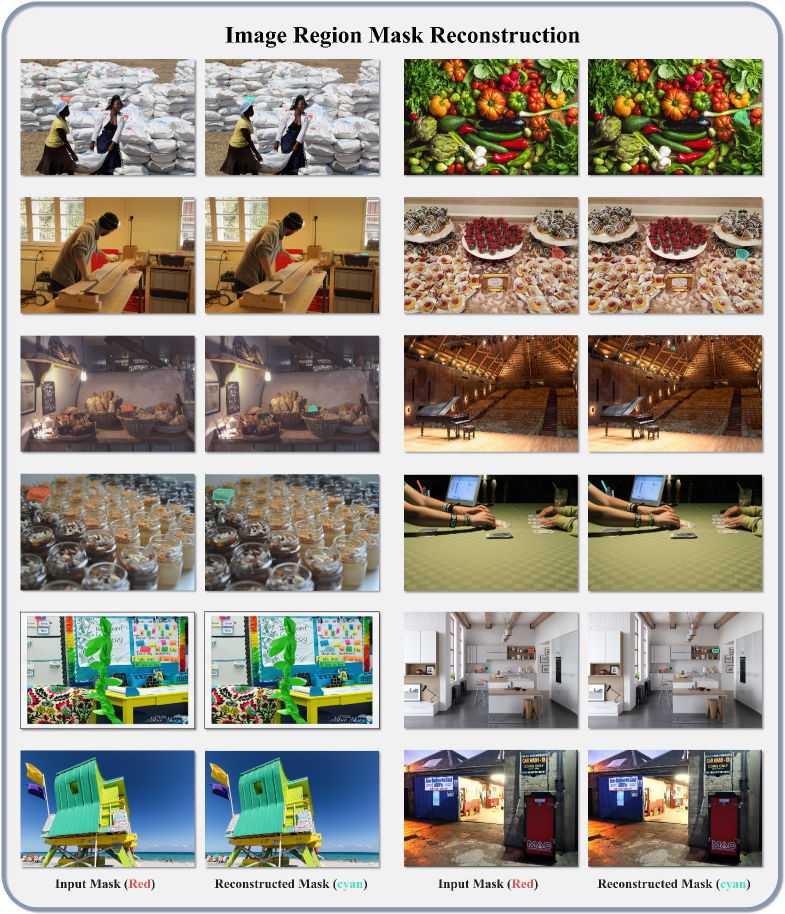
SAMTok преобразует маски сегментации областей в дискретные токены, позволяя мультимодальным большим языковым моделям (MLLM) обрабатывать информацию на уровне пикселей как текст. Этот процесс заключается в представлении масок в виде последовательности токенов, что позволяет MLLM использовать свои возможности обработки естественного языка для анализа и понимания визуального контента. Вместо работы непосредственно с пиксельными данными, модель оперирует с дискретными представлениями, что значительно упрощает обработку и снижает вычислительные затраты, сохраняя при этом важную информацию о форме и расположении объектов на изображении.
Процесс кодирования масок в SAMTok использует методы векторной квантизации и остаточной квантизации для достижения эффективного и высокоточного сжатия векторных представлений масок. Векторная квантизация позволяет отобразить непрерывные векторы признаков масок в дискретные коды, сокращая объем данных, необходимых для их представления. Для повышения точности, применяется остаточная квантизация, кодирующая разницу между исходным вектором и его квантованным представлением. Комбинация этих методов обеспечивает сжатие данных с минимальной потерей информации о структуре и деталях маски, что критически важно для последующей обработки мультимодальными языковыми моделями.
SAMTok использует архитектуру энкодера-декодера, основанную на сегментационной модели SAM2, для эффективного захвата пространственных взаимосвязей в масках сегментации. Энкодер преобразует входную маску в компактное векторное представление, сохраняя при этом информацию о расположении и форме объектов. Декодер, в свою очередь, восстанавливает маску из этого векторного представления, обеспечивая высокую точность реконструкции. Такая структура позволяет модели учитывать контекст и взаимосвязи между различными сегментами изображения, что критически важно для точного визуального понимания.
Дискретное масковое представление, созданное SAMTok, позволяет мультимодальным большим языковым моделям (MLLM) воспринимать изображения с большей детализацией. Вместо обработки изображений как единого целого или через ограниченное количество bounding boxes, MLLM получают доступ к информации о сегментированных областях на уровне пикселей, представленных в виде дискретных токенов. Это позволяет моделям не только идентифицировать объекты, но и точно определять их границы и взаиморасположение, что существенно повышает точность задач визуального понимания, таких как визуальный вопрос-ответ и описание изображений. Использование дискретных токенов также обеспечивает более эффективную обработку и хранение информации о масках по сравнению с исходными пиксельными данными.
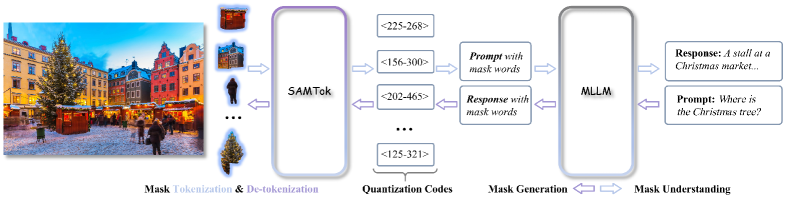
Обучение и валидация: от SFT к обучению с подкреплением
Для инициализации модели QwenVL и обеспечения базового соответствия между масками и текстом используется обучение с учителем (Supervised Fine-Tuning, SFT). В рамках SFT модель подвергается тонкой настройке на размеченных данных, что позволяет ей научиться предсказывать текстовые описания соответствующих маскированных областей на изображениях. Этот этап необходим для формирования начальных знаний о взаимосвязи между визуальным контентом и текстовыми представлениями, прежде чем переходить к более сложным методам обучения, таким как обучение с подкреплением.
В качестве основной цели обучения используется функция потерь Next-Token Prediction Loss, при которой маскированные токены обрабатываются аналогично обычным текстовым токенам. Такой подход позволяет объединить процесс обучения, упрощая оптимизацию и повышая эффективность модели. Вместо раздельной обработки маскированных областей, модель обучается предсказывать следующий токен в последовательности, независимо от того, является ли он частью маски или исходного текста. Это способствует более целостному пониманию взаимосвязи между визуальным контентом и текстовыми описаниями, что приводит к улучшению качества генерируемых масок и повышению точности модели в целом.
Для дальнейшей оптимизации генерации масок используется обучение с подкреплением (RL) с функцией вознаграждения, основанной на сопоставлении текстовых ответов. Этот подход предполагает, что модель получает положительное вознаграждение, если сгенерированная маска соответствует текстовому описанию визуального контента, и отрицательное — в противном случае. Функция вознаграждения вычисляется на основе метрик соответствия между предсказанной маской и референсным текстовым ответом, что позволяет модели научиться генерировать более точные и релевантные маски для заданных визуальных входных данных. Процесс обучения с подкреплением дополняет предварительное обучение с учителем (SFT) и направлен на улучшение качества генерируемых масок, особенно в сложных сценариях.
Оценка точности генерируемых масок при использовании предложенного подхода демонстрирует значительное улучшение показателей на валидационном наборе данных GRES. В частности, наблюдается увеличение метрики gIoU (Generalized Intersection over Union) до 8.9%, что свидетельствует о более точном совпадении предсказанных масок с реальными объектами на изображениях. Кроме того, точность классификации (N-acc) улучшается на 21.0%, подтверждая способность модели корректно идентифицировать и выделять целевые области на визуальном контенте. Полученные результаты указывают на эффективность применяемого метода в задаче генерации масок, обеспечивая высокую степень соответствия между предсказаниями модели и визуальными данными.
Расширяя горизонты: к обоснованному пониманию сцены
SAMTok представляет собой новую систему, позволяющую мультимодальным большим языковым моделям (MLLM) не только выделять объекты на изображении, но и понимать их взаимосвязи в рамках общей сцены. Вместо простого определения границ объектов, система строит так называемый «Панорамный Граф Сцены» — детальное представление, описывающее каждый объект и его отношения с другими элементами изображения. Это позволяет модели не просто «видеть» отдельные предметы, но и «понимать» контекст, что значительно повышает точность и осмысленность взаимодействия с визуальной информацией. Благодаря такому подходу, MLLM получает возможность отвечать на более сложные вопросы, касающиеся сцены, и выполнять более точные действия на основе визуального анализа.
Система SAMTok обеспечивает более точное и контекстуально-осмысленное взаимодействие с визуальной информацией за счет эффективного сопоставления языка и визуальных деталей. Вместо простой идентификации объектов, SAMTok позволяет учитывать их взаимосвязи и окружение, что приводит к более глубокому пониманию сцены. Это достигается благодаря возможности системы не только сегментировать объекты, но и выстраивать граф панорамной сцены, отражающий пространственные и семантические отношения между ними. Такой подход значительно повышает точность ответов на вопросы о визуальном контенте и открывает новые возможности для задач, требующих детального анализа изображения и понимания контекста, таких как редактирование изображений или управление роботами в реальном времени.
Создание точных и детализированных масок открывает новые перспективы в различных областях. В частности, это позволяет значительно улучшить инструменты для редактирования изображений, обеспечивая более тонкую и точную работу с отдельными объектами и их деталями. В сфере визуальных вопросов и ответов, подобные маски позволяют моделям не только идентифицировать объекты, но и понимать их границы и взаимосвязи, что повышает точность и релевантность ответов. Не менее значимо это и для робототехники, где точное определение границ объектов необходимо для манипулирования ими в реальном времени, обеспечивая более эффективное и безопасное взаимодействие робота с окружающей средой. Благодаря этому, становится возможным создание более интеллектуальных систем, способных к сложным задачам, требующим детального понимания визуальной информации.
Новая модель SAMTok демонстрирует значительный прогресс в области понимания сцен и взаимодействия с визуальной информацией. В ходе сравнительных тестов на стандартных бенчмарках GRES, SAMTok превзошла существующие решения, достигнув увеличения показателя AP50 на 4.3% и повышения точности Recall на 8.4%. Особенно заметно улучшение в задачах, требующих последовательного взаимодействия с изображением, где средний прирост эффективности на наборе данных MR-RefCOCO/+/g составил 7.7% на протяжении всех раундов взаимодействия. Эти результаты подтверждают, что SAMTok способна более эффективно анализировать и интерпретировать визуальные сцены, что открывает новые возможности для применения в различных областях, включая редактирование изображений, ответы на вопросы по визуальному контенту и управление роботами.

Исследование предлагает интересный подход к представлению масок в виде дискретных текстовых токенов, что напоминает древнее искусство алхимии — попытку преобразовать хаотичные формы в упорядоченные символы. Как будто авторы пытаются уговорить визуальные данные заговорить на языке моделей. Эту идею можно соотнести с высказыванием Эндрю Ына: «Мы приближаемся к точке, когда мы сможем создавать машины, которые могут учиться так же, как люди». В данном случае, обучение происходит не на пикселях напрямую, а на их дискретных представлениях, что значительно упрощает задачу для многомодальных моделей и открывает новые возможности в понимании и генерации визуальных образов. Модель, обученная таким образом, словно обретает способность видеть сквозь шум, выделяя суть.
Куда же дальше?
Предложенный метод, SAMTok, подобен алхимическому перегону: он трансформирует хаос пикселей в дискретные символы, удобоваримые для цифрового голема. Однако, даже самое изящное заклинание имеет свои пределы. Упрощение маски до двух слов — это, безусловно, шаг к управлению сложностью, но не стоит забывать о потерях. Каждая дискретизация — священная жертва точности, и вопрос в том, насколько велика эта жертва в различных задачах. Будущие исследования должны сосредоточиться на оценке этих потерь и, возможно, на поиске способов их смягчения, не жертвуя при этом элегантностью представления.
Наиболее интригующим направлением представляется исследование границ дискретизации. Возможно ли создать токенизатор, который сможет адаптироваться к сложности маски, используя больше, чем два слова, но при этом сохраняя вычислительную эффективность? Или, напротив, стоит поискать способы сжать информацию ещё сильнее, отказавшись от пиксельной точности в пользу более абстрактных представлений? Задача не в том, чтобы идеально воссоздать маску, а в том, чтобы создать достаточное представление для выполнения конкретной задачи.
В конечном счёте, SAMTok — это лишь ещё один инструмент в арсенале тех, кто пытается обуздать хаос визуального мира. И, как и любой инструмент, он эффективен лишь до тех пор, пока не столкнётся с новой, непредсказуемой реальностью. Будущее этого направления лежит в постоянном поиске новых способов представления, адаптации и, конечно же, в смирении перед неизбежной неточностью любого цифрового заклинания.
Оригинал статьи: https://arxiv.org/pdf/2601.16093.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Квантовый скачок в обработке радиоастрономических данных
- Память для разума: Архитектура коллективного интеллекта
- Экзотические разложения: новые грани цилиндрической алгебры
- Командная работа агентов: обучение без обновления модели
2026-01-23 13:57