Автор: Денис Аветисян
Исследователи представили EvoCUA — систему, позволяющую создавать интеллектуальных агентов для автоматизации работы с компьютером, используя синтетические данные и интерактивные сценарии.
EvoCUA превосходит существующие модели благодаря новому методу обучения с использованием верифицируемых наград и масштабируемых синтетических данных.
Ограниченность статических наборов данных является серьезным препятствием для развития автономных агентов, способных эффективно взаимодействовать с компьютерными системами. В данной работе, ‘EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience’, представлен новый подход к обучению таких агентов, основанный на интеграции автоматической генерации данных, интерактивных прогонов и верифицируемых вознаграждениях. Разработанная система EvoCUA достигает передового результата в 56.7% на бенчмарке OSWorld, значительно превосходя существующие модели с открытым исходным кодом и сравнимые закрытые системы. Сможет ли эволюционный подход к обучению, основанный на генерации опыта, стать надежным путем к созданию действительно автономных и универсальных компьютерных агентов?
Пределы Конвенционального Искусственного Интеллекта
Современные системы искусственного интеллекта зачастую демонстрируют трудности при решении задач, требующих последовательного выполнения нескольких этапов и развитых навыков логического мышления. Несмотря на впечатляющие успехи в узкоспециализированных областях, сложные сценарии, предполагающие планирование, адаптацию к меняющимся условиям и экстраполяцию знаний, представляют значительную проблему. Это связано с тем, что большинство текущих моделей, хоть и способны к распознаванию закономерностей в больших объемах данных, не обладают способностью к полноценному дедуктивному или индуктивному мышлению, что ограничивает их возможности в ситуациях, требующих не просто анализа, но и построения логической цепочки действий для достижения поставленной цели. В результате, даже относительно простые для человека задачи могут оказаться непосильными для современных ИИ-агентов, подчеркивая необходимость разработки принципиально новых подходов к созданию интеллектуальных систем.
Современные подходы к развитию искусственного интеллекта часто делают ставку на увеличение числа параметров модели, стремясь к повышению производительности за счет грубой силы. Однако, подобное масштабирование оказывается не только чрезвычайно затратным в вычислительном плане, требуя огромных ресурсов и энергии, но и неэффективным с точки зрения реального прогресса. Увеличение параметров не всегда приводит к пропорциональному улучшению способности модели к обобщению и решению сложных задач, а также часто усугубляет проблему переобучения. Данный подход становится все более проблематичным, поскольку кривая зависимости производительности от количества параметров демонстрирует тенденцию к замедлению, указывая на необходимость поиска альтернативных стратегий, фокусирующихся на более эффективных алгоритмах и архитектурах, а не на простом увеличении масштаба.
Ограничения современных искусственных интеллектов существенно замедляют создание агентов, способных к полноценному пониманию и взаимодействию со сложными средами. Неспособность эффективно обобщать знания и применять их в новых, непредсказуемых ситуациях приводит к тому, что даже самые мощные модели демонстрируют хрупкость и непредсказуемость в реальных условиях. Например, агент может успешно выполнять задачу в симулированной среде, но потерпеть неудачу при столкновении с незначительными отклонениями в реальном мире. Это связано с тем, что существующие системы часто полагаются на распознавание паттернов в больших объемах данных, а не на глубокое понимание принципов, управляющих окружающей средой. В результате, развитие действительно интеллектуальных агентов требует выхода за рамки простого увеличения вычислительных мощностей и поиска новых подходов к моделированию когнитивных способностей, таких как абстрактное мышление, планирование и адаптация.
EvoCUA: Эволюционирующий Агент для Работы с Компьютером
EvoCUA — это программный агент, предназначенный для взаимодействия с компьютером, функционирующий на основе принципов эволюционного обучения посредством накопления опыта. В отличие от традиционных систем, основанных на заранее заданных правилах или статичных моделях, EvoCUA адаптируется и совершенствуется в процессе работы, анализируя результаты своих действий и оптимизируя стратегии. Данный подход позволяет агенту решать широкий спектр задач, включая автоматизацию рутинных операций, помощь в выполнении сложных действий и адаптацию к изменяющимся условиям использования компьютера, без необходимости явного программирования каждого сценария. Архитектура EvoCUA ориентирована на постоянное обучение и самосовершенствование в реальной среде.
Агент EvoCUA использует в качестве основы визуальную языковую модель Qwen3-VL, что позволяет ему обрабатывать и понимать визуальную информацию в сочетании с текстовыми инструкциями. Для эффективного обучения и адаптации к различным задачам, EvoCUA требует масштабируемой инфраструктуры взаимодействия, обеспечивающей проведение обширных тренировочных сессий и сбор данных о производительности. Такая инфраструктура необходима для обработки большого объема данных, необходимого для обучения модели, а также для обеспечения возможности проведения экспериментов и улучшения алгоритмов обучения.
Ключевым компонентом системы EvoCUA является движок верифицируемого синтеза (Verifiable Synthesis Engine), предназначенный для решения проблемы нехватки данных для обучения. Движок генерирует синтетические данные, имитирующие реальное взаимодействие пользователя с компьютером, и присваивает этим данным верифицируемые награды. Верификация награды осуществляется посредством встроенных механизмов оценки, гарантирующих соответствие синтетических данных желаемым критериям и целям обучения. Использование синтетических данных позволяет значительно увеличить объем обучающей выборки, особенно в ситуациях, когда получение реальных данных затруднено или невозможно, тем самым повышая эффективность и надежность работы агента EvoCUA.
Оптимизация Рассуждений посредством Уточнения Политики на Уровне Шага
EvoCUA обучается с использованием Direct Preference Optimization (DPO), метода, являющегося расширением оптимизации политики на уровне шагов. DPO фокусируется на выявлении и исправлении ключевых ошибок в процессе рассуждений. В отличие от традиционных методов обучения с подкреплением, DPO напрямую оптимизирует политику агента на основе предпочтений, полученных от сравнения различных траекторий выполнения задачи, что позволяет более эффективно устранять недостатки в логике и повышать надежность принимаемых решений. Данный подход позволяет агенту учиться на примерах ошибок, избегая необходимости ручного определения функций вознаграждения.
Метод обучения с подкреплением и проверяемыми наградами (RLVR) направлен на усиление способности агента к надежному логическому мышлению. RLVR использует систему вознаграждений, основанную на верификации промежуточных шагов решения задачи. Это означает, что агент получает награду не только за конечное решение, но и за корректность каждого этапа рассуждений, что позволяет выявлять и корректировать ошибки на ранних стадиях. Такая структура вознаграждения способствует формированию более устойчивых и обоснованных стратегий решения, особенно в сложных задачах, требующих последовательного применения логических операций.
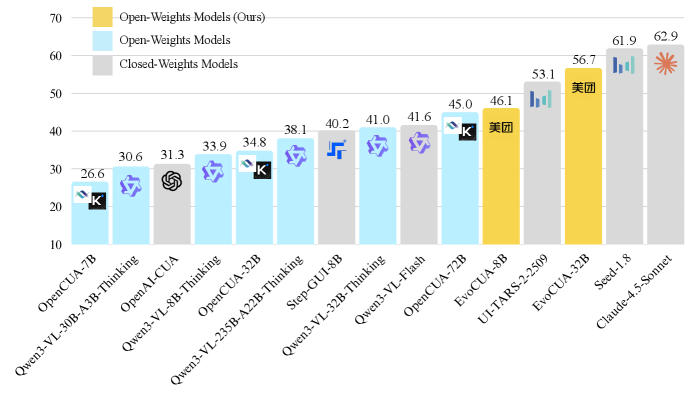
В ходе тестирования на бенчмарке OSWorld, модель EvoCUA продемонстрировала передовые результаты, достигнув показателя успешности в 56.7%. Этот результат превосходит аналогичные показатели других моделей: OpenCUA-72B (45.0%) и UI-TARS-2 (53.1%). Данные результаты подтверждают эффективность применяемых методов оптимизации, направленных на повышение надежности и точности рассуждений модели при решении сложных задач, представленных в бенчмарке OSWorld.
Декодирование «Пространства Мысли»: Визуализация Рассуждений Агента
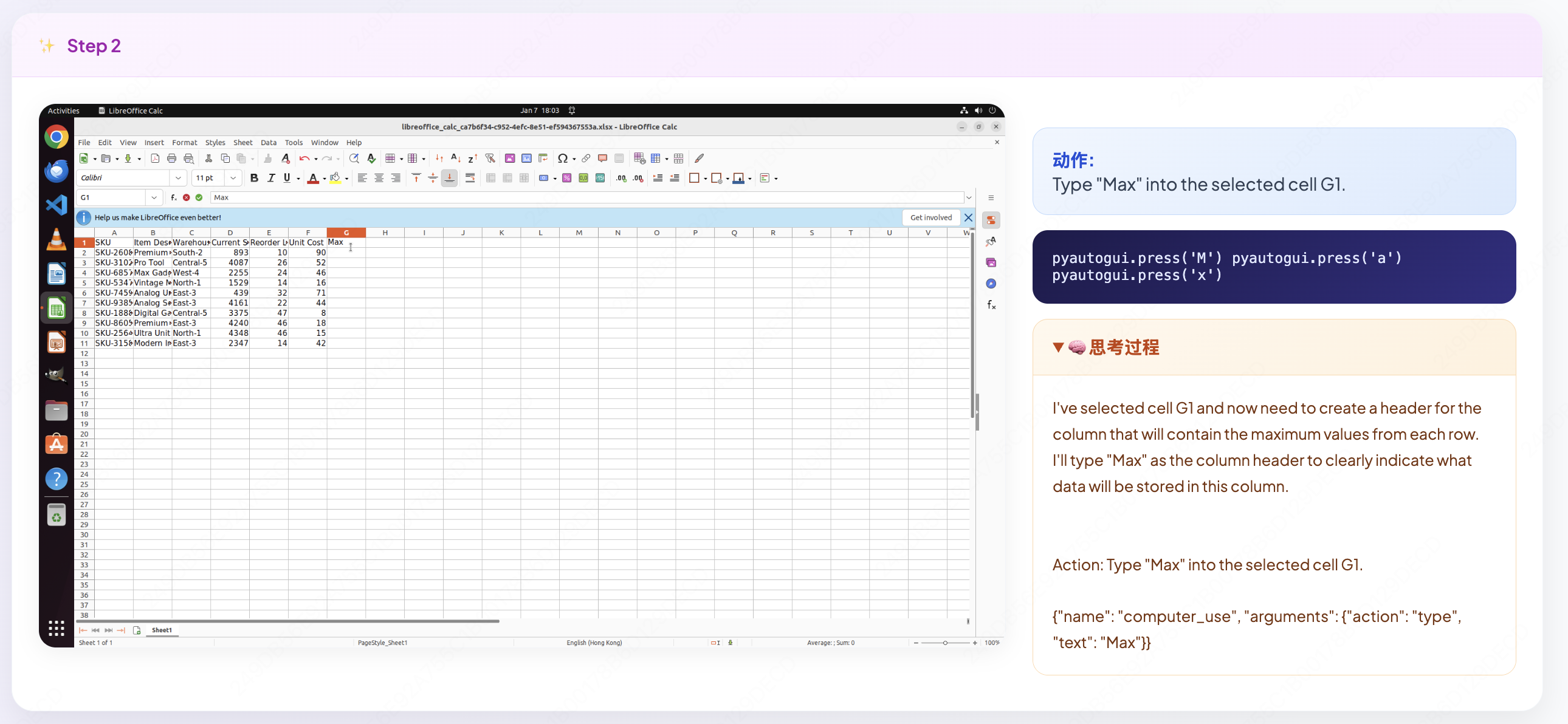
Для детального анализа процесса принятия решений агентом был разработан инструмент — Траекторный Инспектор. Он позволяет проследить за каждым шагом рассуждений и действий агента, сопоставляя их последовательно, кадр за кадром. Этот подход позволяет не просто констатировать факт совершения того или иного действия, а понять логику, лежащую в его основе — какие соображения привели к данному выбору. Инспектор предоставляет возможность визуализировать внутренний «пространство мысли» агента, выявляя ключевые этапы рассуждений и связи между ними. Такой детальный анализ открывает новые возможности для улучшения алгоритмов искусственного интеллекта и повышения прозрачности процессов принятия решений.
Метод ретроспективного анализа траекторий, известный как «Генерация рассуждений с оглядкой», позволяет значительно расширить «пространство мысли» агента. Вместо того чтобы ограничиваться текущим ходом действий, система анализирует уже пройденный путь, выявляя альтернативные варианты и оценивая их потенциальные последствия. Этот процесс, по сути, создает «мысленные эксперименты» на основе реального опыта, позволяя агенту глубже понимать причины своих решений и корректировать стратегию. Такой подход не просто фиксирует последовательность действий, но и строит причинно-следственные связи, что способствует более гибкому и эффективному принятию решений в будущем. В результате, агент получает возможность учиться не только на успешных, но и на ошибочных шагах, постоянно расширяя границы своего понимания и повышая свою адаптивность.
Исследование позволило выйти за рамки простого наблюдения за действиями EvoCUA, предоставив возможность понять логику, лежащую в основе принимаемых решений. Использование разработанных инструментов, включая Trajectory Inspector и Hindsight Reasoning Generation, позволило не только проанализировать последовательность шагов, но и реконструировать ход мыслей агента. Результаты показали улучшение производительности на 11.7% по сравнению с OpenCUA-72B, что свидетельствует о значительном прогрессе в понимании и оптимизации процессов принятия решений. Более того, достигнутый уровень производительности сопоставим с показателями ведущих коммерческих агентов, что подтверждает перспективность предложенного подхода к визуализации и анализу рассуждений искусственного интеллекта.
Взгляд в Будущее: К Универсальным Агентам Рассуждения
Исследование продемонстрировало значительный потенциал эволюционирующих агентов в достижении превосходных результатов при решении сложных задач. Вместо традиционных методов, основанных на заранее заданных алгоритмах, данный подход позволяет агентам адаптироваться и совершенствоваться в процессе взаимодействия со средой. Этот процесс эволюции, имитирующий принципы естественного отбора, приводит к появлению стратегий, превосходящих те, что были бы разработаны вручную. Наблюдаемая эффективность эволюционирующих агентов указывает на перспективность данного направления для создания систем искусственного интеллекта, способных к гибкому и эффективному решению широкого спектра проблем, требующих адаптации и обучения.
Дальнейшие исследования направлены на расширение возможностей разработанных методов и их применение в более сложных областях, требующих продвинутого рассуждения. Особое внимание будет уделено масштабированию текущих подходов, чтобы обеспечить эффективную работу в условиях возрастающей сложности задач. Параллельно изучаются альтернативные алгоритмы оптимизации, в частности, алгоритм GRPO (Gradient-based Recursive Policy Optimization), который потенциально может значительно улучшить скорость обучения и стабильность агентов, позволяя им осваивать новые навыки и адаптироваться к изменяющимся условиям среды с большей эффективностью. Это позволит создать универсальных агентов, способных решать широкий спектр задач, требующих не только выполнения инструкций, но и самостоятельного анализа ситуации и принятия обоснованных решений.
Результаты экспериментов демонстрируют впечатляющую эффективность разработанных агентов EvoCUA. В частности, модель EvoCUA-32B достигла показателя успешности в 56.7%, что свидетельствует о ее способности успешно решать сложные задачи. Особо примечательно, что EvoCUA-8B превзошла по своим характеристикам специализированные модели, содержащие 72 миллиарда параметров, что подчеркивает исключительную эффективность и масштабируемость предложенного подхода. Такое соотношение между размером модели и достигнутой производительностью открывает новые перспективы для создания более компактных и ресурсоэффективных систем искусственного интеллекта, способных к сложному рассуждению.
Исследование, представленное в данной работе, демонстрирует эволюцию агентов автоматизации GUI посредством обучения на масштабируемых синтетических данных. Подобный подход напоминает о фундаментальных принципах теории информации, ведь создание эффективной системы требует не просто обработки данных, а их структурирования и оптимизации для достижения определенной цели. Клод Шеннон однажды заметил: «Информация — это не движение, а выбор». В EvoCUA этот выбор происходит на этапе генерации синтетических данных и определения проверяемых вознаграждений, позволяя агенту адаптироваться к сложным задачам и превосходить существующие модели. Подобно тому, как информация кодируется и декодируется, система EvoCUA преобразует данные в действия, оптимизируя свою производительность во временной кривой.
Куда же дальше?
Представленная работа, как и любая другая, лишь одна точка на кривой угасания. EvoCUA демонстрирует впечатляющую производительность, но сама концепция «агента, использующего компьютер» неизбежно столкнется с ограничениями. Синтетические данные, будучи мощным инструментом, всегда остаются упрощением реальности, а интерактивные прогоны — лишь попыткой охватить бесконечное пространство возможностей. Вопрос не в том, насколько хорошо система справляется с текущими задачами, а в том, как быстро устареет сама парадигма автоматизации графического интерфейса.
Более глубокое исследование должно быть направлено не на оптимизацию существующих архитектур, а на поиск принципиально новых подходов к взаимодействию агента с цифровой средой. Верифицируемые награды — это, безусловно, шаг в правильном направлении, но истинная проверка — это способность системы адаптироваться к непредвиденным изменениям, к той энтропии, которая неизбежно поглощает любое программное обеспечение. Каждая архитектура проживает свою жизнь, а мы лишь свидетели её упадка.
В конечном счете, будущее не за созданием «идеального» агента, а за пониманием того, что совершенство — это иллюзия. Улучшения стареют быстрее, чем мы успеваем их понять, и истинная ценность исследования заключается в осознании этой эфемерности, в умении достойно встретить неизбежное.
Оригинал статьи: https://arxiv.org/pdf/2601.15876.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-23 15:37