Автор: Денис Аветисян
Библиотека Panther позволяет значительно сократить вычислительные затраты и объем памяти при обучении нейронных сетей, используя методы случайной численной линейной алгебры.
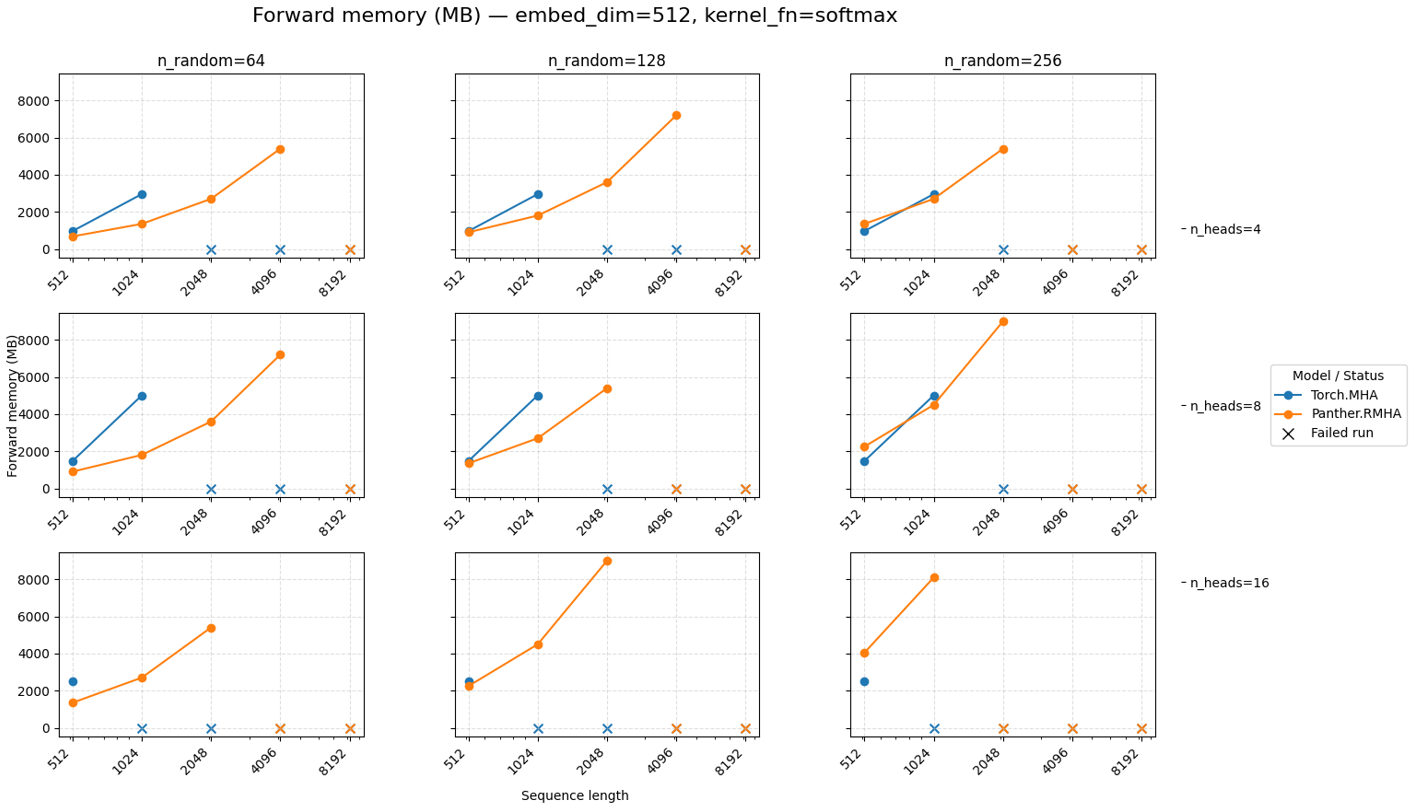
Panther — это PyTorch библиотека, реализующая методы случайной численной линейной алгебры (RandNLA) для сжатия моделей и ускорения вычислений в задачах глубокого обучения.
Ограничения по памяти и вычислительным ресурсам становятся все более серьезным препятствием при обучении современных моделей глубокого обучения. В данной работе представлена библиотека ‘Panther: Faster and Cheaper Computations with Randomized Numerical Linear Algebra’, реализующая методы рандомизированной численной линейной алгебры (RandNLA) для снижения этих ограничений. Panther обеспечивает эффективную замену стандартных компонентов, таких как линейные слои, двумерная свертка и механизм внимания, позволяя значительно сократить потребление памяти (до 75% для BERT) при сохранении сопоставимой точности. Способна ли эта библиотека стать стандартом де-факто для компрессии моделей глубокого обучения и расширить границы возможного в задачах искусственного интеллекта?
Современные вызовы линейной алгебры в машинном обучении
Современное машинное обучение в значительной степени опирается на линейную алгебру, однако традиционные методы её реализации зачастую требуют колоссальных вычислительных ресурсов и объёмов памяти. Операции, такие как умножение матриц AxB или решение систем линейных уравнений, могут стать узким местом при работе с высокоразмерными данными, особенно в контексте глубокого обучения и обработки больших данных. Традиционные алгоритмы, хотя и гарантируют высокую точность, становятся практически невыполнимыми для моделей, содержащих миллиарды параметров, и для наборов данных, насчитывающих миллионы примеров. Это стимулирует поиск более эффективных подходов, способных обеспечить приемлемую производительность при ограниченных ресурсах, что критически важно для развёртывания моделей на мобильных устройствах или в облачных средах с ограниченными вычислительными мощностями.
В современном машинном обучении наблюдается экспоненциальный рост объемов обрабатываемых данных и сложности используемых моделей. Это приводит к значительному увеличению вычислительных затрат и требований к памяти, делая традиционные методы линейной алгебры все менее эффективными. В связи с этим, возникает необходимость в исследовании и внедрении рандомизированных методов линейной алгебры. Они позволяют снизить вычислительную сложность и потребление памяти, сохраняя при этом достаточную точность вычислений. В частности, рандомизированные алгоритмы, такие как \text{RLS} (Recursive Least Squares) и методы на основе случайных проекций, предоставляют возможность приблизительно решать задачи линейной алгебры с существенно меньшими затратами, что особенно важно при работе с большими данными и сложными моделями.
Рандомизированные методы представляют собой перспективный подход к снижению вычислительных затрат в задачах машинного обучения, не приводящий к существенной потере точности. Исследования показывают, что замена традиционных алгоритмов линейной алгебры на рандомизированные позволяет существенно уменьшить размер модели — до 75% — при сохранении сравнимой производительности. Это достигается за счет использования случайных проекций и приближений, которые эффективно снижают сложность вычислений, особенно при работе с большими объемами данных. Такой подход открывает возможности для обучения и развертывания более сложных моделей на ресурсоограниченных платформах, а также для ускорения процессов обучения и предсказания, что является критически важным для современных приложений машинного обучения.
Panther: Библиотека для эффективной RandNLA в PyTorch
Panther — это библиотека, разработанная специально для интеграции методов случайной аппроксимации линейной алгебры (RandNLA) в стандартные рабочие процессы машинного обучения, построенные на базе PyTorch. Она предоставляет инструменты для использования техник, таких как скетчинг и случайное сингулярное разложение (RSVD), непосредственно в привычной среде PyTorch, без необходимости значительных изменений в существующем коде. Это достигается за счет реализации операций, совместимых с тензорами PyTorch, что позволяет бесшовно объединять RandNLA с другими слоями и функциями, используемыми в моделях машинного обучения. Основная цель Panther — упростить применение RandNLA для повышения эффективности и масштабируемости моделей.
Библиотека Panther разработана на основе PyTorch и предоставляет простой в использовании интерфейс для интеграции методов случайной линейной алгебры (RandNLA) в стандартные рабочие процессы машинного обучения. Она позволяет пользователям легко применять такие техники, как скетчинг и рандомизированное сингулярное разложение (RSVD), без необходимости глубокого понимания их внутренней реализации. Данный подход обеспечивает гибкость и упрощает эксперименты с различными RandNLA методами, позволяя исследователям и разработчикам эффективно использовать преимущества этих техник для снижения вычислительной сложности и уменьшения размера моделей, сохраняя при этом сопоставимую производительность. Интеграция с PyTorch позволяет бесшовно использовать существующие инструменты и инфраструктуру, минимизируя затраты на переход и обеспечивая совместимость с другими библиотеками машинного обучения.
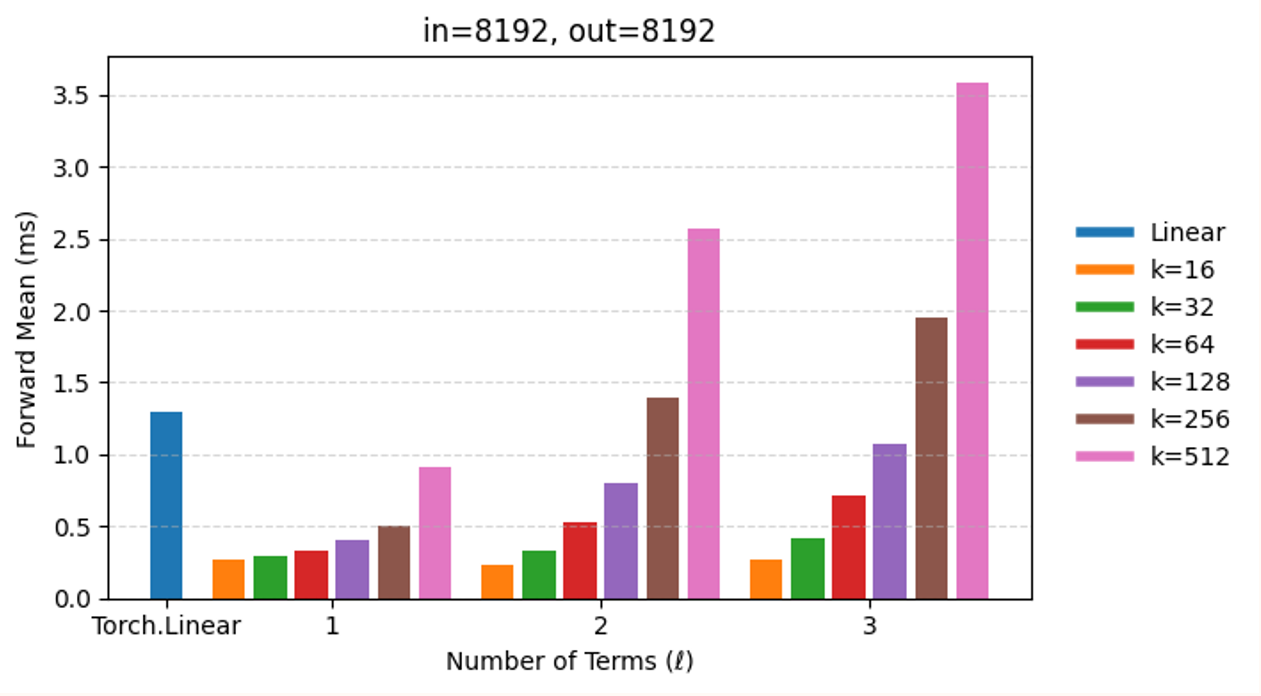
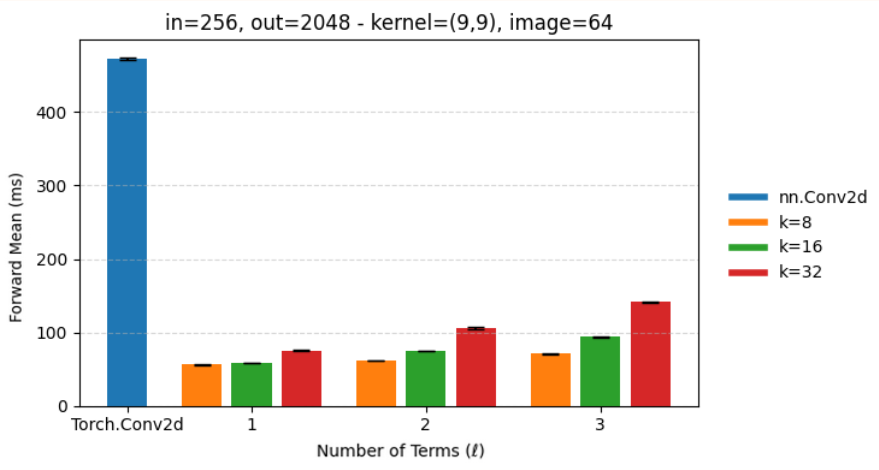
Библиотека Panther предоставляет основные операции, такие как схематические линейные слои (SKLinear) и схематические двумерные сверточные слои (SKConv2D), что позволяет эффективно строить и обучать модели машинного обучения. Использование этих слоев, основанных на методах случайной линейной алгебры, позволяет добиться уменьшения размера модели до 75% при сохранении сопоставимой производительности. Реализация SKLinear и SKConv2D позволяет интегрировать методы схематизации непосредственно в существующие архитектуры PyTorch, не требуя существенных изменений в коде обучения.
pawX и оптимизированные бэкенды для ускорения вычислений
Ядро производительности Panther, pawX, представляет собой расширение PyTorch, разработанное для достижения высокой скорости и эффективности вычислений. pawX позволяет использовать преимущества аппаратного ускорения, предоставляемого CUDA и OpenBLAS, для оптимизации операций линейной алгебры как на центральных, так и на графических процессорах. Это расширение интегрируется непосредственно в вычислительный граф PyTorch, минимизируя накладные расходы и обеспечивая эффективное использование ресурсов оборудования для ускорения обучения и инференса моделей.
Ядро производительности Panther, pawX, использует возможности CUDA и OpenBLAS для ускорения операций линейной алгебры как на центральных, так и на графических процессорах. CUDA обеспечивает параллельные вычисления на GPU NVIDIA, значительно увеличивая скорость обработки матриц и векторов. OpenBLAS, в свою очередь, оптимизированная библиотека базовых линейно-алгебраических подпрограмм, предоставляет высокопроизводительные реализации для CPU, поддерживая различные архитектуры и обеспечивая эффективное использование ресурсов. Комбинация CUDA и OpenBLAS позволяет pawX динамически распределять вычислительную нагрузку между CPU и GPU, максимально используя доступные аппаратные ресурсы и обеспечивая оптимальную производительность в различных сценариях.
В Panther реализованы алгоритмы, такие как CholeskyQR с рандомизацией и выбором главного элемента (CQRRPT), что обеспечивает оптимизированную производительность для определенных задач. Применение CQRRPT позволяет достичь сопоставимой величины MLM Loss — 4.601 против 4.594 — при этом наблюдается снижение размеров моделей. Данный подход позволяет повысить эффективность вычислений и уменьшить потребление ресурсов без существенной потери в качестве результатов.
AutoTuning: Автоматическая настройка для оптимальной производительности
Модуль AutoTuner в Panther автоматически осуществляет поиск оптимальных гиперпараметров скетчинга, используя фреймворк Optuna. Этот процесс реализован для автоматизации настройки параметров, влияющих на производительность и эффективность скетчинга, без необходимости ручного вмешательства. Optuna предоставляет возможности для определения пространства поиска гиперпараметров и алгоритмы оптимизации, позволяющие AutoTuner находить конфигурации, максимизирующие точность и минимизирующие вычислительные затраты. Автоматический поиск параметров позволяет добиться оптимальной производительности модели для конкретного набора данных и архитектуры.
Модуль автоматической настройки (AutoTuner) в Panther позволяет упростить процесс поиска оптимальной конфигурации гиперпараметров скетчинга для заданной модели и набора данных. Автоматизация исключает необходимость ручного подбора параметров, что значительно снижает временные затраты и трудоемкость. В результате достигается максимальная производительность модели при минимальных усилиях со стороны пользователя, позволяя сосредоточиться на других аспектах разработки и анализа данных. Это особенно полезно при работе с большими объемами данных и сложными моделями, где ручной поиск оптимальных параметров может быть практически невозможен.
Эффективность Panther была подтверждена в ходе тестирования на различных наборах данных, включая CIFAR-10 и WikiText, а также с использованием моделей, таких как ResNet-50. Результаты показывают, что при применении Panther к CIFAR-10 наблюдается снижение точности на 3% (с 89% до 86%), сопровождающееся уменьшением размера модели ResNet-50 на 30%. Данные результаты демонстрируют способность Panther к оптимизации моделей с сохранением приемлемого уровня точности при значительном уменьшении их размера, что важно для задач, требующих высокой производительности и ограниченных ресурсов.
Расширяя горизонты: Влияние RandNLA на машинное обучение
Успешная интеграция библиотеки Panther методов случайной аппроксимации линейной алгебры (RandNLA), включая CoLA и Tensor Sketching, наглядно демонстрирует значительный потенциал для более широкого внедрения этих техник в сообществе машинного обучения. Данные методы позволяют существенно снизить вычислительные затраты и требования к памяти при работе с большими данными, что открывает возможности для обучения более сложных моделей и решения задач, ранее недоступных из-за ограничений ресурсов. В частности, CoLA (Communication-efficient Low-rank Approximation) оптимизирует коммуникацию между узлами в распределенных системах, а Tensor Sketching позволяет эффективно аппроксимировать тензорные операции, сохраняя при этом высокую точность. Применение этих подходов в Panther подтверждает их практическую целесообразность и указывает на перспективность дальнейших исследований в данной области, способствуя развитию более масштабируемых и эффективных алгоритмов машинного обучения.
Библиотека Panther демонстрирует значительные улучшения в производительности и простоту использования, что открывает новые возможности для масштабирования моделей машинного обучения и решения более сложных задач. Благодаря оптимизированным алгоритмам и интуитивно понятному интерфейсу, исследователи и разработчики могут эффективно обучать и развертывать модели, требующие больших вычислительных ресурсов. Это позволяет преодолеть ограничения, связанные с объемом данных и сложностью вычислений, и исследовать более глубокие и точные модели. Возможность быстрого прототипирования и масштабирования делает Panther ценным инструментом для решения широкого спектра задач, включая обработку естественного языка и компьютерное зрение, способствуя прогрессу в области искусственного интеллекта и машинного обучения.
Разработка библиотеки Panther не останавливается на достигнутом; дальнейшие исследования направлены на существенное расширение её функциональности и применение методов случайной линейной алгебры (RandNLA) в новых областях. Особое внимание уделяется задачам обработки естественного языка, где RandNLA может оптимизировать работу с огромными объемами текстовых данных и повысить эффективность моделей машинного перевода и анализа тональности. Кроме того, планируется активное внедрение этих техник в задачи компьютерного зрения, позволяя создавать более быстрые и эффективные алгоритмы распознавания образов и анализа изображений. Исследователи уверены, что RandNLA обладает значительным потенциалом для решения сложных задач в этих областях, открывая новые горизонты для развития искусственного интеллекта.
Библиотека Panther, представленная в статье, демонстрирует элегантность подхода к оптимизации вычислений в глубоком обучении. Она использует Randomized Numerical Linear Algebra (RandNLA) для значительного снижения затрат памяти и вычислительной мощности, не жертвуя при этом точностью. Как однажды заметил Винтон Серф: «В конечном счете, главное — это взаимодействие». Это взаимодействие между эффективными алгоритмами RandNLA и гибкой платформой PyTorch позволяет Panther адаптироваться к различным задачам и архитектурам моделей. Оптимизация структуры вычислений, как показывает Panther, напрямую влияет на поведение всей системы, что подтверждает важность целостного подхода к проектированию и реализации алгоритмов.
Куда Далее?
Представленная работа, хотя и демонстрирует впечатляющие результаты в снижении вычислительных затрат, лишь приоткрывает дверь в обширную область Randomized Numerical Linear Algebra (RandNLA). Упрощение вычислений — это всегда компромисс, и истинное искусство заключается в понимании, где этот компромисс оправдан, а где он разрушает фундаментальную структуру решаемой задачи. Необходимо углубленное исследование влияния различных методов скетчинга на устойчивость и обобщающую способность моделей глубокого обучения — не только в контролируемых лабораторных условиях, но и в реальных, шумных данных.
Очевидным направлением развития является адаптация методов RandNLA к различным архитектурам нейронных сетей. Единообразие — это иллюзия, и то, что работает эффективно для одной модели, может оказаться неэффективным для другой. Более того, необходимо исследовать возможности автоматической настройки параметров скетчинга, чтобы минимизировать ручной труд и обеспечить оптимальную производительность в различных сценариях. Иначе, мы рискуем создать еще одну сложную систему, требующую постоянной тонкой настройки.
В конечном счете, задача не в том, чтобы просто ускорить вычисления, а в том, чтобы создать более элегантные и устойчивые системы. Как и в любом живом организме, избыточность и резервирование — это ключевые факторы выживания. Использование RandNLA — это лишь один из инструментов, позволяющих достичь этой цели, и его эффективность будет определяться не только математической точностью, но и глубоким пониманием принципов, лежащих в основе самоорганизующихся систем.
Оригинал статьи: https://arxiv.org/pdf/2601.15473.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Навыки агентов: Новый уровень интеллекта ИИ
- Поймать Мгновение: Эволюция Детекторов Времени
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
2026-01-23 19:01