Автор: Денис Аветисян
Новый подход позволяет преобразовывать неопределенность в долгосрочных планах агентов искусственного интеллекта в управляемые сигналы, повышая их надежность и точность.
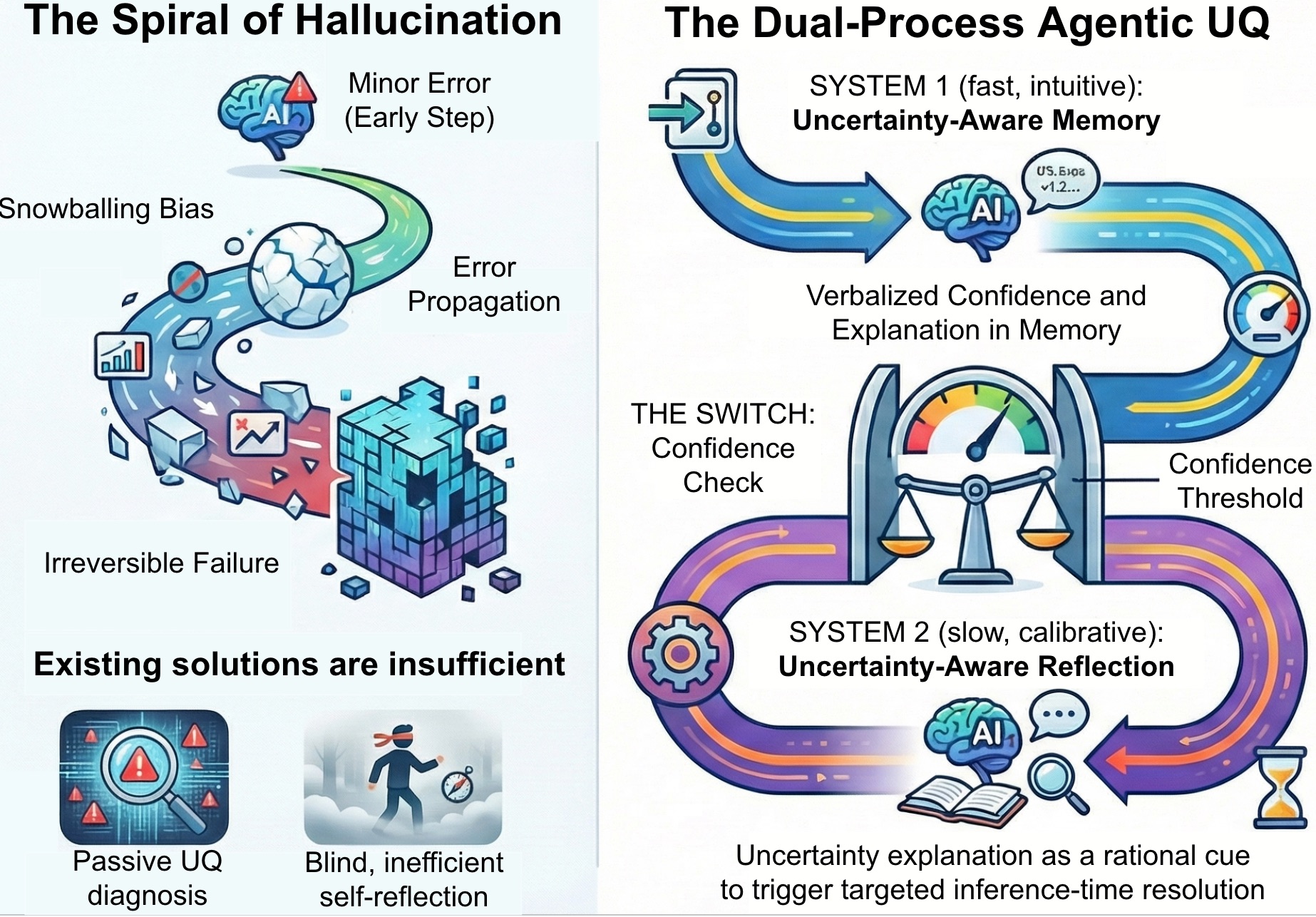
Предлагается фреймворк Agentic Uncertainty Quantification (AUQ), разделяющий прямое распространение и обратную калибровку через моделирование мышления типа ‘Система 1’ и ‘Система 2’.
Несмотря на впечатляющие успехи в долгосрочном планировании, надежность ИИ-агентов зачастую подрывается склонностью к «спирали галлюцинаций», где начальные ошибки необратимо накапливаются. В настоящей работе, посвященной ‘Agentic Uncertainty Quantification’, предложен новый подход, преобразующий вербализованную неопределенность в активные управляющие сигналы. Ключевым результатом является разработанная архитектура AUQ, использующая механизмы, аналогичные системам 1 и 2, для балансировки эффективного выполнения задач и глубокой рефлексии. Способна ли данная концепция принципиально повысить калибровку и надежность ИИ-агентов в сложных, долгосрочных сценариях?
Преодоление Неопределенности: Вызов Долгосрочной Надежности
Современные языковые модели демонстрируют впечатляющие результаты в решении задач, требующих поверхностного понимания и обработки информации. Однако, по мере усложнения логической цепочки и увеличения объема необходимого анализа, их способность поддерживать связность и фактическую точность существенно снижается. В то время как модели легко справляются с простыми вопросами и краткими текстами, при решении многоступенчатых задач или обработке больших объемов данных они часто теряют нить рассуждений, приводя к противоречивым или нелогичным выводам. Данное ограничение связано с тем, что модели склонны к запоминанию и воспроизведению паттернов, а не к глубокому пониманию причинно-следственных связей, что особенно проявляется при необходимости длительного рассуждения и поддержания контекста на протяжении всей цепочки умозаключений.
Ограничение языковых моделей в длительных цепочках рассуждений проистекает из их неспособности эффективно распространять и управлять неопределенностью. В сложных сценариях это приводит к феномену, названному “Спиралью Галлюцинаций”, когда модель, сталкиваясь с недостатком информации или неоднозначностью, начинает генерировать все более отдаленные от реальности утверждения, которые затем используются в дальнейших рассуждениях, усугубляя ошибки. Эта тенденция к самоподкрепляющимся неточностям препятствует надежности модели в задачах, требующих длительного и последовательного мышления, поскольку даже небольшие первоначальные погрешности могут экспоненциально накапливаться и приводить к совершенно неверным выводам. Таким образом, преодоление этого ограничения требует разработки новых методов представления и обработки неопределенности, позволяющих моделям осознавать границы своих знаний и избегать генерации ложной информации.
Для успешного решения задач, требующих долгосрочного планирования и рассуждений, необходим принципиально новый подход к представлению и использованию неопределенности искусственными агентами. Существующие модели часто сталкиваются с проблемой “галлюцинаций” и потери логической связности при усложнении сценария, поскольку не способны эффективно отслеживать и распространять информацию о собственной неуверенности. Вместо простого предсказания наиболее вероятного исхода, агенты будущего должны уметь оценивать степень доверия к каждому шагу рассуждений, учитывать возможные альтернативы и корректировать свои планы на основе постоянно обновляемой оценки рисков. Такой подход позволит не только повысить надежность принимаемых решений, но и сделает процесс рассуждений более прозрачным и понятным, открывая новые возможности для взаимодействия человека и искусственного интеллекта.
Агентный UQ: Основа Надежного Рассуждения
Представляем Agentic UQ — фреймворк, направленный на повышение надежности агентов, объединяющий механизмы осознанного хранения информации (Uncertainty-Aware Memory, UAM) и осознанной рефлексии (Uncertainty-Aware Reflection, UAR). Данная архитектура позволяет агенту отслеживать и учитывать уровень неопределенности на протяжении всего процесса рассуждений. UAM обеспечивает сохранение информации об уверенности и объяснениях, а UAR инициирует целенаправленное разрешение неопределенностей в процессе работы агента, когда установленные пороговые значения неопределенности превышаются. Взаимодействие UAM и UAR формирует замкнутый цикл, способствующий более надежным и обоснованным решениям.
Механизм Uncertainty-Aware Memory (UAM) использует принципы быстрого, интуитивного рассуждения, аналогичные работе ‘Системы 1’ в когнитивной психологии, для последовательного распространения информации о неопределенности на протяжении всего процесса рассуждений агента. В отличие от подходов, игнорирующих или отбрасывающих данные о неуверенности, UAM сохраняет и передает ключевые сигналы, отражающие уровень достоверности и объяснения, связанные с каждым шагом вывода. Это позволяет агенту не только оценивать вероятность своих решений, но и предоставлять информацию о причинах, по которым был сделан тот или иной вывод, что критически важно для обеспечения надежности и интерпретируемости его действий.
Механизм Uncertainty-Aware Reflection (UAR) функционирует как компонент «Системы 2» — медленного, рефлексивного рассуждения — и активируется при достижении заранее определенных пороговых значений неопределенности. Это позволяет агенту целенаправленно решать проблемы во время выполнения (inference-time resolution) в тех случаях, когда уровень уверенности в текущем выводе снижается. UAR не выполняет повторный анализ всей цепочки рассуждений, а фокусируется исключительно на тех этапах, где зафиксирована повышенная неопределенность, что обеспечивает эффективное использование вычислительных ресурсов и повышает надежность принимаемых решений.
Верификация Надежности: Прямое и Обратное Рассуждение
Агентный UQ (Uncertainty Quantification) позволяет решать как задачу прямого прогнозирования валидности траектории (оценка вероятности успешного выполнения последовательности действий), так и обратную задачу — корректировку отклонений от запланированной траектории. Решение обратной задачи достигается путем вывода скрытых путей рассуждений, то есть, анализа причин, приведших к отклонению, и последующей модификации плана действий. Этот подход позволяет не только выявлять ошибки, но и адаптировать поведение агента в реальном времени, повышая надежность и эффективность его работы. Фактически, агентный UQ предоставляет механизм для самокоррекции и улучшения планирования на основе анализа собственных рассуждений.
Методы извлечения достоверности (Confidence Elicitation) являются неотъемлемой частью процесса валидации надежности. Они обеспечивают получение количественных оценок неопределенности, которые используются как в прямой оценке валидности траектории (Forward Problem), так и в коррекции отклонений путем вывода скрытых путей рассуждений (Inverse Problem). В частности, эти методы позволяют определить вероятность успешного выполнения последовательности действий, а также оценить степень уверенности в каждом отдельном шаге. Получаемые количественные показатели неопределенности служат входными данными для алгоритмов калибровки траектории и используются для принятия решений о необходимости корректировки действий агента.
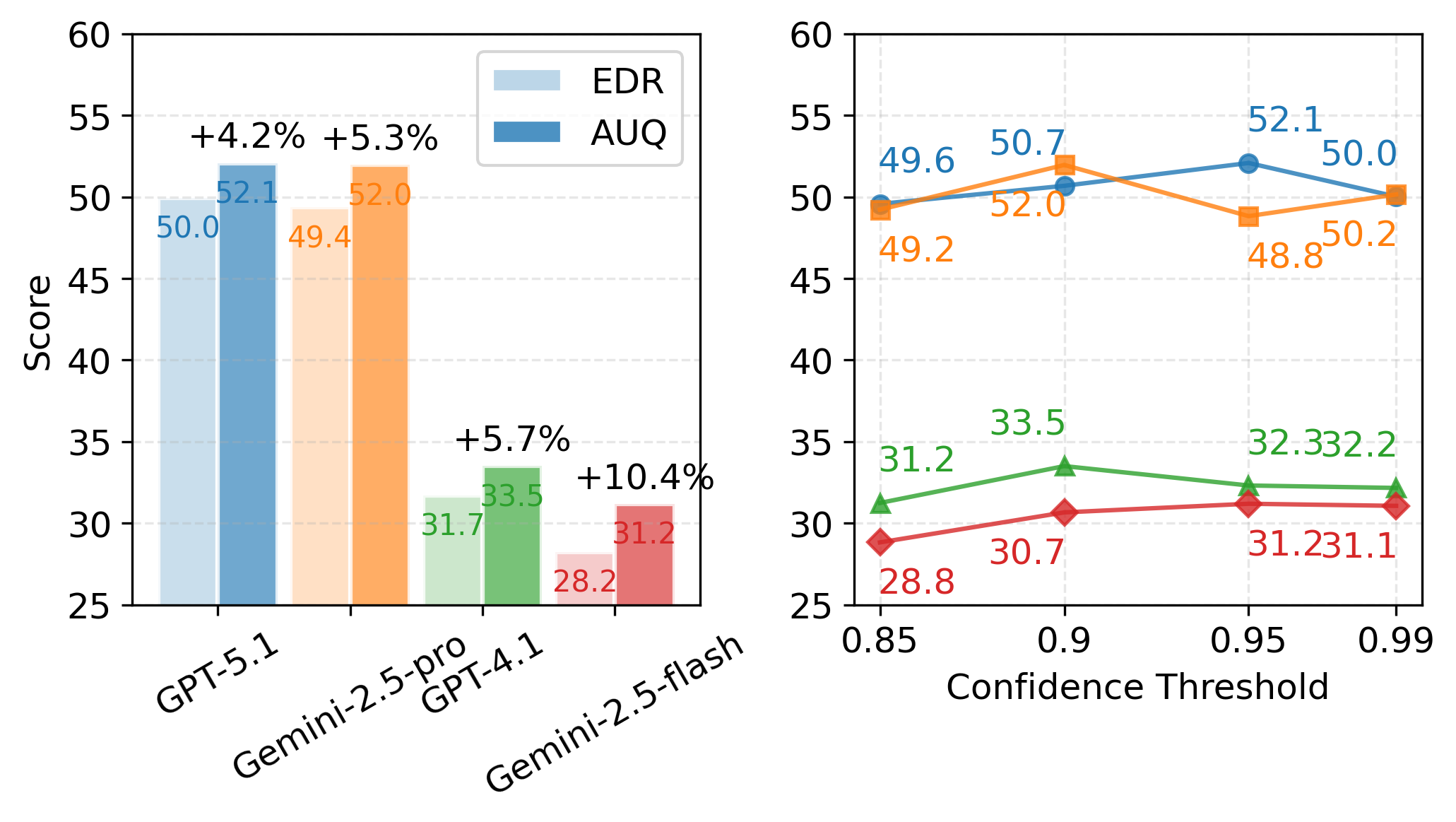
Эффективная калибровка траектории обеспечивает соответствие прогнозируемых уровней уверенности фактической производительности на протяжении длительных последовательностей действий. В процессе калибровки система непрерывно сопоставляет предсказанные вероятности успешного выполнения задач с наблюдаемыми результатами, корректируя внутренние модели для повышения точности. В результате, после этапа рефлексии и самокоррекции, достигается итоговый показатель уверенности в диапазоне 0.95-0.96, что свидетельствует о высокой степени надежности системы при прогнозировании и коррекции отклонений в сложных последовательностях действий.

Оценка и Перспективы Развития
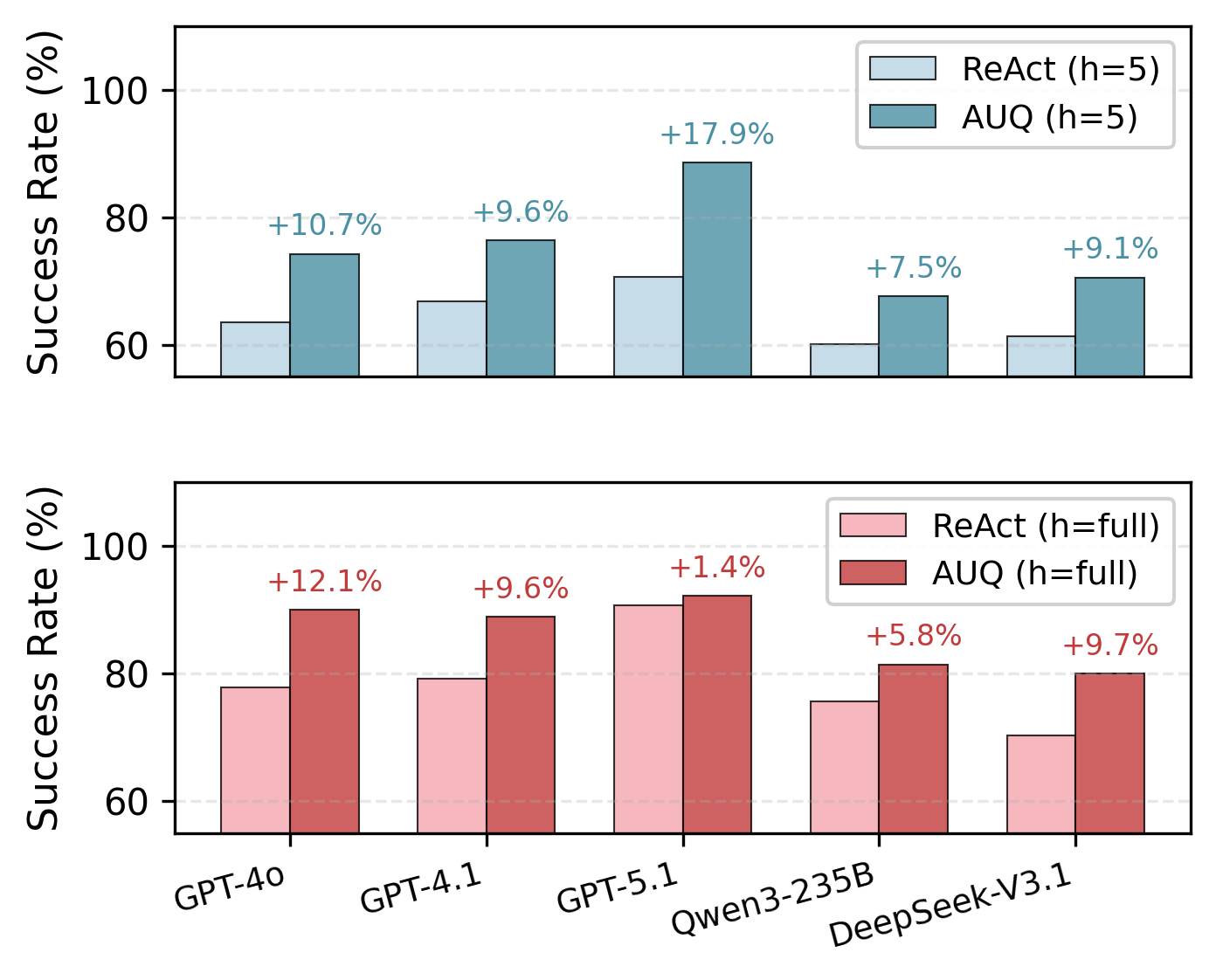
В ходе оценки Agentic UQ на специализированных платформах “Deep Research Bench” и “ALFRED” были продемонстрированы значительные улучшения в производительности и калибровке. Показатели, такие как AUROC и T-ECE, свидетельствуют о повышенной надежности системы, а успешность выполнения задач увеличилась на 20% по сравнению с базовыми агентами. Полученные результаты подтверждают, что Agentic UQ эффективно решает сложные задачи, требующие долгосрочного планирования и принятия решений, обеспечивая более точные и обоснованные результаты.
Исследования продемонстрировали, что Agentic UQ эффективно противодействует феномену “спирали галлюцинаций”, часто возникающему при решении сложных, долгосрочных задач. Данный подход позволяет агенту избегать зацикливания на ложных предположениях и поддерживать более последовательное и достоверное рассуждение на протяжении всего процесса выполнения задания. В результате достигается значительное повышение надежности и предсказуемости действий, особенно в ситуациях, требующих планирования и принятия решений на основе неполной или неопределенной информации. Способность Agentic UQ к смягчению “спирали галлюцинаций” открывает перспективы для создания более автономных и эффективных интеллектуальных систем, способных успешно функционировать в сложных и динамичных средах.
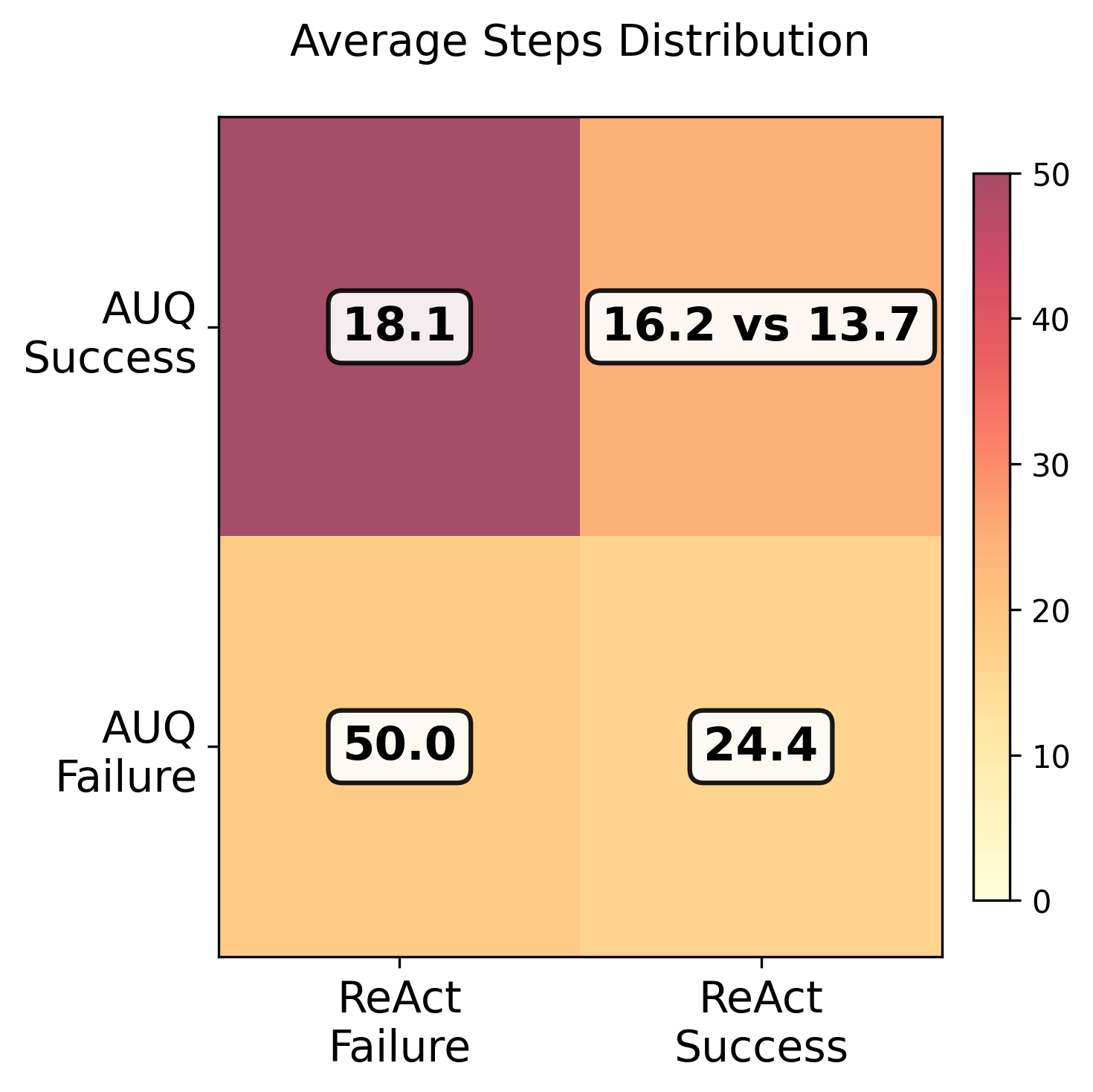
Исследования показали, что Agentic UQ значительно снижает общую стоимость выполнения задач и сокращает количество шагов, необходимых для их завершения, более чем на 30 по сравнению с базовыми агентами, склонными к зацикливанию действий. Это достигается благодаря более эффективному планированию и избежанию повторных, не продуктивных действий. В дальнейшем планируется расширить данную архитектуру для применения в многоагентных системах, что позволит решать более сложные и масштабные задачи. Кроме того, ведется работа над адаптивными порогами неопределенности, которые позволят системе динамически настраивать свою уверенность в принимаемых решениях, повышая общую надежность и устойчивость к непредсказуемым ситуациям.
Исследование, представленное в статье, фокусируется на повышении надежности и калибровки агентов на основе больших языковых моделей в условиях долгосрочного планирования. Подход Agentic Uncertainty Quantification (AUQ) выделяется способностью преобразовывать неопределенность в управляемые сигналы, что особенно важно при принятии решений в сложных сценариях. Как однажды заметила Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». Эта фраза отражает суть AUQ, поскольку система не просто пассивно оценивает риски, но и активно использует неопределенность для улучшения своих действий и повышения предсказуемости результатов. Разделение процессов распространения и калибровки через системы «1» и «2» позволяет агентам более осознанно подходить к решению задач, подобно тому, как математик стремится к доказательству, а не просто к эмпирической проверке.
Что дальше?
Представленная работа, несомненно, демонстрирует элегантность подхода к управлению неопределенностью в агентах, основанных на больших языковых моделях. Однако, пусть N стремится к бесконечности — что останется устойчивым? Декомпозиция на «Систему 1» и «Систему 2» — это лишь удобное представление, а не фундаментальное решение. Неизбежно возникает вопрос о границах применимости такого разделения в контексте действительно сложных, долгосрочных задач. Калибровка, хотя и улучшена, остается зависимой от распределения обучающих данных, а значит, подвержена систематическим ошибкам, когда реальность отклоняется от этого распределения.
Следующим этапом представляется не просто повышение точности калибровки, а разработка методов, позволяющих агенту осознавать границы своей компетентности. Иными словами, необходим механизм, который позволил бы агенту не только оценить вероятность успеха, но и сформулировать запрос о помощи или отказаться от выполнения задачи, если неопределенность слишком велика. Это потребует интеграции с внешними источниками знаний и разработки формальных моделей доверия.
В конечном итоге, истинный прогресс будет достигнут не в улучшении существующих методов калибровки, а в создании агентов, способных к саморефлексии и адаптации в условиях принципиальной неопределенности. Именно тогда мы сможем говорить о действительно надежных и предсказуемых системах, а не о сложных статистических моделях, выдающих правдоподобные ответы.
Оригинал статьи: https://arxiv.org/pdf/2601.15703.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-23 22:21