Автор: Денис Аветисян
Исследователи представили инновационную систему, способную преобразовывать обычные фотографии и видео в иммерсивные 360-градусные панорамы без необходимости точного определения геометрии сцены.

Предлагаемый метод 360Anything использует диффузионные трансформеры для генерации высококачественных панорам из перспективных изображений и видео, обходясь без явной информации о камере или геометрической привязке.
Существующие методы генерации панорамных изображений и видео из перспективных видов часто требуют точной калибровки камеры и явного геометрического выравнивания. В данной работе представлен ‘360Anything: Geometry-Free Lifting of Images and Videos to 360°’ — новый подход, основанный на диффузионных трансформаторах, который позволяет создавать высококачественные 360° панорамы без использования информации о камере или геометрических преобразований. Предложенная модель демонстрирует передовые результаты в задачах генерации панорам как из изображений, так и из видео, превосходя существующие методы, требующие данных о калибровке камеры. Не раскрывая ли потенциал данной технологии для более глубокого понимания геометрии сцены и расширения возможностей компьютерного зрения?
Преодолевая Горизонты: Сложность Создания Панорамных Изображений
Создание высококачественных 360° панорам из обычных перспективных изображений представляет собой сложную задачу, требующую безупречного соединения отдельных кадров и поддержания визуальной целостности на протяжении всей панорамы. Процесс этот осложняется необходимостью компенсации геометрических искажений, возникающих при проецировании сферической сцены на плоское изображение, а также обеспечением плавного перехода между соседними кадрами, чтобы избежать заметных швов и разрывов. Достижение реалистичного и захватывающего эффекта требует не только точной калибровки камер и алгоритмов сшивки, но и тщательной обработки цветовых и текстурных различий между кадрами, что делает задачу особенно трудоемкой и ресурсозатратной.
Традиционные методы генерации панорамных изображений часто сталкиваются с проблемой поддержания визуальной связности по всей площади изображения. В процессе склейки отдельных перспективных кадров неизбежно возникают заметные швы и искажения геометрии, особенно в областях, где изображения пересекаются или имеют значительные различия в освещении и текстуре. Эти артефакты нарушают ощущение погружения и реалистичности панорамы, снижая её эстетическую ценность и затрудняя восприятие. Проблемы возникают из-за сложностей точной регистрации изображений, компенсации перспективных искажений и плавного перехода между кадрами, что требует значительных вычислительных ресурсов и ручной корректировки для достижения приемлемого результата.
Существующие генеративные модели зачастую сталкиваются с трудностями при воссоздании панорамных изображений из-за особенностей эквиректанглярной проекции. Данный формат, необходимый для представления 360° изображений, характеризуется значительными искажениями геометрии и неравномерным распределением пикселей, что требует от моделей учета специфических характеристик. Неспособность адекватно моделировать эти особенности приводит к появлению заметных артефактов, таких как разрывы текстур, деформации объектов и неестественные переходы между областями изображения. В результате, сгенерированные панорамы могут выглядеть нереалистично и лишены необходимой визуальной целостности, что снижает качество восприятия и погружения пользователя.

360Anything: Гармония Трансформеров и Панорамных Миров
В основе системы 360Anything лежит Diffusion Transformer (DiT) — архитектура, используемая в качестве основного генеративного механизма для создания панорамных изображений высокого разрешения. DiT представляет собой разновидность трансформера, адаптированную для задач диффузионного моделирования. В процессе генерации DiT последовательно удаляет шум из случайного изображения, постепенно формируя детализированную панораму. Использование трансформерной архитектуры позволяет эффективно моделировать сложные зависимости между пикселями и создавать реалистичные изображения с высокой степенью детализации, что критически важно для создания иммерсивных сред.
В системе 360Anything отказ от явной проецирования достигается за счет использования конкатенации последовательностей (Sequence Concatenation) в процессе условной генерации. Вместо преобразования перспективных изображений в панорамные, система объединяет токены, представляющие как перспективную, так и панорамную информацию, в единую последовательность, подаваемую на Diffusion Transformer (DiT). Такой подход позволяет DiT напрямую генерировать панорамные изображения, избегая артефактов, возникающих при традиционных методах проецирования, и обеспечивая более высокое качество и согласованность генерируемых панорам.
В системе 360Anything для обучения генератора DiT (denoiser) используется метод Flow Matching. В отличие от традиционных методов обучения диффузионных моделей, Flow Matching оптимизирует процесс обучения, напрямую моделируя траектории потока данных, что позволяет значительно ускорить сходимость и повысить стабильность генерации панорам. Этот подход позволяет избежать проблем, связанных с нестабильностью и медленной сходимостью, часто возникающих при использовании традиционных методов обучения, таких как диффузионные вероятностные модели. Фактически, Flow Matching позволяет эффективно обучать DiT, получая высококачественные панорамы за меньшее время и с большей надежностью.
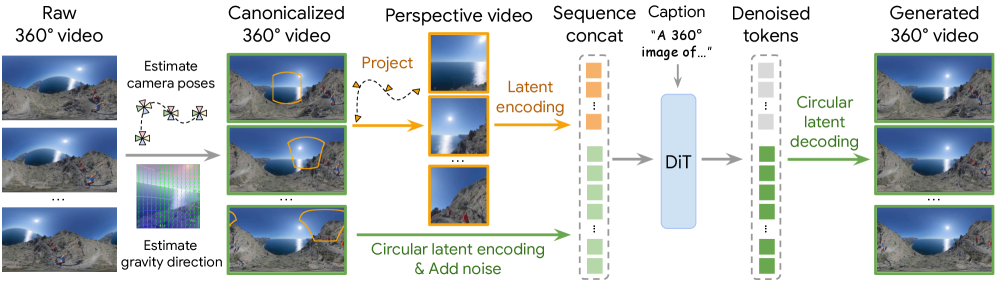
Изящное Решение: Circular Latent Encoding для Бесшовных Панорам
При генерации панорамных изображений видимые швы (артефакты) остаются устойчивой проблемой. Данные артефакты часто возникают из-за разрывов при кодировании изображения в латентное пространство. Причина заключается в том, что стандартные методы кодирования не учитывают циклический характер панорамы, что приводит к несоответствиям на границах изображения. Эти несоответствия проявляются как видимые швы при декодировании и последующей визуализации панорамы, ухудшая общее качество и реалистичность.
Для снижения артефактов, проявляющихся в виде видимых швов при генерации панорам, предложена техника Circular Latent Encoding. Она заключается в предварительном заполнении (padding) и обрезке (cropping) латентных представлений панорамы перед кодированием. Данный процесс позволяет эффективно «завернуть» изображение, создавая непрерывное представление, что минимизирует разрывы на границах и, как следствие, уменьшает видимость швов в результирующей панораме. По сути, метод обеспечивает плавный переход между краями изображения в латентном пространстве, что способствует генерации более реалистичных и качественных панорам.
Результаты проведенных качественных и количественных исследований подтверждают снижение заметности швов при использовании предложенного метода Circular Latent Encoding. Визуальная оценка сгенерированных панорам показала уменьшение артефактов в области стыков, что подтверждается субъективной оценкой качества изображения. Количественный анализ, включающий метрики, оценивающие структурные различия и артефакты, продемонстрировал статистически значимое улучшение показателей качества панорам по сравнению с традиционными методами кодирования латентного пространства. Данные подтверждают, что Circular Latent Encoding эффективно снижает видимость швов и повышает общее восприятие качества генерируемых панорам.

Преодолевая Границы: От Панорам к Трехмерным Мирам
Панорамы, сгенерированные системой 360Anything, представляют собой надежную основу для применения технологии 3D Gaussian Splatting (3DGS), что позволяет добиться высококачественной реконструкции трехмерных сцен. Данный подход использует преимущества детализированных и реалистичных панорамных изображений для создания плотных и визуально точных 3D-моделей окружения. Благодаря способности 360Anything генерировать панорамы с высоким разрешением и широким динамическим диапазоном, 3DGS может эффективно восстанавливать геометрию и текстуры сложных сцен, значительно превосходя по качеству традиционные методы 3D-реконструкции. В результате, созданные модели отличаются высокой степенью реализма и детализации, что открывает новые возможности для применения в виртуальной и дополненной реальности, а также в других областях, требующих точного 3D-представления окружающей среды.
Для оценки качества генерируемых панорам использовался комплексный набор метрик, позволяющий всесторонне проанализировать их реалистичность и соответствие исходным данным. В частности, рассчитывался Fréchet Inception Distance (FID), измеряющий сходство распределений признаков между сгенерированными изображениями и реальными, что позволяет оценить их визуальное качество. Также применялись метрики CLIP Score, оценивающая семантическое соответствие между изображением и текстовым описанием, LPIPS — для оценки воспринимаемого качества изображения с точки зрения человеческого зрения, и VBench — комплексный бенчмарк для оценки качества и реалистичности 360° контента. Использование данного набора метрик позволило провести объективную и всестороннюю оценку качества генерируемых панорам, выявив их сильные стороны и области для дальнейшего улучшения.
Исследования показали, что разработанная система 360Anything демонстрирует передовые результаты в области реконструкции изображений, превосходя существующие аналоги по показателю Fréchet Inception Distance (FID) на популярных датасетах Laval Indoor и SUN360. Более низкий FID указывает на значительное улучшение качества генерируемых изображений, в частности, на повышенную реалистичность и детализацию. Этот результат свидетельствует о способности системы создавать визуально более правдоподобные и убедительные 360-градусные панорамы, что открывает новые возможности для применения в виртуальной реальности, компьютерных играх и других областях, требующих высококачественного визуального контента.
Исследования показали, что модель 360Anything демонстрирует более низкий показатель LPIPS (Learned Perceptual Image Patch Similarity) для видео, сгенерированных данной методикой, по сравнению с базовыми подходами. Этот показатель напрямую отражает восприятие качества изображения человеком, оценивая сходство в восприятии между сгенерированным и реальным видео. Более низкое значение LPIPS указывает на то, что сгенерированные видеоролики обладают более высокой степенью визуального сходства с реальными, что свидетельствует о значительном улучшении в области создания реалистичных и правдоподобных виртуальных сред. По сути, данное достижение указывает на то, что система способна генерировать видеоматериалы, которые кажутся более естественными и приятными для человеческого глаза, обеспечивая повышенный уровень погружения и визуального комфорта.
Исследования показали, что модель 360Anything демонстрирует более низкий показатель FVD (Fréchet Video Distance), что свидетельствует о значительном улучшении как общей геометрии, так и визуального качества генерируемых панорам. Этот показатель, оценивающий сходство между генерируемыми и реальными видео, указывает на более реалистичное и когерентное представление сцены. Более низкий FVD коррелирует с более точным воспроизведением трехмерной структуры и текстур, что особенно важно для создания иммерсивных виртуальных сред и высококачественного визуального контента. Достижение такого результата подтверждает эффективность предложенного подхода в генерации панорам, превосходящих существующие методы по целостному качеству и реалистичности.
Интеграция оценки положения камеры является ключевым элементом, значительно повышающим реалистичность и эффект погружения в создаваемые виртуальные окружения. Точное определение позиции и ориентации камеры в пространстве позволяет корректно отображать перспективу и глубину, что критически важно для создания убедительных 3D-сцен. Благодаря этому, сгенерированные панорамы и видео выглядят более естественными и правдоподобными, создавая у зрителя ощущение присутствия в смоделированном мире. Данная технология обеспечивает согласованность между отдельными кадрами и позволяет создавать плавные, реалистичные движения камеры, что существенно улучшает общее восприятие и взаимодействие с виртуальной средой.

Представленная работа демонстрирует элегантность подхода к созданию панорамных изображений. Вместо сложных вычислений и точного определения положения камеры, 360Anything опирается на возможности диффузионных трансформаторов для плавного преобразования перспективы. Это напоминает слова Джеффри Хинтона: «Я думаю, что самое важное, что мы должны делать, — это создавать системы, которые могут учиться чему-то новому, не забывая при этом старое». Подобно тому, как нейронные сети учатся из данных, не требуя явных инструкций, 360Anything создает панорамы, манипулируя латентным пространством, а не полагаясь на жесткие геометрические ограничения. Такой подход позволяет достичь впечатляющих результатов в синтезе видов и создании высококачественных 360° панорам, подчеркивая гармонию между формой и функцией.
Куда же дальше?
Представленная работа, безусловно, демонстрирует изящный подход к генерации панорамных изображений, избегая грубого навязывания геометрических ограничений. Однако, истинная элегантность заключается не в обходе препятствий, а в их понимании. Дальнейшие исследования должны быть направлены на более глубокое осмысление связи между перспективой и панорамным представлением, а не на её искусственное нивелирование. Вопрос не в том, чтобы «сгенерировать» панораму, а в том, чтобы понять, как информация о сцене кодируется в различных проекциях.
Очевидным направлением представляется исследование границ применимости данного подхода. Как поведет себя система при работе с видеоматериалами, содержащими сложные динамические сцены или значительные изменения освещения? Устойчивость к шумам и артефактам, несомненно, потребует пристального внимания. И, что немаловажно, следует задуматься о вычислительной эффективности. Изящество алгоритма не должно быть оплачено непомерными затратами ресурсов.
В конечном итоге, успех подобного рода исследований будет определяться не столько достигнутыми результатами, сколько поставленными вопросами. Настоящая красота кроется не в совершенстве реализации, а в глубине понимания. Лишь тогда, когда мы научимся видеть за отдельными пикселями общую гармонию, мы сможем по-настоящему оценить потенциал этой технологии.
Оригинал статьи: https://arxiv.org/pdf/2601.16192.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-24 01:40