Автор: Денис Аветисян
Исследователи предлагают упрощенный подход к обучению масштабных моделей генерации изображений, основанный на автоэнкодерах представлений, что открывает возможности для более быстрого обучения и повышения качества.
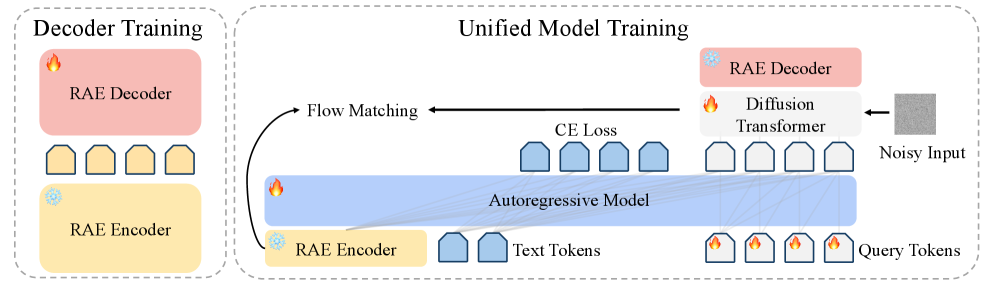
Автоэнкодеры представлений (RAE) оказались более эффективной альтернативой вариационным автоэнкодерам (VAE) для обучения масштабных диффузионных моделей преобразования текста в изображение, обеспечивая унифицированную платформу для визуального понимания и генерации.
Несмотря на успехи диффузионных моделей в генерации изображений по текстовому описанию, масштабирование этих моделей требует эффективных архитектур и методов обучения. В работе ‘Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders’ исследуется возможность масштабирования подхода, основанного на автоэнкодерах представлений (RAE), для генерации изображений по тексту в больших масштабах. Показано, что RAE превосходят вариационные автоэнкодеры (VAE) по скорости сходимости и качеству генерации, обеспечивая более стабильное обучение и унифицированное пространство представлений для мультимодальных моделей. Какие перспективы открывает упрощенная архитектура RAE для создания еще более мощных и гибких систем генерации изображений и понимания визуальной информации?
За пределами пикселей: ограничения традиционной генерации изображений из текста
Несмотря на впечатляющие успехи, современные модели преобразования текста в изображение демонстрируют трудности при создании сложных сцен и понимании композиционных взаимосвязей. Исследования показывают, что генерация реалистичных изображений, содержащих множество объектов и их точное расположение в пространстве, представляет собой значительную проблему. Модели часто не способны правильно интерпретировать сложные описания, приводя к нелогичным или физически невозможным результатам. Например, при запросе изображения, содержащего «красную чашку слева от синей книги, на фоне зеленого дерева», модель может некорректно расположить объекты или игнорировать часть описания. Это связано с тем, что модели обучаются на огромных наборах данных, но не обладают способностью к абстрактному мышлению и пониманию причинно-следственных связей, необходимых для точного воспроизведения сложных композиций.
Современные диффузионные модели, несмотря на впечатляющие результаты в генерации изображений по текстовому описанию, требуют колоссальных вычислительных ресурсов. Этот факт ограничивает их доступность и масштабируемость, особенно при работе с изображениями высокого разрешения или сложными сценами. Более того, точное управление процессом генерации, необходимое для получения желаемых деталей или специфической композиции, представляет значительную сложность. Даже небольшие изменения в текстовом запросе могут приводить к непредсказуемым результатам, что затрудняет создание изображений, точно соответствующих задуманному. Необходимость в огромных вычислительных мощностях и недостаточный контроль над процессом генерации являются ключевыми препятствиями на пути к созданию более эффективных и универсальных систем преобразования текста в изображения.
Современные генеративные модели, преобразующие текст в изображения, часто сталкиваются с трудностями при создании сложных сцен из-за особенностей работы с многомерными латентными пространствами. Эти пространства, по сути, являются абстрактными представлениями данных, где каждое измерение соответствует определенной характеристике изображения. Однако, по мере увеличения сложности сцены, количество необходимых измерений экспоненциально растет, что делает навигацию и интерпретацию этих пространств крайне сложной задачей. Представьте \mathbb{R}^n пространство, где n стремится к бесконечности — поиск конкретного изображения в таком пространстве становится практически невозможным. Именно эта сложность ограничивает способность моделей точно понимать и воспроизводить сложные композиции, а также контролировать мельчайшие детали генерируемых изображений, что подчеркивает необходимость поиска новых подходов к представлению и обработке визуальной информации.

RAE: Новый подход к реконструкции изображений
Автоэнкодеры представлений (RAE) обеспечивают разделение этапов извлечения признаков и реконструкции изображения, что позволяет повысить эффективность обучения. Традиционные автоэнкодеры обычно объединяют эти процессы, требуя одновременной оптимизации как энкодера, так и декодера. RAE, напротив, отделяют извлечение признаков, используя предварительно обученные модели, такие как SigLIP-2, в качестве фиксированного энкодера. Это позволяет сосредоточить процесс обучения исключительно на декодере, значительно сокращая вычислительные затраты и позволяя более эффективно работать с латентным пространством признаков.
Архитектура Representation Autoencoders (RAE) позволяет существенно снизить вычислительные затраты за счет использования замороженного энкодера представлений, такого как SigLIP-2. В отличие от традиционных автоэнкодеров, где обучение включает оптимизацию как энкодера, так и декодера, RAE фокусируется исключительно на обучении декодера. Это достигается за счет предварительно обученного энкодера, который извлекает признаки, а декодер отвечает за реконструкцию изображения на основе этих признаков. Такой подход позволяет сократить количество обучаемых параметров и вычислительную сложность, что приводит к более быстрой сходимости и снижению требований к ресурсам.
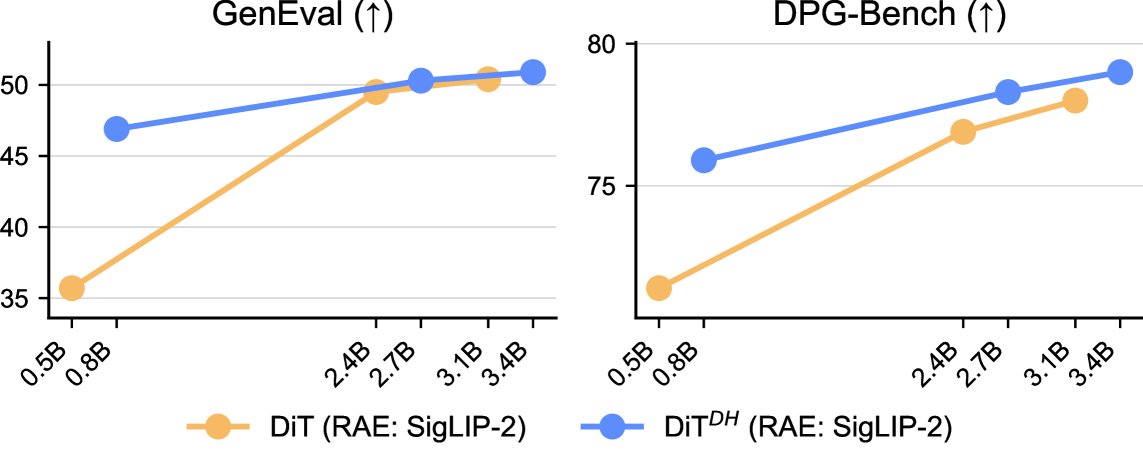
Архитектура Representation Autoencoders (RAE) обеспечивает обучение в более управляемом латентном пространстве, что приводит к повышению качества и контролю над генерируемыми изображениями. В ходе тестирования на бенчмарках GenEval и DPG-Bench, RAE продемонстрировали ускорение сходимости в 4.0 раза и 4.6 раза соответственно, по сравнению с традиционными методами, основанными на Variational Autoencoders (VAE). Данное ускорение обусловлено оптимизацией процесса обучения за счет фокусировки на тренировке декодера, в то время как энкодер представления остается фиксированным.

Оптимизация процесса диффузии для повышения реалистичности
В процессе диффузионного моделирования реализовано планирование шума с учетом размерности (Dimension-Aware Noise Scheduling). Данный подход предполагает индивидуальную настройку уровня добавляемого шума для каждой размерности латентного пространства. Это позволяет более эффективно разрушать структуру данных на начальных этапах диффузии, сохраняя при этом важные детали и повышая точность восстановления изображения на последующих этапах. В отличие от стандартного равномерного добавления шума, адаптивное планирование шума позволяет добиться повышенной детализации и реалистичности генерируемых изображений, особенно в областях, требующих высокой точности представления.
В качестве надежной целевой функции в процессе диффузии используется метод Flow Matching. Он основан на минимизации расхождения между векторным полем, определяющим процесс диффузии, и истинным градиентом вероятностной плотности данных. Это позволяет более эффективно направлять процесс генерации изображений, снижая вероятность появления артефактов и повышая реалистичность получаемых результатов. В отличие от традиционных подходов, использующих вариационный нижний предел, Flow Matching напрямую оптимизирует вероятностную модель, что обеспечивает более стабильное и качественное обучение модели диффузии.
В качестве базовой архитектуры для нашей диффузионной модели используется LightningDiT, что позволяет добиться максимальной производительности и стабильности. LightningDiT представляет собой трансформерную архитектуру, оптимизированную для задач генерации изображений, и характеризуется повышенной эффективностью за счет использования техник дистилляции и квантизации. Применение LightningDiT позволило снизить вычислительные затраты и ускорить процесс обучения модели без потери качества генерируемых изображений, обеспечивая при этом высокую стабильность в процессе инференса и предсказуемые результаты.
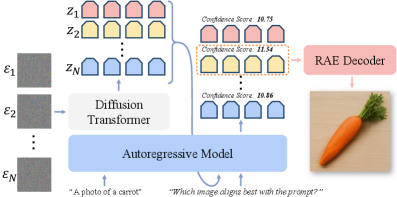
К единой системе визуального интеллекта: горизонты возможностей
Разрабатываемый подход открывает путь к созданию единой модели, способной не только интерпретировать визуальный контент, но и генерировать реалистичные изображения по текстовым запросам. Эта унификация представляет собой значительный шаг вперед в области искусственного интеллекта, поскольку позволяет системе понимать и создавать визуальную информацию в рамках одной архитектуры. Вместо использования отдельных моделей для анализа изображений и генерации контента, предлагаемый подход интегрирует эти функции, что повышает эффективность и открывает новые возможности для приложений, требующих комплексной обработки визуальной информации — от автоматической генерации контента до создания продвинутых систем компьютерного зрения. Такая интеграция позволяет модели извлекать знания из существующих изображений и использовать их для создания новых, более правдоподобных и детализированных визуальных представлений, заданных текстовым описанием.
Методы масштабирования во время тестирования позволяют значительно улучшить качество генерируемых изображений, приближая их к фотореалистичности. Данный подход заключается в многократном применении модели к одному и тому же запросу с незначительными вариациями параметров, что позволяет выявить и усилить наиболее детализированные и правдоподобные элементы изображения. В результате, даже относительно небольшая модель способна создавать визуально сложные и реалистичные изображения, преодолевая ограничения, связанные с вычислительными ресурсами и объемом обучающих данных. Эффективность данного метода подтверждена экспериментально, демонстрируя существенное повышение метрик качества изображения и визуальное превосходство над традиционными подходами к генерации контента.
Для обеспечения эффективного обучения модели на масштабных наборах данных была применена методика SPMD Sharding. Данный подход предполагает распределение вычислительной нагрузки и данных между множеством устройств, что позволяет значительно ускорить процесс обучения и преодолеть ограничения, связанные с объемом памяти одного устройства. Благодаря SPMD Sharding, модель демонстрирует высокую масштабируемость, позволяя обрабатывать и анализировать огромные объемы визуальной информации, что критически важно для создания действительно универсальной системы визуального интеллекта. Такое распределение нагрузки не только сокращает время обучения, но и открывает возможности для дальнейшего увеличения размера модели и, как следствие, повышения её точности и возможностей.
За пределами текущих ограничений: будущее и масштабируемость
Использование больших языковых моделей, таких как Qwen2.5, значительно расширяет семантическое понимание системы. Интеграция этих моделей позволяет системе не просто генерировать данные, но и интерпретировать их смысл, учитывая контекст и нюансы языка. Это достигается благодаря способности Qwen2.5 понимать сложные лингвистические конструкции и взаимосвязи между понятиями, что существенно улучшает качество генерируемого контента и повышает его релевантность. В результате система становится более адаптивной и способной к созданию более осмысленных и когерентных результатов, приближая ее к человеческому уровню понимания и генерации информации.
В рамках исследования использовались вариационные автоэнкодеры, такие как FLUX, в качестве базовых моделей для сравнительного анализа и улучшения существующих генеративных методов. Применение FLUX позволило оценить эффективность разработанных моделей на основе RAE, выявив их превосходство в генерации данных. Такой подход не только подтвердил перспективность предложенной архитектуры, но и обеспечил количественную оценку её преимуществ по сравнению с общепринятыми решениями в области генеративного моделирования. Использование FLUX в качестве эталона обеспечило объективную основу для оценки прогресса и дальнейшей оптимизации разработанных алгоритмов.
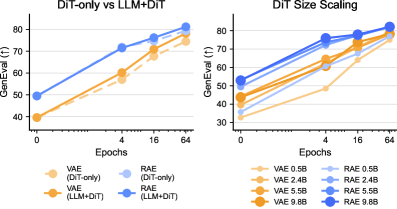
Экспериментальные данные последовательно демонстрируют превосходство разработанных моделей, основанных на архитектуре RAE, над традиционными вариационными автоэнкодерами (VAE) в различных масштабах DiT. В ходе оценки, использующей метрику GenEval, модели RAE неизменно показывают более высокие результаты, что свидетельствует о значительно улучшенном качестве генерируемых данных. Такое превосходство подтверждается стабильностью результатов на разных уровнях сложности DiT, указывая на способность RAE-моделей эффективно моделировать и воспроизводить сложные данные, превосходя существующие генеративные методы по ключевым показателям качества и реалистичности.
Исследование демонстрирует, что Representation Autoencoders (RAE) предлагают более эффективный подход к обучению масштабных моделей преобразования текста в изображение, чем Variational Autoencoders (VAE). Этот метод упрощает процесс обучения и повышает производительность, создавая единую основу для визуального понимания и генерации. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен служить людям, а не наоборот». Эта фраза отражает суть работы, поскольку RAE позволяют создавать более понятные и управляемые модели, расширяя возможности визуального представления информации и делая её доступной для более широкого круга пользователей. Использование RAE открывает путь к более интуитивным и мощным инструментам в области искусственного интеллекта.
Куда дальше?
Представленные результаты демонстрируют, что Автокодировщики Представлений (RAE) представляют собой более элегантный и, возможно, более естественный способ организации латентного пространства для диффузионных моделей, чем традиционные Вариационные Автокодировщики (VAE). Однако, кажущаяся простота не должна вводить в заблуждение. Существующая архитектура, хотя и эффективна, всё ещё требует значительных вычислительных ресурсов для обучения и масштабирования. Ключевым вопросом остаётся поиск методов, позволяющих снизить эту вычислительную нагрузку, не жертвуя качеством генерируемых изображений.
В дальнейшем, необходимо исследовать возможности применения RAE не только для генерации изображений по текстовым запросам, но и для решения более широкого круга задач визуального понимания. Унифицированная модель, способная как генерировать, так и интерпретировать визуальную информацию, представляется всё более вероятной, но её реализация требует преодоления значительных теоретических и практических трудностей. Особый интерес представляет возможность интеграции RAE с другими модальностями, такими как звук и видео, для создания действительно мультимодальных систем.
Нельзя исключать и возможность, что кажущееся преимущество RAE над VAE является лишь следствием специфических параметров обучения и архитектурных решений. Более глубокий анализ латентного пространства, создаваемого RAE, и сравнение его с латентным пространством VAE, может выявить скрытые закономерности и ограничения, определяющие возможности каждой модели. В конечном счете, истинный прогресс требует не слепого следования за новыми архитектурами, а критического осмысления фундаментальных принципов, лежащих в основе машинного обучения.
Оригинал статьи: https://arxiv.org/pdf/2601.16208.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Иллюзия Компетентности: Как ИИ Переоценивает Себя
- Ранжирование как разумный поиск: новая эра оптимизации
- Бреп-Кодер: Искусственный интеллект, понимающий геометрию
2026-01-24 03:20