Автор: Денис Аветисян
Исследователи предлагают инновационную систему, использующую возможности больших языковых моделей для создания перспективных лекарственных соединений.
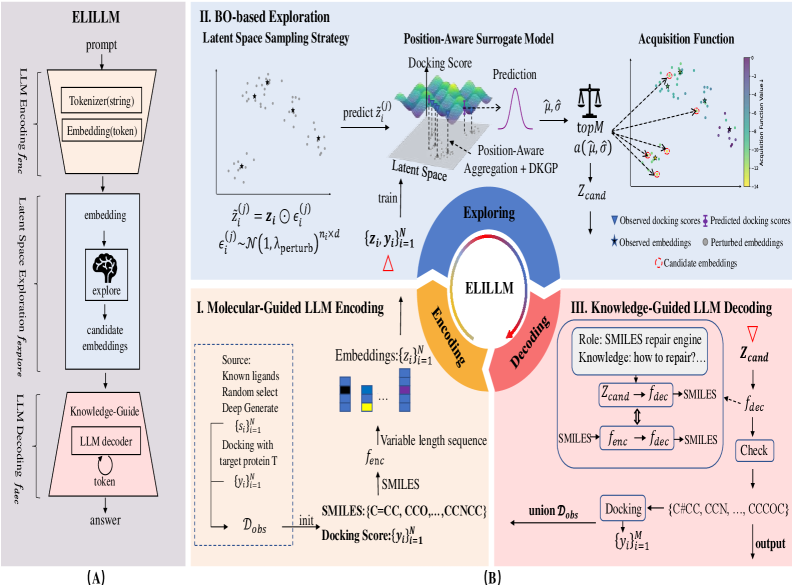
Представленный фреймворк ELILLM оптимизирует процесс молекулярного дизайна, используя байесовскую оптимизацию для исследования латентного пространства больших языковых моделей и генерации молекул с высокой аффинностью.
Несмотря на впечатляющие возможности больших языковых моделей (LLM) в обработке и генерации данных, их применение в рациональном дизайне лекарств, основанном на структуре, ограничено недостаточным пониманием пространственной организации белков и непредсказуемостью процесса генерации молекул. В данной работе, представленной под названием ‘Empowering LLMs for Structure-Based Drug Design via Exploration-Augmented Latent Inference’, предложен фреймворк ELILLM, который интерпретирует генерацию LLM как последовательность кодирования, исследования латентного пространства и декодирования. Используя байесовскую оптимизацию для систематического исследования латентных представлений и механизм декодирования с учетом позиций атомов, ELILLM позволяет генерировать химически валидные и синтетически доступные молекулы с высокой аффинностью к целевым белкам. Сможет ли ELILLM существенно расширить возможности LLM в области разработки новых лекарственных препаратов?
Взлом Молекулярного Пространства: Вызовы и Перспективы
Традиционный подход к разработке лекарственных средств, основанный на структуре, в значительной степени зависит от точного предсказания аффинности связывания молекулы с целевой биомолекулой. В качестве ключевого показателя часто используется Vina Docking Score — метрика, оценивающая прочность взаимодействия. Несмотря на широкое применение, эта методика не лишена ограничений, поскольку точность предсказания аффинности напрямую влияет на успех дальнейших этапов разработки. Недостаточная точность может привести к отбраковке перспективных соединений или, наоборот, к продвижению неэффективных кандидатов, что существенно увеличивает временные и финансовые затраты на создание нового лекарственного препарата. Поэтому постоянное совершенствование методов предсказания аффинности связывания остается актуальной задачей в современной фармацевтической науке.
Эффективное представление молекулярных структур имеет первостепенное значение в современной химии и разработке лекарств. Широко распространенная нотация SMILES, представляющая молекулу в виде текстовой строки, обеспечивает компактность и удобство обработки, однако обладает существенными ограничениями при работе со сложными молекулярными архитектурами. В частности, один и тот же SMILES-код может соответствовать различным изомерам, что затрудняет точное описание трехмерной структуры и, как следствие, предсказание свойств молекулы. Кроме того, SMILES-представление плохо приспособлено для кодирования информации о конформационных свободах и динамике молекулы, что критически важно для понимания ее взаимодействия с биологическими мишенями. В связи с этим, активно разрабатываются альтернативные методы представления молекул, такие как графовые нейронные сети и трехмерные представления, стремящиеся преодолеть недостатки традиционных подходов и обеспечить более полное и точное описание молекулярной структуры.
Первые генеративные модели, такие как вариационные автоэнкодеры и авторегрессионные модели, изначально демонстрировали перспективные результаты в области молекулярного дизайна. Однако, несмотря на их способность создавать новые молекулярные структуры, они часто сталкиваются с трудностями при генерации соединений, обладающих высокой аффинностью к целевым белкам. Проблема заключается в том, что эти модели, как правило, фокусируются на воспроизведении существующих шаблонов, а не на исследовании химического пространства для поиска принципиально новых и эффективных лекарственных кандидатов. В результате, сгенерированные соединения часто оказываются недостаточно активными или обладают неблагоприятными фармакокинетическими свойствами, что ограничивает их практическое применение в разработке лекарств.
Языковые Модели на Службе Химии: Новый Взгляд на Молекулярный Дизайн
Крупные языковые модели (КЯМ) демонстрируют значительные возможности в области рассуждений и обобщения, что делает их перспективными кандидатами для разработки новых молекул. Основываясь на способности КЯМ к прогнозированию последовательностей и пониманию сложных взаимосвязей, они могут быть обучены на больших объемах данных о молекулярных структурах и свойствах. Это позволяет КЯМ генерировать новые молекулярные структуры, предсказывать их свойства и оптимизировать их для конкретных целей, таких как улучшенная эффективность лекарств или новые материалы. Способность к обобщению позволяет моделям создавать молекулы, отличные от тех, на которых они обучались, открывая возможности для инноваций в химической области.
Для непосредственного применения больших языковых моделей (LLM) к задачам молекулярного дизайна требуется преобразование структур молекул в формат, пригодный для обработки LLM. Этот процесс, известный как молекулярное кодирование, создает латентное пространство — многомерное представление молекул, где каждая точка соответствует определенной структуре. В этом латентном пространстве LLM может эффективно исследовать различные молекулярные конфигурации, находить закономерности и генерировать новые структуры, основываясь на заданных критериях. Кодирование позволяет представить сложные химические структуры в виде векторов, что упрощает их обработку и анализ LLM, а также обеспечивает возможность интерполяции между существующими молекулами для создания новых, потенциально полезных соединений.
Ключевая инновация, направленное декодирование (Knowledge-Guided Decoding), заключается во внедрении химических знаний непосредственно в процесс генерации молекул большой языковой моделью (LLM). Это достигается путем модификации процесса декодирования LLM, добавляя штрафы или бонусы, основанные на химических правилах и свойствах. В результате, генерируемые молекулы имеют более высокую химическую валидность — соответствуют правилам валентности и стабильности — и улучшенные целевые свойства, такие как растворимость или биологическая активность. Использование направленного декодирования позволяет снизить количество нереалистичных или нежелательных молекул, генерируемых LLM, повышая эффективность процесса молекулярного дизайна.
ELILLM: Расширенное Исследование Латентного Пространства для Оптимального Дизайна
ELILLM представляет собой фреймворк, использующий подход Exploration-Augmented Latent Inference для эффективной генерации молекул. В его основе лежит синергия между большими языковыми моделями (LLM) и байесовской оптимизацией. LLM используются для изучения латентного пространства молекул, а байесовская оптимизация направляет процесс поиска, эффективно исследуя пространство возможных структур с целью генерации соединений с заданными свойствами. Такой подход позволяет значительно ускорить и оптимизировать процесс разработки новых молекул по сравнению с традиционными методами, требующими ручного вмешательства или менее эффективных алгоритмов поиска.
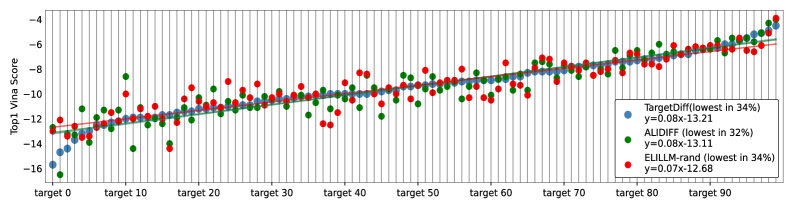
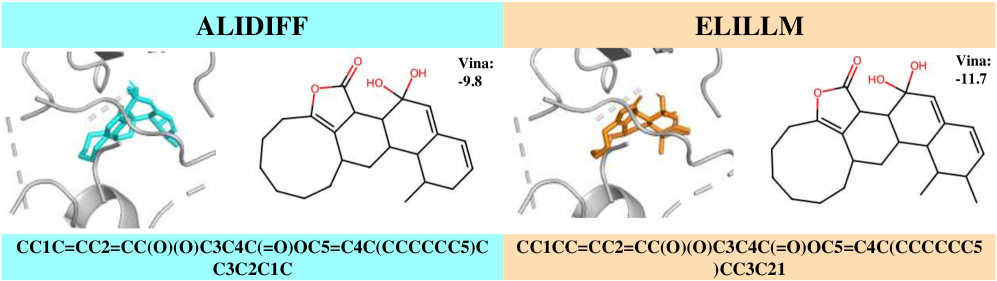
В основе ELILLM лежит модель суррогатного предсказания, ориентированная на позицию в латентном пространстве, которая оценивает аффинность связывания генерируемых молекул. В отличие от традиционных методов, ELILLM не просто оценивает аффинность, но и учитывает положение каждой молекулы в латентном пространстве, что позволяет более точно предсказывать ее свойства. Данная модель используется в процессе байесовской оптимизации для направленного поиска перспективных соединений, существенно повышая эффективность генерации молекул с улучшенной аффинностью связывания по сравнению с существующими подходами, такими как ALIDiff. Фактически, модель суррогатного предсказания выступает в роли ключевого компонента, направляющего процесс генерации молекул к областям латентного пространства, где наиболее вероятно обнаружение соединений с высокой аффинностью.
В ходе тестирования фреймворка ELILLM зафиксировано значительное улучшение аффинности связывания генерируемых молекул по сравнению с моделью ALIDiff. Улучшение составило -4.59% при выборе одного наилучшего кандидата (Top 1), -5.88% при выборе пяти лучших (Top 5), -6.69% при выборе десяти лучших (Top 10) и -7.77% при выборе двадцати лучших (Top 20). Статистическая значимость полученных результатов подтверждена применением непараметрического критерия Вилкоксона (p < 0.05), что указывает на надежность наблюдаемого улучшения аффинности связывания.
ELILLM расширяет принципы Структурно-Ориентированного Молекулярного Дизайна (Structure-Based Drug Design) за счет интеграции байесовской оптимизации и латентного пространства, что обеспечивает надежный и масштабируемый подход к генерации новых молекул с улучшенными свойствами. В отличие от традиционных методов, ELILLM позволяет эффективно исследовать химическое пространство, предсказывая аффинность связывания в латентном пространстве с использованием позиционно-зависимой суррогатной модели. Это позволяет целенаправленно генерировать соединения с повышенной вероятностью проявления желаемых характеристик, обеспечивая более высокую производительность и снижая затраты на скрининг по сравнению с классическими подходами к разработке лекарственных средств.

Раскрытие Потенциала: Будущее Молекулярного Дизайна и Его Влияние
Возможность эффективного исследования химического пространства, обеспечиваемая ELILLM, открывает перспективные пути для создания принципиально новых лекарственных препаратов и материалов. Данный подход позволяет систематически исследовать огромное количество молекулярных структур, предсказывая их свойства и выявляя соединения с желаемыми характеристиками. Вместо традиционных методов, требующих дорогостоящего и трудоемкого синтеза и тестирования, ELILLM предлагает вычислительную платформу для предварительного отбора наиболее перспективных кандидатов. Это значительно ускоряет процесс открытия новых материалов с заданными свойствами, например, повышенной прочностью или улучшенной проводимостью, а также позволяет целенаправленно разрабатывать молекулы, способные эффективно взаимодействовать с биологическими мишенями для лечения различных заболеваний. Таким образом, ELILLM представляет собой мощный инструмент для инноваций в химии и материаловедении, способный значительно сократить время и затраты на разработку новых продуктов.
Архитектура ELILLM демонстрирует значительную масштабируемость, что позволяет проводить высокопроизводительный скрининг и оптимизацию молекулярных свойств. Этот аспект существенно ускоряет процесс разработки лекарственных препаратов, поскольку позволяет исследовать огромное количество химических соединений за короткий промежуток времени. Вместо трудоемких и дорогостоящих лабораторных экспериментов, система способна виртуально оценить потенциал тысяч молекул, выявляя наиболее перспективные кандидаты для дальнейшего изучения. Такой подход не только сокращает временные и финансовые затраты, но и значительно повышает вероятность обнаружения новых терапевтических средств с улучшенными характеристиками, открывая новые горизонты в фармацевтической индустрии и материаловедении.
Дальнейшие исследования направлены на усовершенствование Позиционно-зависимой суррогатной модели и интеграцию более сложных химических знаний в процесс Знание-ориентированного декодирования. Ученые стремятся повысить точность предсказаний и расширить возможности модели в отношении молекулярной структуры и свойств. Ожидается, что уточнение суррогатной модели позволит более эффективно исследовать химическое пространство, а включение углубленных химических знаний значительно улучшит качество генерируемых молекул, повысив их перспективность для разработки новых лекарственных препаратов и материалов. Совершенствование этих аспектов позволит создать более мощный и универсальный инструмент для решения широкого спектра задач в области химии и материаловедения.
Исследование демонстрирует, что подход ELILLM позволяет не просто использовать большие языковые модели, но и активно исследовать их внутреннюю структуру — латентное пространство. Это напоминает о важности понимания фундаментальных принципов любой системы для её эффективного использования. Как однажды заметил Г.Х. Харди: «Математика — это наука о том, что можно логически обосновать». Подобно тому, как математик стремится к строгому обоснованию, ELILLM стремится к оптимизации молекулярного дизайна через осознанное исследование латентного пространства модели, что позволяет создавать соединения с повышенным сродством и, следовательно, улучшает процесс разработки лекарств. Понимание внутренней логики модели открывает путь к её контролируемой эволюции и предсказуемым результатам.
Куда же дальше?
Представленный подход, безусловно, открывает новые горизонты в области компьютерного моделирования лекарств. Однако, не стоит забывать, что каждая оптимизация латентного пространства — это лишь приближение к истинной реальности, а не её точное отражение. Существующие модели всё ещё склонны к генерации соединений, которые выглядят правдоподобно, но могут оказаться недоступными для синтеза или обладать непредсказуемыми свойствами. Следующим шагом видится интеграция с системами, оценивающими не только аффинность, но и синтезируемость молекул, а также их потенциальную токсичность — своего рода “реверс-инжиниринг” биологической совместимости.
Интересно, что истинный прорыв может оказаться не в усовершенствовании алгоритмов оптимизации, а в переосмыслении самой концепции “латинного пространства”. Возможно, необходимо отойти от представления о нём как о статичном контейнере, и рассматривать его как динамическую систему, эволюционирующую под воздействием обратной связи от экспериментов. В конечном итоге, каждый эксплойт начинается с вопроса, а не с намерения — и, возможно, ключ к созданию действительно эффективных лекарств лежит в правильной постановке этих вопросов.
Представляется перспективным исследование возможности использования не только Bayesian Optimization, но и других методов активного обучения для исследования латентного пространства. И, конечно, стоит задуматься о разработке инструментов, позволяющих визуализировать и интерпретировать структуру этого пространства, чтобы понять, какие факторы определяют свойства генерируемых молекул. Ведь понимание системы — значит взломать её.
Оригинал статьи: https://arxiv.org/pdf/2601.15333.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-24 05:06