Автор: Денис Аветисян
Новое исследование сравнивает эффективность различных моделей глубокого обучения для классификации рамановских спектров, выявляя ключевые проблемы, связанные с переносом знаний между наборами данных.
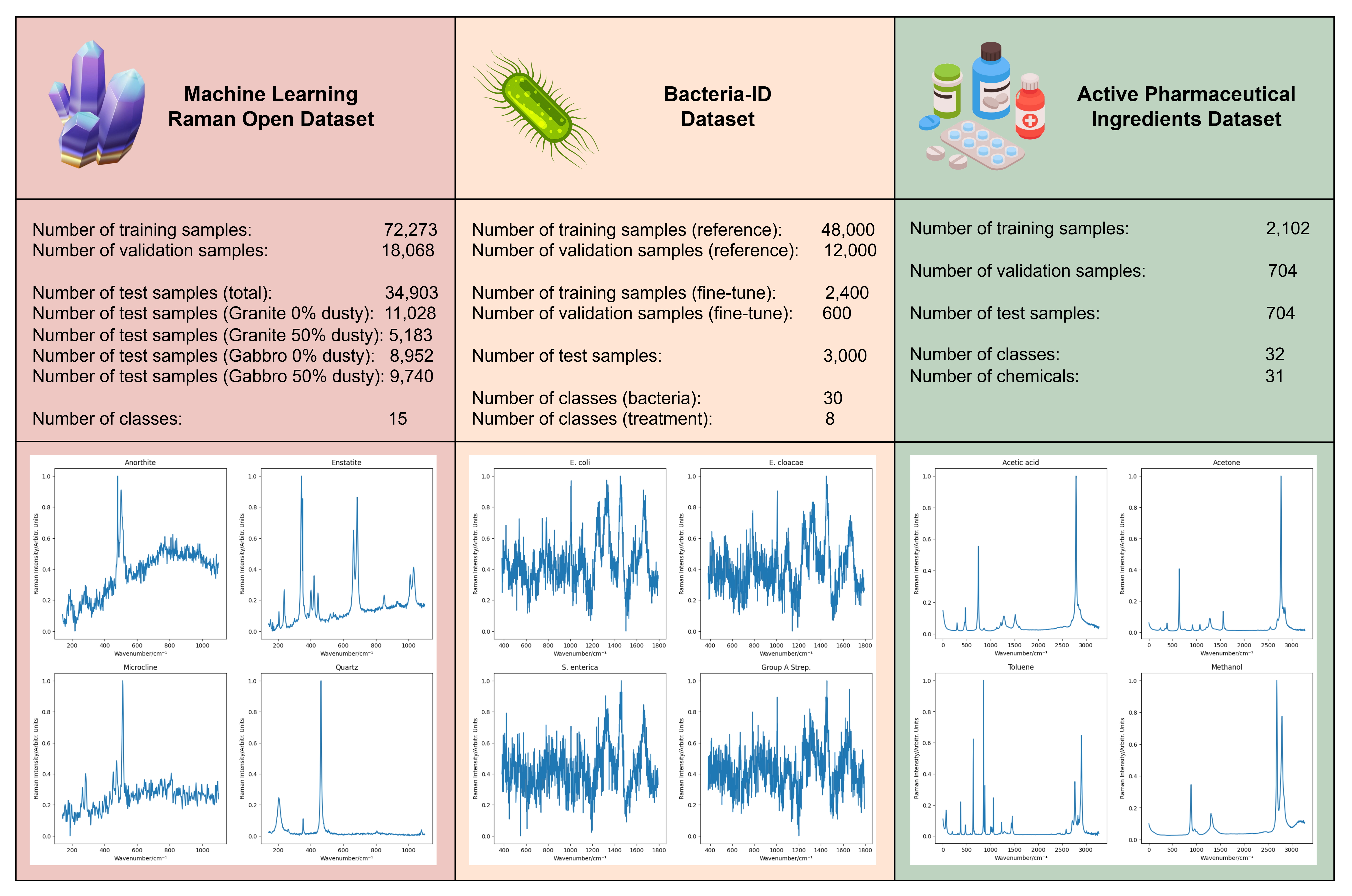
В работе представлен сравнительный анализ пяти моделей глубокого обучения для классификации рамановских спектров на трех открытых наборах данных с акцентом на проблему смещения распределений и потенциал фундаментальных моделей.
Несмотря на растущую популярность глубокого обучения в анализе спектров комбинационного рассеяния, систематических сравнений различных моделей, разработанных специально для этой задачи, до сих пор не хватает. В работе, озаглавленной ‘Benchmarking Deep Learning Models for Raman Spectroscopy Across Open-Source Datasets’, представлен всесторонний сравнительный анализ пяти архитектур глубокого обучения на трех общедоступных наборах данных, что позволяет оценить их эффективность и устойчивость к изменению распределения данных. Полученные результаты демонстрируют важность стандартизированных протоколов обучения и настройки гиперпараметров для обеспечения справедливого и воспроизводимого сравнения моделей. Каковы перспективы дальнейшего развития и применения фундаментальных моделей для повышения точности классификации и снижения затрат на аннотацию данных в спектроскопии Рамана?
Рамановская спектроскопия: Открытие молекулярных отпечатков
Рамановская спектроскопия представляет собой мощный и неразрушающий метод анализа состава материалов, основанный на изучении их молекулярных колебаний. Принцип работы заключается в регистрации рассеянного света, взаимодействующего с веществом, при котором происходит изменение длины волны фотонов в зависимости от типа молекулярных связей и колебаний. Каждый материал обладает уникальным «отпечатком» в виде рамановского спектра, отражающего его химический состав и структуру. Благодаря этому методу возможно идентифицировать компоненты смеси, определить кристаллическую структуру, оценить степень упорядоченности и даже выявить изменения в молекулярной структуре, происходящие в процессе химических реакций или под воздействием внешних факторов. Неразрушающий характер анализа позволяет проводить исследования непосредственно на образце, не нарушая его целостность, что особенно важно при изучении ценных или редких материалов.
Анализ сложных спектров, получаемых с помощью рамановской спектроскопии, требует применения передовых методов обработки данных. Спектры рамановского рассеяния представляют собой богатый источник информации о молекулярном составе и структуре вещества, однако эта информация часто замаскирована в виде сложных паттернов и перекрывающихся сигналов. Для извлечения значимых сведений необходимо использовать алгоритмы, способные эффективно уменьшать размерность данных, выделять ключевые особенности и устранять шумы. К таким алгоритмам относятся методы главных компонент, машинное обучение и другие статистические подходы, позволяющие автоматизировать процесс интерпретации спектров и выявлять тонкие различия между образцами. Успешное применение этих методов открывает возможности для точного и неразрушающего анализа веществ в различных областях науки и техники.
Традиционные методы анализа данных, применяемые к спектрам комбинационного рассеяния света (Рамановским спектрам), часто оказываются неэффективными из-за присущей этим спектрам высокой размерности и изменчивости. Сложность заключается в том, что каждый образец генерирует огромное количество данных, представляющих различные молекулярные колебания, а незначительные изменения в составе или условиях измерения могут приводить к существенным вариациям в спектральной картине. Это затрудняет выделение значимых сигналов, позволяющих однозначно идентифицировать и количественно оценить компоненты образца, и ограничивает возможность широкого применения Рамановской спектроскопии в практических задачах, таких как контроль качества, диагностика материалов и биомедицинские исследования. Неспособность эффективно обрабатывать такие сложные данные препятствует раскрытию всего потенциала этого мощного аналитического метода.
Глубокое обучение для рамановских спектров: Сверточная основа
Глубокие сверточные нейронные сети (ГСНС) стали одним из ведущих решений для классификации спектров Рамана благодаря их способности к иерархическому обучению признакам. В отличие от традиционных методов, требующих ручного извлечения признаков, ГСНС автоматически изучают сложные закономерности в данных спектров Рамана. Это достигается за счет применения последовательных сверточных слоев, которые извлекают признаки низкого уровня (например, пики и полосы) и объединяют их в более сложные и абстрактные представления. Такая иерархическая структура позволяет моделям эффективно обрабатывать высокоразмерные спектральные данные и выделять наиболее релевантные признаки для точной классификации образцов.
В задачах классификации спектров Рамана, глубокие сверточные нейронные сети (Deep CNN) обычно обучаются с использованием функции потерь перекрестной энтропии (Cross-Entropy Loss). Данная функция, математически представляющая собой - \sum_{i=1}^{C} y_i \log(\hat{y}_i) , где y_i — истинное значение класса, а \hat{y}_i — предсказанная вероятность принадлежности к классу, позволяет эффективно оптимизировать модель для максимизации вероятности правильной классификации. Минимизация функции потерь достигается с помощью алгоритмов градиентного спуска, что приводит к корректировке весов сети и повышению точности прогнозов. Функция перекрестной энтропии особенно хорошо подходит для задач многоклассовой классификации, где необходимо определить наиболее вероятный класс из нескольких возможных.
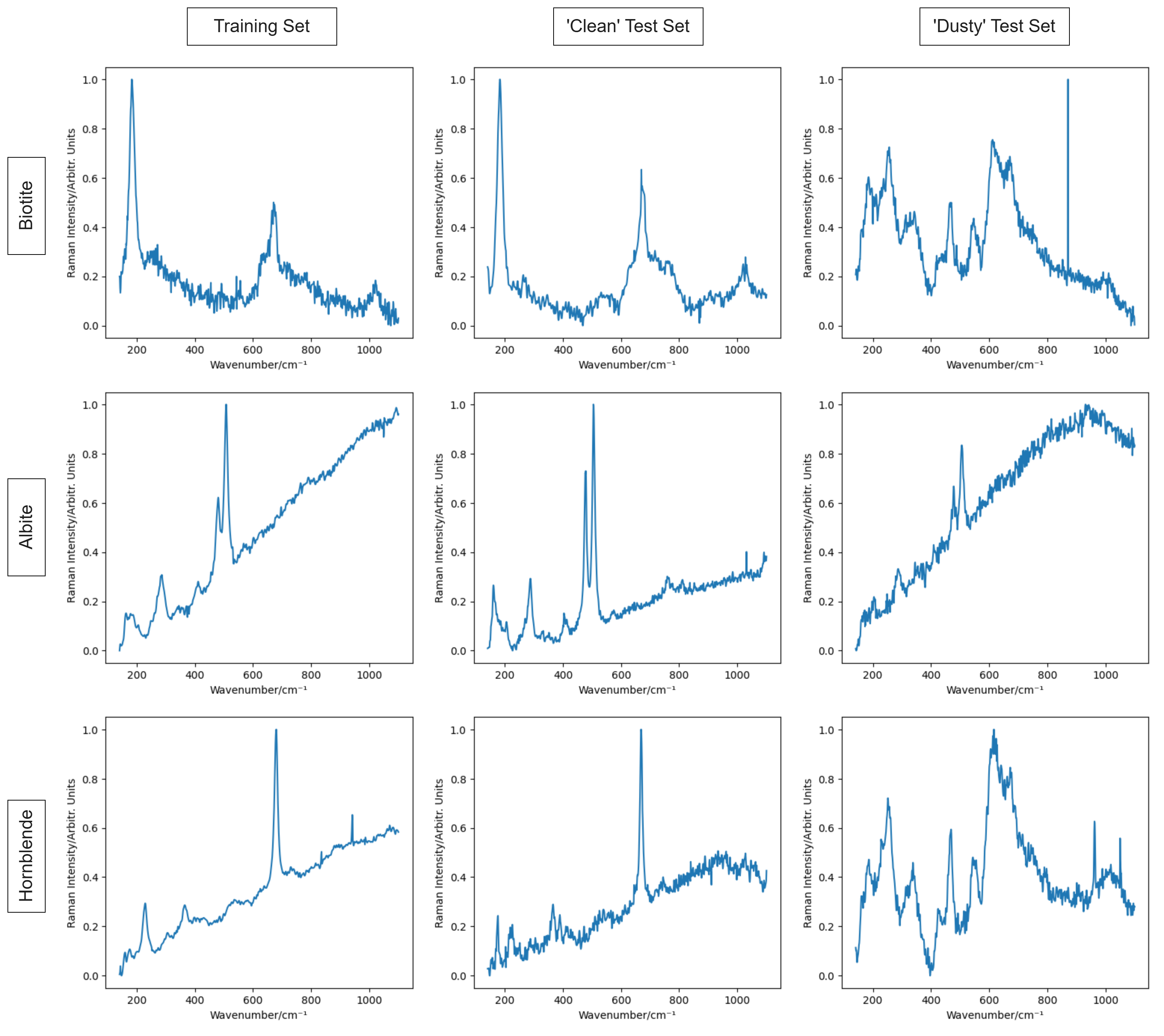
Эффективность моделей глубокого обучения при анализе спектров Рамана может существенно снижаться из-за различий в условиях получения данных и подготовке образцов, что известно как смещение домена (Domain Shift). Набор данных MLROD демонстрирует эту проблему: точность классификации варьируется в диапазоне от 74% до 80%, что указывает на чувствительность моделей к изменениям в процедурах сбора и обработки спектров. Данное явление требует разработки методов адаптации моделей или использования техник, устойчивых к смещению домена, для обеспечения надежной работы в реальных условиях.
Повышение устойчивости: Адаптация к реальным условиям
Неконтролируемая адаптация к домену (Unsupervised Domain Adaptation) представляет собой эффективный метод снижения влияния эффекта смещения домена (Domain Shift), возникающего при применении модели, обученной на одном наборе данных, к данным из другого, отличающегося распределения. Этот подход позволяет модели обобщать данные, которые она не видела во время обучения, без использования размеченных примеров из нового домена. Механизм адаптации заключается в обучении модели находить инвариантные признаки, общие для исходного и целевого доменов, что позволяет ей эффективно переносить знания и сохранять высокую производительность в условиях изменения входных данных. Данный метод особенно актуален в ситуациях, когда получение размеченных данных для целевого домена затруднено или дорогостояще.
Самообучение усиливает устойчивость моделей путем извлечения значимых представлений из немаркированных рамановских спектров, используя присущие спектрам характеристики. Этот подход позволяет модели изучать внутреннюю структуру данных без необходимости в ручной разметке, что особенно важно при работе с большими объемами спектральных данных. В процессе самообучения модель предсказывает части спектра на основе других, тем самым выявляя корреляции и закономерности в данных. Такой способ обучения позволяет модели формировать более обобщенные и робастные представления, не зависящие от конкретных условий получения спектров, что критически важно для адаптации к реальным условиям эксплуатации и вариативности данных.
Фильтрация спектральных компонент является важным этапом предварительной обработки данных, способствующим созданию устойчивых представлений для моделей машинного обучения. Данный процесс включает в себя удаление неинформативных или мешающих спектральных составляющих, таких как флуоресцентный фон или шумы, возникающие в процессе измерения Рамановских спектров. Применение методов, таких как полиномиальная аппроксимация или фильтрация по опорным спектрам, позволяет снизить влияние вариаций, не связанных с анализируемым образцом, и выделить ключевые характеристики спектра. Это, в свою очередь, повышает точность и надежность моделей, особенно при работе с данными, полученными в различных условиях или с использованием различного оборудования.
За пределами стандартных CNN: Многомасштабные и аттеншн-механизмы
Сети с адаптивным масштабом расширяют возможности глубоких сверточных нейронных сетей (CNN) за счет захвата признаков в различных масштабах. Этот подход позволяет более эффективно обнаруживать тонкие спектральные вариации, которые могут быть упущены стандартными CNN, фокусирующимися на признаках определенного размера. Использование нескольких масштабов анализа позволяет модели одновременно учитывать как локальные детали спектра, так и более глобальные тенденции, что особенно важно при анализе сложных спектральных данных, таких как данные Рамановской спектроскопии. Благодаря этому, сети с адаптивным масштабом демонстрируют повышенную чувствительность к незначительным изменениям в спектральном профиле, что критически важно для точной классификации и идентификации различных веществ и микроорганизмов.
В отличие от традиционных свёрточных нейронных сетей (CNN), которые полагаются на трансляционную эквивариантность, RamanNet предлагает иной подход к анализу рамановских спектров. Отказ от этого принципа позволяет модели фокусироваться на локальных особенностях спектра, не привязываясь к их точному положению. Это может привести к созданию более устойчивых к шумам и смещениям моделей, способных выявлять даже незначительные изменения в спектральном профиле. Такой подход потенциально повышает интерпретируемость модели, поскольку акцент делается на значимых спектральных характеристиках, а не на их абсолютном местоположении, что упрощает понимание процесса принятия решений.
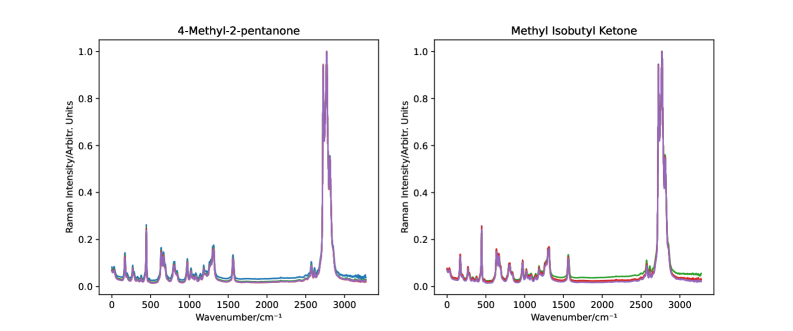
В последнее время архитектуры, основанные на механизмах внимания, и в частности, архитектура Transformer, все активнее применяются для анализа рамановских спектров. Это обусловлено их способностью концентрироваться на наиболее значимых спектральных характеристиках, игнорируя несущественные детали. Проведенные сравнительные испытания показали, что Scale Adaptive Networks (SANet) демонстрируют превосходство над другими моделями: достигнута 100% точность на наборе данных API и 80-86% точность на наборе данных Bacteria-ID при классификации изолятов, а также 96-98% точность при прогнозировании эффективности антибиотиков. Такие результаты подчеркивают потенциал SANet и других attention-based моделей для повышения точности и надежности анализа рамановских спектров в различных областях, включая медицину и материаловедение.
Исследование, представленное в данной работе, демонстрирует важность адаптации моделей глубокого обучения к различным условиям получения данных — проблеме, известной как сдвиг домена. Это особенно актуально для спектроскопии Рамана, где незначительные изменения в настройках прибора или образце могут существенно повлиять на результаты. Как однажды заметил Карл Фридрих Гаусс: «Математика — это наука о бесконечном». Аналогично, бесконечное разнообразие условий получения спектров Рамана требует от моделей не просто запоминания данных, а понимания фундаментальных закономерностей, лежащих в основе спектральных сигналов. Работа подчеркивает потенциал фундаментальных моделей в решении этой задачи, стремясь к созданию систем, способных достойно стареть, сохраняя свою эффективность в меняющихся условиях.
Куда же дальше?
Представленное исследование, хоть и демонстрирует текущее состояние дел в применении глубинного обучения к рамановской спектроскопии, лишь подчеркивает неизбежную хрупкость любой модели перед лицом меняющихся условий. Сравнение производительности на различных наборах данных выявляет не столько абсолютные достоинства той или иной архитектуры, сколько степень её уязвимости к смещению распределений. Каждая абстракция, созданная для классификации спектров, несет в себе отпечаток прошлого — условий, в которых она обучалась, и, следовательно, ограничена в своей применимости.
Перспективы кажутся связанными не с поиском «идеальной» модели, а с разработкой стратегий адаптации и переноса знаний. Появление «фундаментальных моделей» представляется интересным направлением, однако, не стоит забывать, что и они — лишь временное решение. Реальная устойчивость, вероятно, будет достигнута за счет методов, позволяющих моделям эволюционировать вместе с данными, а не просто переобучаться на новых наборах.
В конечном счете, время — не метрика, которую можно оптимизировать, а среда, в которой существуют системы. И задача исследователя — не создать вечную модель, а спроектировать систему, способную достойно стареть, сохраняя свою функциональность даже в условиях неизбежных изменений.
Оригинал статьи: https://arxiv.org/pdf/2601.16107.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-24 05:08