Автор: Денис Аветисян
Исследователи представили Terminal-Bench — платформу для оценки возможностей ИИ-агентов в реалистичных сценариях работы с интерфейсом командной строки.
Terminal-Bench — это новый эталон для оценки и развития ИИ-агентов, способных выполнять сложные задачи в текстовых средах.
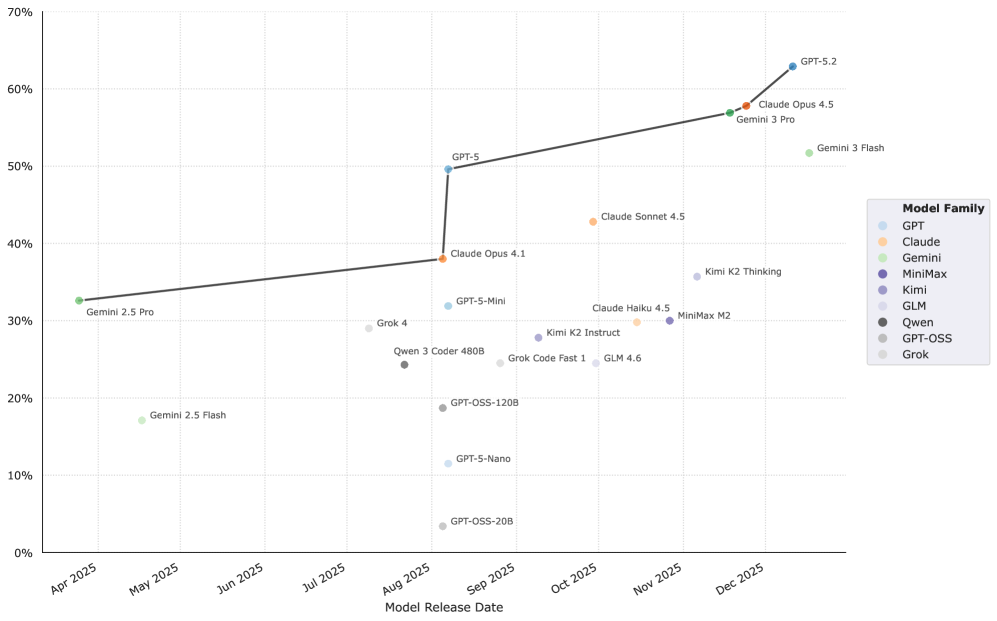
Существующие бенчмарки зачастую не отражают реальной сложности задач, с которыми сталкиваются современные ИИ-агенты. В данной работе, представленной под названием ‘Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces’, авторы предлагают новый, тщательно отобранный набор из 89 задач в среде командной строки, вдохновленных реальными рабочими процессами. Показано, что передовые модели демонстрируют результат менее 65\% на этом бенчмарке, что указывает на существенные области для улучшения. Сможет ли Terminal-Bench стать стандартом для оценки и развития более надежных и автономных ИИ-агентов?
Вызов для надёжной оценки агентов
Для адекватной оценки возможностей искусственного интеллекта, необходимо отойти от использования искусственно созданных тестов и перейти к проверке способности агентов выполнять задачи в реалистичных условиях. Традиционные методы оценки зачастую оперируют упрощенными сценариями, не отражающими всей сложности и непредсказуемости реального мира. Проверка в условиях, приближенных к повседневным задачам, позволяет выявить истинный потенциал агента, его способность к адаптации и решению проблем, с которыми он столкнется в практическом применении. Такой подход обеспечивает более объективную и релевантную оценку, способствующую прогрессу в области разработки интеллектуальных систем.
Существующие методы оценки возможностей искусственного интеллекта часто не отражают всей сложности и многогранности реальных взаимодействий в командной строке, что существенно замедляет прогресс в данной области. В отличие от упрощенных тестовых сценариев, практическое применение требует от агентов не только точного выполнения инструкций, но и умения адаптироваться к непредсказуемым ситуациям, интерпретировать неоднозначные запросы и справляться с ошибками. Ограниченность текущих оценочных фреймворков в воспроизведении этих реальных условий приводит к завышенной оценке возможностей моделей в лабораторных условиях и, как следствие, к трудностям при их внедрении в практические приложения. Недостаток нюансов в тестах не позволяет выявить истинный потенциал агентов и определить области, требующие дальнейшего развития.
Эффективная оценка возможностей искусственного интеллекта требует точного измерения способности агента интерпретировать инструкции и адаптироваться к непредсказуемым обстоятельствам. Современные передовые модели демонстрируют успешное выполнение задач лишь в немногим более чем 65% случаев в реалистичных средах командной строки, что подчеркивает необходимость разработки более сложных и требовательных эталонов для оценки. Данный показатель указывает на существенные пробелы в понимании и применении естественного языка, а также в способности агентов к решению проблем, возникающих в реальных пользовательских сценариях. Соответственно, создание более надежных и репрезентативных бенчмарков является ключевым шагом к развитию действительно интеллектуальных и полезных ИИ-систем.
Terminal-Bench: Реалистичная платформа для оценки
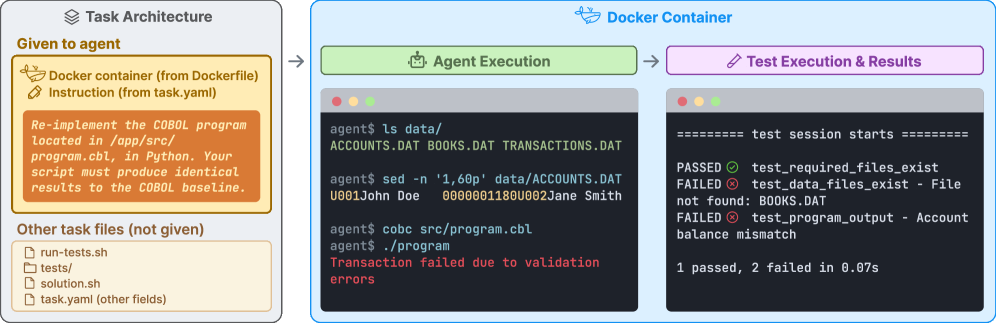
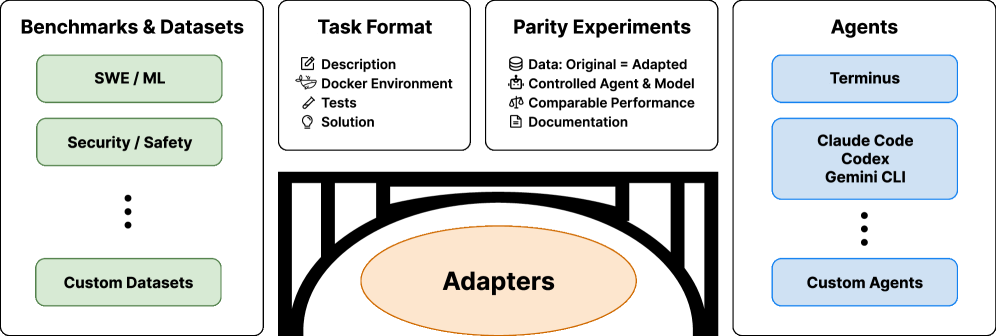
Terminal-Bench представляет собой комплексную платформу, включающую 89 задач, разработанных для оценки производительности агентов в реалистичных средах командной строки. Эти задачи охватывают широкий спектр сценариев, имитирующих повседневные операции в Linux, такие как управление файлами, работа с текстом, навигация по файловой системе и выполнение системных команд. Среда выполнения каждой задачи обеспечивается с использованием Docker-образов, что гарантирует воспроизводимость результатов и стандартизацию условий тестирования для различных моделей и агентов. Задачи разработаны таким образом, чтобы требовать от агентов не только понимания синтаксиса команд, но и способности планировать последовательность действий для достижения поставленной цели.
Terminal-Bench использует Docker-образы для создания стандартизированных сред выполнения задач, что обеспечивает воспроизводимость результатов. Процесс Формулирования Задач включает в себя чёткое определение инструкций, наборов тестов для автоматизированной проверки и эталонных решений. Такая структура позволяет гарантировать rigor — строгость и надёжность — оценки, поскольку каждая задача имеет заранее заданные критерии успеха и объективные метрики. Это, в свою очередь, позволяет сравнивать различные агенты в единой, контролируемой среде, избегая влияния внешних факторов и обеспечивая валидность результатов.
Использование Terminal-Bench обеспечивает сопоставимую и воспроизводимую оценку различных агентов благодаря стандартизированному набору задач и процедуре оценки. Наши исследования показывают, что модели меньшего размера достигают успеха лишь примерно в 15% случаев при решении задач, представленных в Terminal-Bench, что подтверждает высокую сложность и реалистичность предлагаемого набора тестов и необходимость дальнейшего развития моделей для работы в интерактивных средах командной строки.
Оптимизированная оценка с использованием Harbor и Terminus 2
Фреймворк Harbor обеспечивает инфраструктуру для создания и выполнения оценок агентов в рамках Terminal-Bench. Он предоставляет стандартизированный интерфейс и набор инструментов для определения тестовых сценариев, запуска агентов в контролируемой среде и сбора метрик производительности. Harbor позволяет автоматизировать процесс оценки, обеспечивая воспроизводимость результатов и возможность сравнительного анализа различных агентов. Основными компонентами Harbor являются модуль определения задач, модуль запуска агентов и модуль сбора и анализа данных, что позволяет гибко настраивать и расширять функциональность оценочной системы.
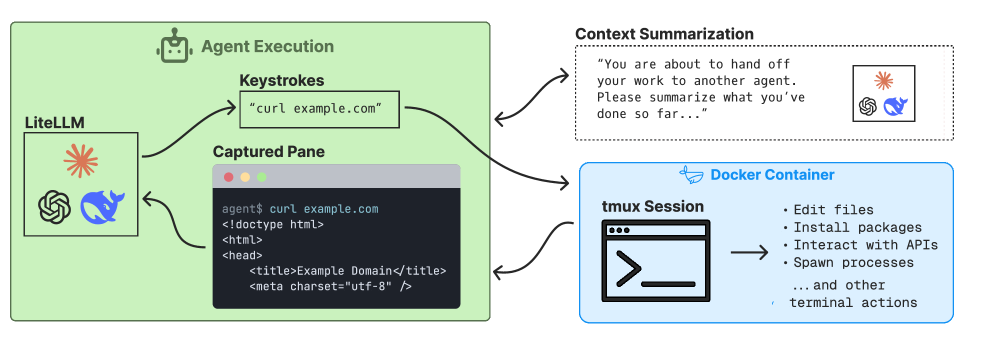
Для обеспечения сопоставимости результатов оценки агентов и минимизации влияния посторонних факторов, мы используем Terminus 2 — минимального агента, реализованного исключительно на языке командной строки Bash. Это позволяет создать контролируемую среду, в которой все агенты выполняют задачи с использованием одного и того же базового набора инструментов и возможностей, исключая различия, связанные с использованием других языков программирования или сторонних библиотек. Использование Bash в качестве единственного инструментария обеспечивает воспроизводимость экспериментов и упрощает анализ производительности различных агентов, фокусируясь исключительно на их логике и алгоритмах решения задач.
Использование предложенной инфраструктуры позволяет эффективно измерять ключевые показатели эффективности (KPI), такие как количество эпизодов (Episode Count) и количество токенов в выходных данных (Output Token Count). Количество эпизодов отражает необходимое количество итераций для достижения цели, а количество токенов указывает на объем вычислительных ресурсов, затраченных агентом. Анализ этих показателей позволяет объективно оценить эффективность агента, его способность к рассуждениям и оптимизации процесса решения задач, а также сравнить производительность различных агентов в единой среде.
Глубокий анализ ошибок с помощью LLM Judging
Для проведения детального анализа ошибок, разработан и внедрен автоматизированный инструмент — “LLM Judge”. Этот инструмент использует большие языковые модели для оценки результатов работы агентов и классификации возникающих ошибок в соответствии со структурированной иерархической таксономией. Такой подход позволяет не просто констатировать факт неудачи, но и точно определить ее природу — от синтаксических ошибок в командах до логических нестыковок в рассуждениях агента. Использование иерархической таксономии обеспечивает гранулярность анализа, позволяя выявлять как общие тенденции, так и специфические проблемы, возникающие в конкретных сценариях. Результаты классификации служат основой для дальнейшей оптимизации агентов и улучшения их способности к решению сложных задач.
Автоматизированная категоризация ошибок, осуществляемая с помощью специализированных моделей, предоставляет ценные сведения о сложностях, с которыми сталкиваются агенты, и указывает на перспективные направления для дальнейшей разработки. Этот подход позволяет выйти за рамки общих показателей производительности и получить детальное представление о причинах неудач, классифицируя их по иерархической таксономии. В результате исследователи получают возможность не просто констатировать факт ошибки, но и понимать её природу — будь то неверная интерпретация инструкций, недостаток знаний в конкретной области или ограничения в возможностях планирования. Такая детализация способствует более целенаправленной работе над улучшением агентов, позволяя сосредоточить усилия на устранении конкретных проблем и повышении их надежности и эффективности в различных сценариях.
Систематическое выявление и классификация ошибок, допущенных агентами, позволяет выйти за рамки поверхностных оценок их производительности и углубиться в понимание их реальных возможностей. Традиционные метрики, такие как точность или скорость выполнения задач, часто не отражают коренные причины неудач. Подробный анализ ошибок, с использованием иерархической таксономии, выявляет конкретные области, где агенты испытывают трудности, будь то проблемы с пониманием инструкций, недостаток знаний в определенной области, или неспособность адаптироваться к новым ситуациям. Такой подход позволяет перейти от простого измерения успеха или неудачи к выявлению конкретных узких мест и направлению усилий по улучшению агентов именно в тех областях, где это наиболее необходимо. В конечном итоге, это способствует созданию более надежных, адаптивных и эффективных интеллектуальных систем.
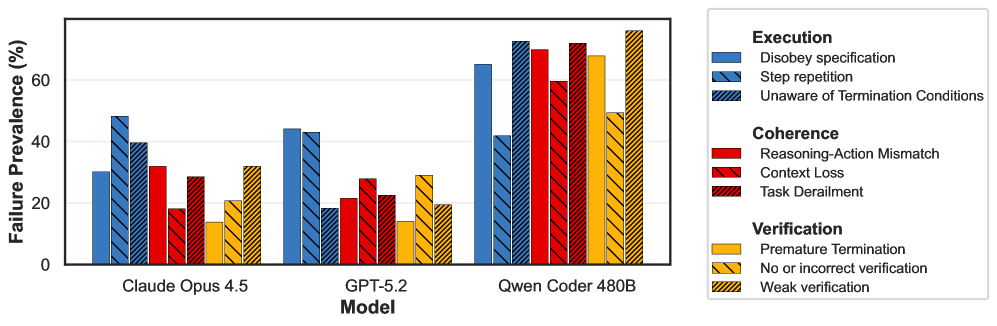
Представленная работа демонстрирует стремление к созданию надёжной и масштабируемой системы оценки AI-агентов в реалистичных терминальных средах. Авторы акцентируют внимание на сложности задачи, предлагая бенчмарк, который проверяет не только способность агента к выполнению отдельных команд, но и его устойчивость к непредсказуемости реального мира. Этот подход перекликается с принципом, высказанным Г.Х. Харди: «Математика — это наука о том, что можно логически доказать, а не о том, что можно вычислить». Аналогично, Terminal-Bench оценивает не просто вычислительные возможности агента, а его способность к логическому мышлению и адаптации в сложных, нетривиальных ситуациях. Подобная оценка принципиально важна для развития действительно надёжных и полезных AI-систем, поскольку хорошая архитектура незаметна, пока не ломается, и именно надёжность является ключевым фактором при оценке систем в реальных условиях.
Куда же дальше?
Представленный фреймворк, Terminal-Bench, подобен тщательно сконструированному мосту. Он позволяет оценить возможности агентов в реалистичной среде, но не следует забывать: мост всегда уязвим на стыках. Истинно сложная задача не в создании агента, успешно выполняющего предписанные действия, а в предвидении тех ситуаций, где его логика неизбежно даст сбой. Всё ломается по границам ответственности — если их не видно, скоро будет больно. Поэтому, дальнейшее развитие должно быть направлено не только на повышение эффективности, но и на выявление этих самых границ.
Важно понимать, что оценка агента в изолированной среде — лишь часть картины. Реальный мир полон неопределенности, контекста и неявных правил. Следующим шагом видится создание сред, моделирующих не только технические задачи, но и социальные взаимодействия, неполную информацию и необходимость адаптации к меняющимся условиям. Оценка должна учитывать не только «что» делает агент, но и «как» он это делает — насколько его действия прозрачны, объяснимы и соответствуют ожиданиям пользователя.
Структура определяет поведение. Простое увеличение масштаба тестовых данных или усложнение задач не решит фундаментальную проблему: агент, лишенный понимания контекста и способности к обобщению, останется хрупкой конструкцией. Необходимо сместить фокус с «решения задач» на «построение систем», способных к самообучению, самодиагностике и самовосстановлению. И тогда, возможно, мы приблизимся к созданию действительно разумных агентов.
Оригинал статьи: https://arxiv.org/pdf/2601.11868.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Экзотические разложения: новые грани цилиндрической алгебры
- Командная работа агентов: обучение без обновления модели
- Иллюзия Компетентности: Как ИИ Переоценивает Себя
- Навыки агентов: Новый уровень интеллекта ИИ
2026-01-24 08:34