Автор: Денис Аветисян
Новое исследование показывает, как читатели оценивают достоверность и надежность научных резюме, созданных с помощью больших языковых моделей.
Исследование посвящено оценке восприятия доверия и качества информации в научных обзорах, сгенерированных или дополненных большими языковыми моделями, и анализу способности читателей определять авторство ИИ.
Несмотря на растущую роль больших языковых моделей (LLM) в научной коммуникации, сохраняется неопределенность относительно восприятия читателями текстов, созданных или отредактированных искусственным интеллектом. Исследование под названием ‘LLM or Human? Perceptions of Trust and Information Quality in Research Summaries’ посвящено изучению того, как читатели оценивают доверие и качество научных рефератов, созданных LLM или людьми. Полученные результаты показывают, что участники испытывают трудности с надежным определением авторства LLM, однако осведомленность об участии ИИ существенно влияет на оценку качества и достоверности текста, при этом рефераты, отредактированные LLM, получают более высокие оценки. Какие новые нормы и правила использования ИИ в научной сфере необходимо разработать для обеспечения прозрачности и поддержания доверия к научным исследованиям?
Раскрытие Нового Ландшафта Научной Коммуникации
В настоящее время наблюдается стремительное распространение больших языковых моделей (БЯМ), что оказывает существенное влияние на способы распространения научных знаний. Этот процесс поднимает важные вопросы об аутентичности и достоверности научной информации. Ранее основой оценки качества исследований считалось установление авторства, однако появление текстов, созданных искусственным интеллектом, ставит под сомнение традиционные критерии. В результате, возникает необходимость в пересмотре подходов к оценке научных публикаций и разработке новых методов, позволяющих достоверно определять происхождение контента и обеспечивать доверие к научным результатам. Подобные изменения требуют от научного сообщества адаптации к новым реалиям и поиска эффективных решений для сохранения целостности научной коммуникации.
Традиционные методы оценки качества научных исследований исторически опирались на восприятие человеческого авторства, считая, что креативность, критическое мышление и ответственность за представленные данные неотделимы от работы ученого. Однако, стремительное развитие искусственного интеллекта, в особенности генеративных моделей, ставит под сомнение этот основополагающий принцип. Возникающая способность ИИ создавать тексты, неотличимые от написанных человеком, не только размывает границы между оригинальным исследованием и автоматизированной генерацией контента, но и требует переосмысления критериев, по которым оценивается научная работа. Возникает необходимость в разработке новых метрик и методов оценки, которые учитывают не только содержание, но и происхождение информации, чтобы обеспечить достоверность и надежность научных публикаций в условиях все более широкого распространения ИИ-генерируемого контента.
Исследование показало, что читатели не способны надежно определить, был ли научный абстракт создан человеком или большой языковой моделью (LLM), демонстрируя результаты, близкие к случайным. Этот тревожный факт подчеркивает серьезную проблему в определении источника научной информации и ставит под сомнение традиционные методы оценки качества исследований, основанные на предположении о человеческом авторстве. Неспособность отличить текст, сгенерированный искусственным интеллектом, от текста, написанного человеком, создает риски для научной коммуникации и требует разработки новых подходов к проверке достоверности и отслеживанию происхождения научных работ.
Изучение того, как читатели воспринимают и оценивают научные аннотации, созданные как человеком, так и большими языковыми моделями, становится критически важным в условиях стремительно меняющегося информационного ландшафта. Поскольку всё больше научных текстов генерируются искусственным интеллектом, способность читателей различать авторство и оценивать достоверность информации подвергается серьезному испытанию. Понимание когнитивных процессов, определяющих восприятие аннотаций, позволит выявить факторы, влияющие на доверие к научным результатам, и разработать стратегии для поддержания целостности научной коммуникации. Данное исследование направлено на выявление особенностей оценки аннотаций, написанных разными способами, с целью определения рисков и возможностей, связанных с распространением контента, созданного искусственным интеллектом, в научной среде.
Спектр Убеждений Читателей: Ориентация в Новом Мире
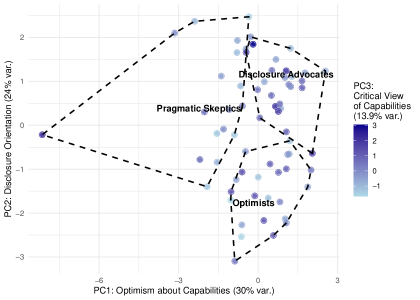
Аудитория воспринимает контент, сгенерированный большими языковыми моделями (LLM), с различной степенью оптимизма, скептицизма и приверженности принципам прозрачности. Наше исследование выявило, что эти предварительные установки оказывают существенное влияние на оценку качества и достоверности текста. Наблюдается широкий спектр мнений: от пользователей, полностью принимающих потенциал LLM, до тех, кто выражает серьезные сомнения в их надежности. Уровень доверия к LLM-контенту варьируется в зависимости от индивидуальных убеждений и опыта, что необходимо учитывать при оценке восприятия и эффективности подобных технологий.
В ходе исследования были выявлены различные установки читателей по отношению к контенту, генерируемому большими языковыми моделями (LLM). Эти установки варьируются от позитивного восприятия и веры в потенциал LLM («Оптимисты») до критической оценки и сомнений в их надежности («Прагматичные скептики»). Установки оказывают значительное влияние на оценку качества и достоверности генерируемого текста. Наблюдается, что читатели с разными установками интерпретируют один и тот же контент по-разному, что необходимо учитывать при анализе восприятия LLM-генерируемого контента.
Согласно проведенному исследованию, 39,13% участников выразили убеждение в необходимости четкой маркировки контента, сгенерированного языковыми моделями (LLM). Данная группа, обозначенная как «Сторонники раскрытия информации», считает, что прозрачность в отношении использования LLM является ключевым фактором для поддержания доверия к представленному материалу. Они подчеркивают важность информирования читателя о том, что контент создан или обработан искусственным интеллектом, независимо от его фактического качества или достоверности. Эта ориентация свидетельствует о растущей осведомленности и озабоченности по поводу влияния LLM на восприятие информации.
Предварительные установки читателей оказывают существенное влияние на их восприятие абстрактных понятий качества и достоверности генерируемого LLM контента. Исследование показало, что субъективные оценки, такие как “качество” и “достоверность”, не являются объективными характеристиками текста, а формируются под воздействием уже существующих убеждений и предвзятостей. В частности, читатели с оптимистичным отношением к LLM склонны оценивать контент как более качественный и заслуживающий доверия, даже при наличии фактических неточностей, в то время как прагматичные скептики, напротив, проявляют повышенную критичность и склонны к негативным оценкам. Данный эффект подтвержден статистически значимыми различиями в оценках одной и той же информации в зависимости от предварительной ориентации респондентов.
Методология: Деконструкция Реакции Читателей
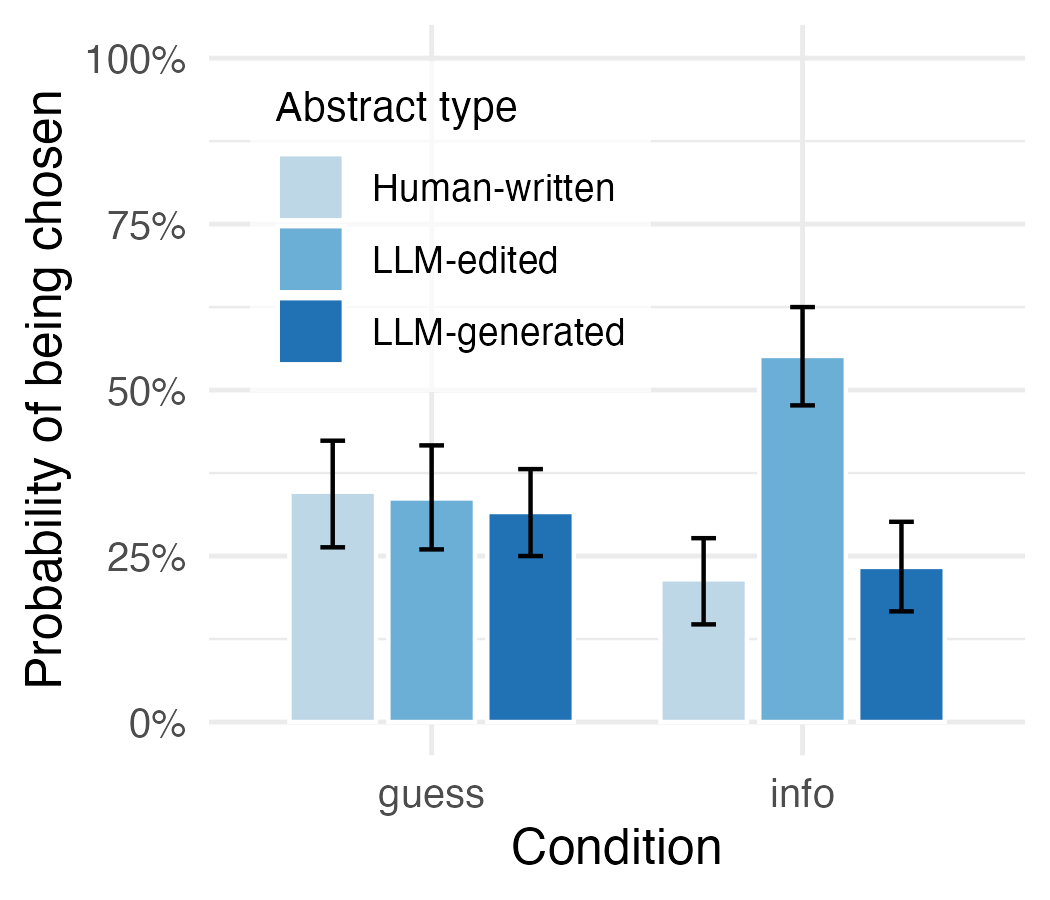
Для оценки реакции читателей было проведено исследование, в рамках которого использовались три типа аннотаций: написанные человеком («HumanWrittenAbstract’s»), сгенерированные языковой моделью («LLMGeneratedAbstract’s») и отредактированные языковой моделью («LLMEditedAbstract’s»). Каждый участник исследования получил для анализа одну из этих аннотаций, выбранную случайным образом. Целью данного подхода было сравнение восприятия и оценки аннотаций, созданных различными способами, и выявление потенциальных различий в интерпретации и доверии к ним.
Для детального анализа интерпретаций участников исследования использовался качественный подход, основанный на тематическом анализе и индуктивном кодировании. Тематический анализ подразумевает выявление повторяющихся паттернов смыслов в текстовых данных, полученных от участников. Индуктивное кодирование, в свою очередь, предполагает, что коды и темы формируются непосредственно из данных, а не на основе заранее определенных категорий. Данный метод позволил избежать предвзятости и обеспечить глубокое понимание того, как участники воспринимают и интерпретируют различные типы аннотаций — ‘HumanWrittenAbstract’s’, ‘LLMGeneratedAbstract’s’ и ‘LLMEditedAbstract’s’ — а также формируют оценки их качества и достоверности.
В рамках исследования проводился анализ ответов участников с целью выявления закономерностей, связывающих их предвзятость (reader orientation), тип аннотации (HumanWrittenAbstract, LLMGeneratedAbstract, LLMEditedAbstract) и оценки качества и достоверности представленной информации. Анализ был направлен на определение, как исходные установки читателей влияют на их восприятие и оценку аннотаций, созданных разными способами, и какие характеристики аннотаций коррелируют с более высокими оценками качества и надежности. Особое внимание уделялось выявлению статистически значимых связей между этими факторами для определения, какие типы аннотаций лучше всего воспринимаются читателями с различной предвзятостью.
Последствия для Научной Добросовестности: Эволюция Критериев Оценки
Исследование показало, что восприятие аннотаций, или рефератов, в значительной степени зависит от предварительной установки читателя, а не от фактического качества написанного текста. Это означает, что первоначальные ожидания и убеждения аудитории формируют оценку содержания, зачастую затмевая объективные показатели ясности, логичности и информативности. Установлено, что даже при идентичном качестве аннотации, различные группы читателей, обладающие разным опытом или предвзятостями, могут прийти к совершенно разным выводам о ее достоинствах. Данный феномен подчеркивает важность учета психологических факторов при оценке научных работ и указывает на необходимость критического подхода к интерпретации полученных результатов, вне зависимости от их формального представления.
Исследование показало неожиданный результат: раскрытие информации об использовании языковых моделей (LLM) при создании научных аннотаций, вопреки ранее наблюдаемому эффекту “штрафа за раскрытие”, фактически повышает уровень доверия и восприятие качества текста. Участники эксперимента демонстрировали более позитивную оценку аннотаций, в которых явно указывалось участие LLM, по сравнению с аннотациями, где эта информация отсутствовала. Данный феномен предполагает, что прозрачность в отношении использования искусственного интеллекта может способствовать укреплению доверия к научным публикациям, особенно в условиях растущего объема контента, созданного при помощи ИИ, и может изменить подход к оценке научной работы, смещая акцент с авторства на содержание и методологию исследования.
Исследование продемонстрировало, что участники не смогли надежно отличить научные аннотации, созданные человеком, от тех, что сгенерированы языковой моделью. Эта неспособность выявлять происхождение текста ставит под сомнение эффективность существующих методов обнаружения авторства и указывает на их ограниченность в условиях широкого распространения контента, созданного искусственным интеллектом. Полученные данные подчеркивают необходимость разработки более совершенных инструментов и подходов к верификации источников научной информации, способных учитывать возрастающую сложность и реалистичность текстов, генерируемых современными языковыми моделями. Невозможность достоверного определения авторства поднимает важные вопросы о прозрачности и ответственности в научной коммуникации.
Полученные результаты имеют существенные последствия для поддержания научной добросовестности и укрепления доверия в условиях растущего объема контента, созданного искусственным интеллектом. Поскольку различить тексты, написанные человеком и языковой моделью, становится все сложнее, возникает необходимость в переосмыслении подходов к оценке научной работы. Важно сместить акцент с простой атрибуции авторства на критическую оценку содержания, проверку источников и прозрачность процесса создания. В отсутствие надежных инструментов для выявления текстов, сгенерированных ИИ, ключевым становится не столько установление авторства, сколько обеспечение достоверности и обоснованности представленных данных и выводов, что требует от научного сообщества повышенного внимания к методологии и верификации результатов исследований.
В условиях растущего объема информации, создаваемой искусственным интеллектом, критическая оценка становится ключевым навыком для обеспечения достоверности научных исследований. Необходимо переходить от слепой веры в источник к тщательной проверке содержания и прозрачности происхождения данных. Акцент должен быть сделан на верификации фактов, анализе методологии и оценке логической последовательности аргументов, а не на простом определении авторства. Повышение осведомленности о возможностях и ограничениях языковых моделей, а также развитие инструментов для выявления предвзятости и манипуляций, представляются необходимыми шагами для поддержания целостности научной коммуникации и укрепления доверия к результатам исследований.
Исследование показывает, что восприятие достоверности научных резюме напрямую связано с прозрачностью их создания. Если читатель знает о содействии больших языковых моделей, уровень доверия, как ни парадоксально, возрастает. Это подчеркивает важность детерминированности в оценке информации: четкое понимание процесса генерации текста позволяет судить о его надежности. Как заметил Г.Х. Харди: «Математика — это искусство делать точные выводы из неточных предпосылок». В данном контексте, предоставление информации об участии ИИ является тем самым «точным предположением», позволяющим читателю правильно оценить «вывод» — содержание резюме и степень доверия к нему.
Что дальше?
Представленное исследование, хотя и демонстрирует интуитивную потребность в раскрытии информации об участии больших языковых моделей, лишь слегка касается фундаментальной проблемы: доверия как такового. Утверждение о повышении доверия при раскрытии информации — это, скорее, констатация факта, что прозрачность — необходимое, но недостаточное условие для истинной валидации. В конечном итоге, абстракт, созданный человеком или машиной, должен быть измерен не по источнику, а по внутренней непротиворечивости и соответствию эмпирическим данным. Проблема не в том, кто написал, а в том, что написано.
Следующий этап должен быть направлен на разработку метрик, позволяющих объективно оценивать качество и достоверность научных резюме, независимо от их авторства. Ирония в том, что мы тратим значительные усилия на обнаружение искусственного интеллекта, вместо того чтобы сосредоточиться на улучшении самого процесса научной коммуникации. Очевидно, что алгоритмы обнаружения всегда будут отставать от алгоритмов генерации — это бесконечная гонка, лишенная математической элегантности.
В конечном счете, истинный прогресс заключается не в определении, «человек это или машина», а в создании систем, где человек и машина работают совместно, дополняя сильные стороны друг друга. Но даже в этом симбиозе, необходимо помнить: алгоритм должен быть доказуем, а не просто «работать на тестах». Любое решение либо корректно, либо ошибочно — промежуточных состояний не существует.
Оригинал статьи: https://arxiv.org/pdf/2601.15556.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Иллюзии понимания: Почему нейросети нас обманывают
2026-01-24 10:07