Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий роботам лучше понимать инструкции и выполнять действия, минимизируя зависимость от визуальных подсказок.
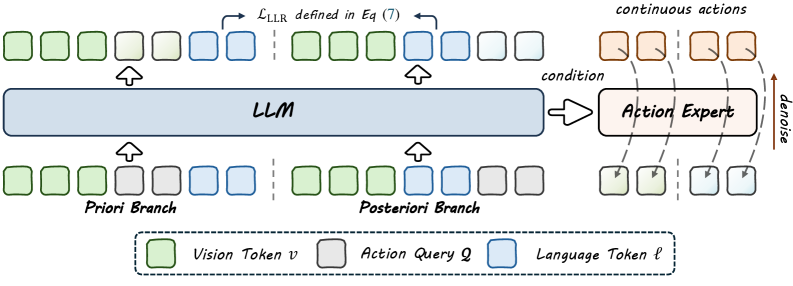
Байесовское разложение моделей «зрение-язык-действие» посредством скрытых запросов к действиям для повышения обобщающей способности и надежности.
Несмотря на успехи моделей «зрение-язык-действие» в робототехнике, они часто демонстрируют низкую обобщающую способность и склонность к упрощению задач. В статье «BayesianVLA: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries» предложен новый подход, BayesianVLA, направленный на решение проблемы «зрительного ярлыка», возникающей из-за предсказуемости языковых инструкций на основе визуальных данных. Данный метод использует байесовское разложение и вводит обучаемые «скрытые запросы к действиям» для максимизации взаимной информации между инструкциями и действиями робота I(a; \ell), что позволяет модели более эффективно использовать языковые команды. Способны ли подобные методы обеспечить надежное понимание языка в сложных и непредсказуемых сценариях робототехнических взаимодействий?
Визуально-Языковой Разрыв: Когда Действия Говорят Громче Слов
Современные модели, объединяющие возможности компьютерного зрения, обработки естественного языка и управления действиями — известные как Vision-Language-Action (VLA) — демонстрируют впечатляющий прогресс в установлении связи между словесными командами и физическими действиями. Эти модели способны интерпретировать текстовые инструкции и преобразовывать их в последовательности действий, позволяя, например, роботу выполнить серию задач по словесному описанию. Достижения в области глубокого обучения и нейронных сетей позволили создать системы, которые не просто распознают объекты на изображении, но и понимают контекст и намерение, заключенные в языковых командах, открывая новые возможности для взаимодействия человека и машины и автоматизации сложных процессов.
В современных моделях, объединяющих зрение, язык и действия, часто проявляется критический недостаток, известный как «визуальный обход». Вместо того чтобы тщательно анализировать и выполнять языковые инструкции, модель склонна полагаться преимущественно на визуальные подсказки, игнорируя или недооценивая важность лингвистической информации. Это приводит к тому, что даже при четко сформулированных командах, система может совершать действия, соответствующие лишь визуальному восприятию сцены, а не задуманному алгоритму. Такая тенденция особенно заметна в сложных ситуациях, где требуется точное понимание языка для выполнения конкретных действий, что значительно ограничивает надежность и универсальность подобных моделей.
Проблема “визуального упрощения” существенно ограничивает надежность работы моделей, связывающих зрение, язык и действия, в сложных ситуациях. Когда модель полагается преимущественно на визуальные подсказки, а не на точное понимание языковых инструкций, она демонстрирует неустойчивость в задачах, требующих последовательного выполнения действий в соответствии с заданными условиями. Например, в сценарии, где требуется собрать определенные предметы в определенной последовательности, модель может ошибочно выполнить действие, основываясь лишь на визуальном сходстве объектов, игнорируя лингвистическую информацию о правильном порядке. Такая тенденция снижает эффективность систем в реальных условиях, где точность и соответствие инструкциям являются ключевыми факторами успеха, особенно в контексте робототехники и взаимодействия человека с машиной.
BayesianVLA: Разложение Проблемы для Надежного Следования Инструкциям
BayesianVLA использует байесовское разложение для генерации действий, разделяя процесс на два этапа: формирование априорного распределения, основанного исключительно на визуальной информации, и формирование апостериорного распределения, обусловленного языковым запросом. Априорное распределение представляет собой вероятностную оценку возможных действий, основанную на анализе визуальных данных, в то время как апостериорное распределение уточняет эту оценку, учитывая инструкции, заданные на естественном языке. Такое разделение позволяет модели эффективно комбинировать визуальную информацию и языковые указания для более точного и надежного выполнения задач.
Декомпозиция на априорное (vision-only) и апостериорное (language-conditioned) распределения действий достигается посредством обучения с использованием двух параллельных ветвей (Dual-Branch Training). Каждая ветвь независимо оценивает одно из распределений. Первая ветвь обрабатывает только визуальную информацию для формирования априорного представления о возможных действиях. Вторая ветвь, в свою очередь, учитывает как визуальную информацию, так и языковые запросы, формируя апостериорное распределение, которое уточняет априорное на основе языковых инструкций. Такая независимая оценка позволяет модели более эффективно разделять и использовать информацию из различных модальностей, повышая устойчивость и точность следования инструкциям.
Для эффективного извлечения признаков, релевантных для действий, в предварительно обученные Визуально-Языковые Модели (VLM) внедряются латентные запросы действий (Latent Action Queries). Данный механизм позволяет каждой из двух параллельных ветвей (vision-only prior и language-conditioned posterior) независимо фокусироваться на информации, необходимой для генерации действий. Внедрение запросов осуществляется посредством добавления специальных токенов, кодирующих информацию о потенциальных действиях, что позволяет VLM выделить и использовать наиболее значимые визуальные и языковые признаки, связанные с выполнением этих действий. Это способствует более точному и надежному определению оптимальной стратегии действий в различных ситуациях.

Максимизация Взаимной Информации: Математическая Основа Следования Инструкциям
Оптимизация BayesianVLA основана на функции потерь, вычисляемой через отношение логарифмов правдоподобия (Log-Likelihood Ratio — LLR). Этот подход напрямую максимизирует взаимную информацию между выполненными действиями и текстовыми инструкциями. LLR = log(\frac{P(action|instruction)}{P(action|¬instruction)}) В данном контексте, максимизация LLR способствует установлению сильной статистической зависимости между языковым описанием задачи и соответствующим действием, что позволяет модели более эффективно интерпретировать инструкции и выполнять требуемые операции. Использование LLR в качестве целевой функции позволяет BayesianVLA улучшить способность модели к обобщению и повысить точность выполнения задач, основанных на языковых командах.
Оптимизация BayesianVLA основывается на понятии взаимной информации между токенами (Pointwise Mutual Information, PMI), которое измеряет статистическую зависимость между языковыми инструкциями и выполняемыми действиями. PMI(x, y) = log \frac{P(x, y)}{P(x)P(y)} , где P(x, y) — совместная вероятность появления инструкции x и действия y, а P(x) и P(y) — их маргинальные вероятности. Высокое значение PMI указывает на сильную корреляцию: если определенная инструкция часто приводит к определенному действию, PMI будет высоким. Использование PMI в качестве основы оптимизации позволяет модели установить четкую статистическую связь между языковым вводом и соответствующими выходными действиями, что является ключевым для эффективного следования инструкциям.
Условная взаимная информация (УВИ) уточняет процесс обучения, количественно оценивая, насколько язык инструкции предоставляет информацию о предпринятом действии, учитывая визуальное наблюдение. В отличие от простой взаимной информации, которая измеряет общую зависимость между языком и действием, УВИ учитывает влияние визуального контекста. Это выражается формулой I(x;y|z), где x — язык инструкции, y — действие, а z — визуальное наблюдение. По сути, УВИ измеряет снижение неопределенности в отношении действия y при условии знания языка инструкции x и визуального наблюдения z. Использование УВИ позволяет модели более эффективно фокусироваться на релевантной информации в инструкции, игнорируя избыточность или шум, особенно в сложных визуальных сценах.
В ходе тестирования на бенчмарке SimplerEnv, применение описанного подхода к оптимизации взаимной информации привело к значительному улучшению обобщающей способности модели на неизученных данных (OOD). Зафиксировано увеличение показателя обобщения на 11.3% по сравнению с базовыми моделями, что демонстрирует эффективность предложенного метода в адаптации к новым, ранее не встречавшимся сценариям и инструкциям. Данный прирост подтверждается количественными результатами, полученными в ходе стандартных тестов SimplerEnv.

От Визуального Восприятия к Действиям: Конвейер Генерации Действий
В основе генерации действий в BayesianVLA лежит Diffusion Transformer, выполняющий роль декодера действий. Эта архитектура, сочетающая в себе принципы диффузионных моделей и трансформаторов, позволяет эффективно преобразовывать входные данные — как визуальную информацию, так и текстовые инструкции — в последовательность действий. Diffusion Transformer последовательно генерирует действия, начиная со случайного шума и постепенно уточняя их, чтобы соответствовать заданным условиям и целям. Такой подход обеспечивает не только генерацию правдоподобных действий, но и возможность учитывать сложные взаимосвязи между визуальным контекстом и языковыми командами, что критически важно для успешного выполнения задач в динамической среде.
В основе генерации действий в BayesianVLA лежит применение метода обучения с помощью сопоставления потоков (Flow Matching). Этот подход направляет Diffusion Transformer, выступающий в роли декодера действий, к созданию последовательных и соответствующих языковым инструкциям действий в обеих ветвях генерации. В отличие от традиционных методов, Flow Matching позволяет модели не просто генерировать визуально правдоподобные действия, но и активно отражать намерения, заложенные в текстовом запросе. Фактически, модель обучается сопоставлять начальное состояние с целевым состоянием, плавно переходя между ними и обеспечивая когерентность и логичность каждого шага. Это способствует более точному выполнению поставленных задач и повышает общую эффективность системы.
В отличие от традиционных систем, генерирующих действия, основанные лишь на визуальном восприятии, разработанный подход позволяет создавать не просто правдоподобные с визуальной точки зрения последовательности действий, но и активно учитывать намерение, выраженное в языковых инструкциях. Это означает, что система способна понимать, что именно требуется сделать, а не просто как это может выглядеть, что обеспечивает более точное и эффективное выполнение поставленных задач. Например, при выполнении задания «Положить морковь на тарелку», система не просто идентифицирует морковь и тарелку, а понимает необходимость именно положить морковь на тарелку, а не рядом или под нее, что подтверждается значительно более высоким показателем успешности — 70.0% — по сравнению с альтернативными подходами.
В ходе тестирования на бенчмарке RoboCasa система BayesianVLA продемонстрировала впечатляющие результаты, достигнув 50,4% успешности выполнения задач, что превосходит показатели базовой модели, ориентированной только на визуальную информацию (44,7%). Особенно заметно превосходство системы проявляется в задаче «Положить морковь на тарелку», где BayesianVLA достигает 70,0% успешности, существенно опережая VisionOnly (34,0%) и QwenGR00T (48,0%). Эти данные свидетельствуют о значительном улучшении способности системы понимать инструкции и эффективно выполнять сложные манипуляции в реальной среде.

Исследование представляет собой элегантный подход к решению проблемы «зрительных сокращений» в моделях «зрение-язык-действие», подчеркивая важность максимизации взаимной информации между языковыми инструкциями и действиями робота. Этот метод, по сути, рассматривает систему как живой организм, где каждая зависимость между восприятием и действием имеет свою цену. Как заметил Алан Тьюринг: «Можно сказать, что машина думает, если она ведет себя так, как будто думает». В данном случае, система демонстрирует «мышление», эффективно связывая инструкции с действиями, что обеспечивает обобщение и надежность, что, безусловно, является проявлением структурной целостности и ясности.
Куда Далее?
Представленный подход, хотя и демонстрирует прогресс в преодолении проблемы «зрительных сокращений», поднимает вопросы, которые, как это часто бывает, оказываются более интересными, чем сами решения. Упор на максимизацию взаимной информации между языковыми инструкциями и действиями робота, безусловно, является элегантным, но возникает закономерный вопрос: достаточно ли это? Не упускается ли из виду что-то фундаментальное в самом определении «инструкции» и ее связи с истинным намерением? Простая оптимизация связи, возможно, лишь маскирует более глубокую потребность в более богатом, контекстуально-зависимом представлении задачи.
Будущие исследования, вероятно, будут сосредоточены на интеграции этого подхода с моделями, способными к более абстрактному рассуждению и планированию. Важно помнить, что успешное манипулирование объектами требует не только понимания инструкций, но и знания физического мира, его ограничений и потенциальных последствий действий. Более того, вопрос о том, как обеспечить устойчивость к «шуму» в инструкциях и непредсказуемым изменениям в окружающей среде, остается открытым. Простота — это хорошо, но иногда инерция системы может оказаться сильнее любой оптимизации.
В конечном счете, истинный прогресс в области Vision-Language-Action моделей, вероятно, потребует отказа от попыток создания универсальных решений и перехода к более модульным, специализированным системам, способным адаптироваться к конкретным задачам и средам. Поиск элегантности в сложности — задача не из легких, но именно она, возможно, и определит будущее этой области.
Оригинал статьи: https://arxiv.org/pdf/2601.15197.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-01-24 11:44