Автор: Денис Аветисян
Новое исследование показывает, что качество предварительной обработки данных является ключевым фактором успеха при использовании техники Embedding Retrofitting в системах генерации ответов на основе поиска.
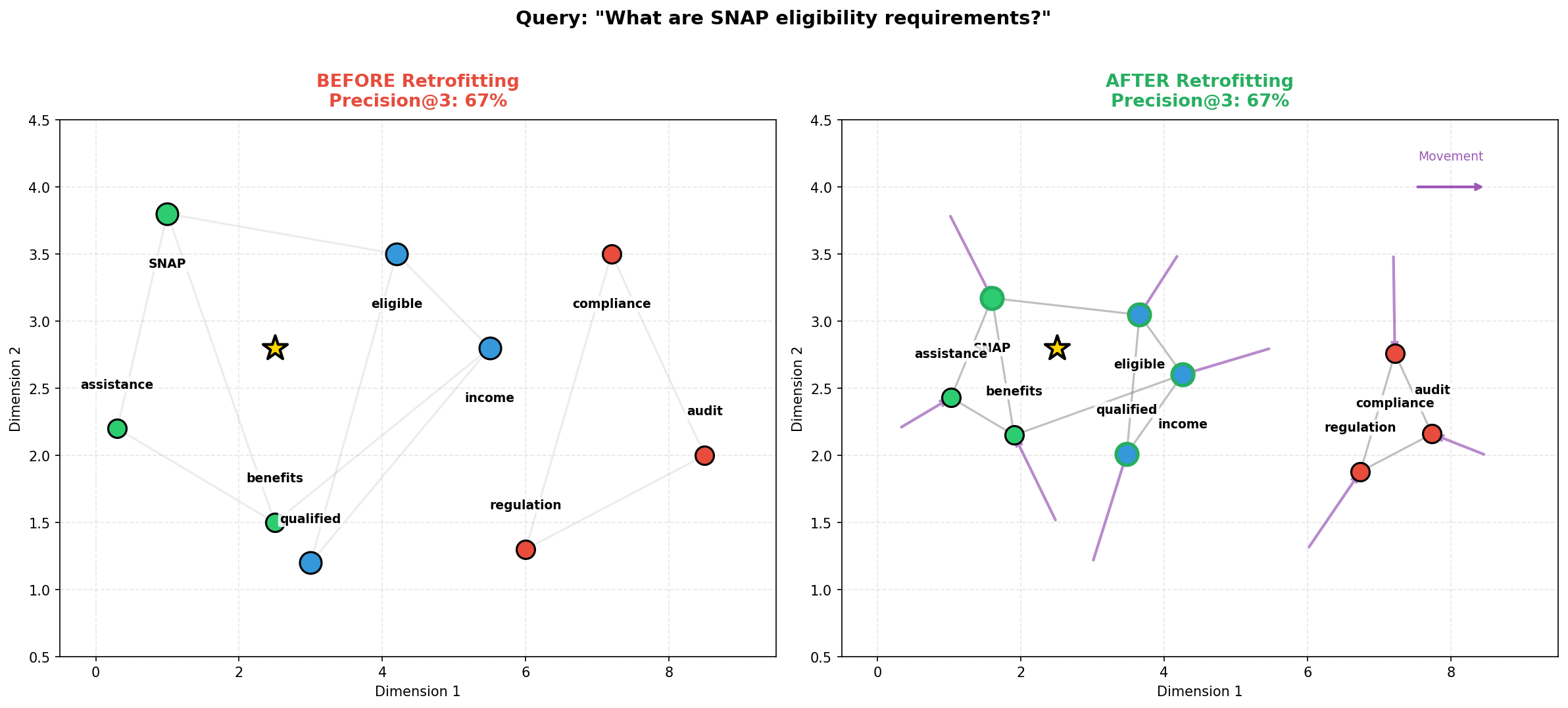
Эффективная инженерная подготовка данных значительно повышает качество поиска и, как следствие, точность ответов в системах Retrieval-Augmented Generation.
Несмотря на перспективность методов встраивания знаний для улучшения поисково-генеративных систем (RAG), их эффективность критически зависит от качества используемых данных. В работе ‘Embedding Retrofitting: Data Engineering for better RAG’ исследуется влияние качества предобработки текстовых данных на процесс корректировки векторных представлений слов с использованием графов знаний. Показано, что тщательно спроектированный конвейер предобработки позволяет не только устранить артефакты аннотаций, приводящие к искажению графа знаний, но и добиться статистически значимого улучшения качества поиска — до 6.2\% — по сравнению с использованием необработанных данных. Не является ли качество предобработки данных определяющим фактором успеха методов корректировки встраиваний, превосходящим различия между самими алгоритмами?
Шум в Данных: Вызовы для Векторных Представлений
Предварительно обученные векторные представления слов, такие как Word2Vec, GloVe и BERT, служат надёжной семантической основой для многих задач обработки естественного языка. Однако, их эффективность существенно снижается при работе с зашумленными данными. Эти модели, несмотря на свою способность улавливать общие закономерности языка, оказываются уязвимы к артефактам и нерелевантным корреляциям, присутствующим в реальных корпусах текстов. Изначально созданные для работы с чистыми данными, они испытывают трудности в интерпретации и обобщении информации, когда сталкиваются с шумом, что приводит к снижению точности и ухудшению результатов в задачах, требующих глубокого понимания смысла.
Анализ корпусов реальных данных, например, из компании ZeroG Financial Services, выявил наличие ложных корреляций, возникающих из-за аннотаций хештегами, что негативно сказывается на производительности моделей. Измерение так называемого «Коэффициента Шума» показало значение 0.96 в исходных данных, что свидетельствует о значительном уровне нежелательных артефактов. Данные корреляции приводят к формированию неверных семантических связей, искажая представление о реальных отношениях между понятиями и, как следствие, снижая точность выполнения задач, требующих понимания смысла текста.
Шум, присутствующий в данных, проявляется в формировании некорректных семантических связей, что негативно сказывается на эффективности выполнения задач, требующих глубокого понимания смысла. В частности, при использовании векторных представлений слов для систем ответов на вопросы, неточности в отношениях между понятиями приводят к снижению качества предоставляемых ответов. Система может выдавать нерелевантную информацию или давать неверные заключения, поскольку её способность к логическому выводу и пониманию контекста искажается зашумлёнными данными. Это особенно заметно в сложных вопросах, требующих интеграции знаний из различных источников, где даже небольшие погрешности в семантических связях могут привести к существенным ошибкам в ответе.
В отличие от зашумленных корпусов, таких как данные ZeroG Financial Services, законодательная база HR-1 предоставляет ценный контраст, демонстрируя потенциал высококачественных данных. Исследования показали, что предварительная обработка данных для удаления артефактов аннотации, например, избыточных хештегов, может кардинально изменить результаты ретрофитинга. Вместо деградации производительности, наблюдаемой в исходных зашумленных данных (снижение на 5.2%), применение методов очистки позволяет добиться значительного улучшения — до -3.5%. Это подчеркивает критическую важность разработки и внедрения методик снижения уровня шума в реальных данных, поскольку качество входных данных напрямую влияет на эффективность последующих задач обработки естественного языка.
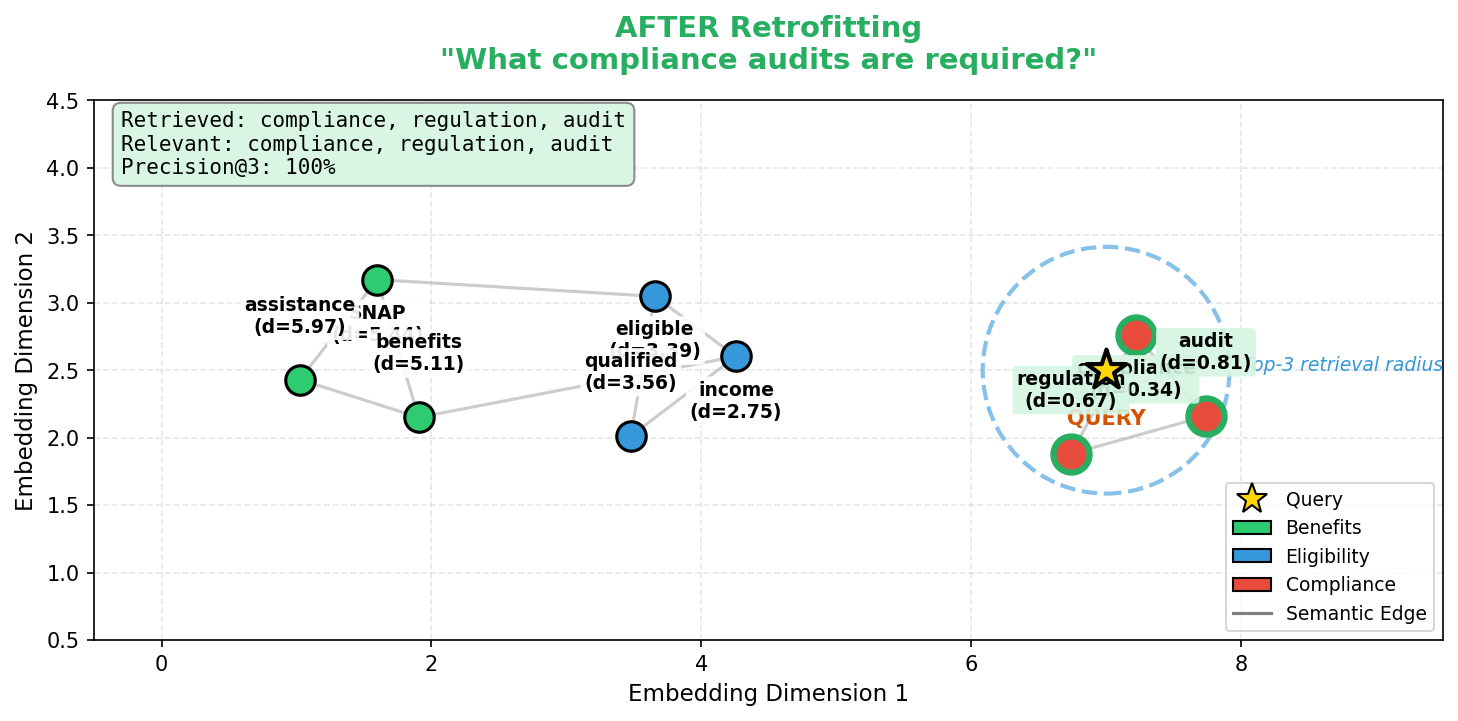
Ретрофитинг для Релевантности: Согласование Векторных Представлений со Знаниями
Метод ретрофитинга векторных представлений предполагает корректировку предобученных векторных представлений с целью соответствия реляционным ограничениям, полученным из графа знаний. В процессе ретрофитинга, векторы слов или сущностей изменяются таким образом, чтобы отражать известные отношения между ними, заданные в графе знаний. Это достигается путём минимизации функции потерь, которая измеряет несоответствие между существующими векторными представлениями и реляционными ограничениями, определёнными в графе знаний. Фактически, ретрофитинг позволяет “настроить” существующие векторные представления, чтобы они более точно отражали семантические связи, зафиксированные в структурированных знаниях.
Процесс ретрофитинга эмбеддингов направлен на то, чтобы обеспечить точное отражение семантических связей в векторном пространстве. Это достигается путем корректировки предобученных эмбеддингов в соответствии с реляционными ограничениями, полученными из графа знаний. Точное представление семантических отношений критически важно для повышения производительности в задачах, использующих эти эмбеддинги, таких как классификация текста, анализ сходства и ответы на вопросы. Более точное отражение семантики позволяет моделям лучше обобщать и делать более обоснованные прогнозы, улучшая общую эффективность и надежность системы.
Методы ретрофитинга, такие как Attention Retrofitting и EWMA Retrofitting, совершенствуют процесс адаптации векторных представлений путем интеллектуального взвешивания выбора соседних элементов и стабилизации обновлений посредством временной регуляризации. В частности, EWMA Retrofitting демонстрирует более низкий коэффициент вариации — 1.9% — по сравнению с Attention Retrofitting, у которого этот показатель составляет 2.5%. Это указывает на более стабильную и предсказуемую сходимость алгоритма EWMA при адаптации векторных представлений к знаниям, полученным из графов знаний.
Методы ретрофитинга позволяют расширить возможности базовых моделей, таких как Word2Vec, GloVe и BERT, за счет адаптации векторных представлений к знаниям, полученным из графов знаний. Экспериментальные данные демонстрируют улучшение результатов на корпусе ZeroG на 4.8% и на законодательных корпусах с очищенными данными на 6.2%. Данные улучшения свидетельствуют о повышении точности семантического представления слов и сущностей в векторном пространстве, что положительно сказывается на производительности в задачах, требующих понимания контекста и отношений между понятиями.
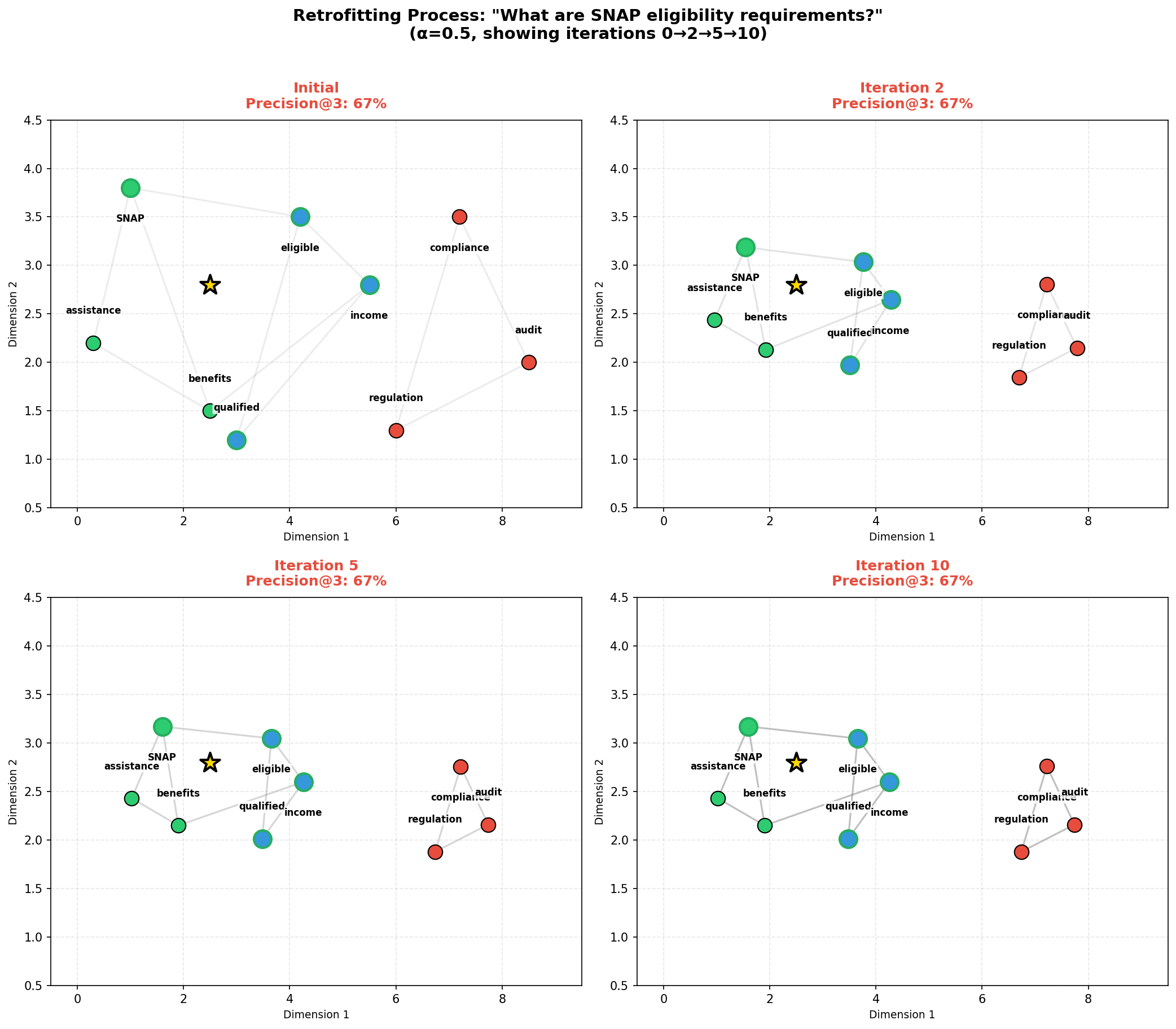
Плотное Извлечение и RAG: Построение Интеллектуальной Системы
Плотное извлечение, использующее векторные базы данных, такие как PostgreSQL с расширением pgvector, обеспечивает эффективный поиск по сходству в ретрофитированном пространстве вложений. Вместо традиционных методов поиска по ключевым словам, плотное извлечение оперирует векторными представлениями документов и запросов. Расстояние между этими векторами в многомерном пространстве определяет степень релевантности. Использование pgvector в PostgreSQL позволяет эффективно хранить и индексировать эти векторы, обеспечивая высокую скорость выполнения поисковых запросов по сходству, что критически важно для систем, работающих с большими объемами данных и требующих быстрого отклика.
Парадигма Retrieval-Augmented Generation (RAG) представляет собой подход, объединяющий этап извлечения релевантной информации с последующей генерацией ответа с использованием больших языковых моделей. В рамках RAG, сначала выполняется поиск наиболее подходящих документов или фрагментов текста на основе семантической близости запроса, а затем найденная информация используется как контекст для языковой модели, что позволяет ей формировать более точные, обоснованные и контекстуально релевантные ответы. Таким образом, RAG позволяет преодолеть ограничения, связанные с объемом знаний, заложенным непосредственно в языковую модель, и использовать внешние источники информации для улучшения качества генерируемого текста.
Метод Retrieval-Augmented Generation (RAG) повышает точность и контекстуальную релевантность ответов на вопросы различного типа — фактические, количественные и качественные — за счет предварительного извлечения релевантных документов. Этот процесс основан на сравнении векторных представлений (эмбеддингов) запроса и документов, что позволяет находить наиболее близкие по смыслу материалы. Вместо генерации ответа исключительно на основе внутренних знаний языковой модели, RAG использует извлеченные документы в качестве контекста, обеспечивая более обоснованные и точные ответы, подкрепленные внешними источниками информации.
Эффективность всего процесса, основанного на извлечении информации и генерации ответов (RAG), напрямую зависит от качества векторных представлений (embeddings), создаваемых методами ретрофитинга и используемой моделью all-MiniLM-L6-v2. Важно отметить, что при плотности графа, превышающей порог 0.05, данный подход не рекомендуется к применению. Проведенные исследования демонстрируют статистически значимое улучшение результатов (p < 0.05) при соблюдении данного ограничения, что указывает на важность контроля плотности графа для обеспечения высокой точности и релевантности извлекаемой информации.
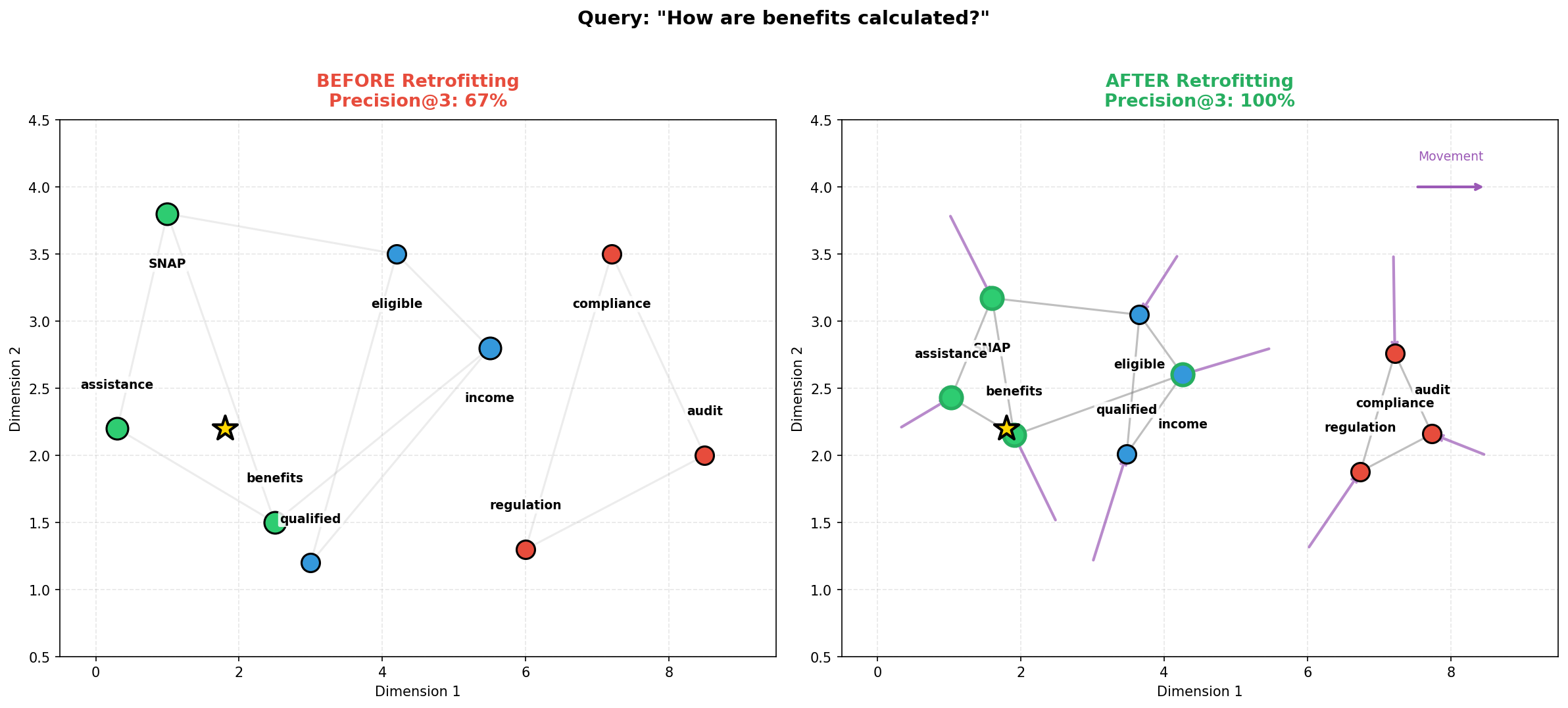
Исследование, представленное в статье, подчеркивает критическую важность предварительной обработки данных для повышения качества извлечения информации в системах генерации с использованием поиска (RAG). Авторы демонстрируют, что тщательно спроектированный конвейер обработки данных может значительно улучшить статистические показатели релевантности. Этот подход резонирует с убеждением, что истинная элегантность алгоритма заключается в его непротиворечивости. Как однажды заметил Линус Торвальдс: «Плохой код похож на плохо построенное здание — рано или поздно рухнет». В контексте RAG, пренебрежение качеством данных — это фундамент, заложенный на шаткой основе, что неизбежно приводит к ухудшению результатов и снижению надежности системы.
Что дальше?
Представленная работа, несомненно, подчеркивает очевидное, но часто игнорируемое: качество входных данных является краеугольным камнем любой системы, даже такой, кажущейся устойчивой к шуму, как генеративные модели с расширенным поиском. Утверждение о статистически значимом улучшении качества поиска посредством ретрофитинга встраиваний, само по себе, не является революционным. Скорее, оно напоминает о фундаментальном принципе: оптимизация без анализа — это самообман и ловушка для неосторожного разработчика. Очевидным следующим шагом представляется не столько поиск новых алгоритмов ретрофитинга, сколько разработка формальных методов оценки влияния препроцессинга данных на метрики релевантности.
Необходимо признать, что предложенный подход, хотя и демонстрирует улучшение, не решает проблему семантического разрыва между структурированными знаниями (например, графами знаний) и векторными представлениями. Более того, вопрос о масштабируемости представленного конвейера препроцессинга для действительно крупных корпоративных баз знаний остается открытым. Следует исследовать возможности автоматизации и адаптации конвейера к различным источникам данных и схемам знаний.
В конечном итоге, истинная элегантность не в сложности алгоритма, а в его способности надежно и предсказуемо решать задачу. Успех в области генеративных моделей с расширенным поиском будет зависеть не от изобретения новых техник встраивания, а от создания систем, способных к самодиагностике и адаптации к изменяющимся условиям, что, в свою очередь, требует глубокого понимания математических основ и строгого подхода к оценке качества.
Оригинал статьи: https://arxiv.org/pdf/2601.15298.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Экзотические разложения: новые грани цилиндрической алгебры
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-24 11:49