Автор: Денис Аветисян
Исследователи предлагают инновационную систему, использующую структурированную семантическую память для повышения эффективности и точности преобразования естественного языка в SQL-запросы.
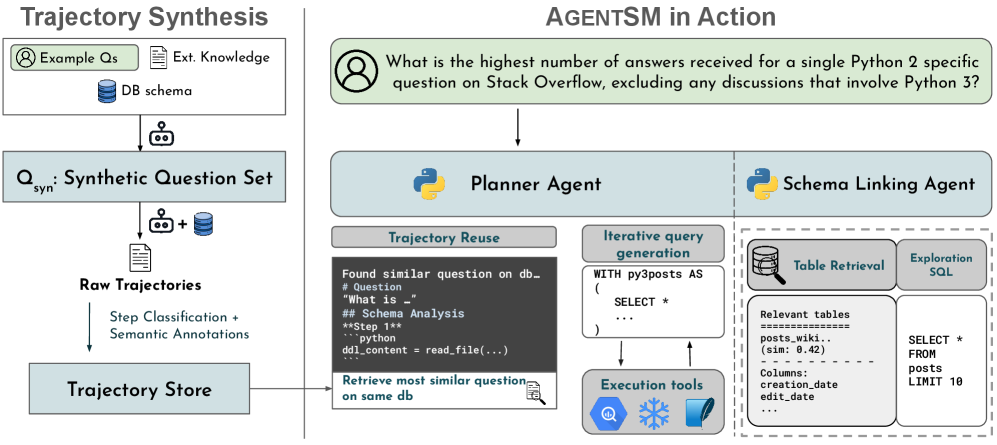
AgentSM — агентная система, использующая повторное использование логических шагов и семантическую память для более эффективного анализа данных и работы со сложными базами данных.
Несмотря на значительные успехи в области Text-to-SQL, современные системы испытывают трудности при работе со сложными корпоративными базами данных и требуют значительных вычислительных ресурсов. В данной работе представлена система AgentSM: Semantic Memory for Agentic Text-to-SQL, использующая агентный подход и семантическую память для повышения эффективности и точности преобразования естественного языка в SQL-запросы. Предложенный фреймворк позволяет повторно использовать предыдущие этапы рассуждений, что приводит к сокращению потребления токенов на 25% и длины траектории на 35% на бенчмарке Spider 2.0. Сможет ли подобный подход к организации семантической памяти значительно расширить возможности анализа данных и автоматизации работы с базами данных в реальных приложениях?
Пределы Традиционного Text-to-SQL
Несмотря на значительный прогресс в области преобразования текста в SQL благодаря большим языковым моделям (LLM), их эффективность ограничена чрезмерной зависимостью от масштабирования параметров. Вместо развития способностей к сложному логическому выводу, существующие модели часто стремятся решить проблему за счет увеличения размера сети и объема обучающих данных. Такой подход оказывается не только ресурсоемким, но и не позволяет эффективно справляться с задачами, требующими глубокого понимания структуры базы данных и сложных взаимосвязей между таблицами. В результате, при работе со сложными запросами и базами данных, такими как представленные в Spider 2.0 Benchmark, производительность подобных моделей быстро снижается, подчеркивая необходимость в разработке более эффективных и интеллектуальных методов решения данной задачи.
Существующие методы преобразования текста в SQL часто демонстрируют неспособность эффективно работать со сложными, многодиалектными базами данных, что ярко проявляется при тестировании на бенчмарке Spider 2.0. Этот бенчмарк, включающий базы данных, использующие различные SQL-диалекты и сложные схемы, выявляет ограничения существующих моделей в понимании нюансов запросов и адаптации к различным синтаксическим правилам. Неспособность адекватно обрабатывать такие сложные структуры данных подчеркивает необходимость разработки более устойчивых и адаптивных решений, способных к обобщению и эффективной работе в реальных сценариях, где разнообразие баз данных является нормой. Очевидно, что для достижения надежного преобразования текста в SQL требуется преодолеть зависимость от упрощенных предположений о структуре базы данных и разработать методы, способные учитывать сложность и разнообразие реальных данных.
Традиционные методы преобразования текста в SQL часто сталкиваются с ограничениями в повторном использовании ранее выполненных шагов логических рассуждений. Это приводит к избыточным вычислениям и, как следствие, к снижению общей производительности системы. Вместо того чтобы сохранять и применять промежуточные результаты анализа, многие подходы каждый раз начинают процесс с нуля, даже если отдельные компоненты запроса уже были успешно обработаны. Такая неэффективность особенно заметна при работе со сложными базами данных и многоэтапными запросами, где повторение одних и тех же операций может существенно замедлить выполнение. Исследования показывают, что способность к сохранению и повторному использованию логических шагов является ключевым фактором для повышения эффективности и масштабируемости систем Text-to-SQL.
Агентический Text-to-SQL: Новый Подход
Агентический подход к преобразованию текста в SQL отличается от статического промптинга использованием агентов, которые взаимодействуют непосредственно с базой данных. Вместо однократной генерации запроса, агенты последовательно анализируют схемы базы данных, проверяют синтаксис и семантику генерируемых запросов, и при необходимости корректируют их. Этот итеративный процесс позволяет агентам динамически адаптироваться к сложной структуре баз данных, что повышает точность и надежность генерируемых SQL-запросов по сравнению с традиционными методами, основанными на однократном промптинге.
Агент сопоставления схемы играет ключевую роль в процессе преобразования текста в SQL, используя такие инструменты, как Vector Search Tool, для установления связи между лексемами естественного языка и соответствующими элементами схемы базы данных. Этот инструмент осуществляет поиск наиболее релевантных таблиц и столбцов, основываясь на семантической близости между запросом пользователя и метаданными схемы. Сопоставление позволяет агенту понимать, к каким конкретным данным в базе относится вопрос, что необходимо для генерации корректного SQL-запроса и повышения точности результатов. В процессе поиска используется векторное представление как запроса, так и элементов схемы, что обеспечивает эффективное и быстрое сопоставление даже при сложных и неоднозначных запросах.
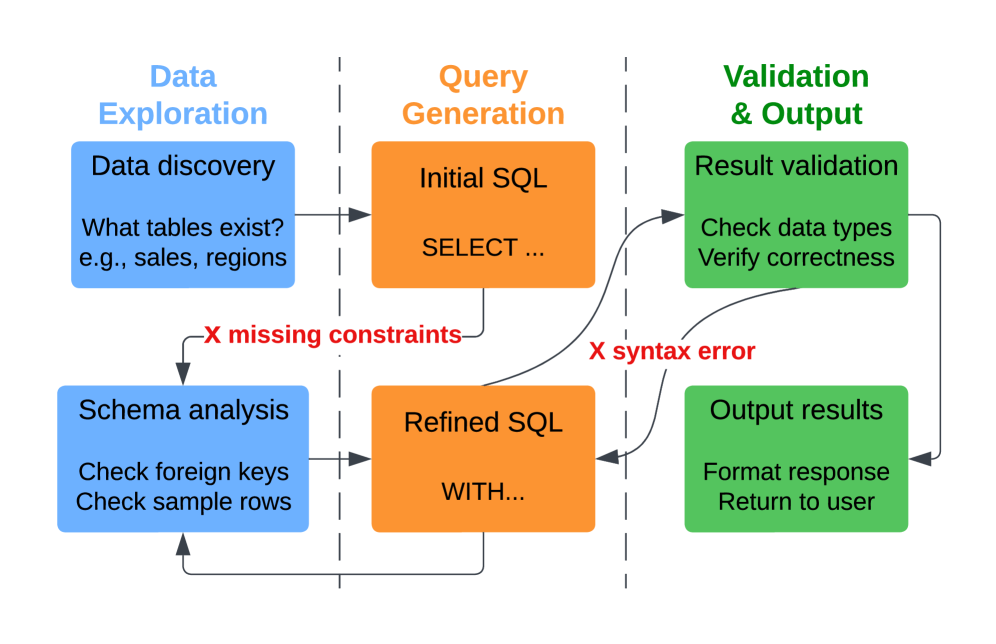
Использование итеративного подхода в системах Agentic Text-to-SQL позволяет эффективно обрабатывать сложные структуры реальных баз данных и повышать точность генерируемых запросов. Вместо однократной попытки преобразования естественного языка в SQL, агенты последовательно взаимодействуют с базой данных, проверяя схему, валидируя промежуточные результаты и корректируя запрос на основе полученной обратной связи. Этот процесс включает в себя многократное уточнение запроса и проверку его корректности, что особенно важно для баз данных с большим количеством таблиц, сложных связей и нечетко определенной семантикой. Итеративный подход позволяет агенту адаптироваться к особенностям конкретной базы данных и минимизировать количество ошибок, что приводит к более надежным и точным результатам.
AgentSM: Масштабирование Агентского Рассуждения с Использованием Памяти
AgentSM представляет собой масштабируемую и стабильную агентурную структуру, использующую структурированную семантическую память для хранения и повторного использования предыдущих шагов рассуждений — концепцию, известную как «Повторное использование траекторий» (Trajectory Reuse). Этот подход позволяет агенту сохранять последовательности действий, успешно приведшие к решению задачи, и применять их в аналогичных ситуациях. Вместо повторного выполнения всех этапов рассуждений с нуля, AgentSM извлекает и адаптирует ранее вычисленные траектории, что существенно снижает вычислительные затраты и повышает эффективность процесса принятия решений. Повторное использование траекторий основано на хранении не только конечного результата, но и промежуточных шагов, что позволяет адаптировать сохраненные решения к новым, слегка отличающимся условиям.
Классификация траекторий в AgentSM разделяет действия агента на фазы: исследование, выполнение и валидацию. Эта категоризация позволяет оптимизировать управление памятью, поскольку позволяет агенту более эффективно хранить и извлекать релевантные этапы рассуждений для каждой фазы. Фаза исследования включает в себя сбор информации и формулирование гипотез, выполнение — непосредственное выполнение действий для достижения цели, а валидация — проверку результатов и корректировку стратегии. Разделение на фазы облегчает фокусировку обучения, позволяя агенту совершенствовать свои навыки в каждой конкретной области деятельности и повышать общую эффективность рассуждений.
В AgentSM для оптимизации процесса принятия решений и снижения вычислительной нагрузки используются композитные инструменты — предварительно сконфигурированные комбинации часто используемых отдельных инструментов. Этот подход позволяет избежать повторного выполнения последовательности простых операций, заменяя их вызовом единого, комплексного инструмента. Композитные инструменты повышают эффективность за счет сокращения количества шагов, необходимых для достижения результата, и уменьшения общего объема вычислений, что особенно важно при работе со сложными задачами и большими объемами данных.
Система AgentSM демонстрирует передовую точность в 44.8% на бенчмарке Spider 2.0 Lite, что является результатом эффективного использования структурированной семантической памяти и повторного применения ранее выполненных шагов рассуждений (Trajectory Reuse). Данный показатель превосходит существующие решения в задачах преобразования естественного языка в SQL-запросы, что подтверждает эффективность предложенного подхода к масштабированию агентского рассуждения и оптимизации процесса планирования действий.
Повторное использование траекторий (Trajectory Reuse) в AgentSM позволяет сократить среднюю длину последовательности действий агента на 25%. Это достигается за счет сохранения и последующего применения ранее выполненных шагов рассуждений в новых ситуациях, что значительно снижает вычислительные затраты и повышает общую эффективность системы. Сокращение длины траектории означает уменьшение количества необходимых операций для достижения цели, что приводит к более быстрому и экономичному выполнению задач.
Повторное использование траекторий (Trajectory Reuse) в AgentSM демонстрирует значительное повышение точности — на 35% по сравнению с системами, не использующими данный подход. Этот прирост точности обусловлен эффективным использованием ранее выполненных шагов рассуждений, что позволяет избегать повторных ошибок и ускоряет процесс достижения корректного результата. Увеличение точности подтверждается результатами экспериментов и свидетельствует о высокой эффективности механизма повторного использования траекторий в контексте решения задач, требующих последовательного рассуждения и планирования действий.
Агент планирования (Planner Agent) является ключевым компонентом системы AgentSM, осуществляющим централизованное управление всем процессом рассуждений и генерацию SQL-запросов. Этот агент отвечает за оркестрацию последовательности действий, начиная с анализа запроса пользователя и заканчивая формированием корректного SQL-запроса для извлечения необходимой информации из базы данных. Он использует структурированную семантическую память для повторного использования предыдущих шагов рассуждений (Trajectory Reuse), классифицирует действия в фазы (Exploration, Execution, Validation) и взаимодействует с Композитными Инструментами для оптимизации процесса принятия решений и снижения вычислительной нагрузки. По сути, агент планирования выполняет роль центрального контроллера, обеспечивая согласованность и эффективность всей системы AgentSM.
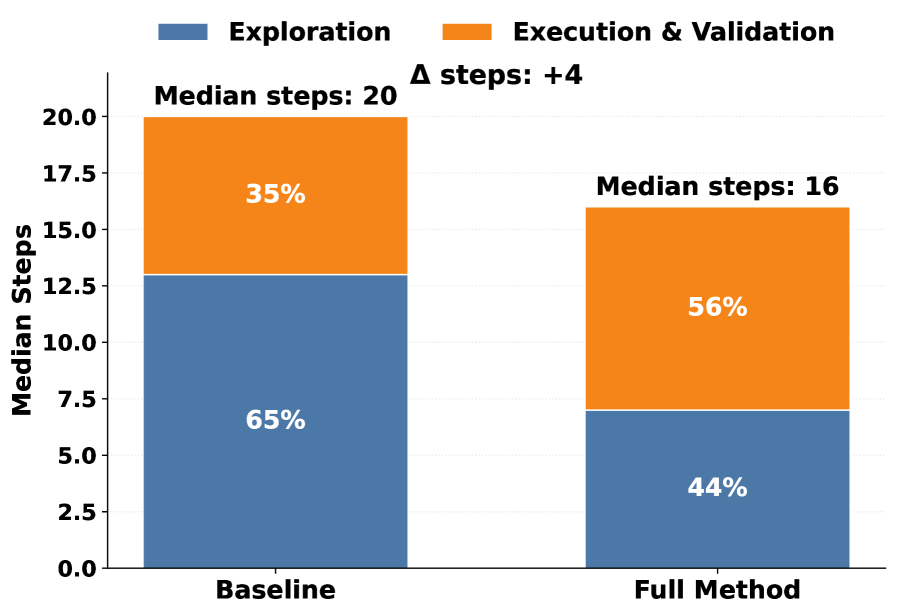
За Пределами Базового Уровня: Демонстрация Превосходства AgentSM
Исследования последовательно демонстрируют превосходство AgentSM над базовыми агентами преобразования текста в SQL, такими как SpiderAgent и CodingAgent. Этот передовой результат обусловлен внедрением подхода, усиливающего возможности агента за счет использования памяти. В отличие от традиционных моделей, AgentSM способен эффективно сохранять и извлекать релевантную информацию из предыдущих взаимодействий и шагов рассуждений. Это позволяет агенту более точно интерпретировать сложные запросы, избегать повторных ошибок и генерировать более качественные SQL-запросы, значительно превосходящие аналоги по точности и эффективности решения поставленных задач.
В основе AgentSM лежит фреймворк ReAct, позволяющий агенту последовательно чередовать этапы рассуждения и действия для повышения эффективности принятия решений. Вместо однократной генерации ответа, ReAct стимулирует итеративный процесс, где агент сначала обдумывает текущую ситуацию и определяет необходимые шаги, а затем выполняет конкретное действие, например, формирование SQL-запроса. Результаты действия анализируются, и цикл повторяется, позволяя агенту корректировать свою стратегию и постепенно приближаться к правильному решению. Такой подход особенно важен при работе со сложными запросами, требующими многоэтапного анализа и учета различных факторов, поскольку он позволяет агенту избегать ошибок и находить оптимальное решение даже в условиях неопределенности.
Для расширения возможностей AgentSM применяются передовые методы организации памяти, такие как MemGPT и Mem0. Эти техники внедряют иерархические структуры памяти, позволяющие агенту эффективно управлять контекстом и учитывать долгосрочные зависимости при решении задач. MemGPT, например, позволяет создавать и поддерживать последовательные диалоги, сохраняя историю взаимодействия, что критически важно для сложных запросов. В свою очередь, Mem0 использует принципы сжатия и извлечения информации, обеспечивая доступ к релевантным данным даже в условиях ограниченных ресурсов. Такая многоуровневая организация памяти существенно повышает способность AgentSM к обучению и адаптации, позволяя ему демонстрировать превосходные результаты в задачах, требующих сохранения и анализа информации на протяжении длительного времени.
Архитектура AgentSM представляет собой прочную основу для дальнейших исследований в области машинного обучения с небольшим количеством примеров (few-shot learning) и обобщения знаний на новые области (cross-domain generalization). Её способность эффективно управлять контекстом и долгосрочными зависимостями, благодаря использованию продвинутых иерархий памяти, позволяет агенту адаптироваться к новым задачам, используя ограниченное количество обучающих данных. Это открывает перспективы для создания более гибких и универсальных систем искусственного интеллекта, способных решать широкий спектр задач без необходимости обширного переобучения для каждой конкретной области применения. В частности, исследования в рамках AgentSM могут способствовать разработке агентов, способных к быстрому освоению новых баз данных и выполнению сложных SQL-запросов даже при ограниченном количестве примеров запросов.
Исследование представляет собой смелый вызов традиционному подходу к Text-to-SQL, предлагая AgentSM — систему, которая не просто выполняет запросы, но и учится на собственном опыте. Подобно тому, как опытный исследователь разбирает сложную систему, AgentSM анализирует предыдущие шаги рассуждений, сохраняя их в структурированной семантической памяти для последующего использования. Это позволяет системе эффективно справляться со сложными базами данных, используя накопленные знания для оптимизации процесса. Как заметил Джон фон Нейманн: «В науке не бывает абсолютной истины, только приближения». AgentSM демонстрирует это, постоянно совершенствуя свои методы и приближаясь к более точному и эффективному решению задачи Text-to-SQL.
Куда Дальше?
Представленная работа демонстрирует, что даже в, казалось бы, отлаженных системах преобразования естественного языка в SQL, остаются лакуны. AgentSM, используя концепцию семантической памяти для повторного использования траекторий рассуждений, лишь приоткрывает дверь к более эффективным методам исследования данных. Однако, истинный вопрос заключается не в скорости, а в глубине понимания. Способна ли система, опираясь на прошлый опыт, выйти за рамки заданных параметров, предвидеть неочевидные связи и, возможно, обнаружить ошибки в самой структуре базы данных?
Очевидным направлением для дальнейших исследований является расширение возможностей семантической памяти. Вместо простого хранения успешных траекторий, система должна научиться анализировать провалы, выявлять закономерности в ошибках и, следовательно, совершенствовать собственную логику. Более того, возникает вопрос об интеграции с другими «агентами», специализирующимися на различных аспектах анализа данных. Возможно ли создание «коллективного разума», способного решать задачи, непосильные для отдельных систем?
В конечном счете, AgentSM — это не просто инструмент для извлечения информации, а признание того, что даже самые сложные алгоритмы нуждаются в механизме обучения на собственных ошибках. Истинный прогресс заключается не в создании идеальной системы, а в постоянном тестировании её границ, взломе существующих ограничений и, возможно, даже в намеренном введении «багов», чтобы увидеть, как система реагирует на неожиданные вызовы. Ведь, как известно, система проявляет себя наиболее ярко, когда её пытаются сломать.
Оригинал статьи: https://arxiv.org/pdf/2601.15709.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Робот-исследователь: новый подход к автономной навигации
2026-01-24 15:27