Автор: Денис Аветисян
Исследователи предлагают инновационный метод повышения точности и надежности моделей машинного обучения за счет итеративного улучшения самих данных.
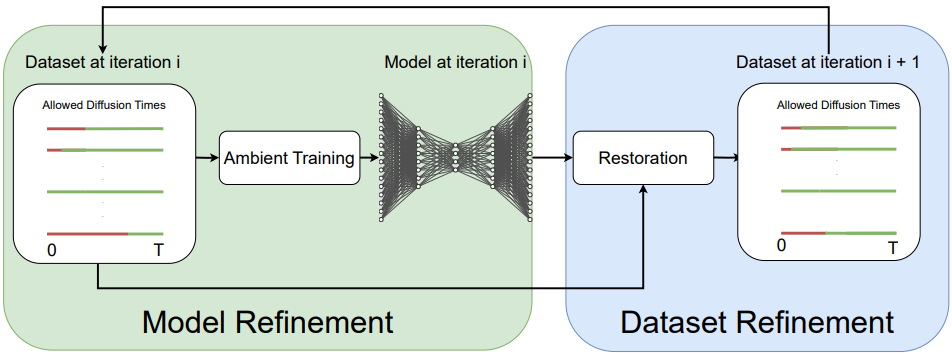
В статье представлен фреймворк Ambient Dataloops, использующий генеративные модели для восстановления и очистки наборов данных посредством самообучения и повторного обучения.
Несмотря на значительные успехи в генеративном моделировании, современные наборы данных часто содержат образцы разного качества, что негативно сказывается на производительности моделей. В работе ‘Ambient Dataloops: Generative Models for Dataset Refinement’ предложен итеративный фреймворк, использующий совместную эволюцию данных и модели для последовательного улучшения качества наборов данных и повышения эффективности диффузионных моделей. Ключевая идея заключается в применении методов обучения с использованием зашумленных данных (Ambient Diffusion) для восстановления данных в цикле итеративного уточнения. Способны ли подобные «циклы данных» радикально улучшить генеративные модели и открыть новые возможности в задачах, таких как генерация изображений и дизайн белков?
Проблема достоверности: узкое место в предсказании белковых структур
Прогнозирование структур белков имеет решающее значение для понимания их функций и разработки новых лекарственных препаратов, однако точность этих предсказаний часто остается под вопросом. Несмотря на значительные успехи в области вычислительной биологии, моделирование трехмерной структуры белка — сложная задача, подверженная ошибкам из-за неполных данных или упрощенных алгоритмов. Неопределенность в предсказанных структурах может привести к неверной интерпретации биологических процессов и, как следствие, к неудачным экспериментам или неэффективным терапевтическим стратегиям. Поэтому, оценка достоверности предсказанных структур является критически важным этапом в любом исследовании, использующем данные о структуре белков, требующим разработки новых, более надежных методов валидации.
Несмотря на широкое использование метрик, таких как pLDDT, для оценки достоверности предсказанных структур белков, современные методы сталкиваются с ограничениями в полной оценке их валидности. pLDDT, хоть и указывает на локальную уверенность модели в конкретных аминокислотных остатках, не учитывает глобальную согласованность структуры, физико-химические ограничения или соответствие известным функциональным особенностям белка. Высокие значения pLDDT могут маскировать локальные ошибки или нереалистичные конформации, что приводит к неточным результатам в последующих исследованиях, например, при моделировании взаимодействия белок-белок или разработке лекарств. Таким образом, необходимы более комплексные подходы к оценке качества структур, включающие анализ различных критериев и интеграцию дополнительных источников информации для обеспечения надежности и точности предсказаний.
Недостаточное качество данных о структуре белков существенно ограничивает возможности их применения в различных областях, от разработки новых лекарственных препаратов до понимания фундаментальных биологических процессов. Ошибки или неточности в моделях белковых структур могут привести к неверным выводам о функции белка, его взаимодействии с другими молекулами и, как следствие, к неэффективности или даже вреду при использовании в практических приложениях. В связи с этим, разработка и внедрение надежных методов оценки качества данных, позволяющих выявлять и устранять погрешности, является критически важной задачей для обеспечения достоверности и надежности исследований в области протеомики и структурной биологии. Без адекватной оценки качества, даже самые передовые вычислительные методы предсказания структуры белка теряют свою ценность, поскольку полученные результаты могут быть недостоверными и не применимыми на практике.
Генерирование новых белков: искусство дизайна и последовательности
Методы, такие как ProteinMPNN и ESMFold, позволяют создавать новые белки, исходя из заданных структур их полипептидной цепи (backbone). Эти алгоритмы используют глубокое обучение для предсказания аминокислотной последовательности, наиболее вероятно соответствующей стабильной трехмерной структуре белка. В отличие от традиционных методов, которые начинаются с аминокислотной последовательности и пытаются предсказать структуру, ProteinMPNN и ESMFold работают в обратном направлении, что позволяет целенаправленно создавать белки с желаемыми структурными характеристиками. В процессе генерации последовательности учитываются физические ограничения и энергетическая стабильность белка, что повышает вероятность получения функционально активных белков.
Проблема “реализуемости” (designability) в контексте генерации новых белков заключается в том, что не каждая аминокислотная последовательность, теоретически соответствующая заданной спиральной структуре, физически стабильна и способна к сворачиванию в эту структуру. Это связано с энергетическими ограничениями и пространственными препятствиями, возникающими при взаимодействии аминокислотных остатков. Низкая реализуемость приводит к образованию нестабильных белков, склонных к агрегации или неправильному сворачиванию, что делает их непригодными для практического применения. Оценка реализуемости требует учета множества факторов, включая гидрофобные взаимодействия, водородные связи и ван-дер-ваальсовы силы, а также предотвращение стерических конфликтов между аминокислотными остатками.
Оценка качества данных (DataQualityAssessment) является критически важным этапом при генерации новых белков. Этот процесс включает в себя фильтрацию и уточнение предложенных аминокислотных последовательностей для обеспечения их физической реализуемости и структурной целостности. Оценка включает проверку на наличие нефизических взаимодействий, таких как столкновения атомов или неблагоприятные энергетические состояния, а также анализ стабильности предсказанной структуры. Использование специализированных алгоритмов и скоринговых функций позволяет выявлять и отбраковывать последовательности, которые, вероятно, не смогут правильно свернуться или будут нестабильны in vivo. Высокое качество оценки данных напрямую влияет на успешность последующих экспериментальных исследований и практического применения сгенерированных белков.

Уточнение данных посредством диффузии: итеративный подход к совершенству
Фреймворк AmbientDataloops реализует совместную эволюцию набора данных и модели, осуществляя итеративное улучшение обоих компонентов. Процесс заключается в последовательном обучении модели на текущей версии набора данных, после чего результаты обучения используются для усовершенствования самого набора данных. Данная итерация повторяется многократно, позволяя модели и данным взаимно влиять друг на друга и достигать более высокого качества. Этот подход отличается от традиционных методов, где набор данных фиксирован, а модель обучается на нем единожды, что позволяет AmbientDataloops адаптироваться к данным и улучшать их характеристики в процессе обучения.
Восстановление набора данных (DatasetRestoration) осуществляется посредством применения техник диффузионных моделей (DiffusionModel). Данный процесс предполагает итеративное добавление шума к образцам данных и последующее его удаление с помощью обученной модели. Это позволяет не только устранять артефакты и повышать качество существующих данных, но и генерировать новые, более реалистичные образцы, эффективно улучшая общее качество и разнообразие набора данных. Алгоритм использует обратное диффузионное моделирование для постепенного восстановления исходных данных из зашумленного состояния.
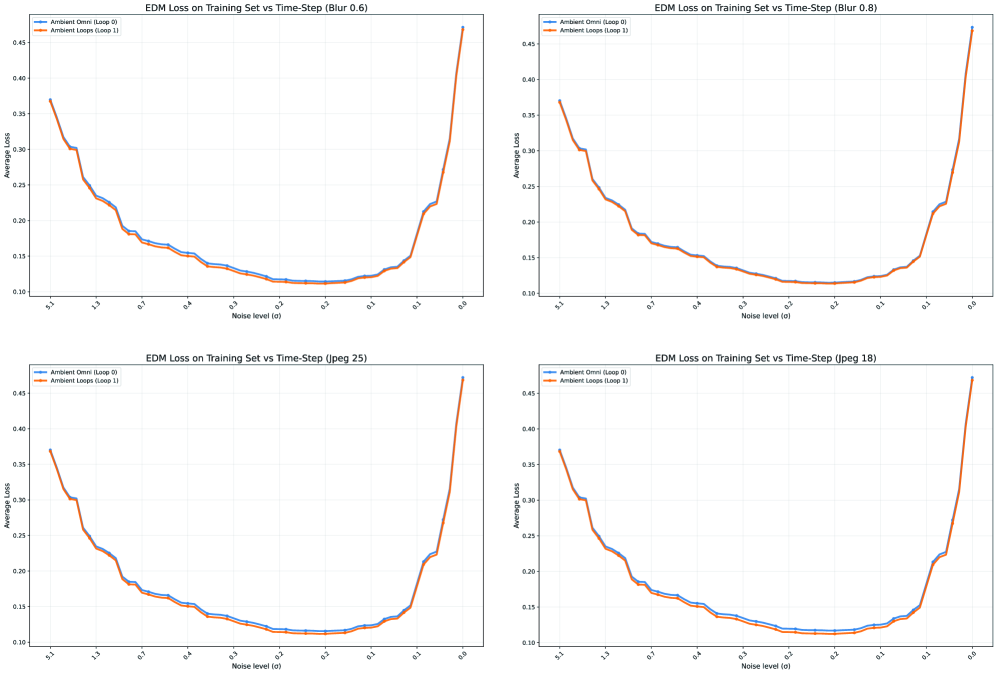
В рамках платформы AmbientOmni, аннотация уровня шума (NoiseLevelAnnotation) является ключевым элементом управления процессом диффузии, обеспечивающим эффективное улучшение качества данных. Эта аннотация предоставляет информацию, необходимую для точной настройки диффузионной модели, позволяя целенаправленно удалять артефакты и повышать реалистичность сгенерированных или восстановленных данных. Экспериментальные результаты демонстрируют, что применение NoiseLevelAnnotation позволяет добиться снижения метрики FID (Fréchet Inception Distance) до 17% по сравнению с базовыми методами, что свидетельствует о значительном улучшении качества данных и повышении эффективности модели.
Обеспечение разнообразия и устойчивости: за пределами индивидуальных дизайнов
Оценка разнообразия сгенерированных белков является критически важным аспектом при создании надежных и функциональных наборов данных. Недостаточное разнообразие может привести к предвзятости и снижению эффективности последующих анализов и экспериментов. В частности, при проектировании белков, ограниченное пространство вариантов может привести к созданию структур, которые либо нефункциональны, либо не способны адаптироваться к изменяющимся условиям. Поэтому, для обеспечения надежности и универсальности спроектированных белков, необходимо тщательно оценивать и максимизировать разнообразие генерируемых структур, используя соответствующие метрики и алгоритмы, что позволяет создавать библиотеки с улучшенными характеристиками и потенциалом для широкого спектра применений.
Для оценки разнообразия создаваемых белков и обеспечения надежности наборов данных, активно применяются методы кластеризации структур, такие как Foldseek. Эта программа позволяет группировать схожие по структуре белки, выявляя избыточность в наборах данных. Использование Foldseek предоставляет возможность целенаправленно отбирать наиболее уникальные и информативные структуры, избегая повторений и повышая эффективность дальнейших исследований. Такой подход к отбору данных критически важен для создания высококачественных библиотек белков, которые демонстрируют улучшенные характеристики, включая повышенные показатели Designability и Diversity в экспериментах по проектированию белков.
Создание высококачественных библиотек протеинов стало возможным благодаря сочетанию тщательно отобранных данных и надежных метрик оценки, таких как CLIP-IQA. Исследования показали, что подобный подход не только повышает значения CLIP-IQA, отражая улучшенное качество спроектированных белков, но и позволяет достичь условного FID ниже 5 для восстановленных наборов данных, что свидетельствует о высокой степени реалистичности и правдоподобия. Более того, эксперименты подтвердили значительное улучшение как способности белков к функциональности (Designability), так и разнообразия в протеиновых библиотеках, что открывает новые перспективы для биоинженерии и разработки лекарственных препаратов.
Исследование, представленное в данной работе, демонстрирует элегантную простоту и глубину итеративного подхода к улучшению данных. Концепция ‘Ambient Dataloops’, по сути, является воплощением идеи непрерывного совершенствования через последовательное шумоподавление и переобучение. Как однажды заметил Роберт Тарджан: «Программирование — это больше искусство, чем наука». Этот принцип особенно актуален здесь, поскольку создание и усовершенствование датасетов требует не только технических навыков, но и интуиции, позволяющей увидеть скрытые закономерности и недостатки. Подобно тому, как художник шлифует свой шедевр, так и данная методика позволяет ‘отшлифовать’ данные, добиваясь повышения качества и эффективности модели. Каждый этап шумоподавления — это признание изначальной ‘несовершенности’ исходных данных, а переобучение — попытка приблизиться к идеалу.
Что дальше?
Предложенный подход, использующий итеративное улучшение наборов данных посредством совместной эволюции модели и данных, ставит интересный вопрос: а что, если шум в данных — не ошибка, а сигнал, несущий информацию о границах допустимого? Если рассматривать процесс «очистки» данных как навязывание предвзятости, то возникает закономерный вопрос о том, не упускается ли ценная информация, скрытая в кажущемся хаосе. Попытки создания «идеальных» наборов данных могут привести к сужению возможностей модели, лишая её способности к обобщению и адаптации к реальным, шумным условиям.
Перспективным направлением представляется исследование не столько удаления шума, сколько его преобразования — выделения полезных признаков из, казалось бы, бесполезной информации. Следует обратить внимание на возможность использования принципов самообучения не только для улучшения качества данных, но и для выявления скрытых закономерностей, которые не очевидны при традиционном анализе. В конечном счёте, задача состоит не в том, чтобы создать «чистые» данные, а в том, чтобы научить модель эффективно работать с реальностью, которая по своей природе является нелинейной и зашумлённой.
Игнорирование вопроса о предвзятости, заложенной в процессе «восстановления» данных, кажется опасным упрощением. Необходимо разработать метрики, позволяющие оценивать не только качество данных, но и степень их искажения в процессе обработки. Возможно, будущие исследования сосредоточатся на создании систем, способных обнаруживать и компенсировать предвзятость, обеспечивая более справедливое и надежное машинное обучение.
Оригинал статьи: https://arxiv.org/pdf/2601.15417.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-01-24 15:29