Автор: Денис Аветисян
В новой работе представлена MirrorBench — платформа для строгого анализа реалистичности поведения искусственных агентов в диалоге.
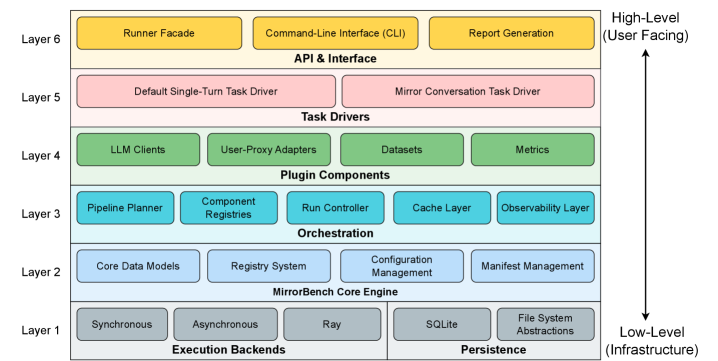
Предложенный фреймворк обеспечивает воспроизводимую оценку человекоподобия пользовательских прокси-агентов с использованием LLM в качестве эксперта, стандартизируя бенчмаркинг и сравнение различных моделей.
Несмотря на растущее использование больших языковых моделей в качестве симуляторов пользователей, оценка реалистичности их поведения остаётся сложной задачей. В данной работе представлена система MirrorBench: An Extensible Framework to Evaluate User-Proxy Agents for Human-Likeness, — воспроизводимый и расширяемый фреймворк для всесторонней оценки качества генерируемых пользовательских реплик, отвязанной от успеха выполнения задач. Система позволяет сравнивать различные модели-прокси пользователей, используя разнообразные метрики, включая лексическое разнообразие и оценку на основе LLM-судей, выявляя систематические расхождения с реальным человеческим поведением. Возможно ли, используя MirrorBench, разработать пользовательские прокси, неотличимые от настоящих людей в диалоговых системах?
Разоблачение Искусственного Правдоподобия: Вызовы Оценки Разговорного ИИ
Оценка разговорного искусственного интеллекта не ограничивается лишь успешным выполнением поставленных задач; реалистичность и правдоподобие в общении играют ключевую роль, однако их количественная оценка представляет собой значительную сложность. В то время как системы могут эффективно предоставлять информацию или выполнять команды, подлинное взаимодействие требует способности учитывать контекст, демонстрировать эмпатию и использовать естественный язык со всеми его нюансами. Попытки оценить эти качества сталкиваются с проблемой субъективности восприятия, поскольку то, что кажется реалистичным одному человеку, может восприниматься как искусственное другим. Более того, существующие метрики часто не учитывают тонкости невербальной коммуникации и эмоциональной окраски, которые являются неотъемлемой частью человеческого диалога. Таким образом, создание объективных и надежных методов оценки реалистичности разговорного ИИ остается актуальной задачей, требующей междисциплинарного подхода, объединяющего лингвистику, психологию и компьютерные науки.
Традиционные методы оценки разговорного искусственного интеллекта зачастую не способны уловить тонкости человеческого общения, что приводит к предвзятым и ненадежным результатам. Существующие метрики, ориентированные преимущественно на успешное выполнение поставленной задачи, игнорируют такие важные аспекты, как естественность диалога, уместность ответов в контексте беседы, и способность системы поддерживать эмоциональную окраску разговора. В результате, чат-бот, способный формально решить проблему, может звучать неестественно и отталкивающе, что негативно сказывается на пользовательском опыте. Недостаточность существующих подходов требует разработки новых, более комплексных методов оценки, учитывающих не только функциональность, но и качество и реалистичность взаимодействия с пользователем.
Ключи к Человекоподобию: Измерение Реалистичности в Диалоге
В оценке реалистичности искусственного интеллекта ключевым понятием являются “Метрики человекоподобия” — количественно измеримые показатели, определяющие степень соответствия поведения агента человеческому. Эти метрики позволяют объективно оценивать, насколько естественно и правдоподобно ИИ взаимодействует с пользователем, выходя за рамки субъективных впечатлений. Оценка проводится по различным параметрам, включая стилистику речи, последовательность ответов и способность поддерживать контекст беседы. Использование количественных метрик необходимо для сравнительного анализа различных моделей ИИ и отслеживания прогресса в области создания реалистичных диалоговых систем.
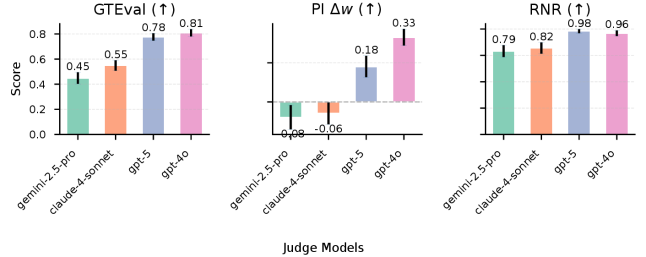
Оценка реалистичности искусственного интеллекта часто проводится с использованием суждений экспертов, выражаемых в виде метрик, таких как ‘GTEval’ и ‘Pairwise Indistinguishability’. В рамках этих оценок, модель Gemini-2.5-Pro продемонстрировала результат 0.85, в то время как Claude-4-Sonnet получила оценку 0.72. Данные метрики отражают степень, в которой ответы модели воспринимаются экспертами как человеческие, где более высокие значения указывают на большую реалистичность и правдоподобность диалога.
Помимо субъективных оценок, объективные метрики лингвистического стиля, такие как ‘Лексическое разнообразие’ (Lexical Diversity), предоставляют ценные сведения о реалистичности ведения диалога. Лексическое разнообразие измеряет богатство словарного запаса, используемого в тексте, и рассчитывается как отношение количества уникальных слов к общему количеству слов. Более высокое значение указывает на более широкий и разнообразный словарный запас, что обычно коррелирует с более естественной и человекоподобной речью. Анализ лексического разнообразия позволяет количественно оценить способность языковой модели генерировать разнообразные и не повторяющиеся фразы, что является важным аспектом оценки реалистичности диалога, не зависящим от индивидуального восприятия оценщиков.
MirrorBench: Система для Бескомпромиссной Оценки ИИ
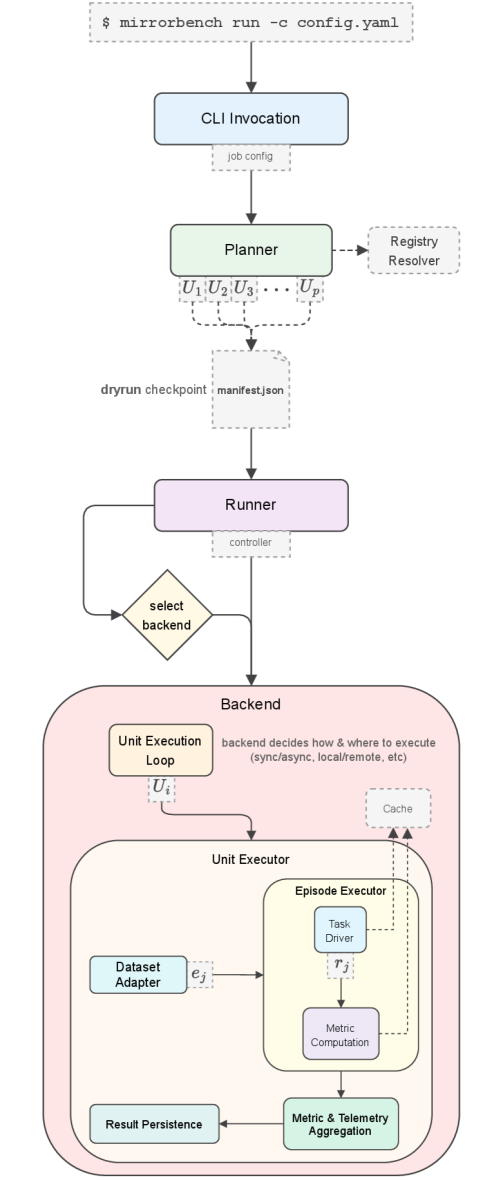
Фреймворк MirrorBench представляет собой расширяемую систему для оценки ‘User-Proxy Agents’ посредством комплексного набора метрик, имитирующих человекоподобность. Данные метрики позволяют количественно оценить, насколько поведение агента соответствует ожиданиям, основанным на человеческих взаимодействиях. Расширяемость системы позволяет добавлять новые метрики и адаптировать существующие для различных сценариев и типов агентов, обеспечивая гибкость в процессе оценки. В состав фреймворка входит инструментарий для сбора данных, автоматизированного анализа и визуализации результатов, что упрощает процесс сравнения различных ‘User-Proxy Agents’ и выявления областей для улучшения.
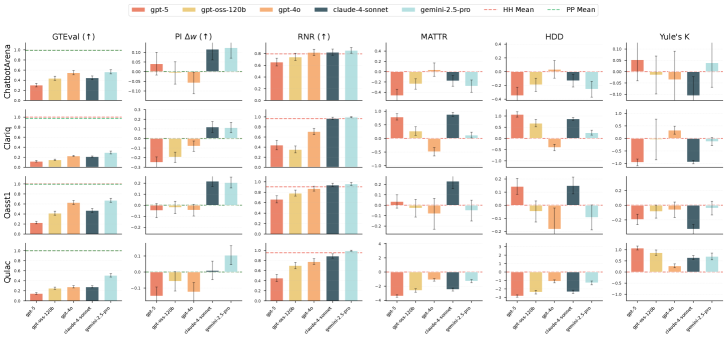
Для проведения оценки и обеспечения разнообразия сценариев диалогов, фреймворк MirrorBench использует несколько общедоступных наборов данных. В их числе ChatbotArena, предоставляющий данные из соревнований между чат-ботами; OASST1, содержащий многоязычные диалоги, созданные сообществом; QULAC, ориентированный на вопросы, требующие рассуждений и логического вывода; и ClariQ, представляющий собой набор данных, разработанный для оценки качества ответов в контексте диалога. Использование этих разнообразных наборов данных позволяет MirrorBench проводить всестороннюю оценку пользовательских прокси-агентов в различных ситуациях и условиях общения.
В основе MirrorBench лежит система калибровочных контролей, предназначенная для минимизации смещений и обеспечения надежности сравнительного анализа. Данная система включает в себя оценку взаимодействий как между агентами-прокси (Proxy-Proxy), так и между людьми (Human-Human). Оценка взаимодействий между людьми служит базовым уровнем для определения реалистичности и согласованности ответов, а сравнение Proxy-Proxy позволяет выявить потенциальные систематические ошибки и несоответствия в работе различных агентов. Такой подход позволяет более точно оценить, насколько хорошо агенты-прокси имитируют человеческое поведение в различных сценариях и избежать ложных выводов, вызванных предвзятостью или несогласованностью оценок.
Фреймворк MirrorBench обеспечивает высокую производительность благодаря асинхронной архитектуре и максимальной степени параллельности обработки. Это позволяет достичь пропускной способности в 8 эпизодов в минуту, что значительно ускоряет процесс оценки. При этом стоимость одного эпизода оценки составляет всего $0.01, что делает MirrorBench экономически эффективным решением для масштабного бенчмаркинга моделей, особенно при работе с большими наборами данных и необходимостью проведения большого количества оценок.

Путь к Истинным Искусственным Компаньонам: Взгляд в Будущее
Исследователи разработали строгую систему оценки, названную ‘MirrorBench’, для анализа так называемых ‘User-Proxy Agents’ — искусственных агентов, имитирующих поведение пользователя в диалоге. Эта методика позволяет выявлять слабые места в способности ИИ вести естественную беседу, фокусируясь не только на выполнении задач, но и на соблюдении лингвистических норм и паттернов, характерных для человеческой речи. Благодаря ‘MirrorBench’ становится возможным количественно оценить, насколько правдоподобно и убедительно ИИ воспроизводит манеру общения, что открывает путь к созданию более человечных и эффективных разговорных систем. Результаты подобных оценок крайне важны для дальнейшего совершенствования алгоритмов и моделей, используемых в чат-ботах, виртуальных ассистентах и других приложениях, требующих взаимодействия с пользователем на естественном языке.
Разработанная платформа способствует созданию агентов, способных не просто выполнять поставленные задачи, но и вести диалог, приближенный к человеческому. Она стимулирует исследования в области моделирования естественных языковых паттернов, таких как умение адаптироваться к стилю общения собеседника, использовать невербальные сигналы в текстовом формате и демонстрировать эмпатию. В результате, создаваемые агенты способны поддерживать более осмысленные и продуктивные беседы, что повышает доверие пользователей и открывает новые возможности для взаимодействия человека и искусственного интеллекта. Такой подход позволяет перейти от функциональных помощников к настоящим компаньонам, способным понимать нюансы человеческого общения и строить долгосрочные отношения с пользователями.
Исследования показали, что модели Gemini-2.5-Pro и Claude-4-Sonnet представляют собой оптимальное сочетание производительности и экономической эффективности, открывая новые перспективы для создания более привлекательных и заслуживающих доверия искусственных компаньонов и помощников. Эти модели демонстрируют способность поддерживать содержательные диалоги при относительно низких затратах на вычислительные ресурсы, что делает их особенно перспективными для широкого внедрения в различные приложения, от персональных ассистентов до систем поддержки клиентов. Данный баланс между качеством и стоимостью позволяет создавать более доступные и удобные в использовании ИИ-системы, способные не только выполнять поставленные задачи, но и поддерживать естественное и приятное общение, что является ключевым фактором для повышения доверия и вовлеченности пользователей.
Исследование представляет собой попытку систематизировать оценку «человекоподобия» агентов, имитирующих поведение пользователей в диалоге. Авторы предлагают MirrorBench — не просто фреймворк, а инструмент для деконструкции существующих подходов и выявления их слабых мест. Это напоминает о важности понимания внутренней структуры любой системы, чтобы её эффективно улучшить. Как заметил Марвин Минский: «Лучший способ понять — это создать». MirrorBench, по сути, и есть попытка создания эталона оценки, позволяющего разобрать «человечность» агентов на составные части и понять, как её можно оптимизировать, используя LLM в качестве судей.
Куда же дальше?
Представленная работа, создавая платформу для оценки «человечности» агентов, неизбежно обнажает глубину вопроса: а что, если «человечность» — это всего лишь набор предсказуемых паттернов, ловко воспроизводимых алгоритмом? MirrorBench, как лакмусовая бумажка, демонстрирует, насколько легко можно подделать убедительность, но не раскрывает истинную природу сознания, которое эта убедительность имитирует. Настоящий вызов — не в создании более правдоподобных имитаций, а в понимании, что вообще отличает живое от симулированного.
Очевидным направлением развития представляется расширение набора метрик. Оценивать «человечность» по ответам на вопросы — всё равно что судить о художнике по копиям чужих картин. Необходимы более тонкие инструменты, учитывающие контекст, невербальные сигналы, способность к импровизации и, что самое важное, — неспособность к абсолютно рациональному поведению. Иначе, рано или поздно, машина превзойдёт человека в искусстве убеждения, оставив за бортом всё, что мы считаем подлинным.
В конечном счёте, MirrorBench — это лишь первый шаг на пути к созданию «Зеркала», отражающего не столько «человечность» агента, сколько нашу собственную, всё более размытую и искусственную. И, возможно, именно в этом искажении и кроется истина. Ведь всякая модель — это упрощение, а всякое упрощение — ложь. Но иногда эта ложь позволяет увидеть суть.
Оригинал статьи: https://arxiv.org/pdf/2601.08118.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-01-24 16:42