Автор: Денис Аветисян
Новый подход позволяет системам распознавания речи непрерывно обучаться новым командам и адаптироваться к меняющимся условиям, не теряя при этом эффективности и скорости работы.
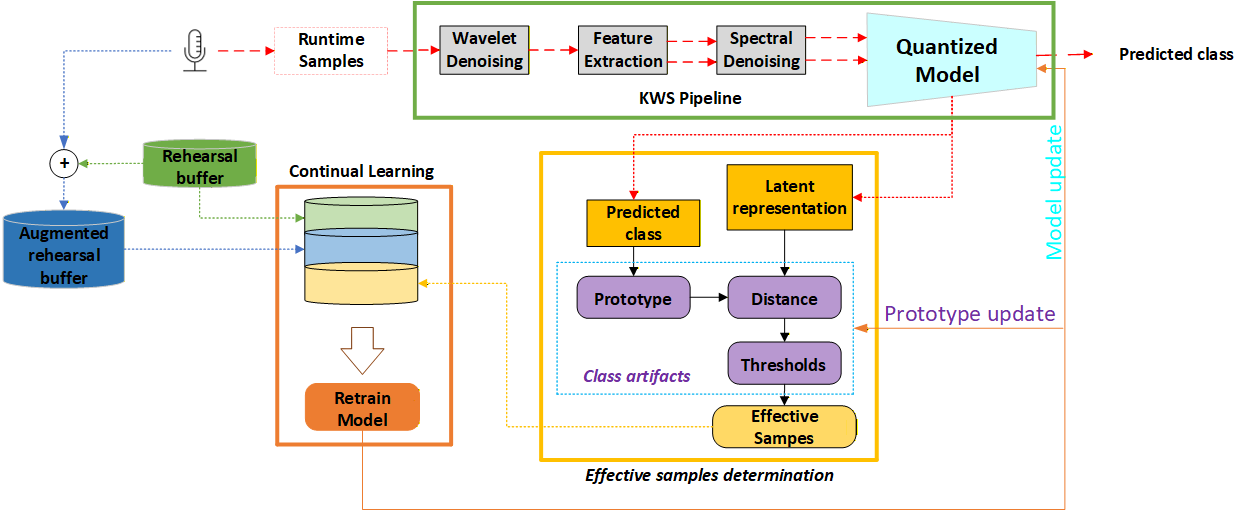
Представлена система непрерывного обучения для распознавания ключевых слов в встраиваемых системах с использованием компактной модели, памяти для повторения и обучения на основе прототипов.
Несмотря на значительные успехи в области распознавания ключевых слов, системы с ограниченными вычислительными ресурсами остаются уязвимыми к снижению точности при изменении условий записи и уровне шума. В данной работе, ‘Domain-Incremental Continual Learning for Robust and Efficient Keyword Spotting in Resource Constrained Systems’, предложен комплексный подход к непрерывному обучению, позволяющий адаптироваться к новым условиям, сохраняя при этом эффективность. В основе решения лежит интеграция двухпотоковой сверточной нейронной сети, многоступенчатой системы шумоподавления и прототипного обучения с использованием памяти репетиций для инкрементной переподготовки модели. Каким образом предложенный фреймворк может быть масштабирован для работы с еще более сложными акустическими условиями и расширенным набором ключевых слов в реальных приложениях?
Пророчество Системы: Вызовы Непрерывного Обучения на Периферийных Устройствах
Традиционные модели машинного обучения часто сталкиваются с проблемой «катастрофического забывания» при непрерывном обучении. Суть явления заключается в том, что при освоении новой информации, модель склонна утрачивать знания, полученные ранее. Это происходит из-за того, что веса нейронной сети, настроенные для решения определенной задачи, изменяются при обучении на новом наборе данных, приводя к ухудшению производительности на предыдущих задачах. В отличие от человеческой способности адаптироваться и накапливать знания, стандартные алгоритмы машинного обучения не обладают механизмом сохранения старых навыков при приобретении новых, что существенно ограничивает их применение в динамичных средах, требующих постоянной адаптации и обучения на протяжении всего жизненного цикла.
Развертывание моделей машинного обучения на микроконтроллерах с ограниченными ресурсами, таких как TM4C123GXL и STM32F746, значительно усугубляет проблему катастрофического забывания. Ограниченный объем памяти и вычислительной мощности этих устройств не позволяют эффективно хранить и обновлять параметры моделей при обучении новым данным. Это приводит к тому, что при освоении новой информации, ранее полученные знания стираются, что делает невозможным создание действительно адаптирующихся и непрерывно обучающихся систем для периферийных вычислений. В результате, требуется разработка специальных алгоритмов и архитектур моделей, способных к эффективному обучению и сохранению знаний в условиях жестких аппаратных ограничений.
Необходимость в эффективных и адаптируемых моделях машинного обучения становится особенно актуальной в приложениях, функционирующих в динамично меняющихся условиях. В таких сценариях, как, например, системы автономной робототехники или мониторинг окружающей среды, постоянная способность к обучению и адаптации к новым данным критически важна для поддержания высокой производительности и надежности. Модели, способные к непрерывному обучению без потери ранее приобретенных знаний, позволяют устройствам эффективно функционировать в течение длительного времени, избегая необходимости в дорогостоящей и сложной переподготовке. Разработка таких моделей является ключевой задачей для обеспечения долгосрочной работоспособности и расширения возможностей применения интеллектуальных систем в реальном мире, особенно в условиях ограниченных ресурсов и постоянного изменения данных.
Квантованные Нейронные Сети: Открытие Эры Периферийного Интеллекта
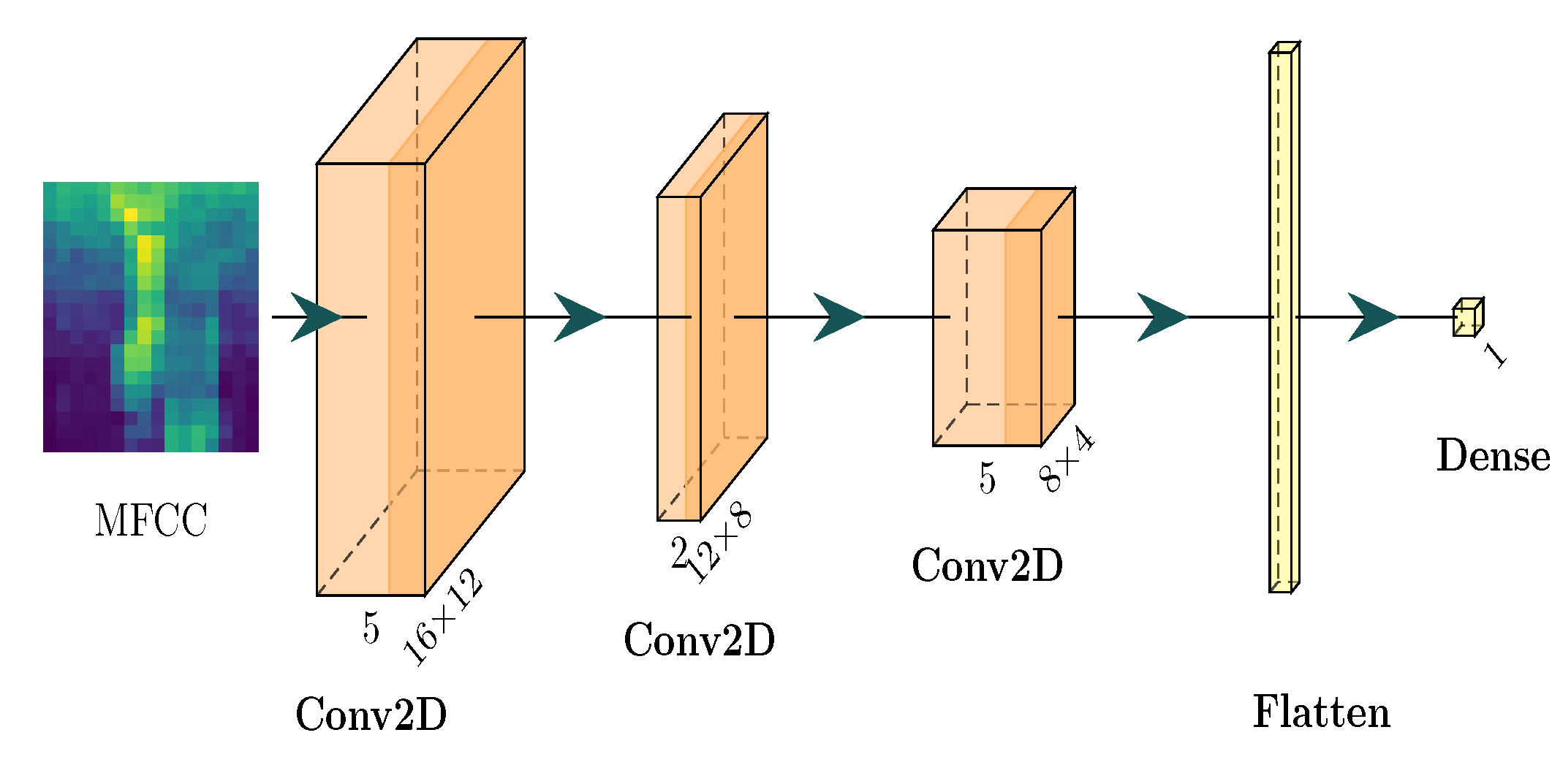
Квантованные нейронные сети (Quantized Neural Networks) снижают размер модели и вычислительные затраты за счет представления весов и активаций с использованием более низкой точности. Традиционно, веса и активации хранятся в формате с плавающей точкой (например, 32 бита). Квантование позволяет уменьшить количество бит, используемых для представления этих значений — до 8 бит, 4 бита или даже меньше. Это приводит к значительному уменьшению объема памяти, необходимого для хранения модели, и снижению требований к вычислительной мощности для выполнения операций, таких как умножение и сложение. Например, переход от 32-битной плавающей точки к 8-битному целочисленному представлению уменьшает размер модели в 4 раза и может значительно ускорить вычисления на специализированном оборудовании.
Обучение с учетом квантования (Quantization Aware Training) представляет собой метод, направленный на минимизацию потери точности при переходе к сниженной разрядности представления весов и активаций нейронной сети. В процессе обучения с учетом квантования, симуляция эффектов квантования — округления и усечения значений — интегрируется в процесс обратного распространения ошибки. Это позволяет сети адаптироваться к ограничениям, вносимым сниженной точностью, и компенсировать возникающие погрешности, тем самым сохраняя или даже улучшая общую производительность модели после квантования. В отличие от пост-тренировочного квантования, при котором квантование применяется к уже обученной модели, обучение с учетом квантования позволяет сети «учиться» работать с ограниченной точностью на этапе тренировки.
Квантизация нейронных сетей позволяет развертывать сложные модели, такие как CNN, BC-ResNet и MobileNet, на периферийных устройствах, в частности, на платформе GAP9. Достигается это за счет значительного сокращения размера модели и вычислительной нагрузки. В результате, модель может содержать всего 1595 параметров и требовать 0.89 миллионов операций с плавающей точкой (M FLOPS) для выполнения, что делает ее пригодной для устройств с ограниченными ресурсами.
Глубинные разделяемые свёртки (Depthwise Separable Convolutions) повышают эффективность CNN-архитектур за счет разделения стандартной свёртки на два этапа: глубинный свёртки (Depthwise Convolution) и точечной свёртки (Pointwise Convolution). Глубинная свёртка применяет фильтр к каждому входному каналу независимо, снижая вычислительную сложность. Затем, точечная свёртка, представляющая собой 1×1 свёртку, комбинирует результаты глубинной свёртки для создания выходных каналов. Такое разделение значительно уменьшает количество параметров и операций с плавающей точкой (FLOPS) по сравнению со стандартными свёртками, что особенно важно для развертывания моделей на устройствах с ограниченными ресурсами.
Противодействие Забыванию: Стратегии Непрерывного Обучения
Непрерывное обучение (Continual Learning) представляет собой подход в машинном обучении, направленный на создание моделей, способных последовательно изучать новые данные, не теряя при этом знаний, полученных ранее. В отличие от традиционных моделей, которые обычно переобучаются на каждом новом наборе данных, что приводит к “катастрофическому забыванию” предыдущей информации, непрерывное обучение стремится к сохранению и интеграции старых знаний в процессе обучения новым. Это достигается за счет применения различных стратегий, таких как сохранение репрезентаций прошлых данных, регуляризация для предотвращения изменений в важных параметрах модели, или динамическое выделение ресурсов для новых задач, не затронув уже усвоенные знания. Эффективность непрерывного обучения оценивается по способности модели поддерживать высокую производительность как на новых, так и на старых задачах.
Методы, такие как Dark Experience Replay (DER) и Gradient Episodic Memory (GEM), направлены на смягчение катастрофического забывания в задачах непрерывного обучения за счет сохранения и повторного использования прошлых опытов. DER хранит небольшую выборку прошлых данных и воспроизводит их в процессе обучения новым задачам, что позволяет модели удерживать ранее полученные знания. GEM, в свою очередь, сохраняет градиенты потерь для предыдущих задач и использует их для регуляризации обучения на новых данных, предотвращая значительное изменение весов, критичных для старых задач. Оба подхода используют сохраненные данные для формирования дополнительного сигнала, который стабилизирует процесс обучения и способствует удержанию информации, полученной на предыдущих этапах.
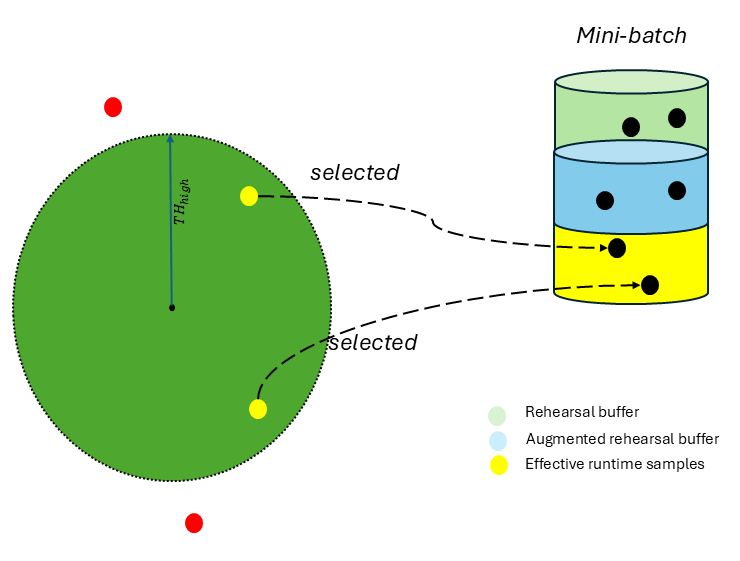
Метод эффективных выборок (Effective Samples) и псевдо-маркировки (Pseudo-Labeling) используется для непрерывной адаптации моделей путем идентификации и использования наиболее надежных точек данных. В основе лежит вычисление векторных представлений классов (Class Prototype embeddings), которые служат центроидами для каждого класса. Выборки, наиболее близкие к этим прототипам, считаются наиболее надежными и используются для обновления модели. Псевдо-маркировка назначает метки этим выбранным образцам, что позволяет модели обучаться на расширенном наборе данных без необходимости ручной аннотации, эффективно предотвращая забывание ранее полученных знаний и улучшая обобщающую способность.
Буфер повторения (Rehearsal Buffer) представляет собой механизм, используемый в задачах непрерывного обучения для смягчения эффекта катастрофического забывания. Он заключается в хранении подмножества данных, полученных на предыдущих этапах обучения, и их последующем использовании в процессе обучения на новых данных. Данные в буфере повторения обычно отбираются случайным образом или с использованием стратегий, направленных на сохранение наиболее информативных или репрезентативных примеров. Повторное использование этих данных в сочетании с новыми данными позволяет модели сохранять знания, приобретенные на предыдущих этапах, и предотвращает их потерю при обучении новым задачам.
Усиление Надежности через Обработку Сигналов
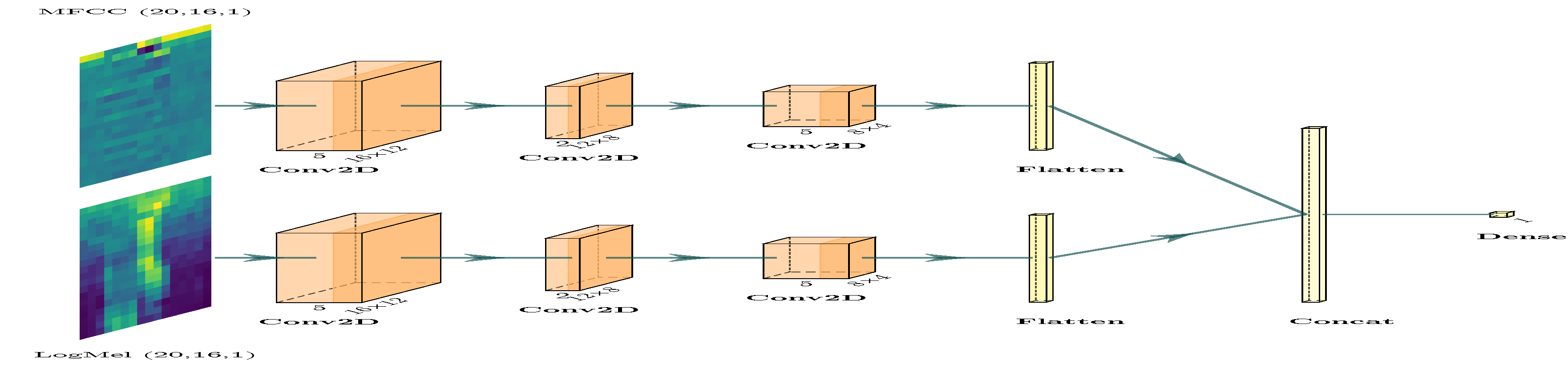
Применение методов шумоподавления, таких как вейвлет-деноизинг и спектральный деноизинг, существенно повышает качество входных данных, используемых в системах обработки сигналов. Эти техники эффективно устраняют нежелательные шумы и артефакты, что позволяет извлекать более четкую и информативную картину из исходного сигнала. В частности, обработка аудио-признаков, таких как MFCC и LogMel спектрограммы, с использованием данных методов, значительно улучшает надежность полученных представлений, способствуя более точной и стабильной работе моделей машинного обучения. Это особенно важно в условиях реального мира, где данные часто бывают зашумлены, и даже незначительные улучшения качества сигнала могут привести к существенному повышению производительности системы.
Для повышения надежности извлекаемых признаков, методы обработки сигнала применяются непосредственно к аудиохарактеристикам, таким как MFCC (Mel-Frequency Cepstral Coefficients) и LogMel спектрограммы. Эти спектрограммы, представляющие собой визуальное отображение частотного состава звука во времени, подвергаются обработке для снижения шумов и выделения наиболее значимых компонентов. Улучшение качества этих представлений позволяет моделям машинного обучения формировать более устойчивые и точные представления о звуковом сигнале, что критически важно для распознавания речи, анализа звуковых событий и других приложений, где шум может существенно искажать исходные данные. По сути, обработка спектрограмм служит фильтром, отсеивающим нерелевантную информацию и усиливающим полезные сигналы, тем самым оптимизируя процесс обучения и повышая общую производительность системы.
Особое значение обработка сигналов приобретает в условиях зашумленной среды, где качество исходных данных напрямую влияет на эффективность работы моделей машинного обучения. В частности, применение методов шумоподавления позволяет значительно повысить точность распознавания, демонстрируя впечатляющие результаты — до 95.28% в сложной акустической среде TCAR при отношении сигнал/шум 0 дБ. Это свидетельствует о том, что даже при крайне неблагоприятных условиях, грамотная предварительная обработка сигнала способна обеспечить высокую надежность и устойчивость систем автоматического распознавания, открывая возможности для их применения в реальных, зачастую шумных, сценариях.
Методика постепенного обучения в новой области, объединенная с домейн-адверсариальными нейронными сетями, позволяет моделям адаптироваться к меняющимся условиям и распределениям данных. Данный подход позволяет системе последовательно осваивать информацию из новых источников, не забывая при этом знания, полученные ранее. Домейн-адверсариальные сети, в свою очередь, способствуют извлечению общих, доменно-независимых признаков, что повышает устойчивость модели к изменениям в характеристиках входных данных. Это особенно важно в реальных условиях, где входные данные могут значительно различаться по качеству и происхождению, обеспечивая надежную работу системы даже при существенном смещении данных.

Будущее Адаптивного Периферийного Интеллекта
Схождение квантованных нейронных сетей, непрерывного обучения и передовых методов обработки сигналов открывает путь к созданию действительно адаптивного периферийного интеллекта. Этот синергетический подход позволяет устройствам не просто реагировать на входные данные, но и постоянно совершенствовать свои алгоритмы, обучаясь непосредственно на потоке информации в реальном времени. В результате, периферийные устройства становятся способными к самооптимизации, приспосабливаясь к меняющимся условиям окружающей среды и потребностям пользователя, что обеспечивает более эффективную и персонализированную работу даже в условиях ограниченных ресурсов. Такая адаптивность принципиально отличает новое поколение устройств от традиционных систем с фиксированными параметрами, предлагая качественно иной уровень взаимодействия и функциональности.
Современные алгоритмы позволяют реализовать функцию постоянного распознавания ключевых слов и анализа звука в режиме реального времени даже на устройствах с ограниченными вычислительными ресурсами. Исследования демонстрируют, что подобная технология достигает высокой точности — 93.84% — в сложных акустических условиях, таких как среда NFIELD при отношении сигнал/шум -10 дБ. Это открывает возможности для создания “всегда включенных” интеллектуальных устройств, способных оперативно реагировать на голосовые команды или анализировать окружающие звуки, не требуя значительных энергозатрат и сохраняя высокую производительность даже в зашумленной обстановке.
Перспективные исследования в области адаптивного периферийного интеллекта направлены на создание алгоритмов, демонстрирующих повышенную эффективность и устойчивость к помехам. Недавние разработки позволили добиться энергопотребления в 64.45 μJ при использовании оптимизированного оборудования M4 и значительно меньшего числа параметров — всего 1,595, что существенно превосходит показатели более сложных моделей, таких как MCUNetv3 и DSCNN-S. Такой подход открывает возможности для создания интеллектуальных устройств с минимальным энергопотреблением и расширенными возможностями адаптации к окружающей среде, позволяя им функционировать продолжительное время от небольших источников питания и эффективно обрабатывать данные в реальном времени.
Появление нового поколения интеллектуальных устройств, способных к непрерывной адаптации к окружающей среде, открывает перспективы персонализированного взаимодействия. Эти устройства, функционирующие на базе оптимизированных алгоритмов и квантованных нейронных сетей, смогут не только распознавать голосовые команды в сложных акустических условиях, но и обучаться на основе индивидуальных предпочтений пользователя. Подобная адаптивность позволит создавать системы, реагирующие на изменения в окружении и предлагающие релевантный контент или услуги, что существенно повысит удобство и эффективность использования гаджетов в повседневной жизни. В будущем, можно ожидать появление устройств, предсказывающих потребности пользователя и предлагающих проактивные решения, что кардинально изменит взаимодействие человека и техники.
Представленное исследование демонстрирует, что попытки построить универсальную систему распознавания ключевых слов в постоянно меняющихся условиях обречены на неудачу. Вместо этого, акцент делается на адаптации и сохранении знаний, полученных в различных доменах. Это напоминает подход, когда система не проектируется, а скорее взращивается, подобно организму, адаптирующемуся к окружающей среде. Как однажды заметил Пол Эрдёш: «Математика — это искусство открывать закономерности, а не просто решать задачи». В данном контексте, прототипное обучение и репетитивная память выступают не как инструменты, а как механизмы, позволяющие системе «вспоминать» и адаптироваться к новым условиям, подобно тому, как опыт формирует знания. И подобно тому, как порядок — это лишь временный буфер между двумя сбоями, стабильность системы распознавания ключевых слов требует постоянной адаптации и обучения.
Куда Ведет Дорога?
Представленная работа, несомненно, представляет собой еще один шаг на пути к адаптивным системам распознавания ключевых слов. Однако, не стоит обманываться кажущейся устойчивостью. Каждая оптимизация, каждое сжатие модели — это не победа над энтропией, а лишь отсрочка неизбежного. Система не «запоминает» новые домены, она приобретает новые формы уязвимости, скрытые до момента столкновения с непредсказуемым шумом реальности. Идея «репетиторной памяти» лишь иллюзия контроля над потоком забывания; вопрос в том, что именно будет забыто первым, и какие неожиданные последствия это повлечет.
Вместо того чтобы стремиться к идеальному «непрерывному обучению», более плодотворным представляется исследование механизмов самоорганизации и адаптации, имитирующих биологические системы. Вместо хранения «прототипов», возможно, стоит обратить внимание на принципы распределенного представления знаний и неявного обучения. Настоящая устойчивость кроется не в количестве сохраненных примеров, а в способности системы к быстрой и эффективной перестройке в ответ на изменения окружающей среды.
В конечном счете, эта работа поднимает фундаментальный вопрос: что значит «понять» для машины? Или, возможно, правильнее спросить: что значит «выжить» в условиях постоянной неопределенности? До тех пор, пока мы будем воспринимать системы как инструменты, а не как развивающиеся экосистемы, мы обречены на повторение одних и тех же ошибок. Долговременная стабильность — не признак совершенства, а предвестник неминуемой катастрофы.
Оригинал статьи: https://arxiv.org/pdf/2601.16158.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Робот-исследователь: новый подход к автономной навигации
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Биомолекулярные связи: новый тест для искусственного интеллекта
2026-01-24 18:35