Автор: Денис Аветисян
Новая методика позволяет автоматически оценивать и улучшать работу ИИ-агентов, проводящих научные исследования, выявляя ошибки и адаптируясь в процессе работы.
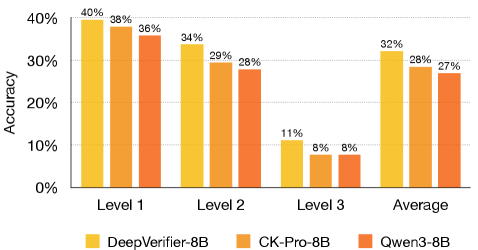
Представлен DeepVerifier — фреймворк для верификации и масштабирования надежности ИИ-агентов на этапе выполнения задач, использующий рубрики оценки и автоматическую обратную связь.
Несмотря на значительный прогресс в области автоматизированного поиска знаний, современные Deep Research Agents (DRA) часто сталкиваются с проблемами надежности и самосогласованности. В данной работе, ‘Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification’, предложен новый подход к эволюции DRA, основанный на верификации результатов работы агента в процессе инференса с использованием тщательно разработанных рубрик. Разработанный фреймворк DeepVerifier позволяет достичь улучшения точности на 8-11% на сложных датасетах, таких как GAIA и XBench-DeepResearch, за счет автоматического анализа ошибок и итеративной доработки ответов. Сможет ли подобный механизм самоверификации стать основой для создания по-настоящему автономных и надежных систем интеллектуального поиска?
Задача: Надёжность Глубоких Исследовательских Агентов
Глубокие исследовательские агенты (DRA), использующие возможности больших языковых и визуально-языковых моделей, представляют собой значительный прорыв в автоматизированном сборе и анализе информации. Однако, несмотря на свой потенциал, эти агенты склонны к ошибкам при решении сложных задач, требующих многоступенчатого рассуждения и интерпретации. Ошибки могут возникать из-за неточностей в исходных данных, неоднозначности запросов или ограничений самих моделей в понимании контекста. Сложность задач, включающих поиск, синтез и проверку информации из различных источников, создает значительные трудности для поддержания высокой точности и надежности DRA, что подчеркивает необходимость разработки новых методов контроля качества и верификации результатов их работы.
Традиционные методы оценки результатов, генерируемых агентами глубоких исследований, сталкиваются со значительными трудностями, создавая узкое место в процессе автоматического обнаружения знаний. Существующие подходы, такие как ручная проверка или простые метрики соответствия, часто не способны выявить тонкие ошибки, неточности или логические несоответствия, особенно в сложных задачах, требующих анализа большого объема информации и установления причинно-следственных связей. Это ограничивает возможность масштабирования агентов глубоких исследований, поскольку необходимость в постоянном контроле со стороны человека снижает их автоматизацию и эффективность. Неспособность надежно верифицировать результаты ставит под вопрос достоверность полученных знаний и препятствует широкому применению этих агентов в критически важных областях, где точность и обоснованность информации имеют первостепенное значение.
Надежность и масштабируемость интеллектуальных агентов для глубоких исследований (DRAs) напрямую зависят от способности к эффективной верификации их результатов. Без надежных механизмов подтверждения достоверности, сложность задач и потенциальные ошибки в работе DRAs становятся критическим препятствием для автоматического получения знаний. Ограниченная возможность проверки полученных данных не позволяет в полной мере использовать потенциал этих систем, поскольку ненадежные выводы могут привести к ошибочным решениям и искажению информации. В конечном итоге, отсутствие адекватной верификации существенно ограничивает масштабируемость DRAs, препятствуя их широкому применению в областях, требующих высокой точности и надежности информации, таких как научные исследования, анализ данных и принятие стратегических решений.
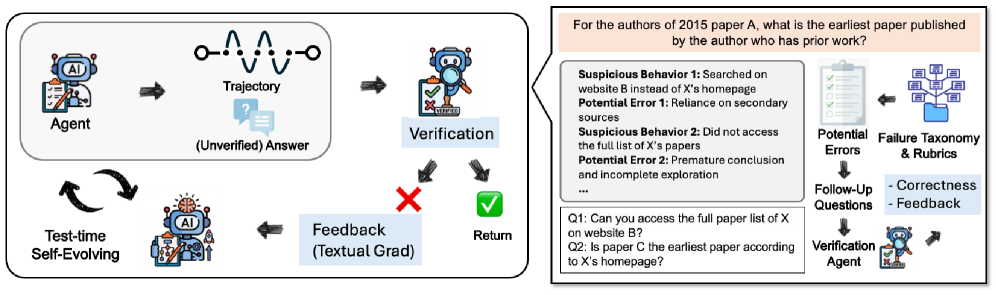
Использование Асимметрии Верификации с DeepVerifier
DeepVerifier реализует автоматизированный конвейер, основанный на принципах агентного подхода, для верификации результатов, генерируемых системой DRA. В основе работы лежит наблюдение о том, что процесс проверки (верификации) зачастую требует меньше вычислительных ресурсов и сложнее в плане ошибок, чем процесс генерации новых данных. Система построена таким образом, чтобы использовать эту асимметрию, позволяя более эффективно и надежно оценивать качество выходных данных DRA, чем если бы использовался аналогичный агентный подход для их генерации. Это позволяет снизить затраты на вычислительные ресурсы и повысить общую надежность системы.
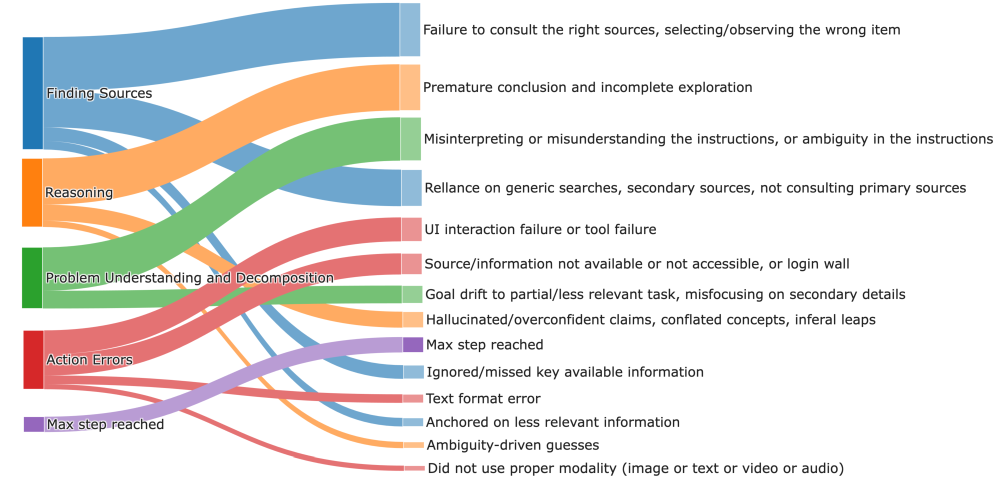
Система DeepVerifier использует структурированный подход к верификации, основанный на таксономии ошибок DRA (Direct Reasoning Agent). Эта таксономия классифицирует типичные ошибки, возникающие в процессе генерации ответов, позволяя системе идентифицировать конкретные недостатки в выходных данных DRA. Классификация по таксономии позволяет предоставить целевую обратную связь, указывающую на тип допущенной ошибки, что способствует более эффективной коррекции и улучшению качества ответов. Таксономия служит основой для разработки рубрик, используемых в системе вознаграждений, обеспечивая более точную оценку и направленное обучение модели.
Система DeepVerifier использует систему вознаграждений, основанную на рубриках, для повышения эффективности процесса верификации. Эти рубрики формируются на основе таксономии ошибок DRA, позволяя выделять и оценивать конкретные типы дефектов в генерируемых ответах. Вознаграждения, присваиваемые верификатору в зависимости от точности выявления и классификации ошибок согласно рубрикам, служат как дискриминирующий сигнал, направляя процесс верификации и повышая его точность. Использование рубрик позволяет системе отличать более сложные ошибки от простых, обеспечивая более детализированную и релевантную обратную связь для улучшения DRA.
Обучение и Совершенствование DeepVerifier: Сила Данных
В основу обучения с учителем модели верификации DeepVerifier-8B положен датасет DeepVerifier-4K, состоящий из тщательно отобранных пар «вопрос-ответ». Этот датасет был специально разработан для повышения точности и надежности модели в процессе верификации. Процесс курирования включал в себя отбор примеров, обеспечивающих разнообразие сценариев и сложность вопросов, что позволило модели научиться более эффективно различать правдивые и ложные утверждения. Объем датасета DeepVerifier-4K составляет 4000 тщательно проверенных пар, что является ключевым фактором, обеспечивающим высокую производительность модели.
Процесс контролируемой тонкой настройки на основе набора данных DeepVerifier-4K позволил создать модель DeepVerifier-8B, демонстрирующую значительное повышение точности верификации. В ходе тестирования DeepVerifier-8B показал улучшение на 5.5% по сравнению с предыдущими версиями, что свидетельствует о более эффективной и детализированной оценке соответствия между запросом и ответом. Данное улучшение достигнуто за счет оптимизации параметров модели на специально подобранном наборе данных, обеспечивающем более точную и надежную верификацию.
Эффективность DeepVerifier обусловлена его модульной архитектурой, состоящей из трех основных компонентов. Модуль декомпозиции (Decomposition Module) отвечает за разделение сложного запроса на более простые, поддающиеся анализу подзадачи. Модуль верификации (Verification Module) анализирует каждую подзадачу и сопоставляет ее с соответствующими источниками информации для подтверждения или опровержения утверждений. Наконец, модуль оценки (Judge Module) объединяет результаты верификации всех подзадач, формируя итоговое заключение о достоверности исходного запроса. Взаимодействие этих модулей позволяет DeepVerifier комплексно анализировать информацию и обеспечивать высокую точность верификации.
Подтверждение Производительности и Масштабируемости DeepVerifier
Оценка производительности DeepVerifier с использованием эталонного набора данных GAIA продемонстрировала его высокую эффективность в проверке результатов, полученных от агентов DRA (Differential Reasoning Agents). Исследование показало, что система способна точно оценивать ответы в широком спектре задач, включающих логическое мышление, обработку мультимодальных данных и анализ информации, полученной в процессе веб-серфинга. В результате применения DeepVerifier наблюдается значительное повышение общей точности оценки — с 52% до 59%, что свидетельствует о его потенциале для улучшения надежности и достоверности систем, основанных на DRA, и обеспечения более качественной оценки их работы в различных сценариях.
Интеграция DeepVerifier с передовой системой Cognitive Kernel-Pro демонстрирует его высокую совместимость с современными фреймворками для разработки агентов, работающих на основе рассуждений (DRA). Данное взаимодействие подтверждает, что DeepVerifier может эффективно использоваться в качестве ключевого компонента для оценки достоверности и обоснованности ответов, генерируемых сложными системами искусственного интеллекта. Такая совместимость позволяет разработчикам легко внедрять DeepVerifier в существующие рабочие процессы и масштабировать решения на основе DRA, обеспечивая надежную проверку и повышение общей производительности интеллектуальных агентов. Это открывает возможности для создания более доверенных и эффективных систем, способных к сложному рассуждению и взаимодействию с окружающим миром.
В ходе исследований было показано, что применение методов масштабирования во время тестирования и цикла рефлексивной обратной связи значительно повышает эффективность DeepVerifier при проведении анализа. В частности, точность оценки на наборе данных GAIA увеличилась на 8%, а на бенчмарке BrowseComp — от 5,0% до 10,0%. Кроме того, наблюдались улучшения в работе с XBench-DeepSearch, где точность выросла с 41,0% до 47,0%, а показатель F1 — от 12% до 48% при мета-оценке. Эти результаты демонстрируют, что предложенные техники позволяют DeepVerifier более надежно и точно оценивать ответы, полученные от различных систем, даже в сложных сценариях поиска и анализа информации.
Представленная работа демонстрирует стремление к упрощению сложных систем, что перекликается с идеями Анри Пуанкаре. Он утверждал: «Наука не состоит из цепи, а из паутины». Данное исследование, предлагая DeepVerifier для автоматизированной верификации Deep Research Agents (DRAs), как бы плетет эту паутину, создавая систему, способную к самоэволюции и масштабированию на этапе тестирования. Акцент на анализе таксономии ошибок и использовании рубрик для оценки, в конечном счете, направлен на повышение надежности DRAs, что является воплощением принципа структурной честности, где ясность и точность преобладают над избыточностью.
Что дальше?
Представленная работа, стремясь к надежности систем глубокого исследования, обнажает не столько решение, сколько сущность проблемы. Автоматизированная верификация, как и любая попытка формализации мышления, неизбежно сталкивается с границами собственного понимания. Классификация неудач — полезный инструмент, но истинная сложность заключается не в перечислении ошибок, а в предвидении их возникновения. Попытка масштабирования в процессе работы — логичный шаг, однако он лишь отодвигает вопрос о фундаментальной непроверяемости, присущей любой системе, действующей в условиях неполной информации.
Будущие исследования, вероятно, должны сместить фокус с поиска идеальной метрики надежности на разработку систем, способных признавать и корректно обрабатывать собственную неопределенность. Важнее не устранить ошибки, а научиться извлекать из них пользу, воспринимая их как сигнал о необходимости пересмотра базовых предположений. Стремление к “саморазвивающимся агентам” обречено на провал, если не будет сопровождаться осознанием границ их познания.
В конечном счете, истинный прогресс заключается не в создании более сложных систем, а в их упрощении. Иногда, чтобы увидеть суть, достаточно убрать лишнее. Иначе, в погоне за совершенством, рискуем потерять из виду самое главное — ясность.
Оригинал статьи: https://arxiv.org/pdf/2601.15808.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-24 20:07