Автор: Денис Аветисян
Новое исследование показывает, как комбинировать современные методы поиска и обработки языка для получения более точных и надежных ответов на вопросы, связанные с нормативными документами.
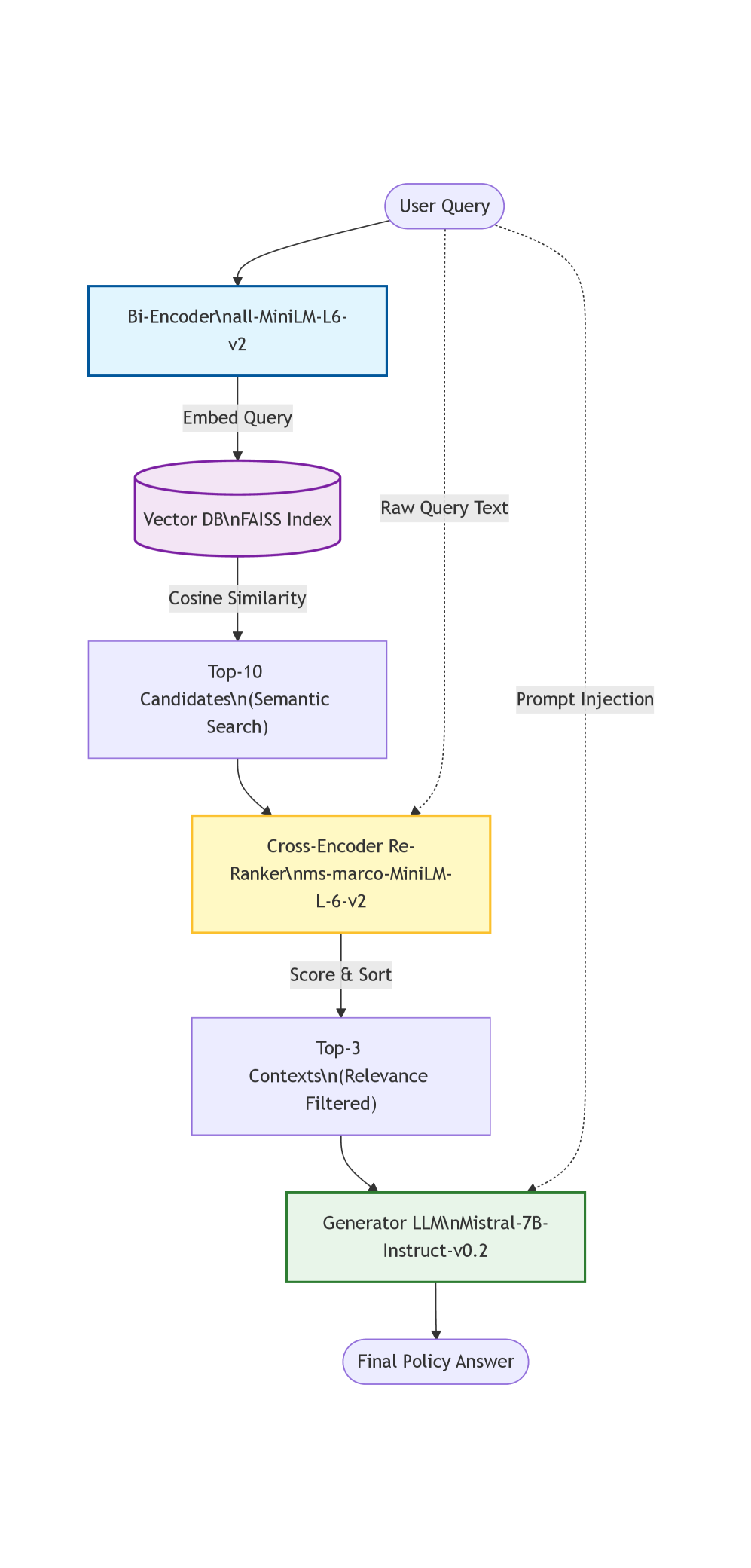
Эмпирическая оценка архитектур Retrieval-Augmented Generation (RAG) с использованием двухуровневого поиска и кросс-энкодеров для ответа на вопросы по политическим документам.
Несмотря на огромный потенциал больших языковых моделей (LLM) в сфере государственного управления, их склонность к галлюцинациям представляет серьезную проблему для областей, требующих высокой точности информации. В данной работе, ‘Chunking, Retrieval, and Re-ranking: An Empirical Evaluation of RAG Architectures for Policy Document Question Answering’, исследуется эффективность архитектур Retrieval-Augmented Generation (RAG) в снижении этих рисков при работе с нормативными документами Центров по контролю и профилактике заболеваний (CDC). Полученные результаты демонстрируют, что двухэтапный процесс извлечения информации с использованием кросс-энкодера значительно повышает достоверность ответов LLM на сложные вопросы по политике. Какие дальнейшие оптимизации стратегий сегментации документов необходимы для повышения эффективности многошаговых рассуждений в системах на основе LLM?
Вызов контекста в современных НЛП-моделях
Несмотря на впечатляющие возможности современных больших языковых моделей, их производительность часто ограничивается длиной контекста и вычислительными затратами. Обработка обширных текстов требует значительных ресурсов, что приводит к замедлению работы и увеличению стоимости вычислений. Существующие архитектуры сталкиваются с трудностями при удержании и эффективном использовании информации из длинных последовательностей, что негативно сказывается на точности и последовательности генерируемого текста. В результате, способность модели к глубокому пониманию и генерации сложных, контекстуально релевантных ответов существенно снижается, особенно при работе с задачами, требующими анализа больших объемов информации.
Традиционные методы обработки естественного языка часто сталкиваются с трудностями при работе с обширными базами знаний. Вместо полноценного понимания и логического вывода, системы зачастую ограничиваются поверхностным сопоставлением данных, что приводит к неточностям и упрощенному восприятию информации. Особенно это проявляется в задачах, требующих глубокого анализа контекста и учета взаимосвязей между различными фактами. Неспособность эффективно интегрировать и использовать широкий спектр знаний лишает модель возможности генерировать действительно осмысленные и нюансированные ответы, снижая ее общую надежность и достоверность.
Расширенная генерация с поиском: преодолевая ограничения знаний
Генеративные модели с расширенным поиском (RAG) решают проблему ограниченности знаний и устаревшей информации в больших языковых моделях (LLM) за счет комбинирования их возможностей с внешним поиском релевантных данных. Вместо того, чтобы полагаться исключительно на параметры, полученные в процессе обучения, RAG системы динамически извлекают информацию из внешних источников знаний, таких как базы данных документов или веб-сайты, и используют её для дополнения входных данных для LLM. Это позволяет модели генерировать ответы, основанные на актуальной и проверенной информации, преодолевая ограничения, присущие только параметрическим LLM.
Системы Retrieval-Augmented Generation (RAG) функционируют посредством двух последовательных этапов. На первом этапе происходит поиск релевантных документов в базе знаний, используя методы информационного поиска, такие как семантический поиск или поиск по ключевым словам. На втором этапе извлеченные документы добавляются к входным данным языковой модели в качестве контекста. Это расширение входных данных позволяет модели генерировать ответы, основанные не только на её внутренних знаниях, но и на актуальной, специфической информации, полученной из базы знаний, что существенно повышает точность и релевантность генерируемого текста.
Внедрение подхода Retrieval-Augmented Generation (RAG) демонстрирует существенное повышение качества генерируемых ответов по сравнению с традиционными большими языковыми моделями (Vanilla LLM). Согласно проведенным оценкам, RAG обеспечивает увеличение достоверности генерируемого контента на 79%, что свидетельствует о значительном снижении вероятности генерации фактических ошибок или неточной информации. Кроме того, наблюдается повышение релевантности ответов на 55%, указывающее на улучшенную способность модели предоставлять информацию, непосредственно относящуюся к заданному вопросу или контексту. Эти показатели подтверждают эффективность RAG в предоставлении более точных, информативных и контекстуально уместных ответов.
Двухэтапный конвейер для оптимизированного поиска информации
В исследовании реализован двухэтапный конвейер поиска информации, включающий в себя Bi-Encoder для первичного, быстрого отбора кандидатов и Cross-Encoder для точной переоценки релевантности. Такой подход позволяет эффективно обрабатывать большие объемы данных, сначала быстро идентифицируя потенциально релевантные документы, а затем детально оценивая их соответствие запросу. Bi-Encoder обеспечивает высокую скорость работы, в то время как Cross-Encoder повышает точность за счет более глубокого семантического анализа, что в совокупности оптимизирует процесс поиска.
В системе используется Bi-Encoder для быстрого поиска потенциально релевантных документов в базе знаний. Этот компонент основан на архитектуре Sentence-BERT и использует метрику косинусного сходства для оценки семантической близости между запросом и документами. В ходе тестирования на сложных запросах, Bi-Encoder демонстрирует точность выявления релевантных документов в диапазоне от 65% до 80%, что обеспечивает эффективное сокращение объема данных для последующей обработки.
Кросс-энкодер, использующий архитектуру Transformer и модель ms-marco-MiniLM-L-6-v2, выполняет переранжирование отобранных кандидатов, оценивая их семантическую релевантность запросу. Этот процесс позволяет повысить общую точность поиска до 85-90% на стандартных веб-поисковых бенчмарках. В отличие от Bi-Encoder, кросс-энкодер анализирует запрос и документ одновременно, что позволяет более точно оценивать смысловую близость, но требует значительно больших вычислительных ресурсов и времени обработки.
Оценка эффективности и перспективы развития
Тщательная оценка продемонстрировала, что разработанный двухэтапный конвейер RAG (Retrieval-Augmented Generation) значительно превосходит базовые модели как по релевантности, так и по достоверности генерируемых ответов. В частности, зафиксировано относительное улучшение достоверности на 28% по сравнению с простой конфигурацией RAG. Это означает, что система не только предоставляет более соответствующие запросу сведения, но и значительно снижает вероятность генерации фактических ошибок или галлюцинаций, что критически важно для приложений, требующих высокой точности и надежности информации.
Перспективным направлением для дальнейших исследований является интеграция знаний из графов знаний, что позволит существенно снизить вероятность галлюцинаций и повысить фактическую точность генерируемых ответов. Вместо простой извлечения информации из текстовых документов, система сможет использовать структурированные связи между понятиями, представленные в графе знаний, для проверки и дополнения извлеченных фактов. Такой подход позволит не только верифицировать информацию, но и выявлять противоречия, а также обогащать ответы дополнительными сведениями, недоступными в исходных документах, что значительно повысит надежность и полноту предоставляемой информации.
Исследования показывают, что применение методов структурированного разбиения документов на фрагменты имеет решающее значение для сохранения логической связности сложных рабочих процессов, описанных в политических документах. Традиционные методы фрагментации часто приводят к разделению последовательных этапов, что затрудняет понимание и анализ. Внедрение техник, учитывающих структуру документа — например, выделение логических блоков и поддержание их целостности при разделении — позволяет избежать фрагментации, обеспечивая последовательность и когерентность генерируемых выводов. Это особенно важно при работе с нормативными актами и политическими руководствами, где нарушение логической связи может привести к неверной интерпретации и принятию ошибочных решений.
Масштабирование RAG: к надежным и безопасным системам
Для полной реализации потенциала RAG, особенно в областях, связанных с конфиденциальными данными, необходима надежная и безопасная структура обмена информацией. Существующие системы часто сталкиваются с проблемами при интеграции внешних источников знаний, что создает уязвимости в плане безопасности и точности предоставляемой информации. Надежный фреймворк обмена данными позволяет не только эффективно использовать разнообразные источники знаний, но и гарантирует защиту от несанкционированного доступа, манипуляций и утечек информации. Это особенно важно в контексте критически важных приложений, где достоверность и целостность данных имеют первостепенное значение, а компрометация может привести к серьезным последствиям. Современные подходы к разработке подобных фреймворков включают в себя механизмы аутентификации, авторизации, шифрования и аудита, обеспечивающие многоуровневую защиту на протяжении всего жизненного цикла данных.
Разработка протокола контекста модели открывает возможности для беспрепятственного подключения внешних источников знаний, одновременно обеспечивая строгие стандарты безопасности. Этот протокол позволяет системе RAG (Retrieval-Augmented Generation) динамически и безопасно получать доступ к актуальной информации, необходимой для формирования точных и обоснованных ответов. В его основе лежит четкое определение прав доступа и механизмов аутентификации, что предотвращает несанкционированный доступ к конфиденциальным данным. Кроме того, протокол предусматривает шифрование данных как при передаче, так и при хранении, а также ведение подробного журнала всех операций для обеспечения прозрачности и возможности аудита. Благодаря такому подходу, RAG-системы становятся более надежными и устойчивыми к потенциальным угрозам, позволяя использовать их в критически важных областях, где конфиденциальность и достоверность информации имеют первостепенное значение.
Разработка и внедрение систем извлечения информации с помощью генеративных моделей (RAG) открывает новые возможности для принятия решений в критически важных областях, таких как государственное управление. Обеспечение высокой точности, прозрачности и безопасности становится первостепенной задачей при использовании RAG в подобных сценариях. Это требует не только тщательной проверки источников информации и механизмов ее обработки, но и внедрения строгих протоколов контроля доступа и аудита. Успешное применение RAG в государственном секторе позволит повысить качество принимаемых решений, обеспечить их обоснованность и, как следствие, укрепить доверие граждан к органам власти. Внедрение подобных систем предполагает комплексный подход, охватывающий как технические аспекты, так и вопросы этики и ответственности.
Исследование демонстрирует, что многоступенчатый конвейер извлечения информации, включающий кросс-энкодер, существенно повышает точность и надёжность больших языковых моделей при работе со сложными вопросами, касающимися нормативных документов. Этот подход позволяет не просто находить релевантные фрагменты текста, но и оценивать их значимость в контексте конкретного вопроса, что критически важно для обеспечения фактической точности ответов. Как заметил Блез Паскаль: «Всякое великое дело начинается с малого». В данном случае, кажущееся небольшим улучшение в архитектуре извлечения информации приводит к значительным результатам в решении сложной задачи соответствия политике и обеспечения достоверности фактов.
Что дальше?
Представленная работа, демонстрируя преимущество двухэтапного поиска с применением кросс-энкодера, лишь подчеркивает фундаментальную проблему: оптимизация чего? Точность ответа — да, но к какой цене? Настоящая надежность системы Retrieval-Augmented Generation (RAG) определяется не только способностью извлекать релевантную информацию, но и её способностью отличать необходимое от случайного. Простота архитектуры, как элегантный дизайн, должна быть направлена не на минимализм, а на ясность структуры, определяющей поведение системы.
Остаётся нерешённой проблема оценки «фактической верности» (factual faithfulness). Достаточно ли простого сопоставления с исходным документом, или необходимо более глубокое понимание контекста и намерений, заложенных в политических документах? Игнорирование этой сложности неизбежно ведёт к созданию систем, способных генерировать правдоподобные, но неверные ответы. Более того, исследование возможности применения аналогичных подходов к задачам, требующим не просто извлечения фактов, а синтеза и обобщения информации, представляется крайне перспективным.
Следующим шагом видится переход от оценки производительности отдельных компонентов к анализу системы в целом как живого организма. Нельзя «чинить» одну часть, не понимая, как она взаимодействует с другими. Поиск оптимальной структуры RAG, способной адаптироваться к изменяющимся требованиям и обеспечивать надежность и прозрачность, — задача, требующая не только технических усовершенствований, но и философского осмысления самой природы знания.
Оригинал статьи: https://arxiv.org/pdf/2601.15457.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-24 23:29