Автор: Денис Аветисян
Новый подход к активному обучению использует возможности нескольких больших языковых моделей для автоматической разметки данных, снижая затраты и повышая надежность.
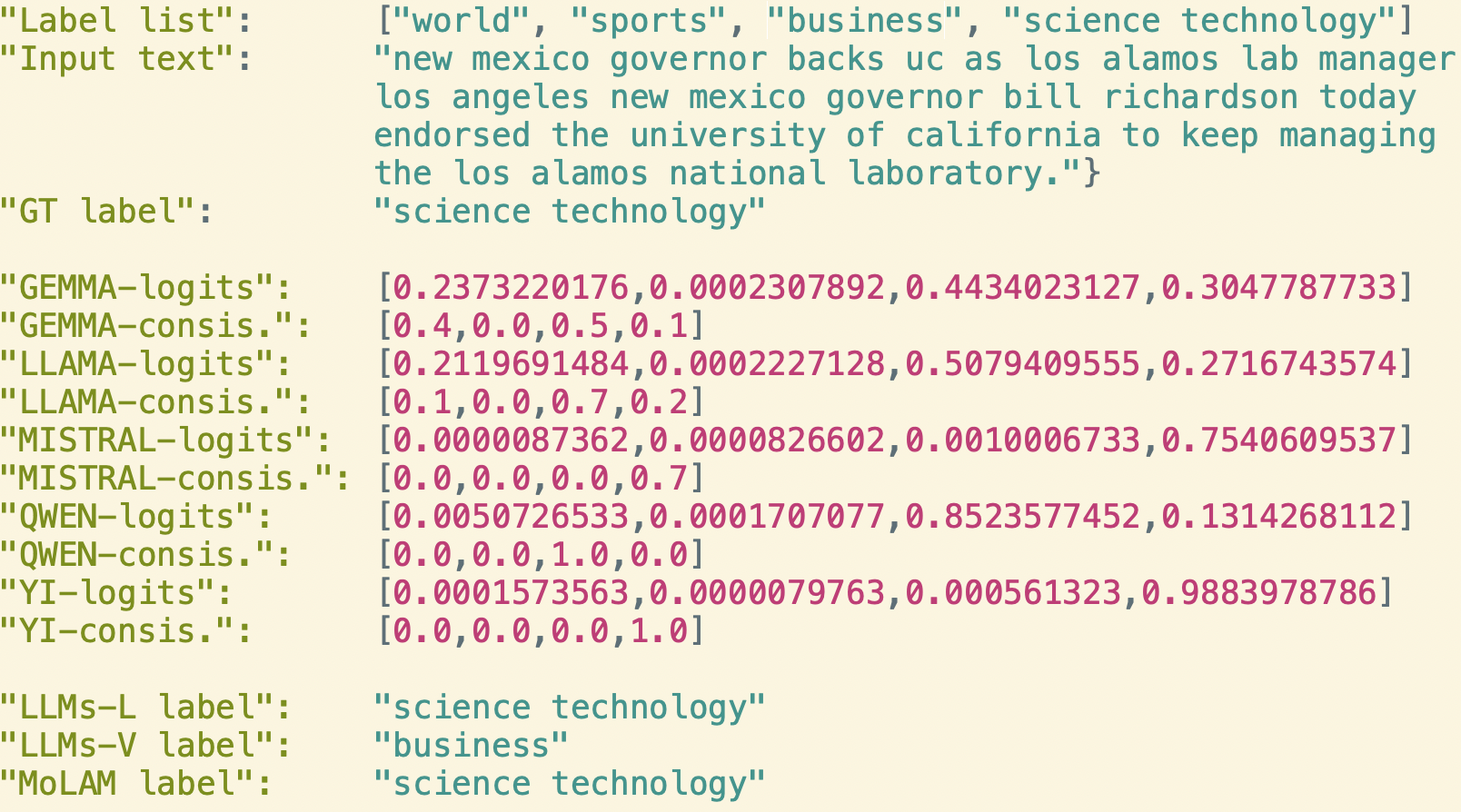
Представлен MoLLIA — фреймворк активного обучения, заменяющий ручную разметку смесью языковых моделей и решающий проблемы зашумленных данных и расхождений в аннотациях.
Несмотря на значительный прогресс в области активного обучения, высокая стоимость ручной разметки данных остается серьезным препятствием. В данной работе, озаглавленной ‘Next Generation Active Learning: Mixture of LLMs in the Loop’, предлагается новый подход, заменяющий людей-аннотаторов аннотатором на основе смеси больших языковых моделей (LLM). Предложенная схема MoLLIA, использующая техники снижения влияния зашумленных данных и выявления расхождений в разметке, демонстрирует сравнимую с человеческой точность и превосходит существующие методы, основанные на отдельных LLM или их ансамблях. Возможно ли дальнейшее повышение эффективности и надежности активного обучения за счет более тонкой настройки и адаптации моделей LLM к специфическим задачам?
Стоимость Разметки: Препятствие на Пути к Развитию NLP
Традиционное обучение с учителем в области обработки естественного языка требует колоссальных объемов размеченных данных, что становится серьезным препятствием для развития многих приложений. Для достижения высокой точности современных моделей необходимо, чтобы каждый элемент данных — будь то текст, изображение или аудио — был тщательно проанализирован и помечен экспертом. Однако, сбор и разметка таких данных — процесс трудоемкий, требующий значительных временных и финансовых затрат. Более того, ручная разметка подвержена человеческим ошибкам и субъективным интерпретациям, что снижает надежность и воспроизводимость результатов. В связи с этим, потребность в автоматизации и оптимизации процесса разметки данных становится всё более актуальной задачей для исследователей и разработчиков в области искусственного интеллекта.
Ручная аннотация данных представляет собой значительную проблему в современной обработке естественного языка. Процесс требует значительных временных и финансовых затрат, поскольку квалифицированные лингвисты тратят часы на разметку каждого образца текста или речи. Помимо стоимости, ручная аннотация подвержена человеческому фактору, что приводит к непоследовательности в оценках и, как следствие, к снижению качества обучаемых моделей. Эта непоследовательность особенно критична при работе с большими объемами данных, поскольку даже небольшие ошибки могут накапливаться и существенно влиять на производительность системы. В конечном итоге, сложность и дороговизна ручной аннотации ограничивают масштабируемость моделей и препятствуют широкому внедрению передовых NLP-технологий.
Активное обучение представляет собой перспективный подход к снижению затрат на разметку данных в современных задачах обработки естественного языка. Вместо случайного выбора примеров для ручной аннотации, данный метод предполагает стратегический отбор наиболее информативных образцов, что позволяет моделям быстрее достигать высокой точности при меньшем объеме размеченных данных. Однако эффективность активного обучения напрямую зависит от качества запросов — алгоритма, определяющего, какие именно примеры следует отправить на разметку. Неэффективный алгоритм запросов может привести к выбору избыточных или нерелевантных данных, сводя на нет преимущества подхода и увеличивая общие затраты. Таким образом, разработка и оптимизация алгоритмов запросов является ключевой задачей для успешного применения активного обучения в реальных приложениях.
Современные стратегии активного обучения, направленные на снижение затрат на разметку данных, часто сталкиваются с трудностями при работе с большими языковыми моделями. Существующие алгоритмы, разработанные для более простых задач, не всегда способны эффективно определять наиболее информативные примеры для разметки, учитывая сложность и многогранность современных нейронных сетей. Особенно остро стоит проблема обеспечения надежности аннотаций — даже небольшие неточности в размеченных данных могут существенно снизить производительность модели, а выявление и исправление этих ошибок требует дополнительных ресурсов. Таким образом, несмотря на перспективность активного обучения, его успешное применение в контексте больших языковых моделей требует разработки новых, более адаптивных и устойчивых к шуму стратегий отбора данных для разметки.
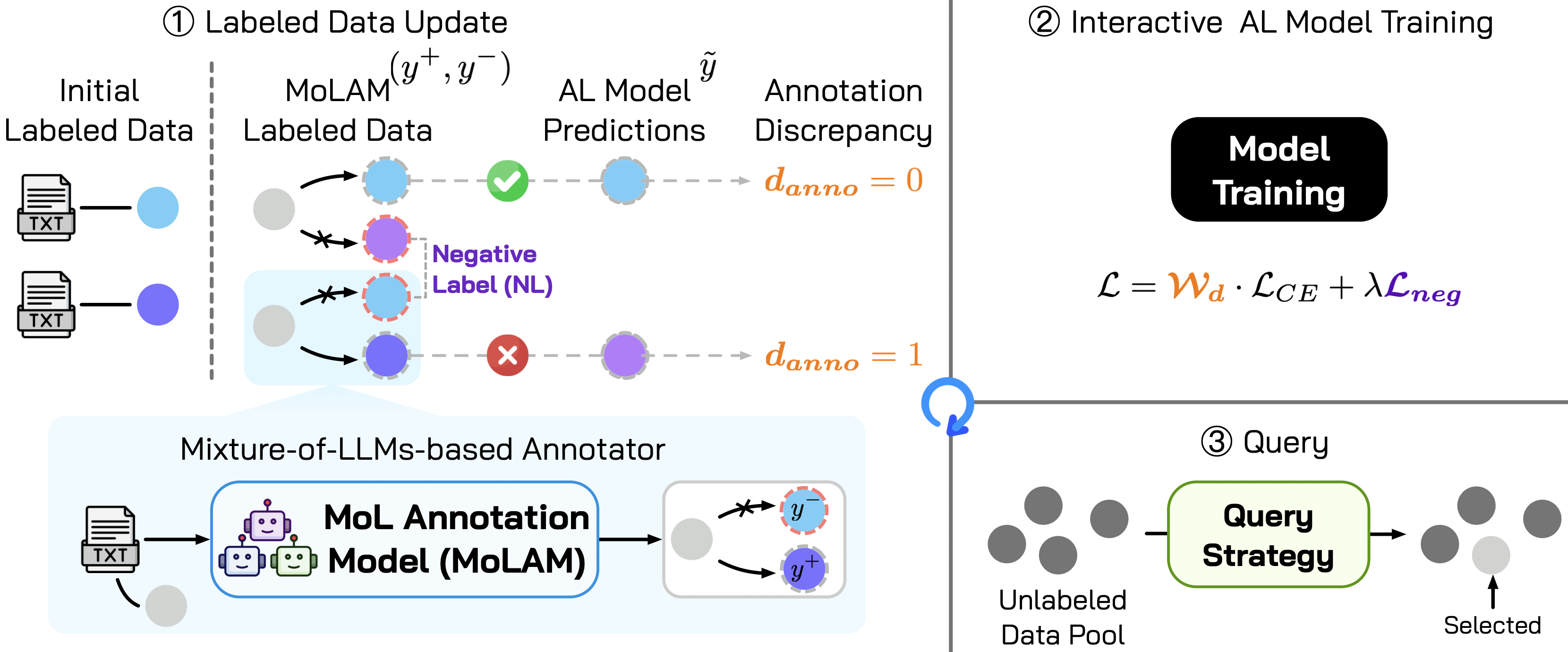
MoLLIA: Симбиоз Языковых Моделей для Интеллектуальной Разметки
MoLLIA использует подход, основанный на смеси языковых моделей (LLM), для генерации более надежных и устойчивых аннотаций. Вместо использования одной модели, MoLLIA объединяет прогнозы нескольких LLM, что позволяет снизить влияние индивидуальных смещений и несоответствий каждой модели. Такой подход позволяет компенсировать недостатки отдельных моделей, используя их сильные стороны, и тем самым повысить общую точность и надежность процесса аннотирования. Комбинация моделей достигается путем усреднения или взвешивания их прогнозов, что приводит к более консистентным и точным результатам по сравнению с использованием одной модели.
Компонент MoLAM в составе MoLLIA использует метод псевдоразметки для эффективного использования неразмеченных данных и повышения качества аннотаций. Псевдоразметка предполагает использование языковых моделей для автоматической генерации меток для неразмеченных данных. Эти автоматически сгенерированные метки, рассматриваемые как «псевдо-истина», затем используются в качестве обучающих данных для дальнейшей доработки модели аннотации. Процесс итеративный: модель предсказывает метки, эти метки используются для обучения, и процесс повторяется, что позволяет модели извлекать полезную информацию из неразмеченных данных и улучшать общую точность аннотаций без необходимости ручной разметки больших объемов данных.
Использование смеси языковых моделей (LLM) в MoLLIA позволяет снизить влияние индивидуальных смещений и несоответствий, присущих каждой отдельной модели. Вместо полагания на прогнозы одной LLM, MoLLIA объединяет выводы нескольких моделей, эффективно усредняя их сильные стороны и компенсируя слабые. Такой подход позволяет уменьшить вероятность ошибок, вызванных специфическими особенностями обучения или предвзятостями, заложенными в конкретной модели, и, как следствие, повысить общую надежность и согласованность получаемых аннотаций. По сути, смешивание моделей создает более устойчивую и объективную систему аннотирования.
В ходе тестирования на четырех различных эталонных наборах данных, система MoLLIA продемонстрировала качество аннотаций, сопоставимое с качеством, обеспечиваемым профессиональными аннотаторами-людьми. Это позволяет существенно снизить затраты, связанные с привлечением и оплатой труда людей для выполнения задач аннотирования данных, что делает MoLLIA экономически эффективной альтернативой традиционным методам. Полученные результаты подтверждают возможность автоматизации процесса аннотирования с сохранением высокого уровня точности и надежности.
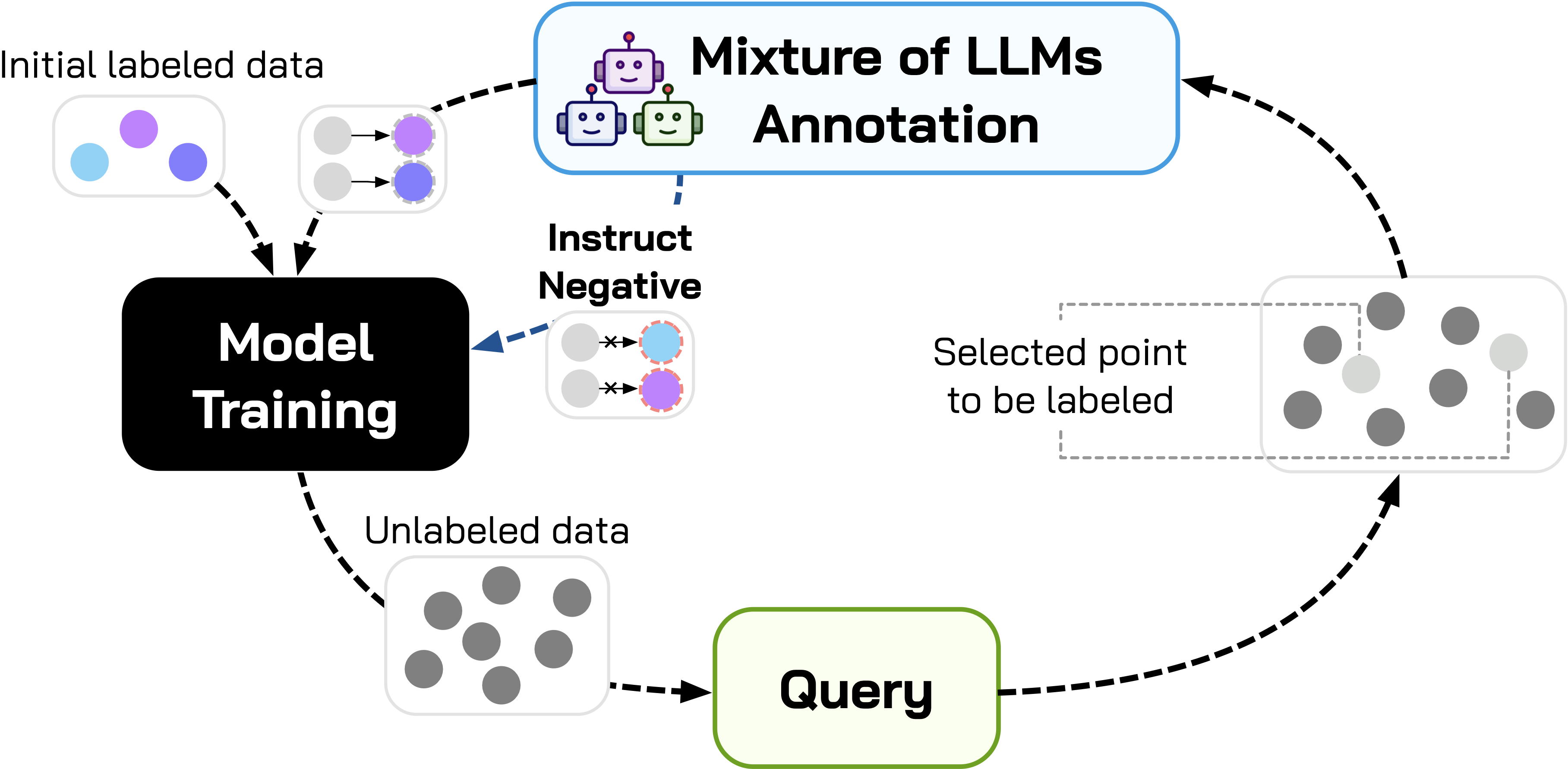
Стратегический Отбор: Методы Активного Обучения в MoLLIA
MoLLIA использует проверенные методы активного обучения, включая оценку неопределенности (Uncertainty Estimation), выбор ключевого подмножества данных (CoreSet), анализ устойчивости к шуму (Noise Stability) и алгоритм BEMPS для стратегического отбора образцов для аннотации. Оценка неопределенности определяет образцы, в которых модель проявляет наибольшую неуверенность в своих предсказаниях. CoreSet стремится выбрать репрезентативное подмножество данных, минимизируя расстояние между выбранными и невыбранными образцами. Анализ устойчивости к шуму фокусируется на образцах, которые наиболее чувствительны к небольшим изменениям во входных данных, указывая на потенциальную сложность. BEMPS (Batch Evaluation of Multiple Posterior Samples) использует несколько выборок из апостериорного распределения для более надежной оценки неопределенности. Комбинирование этих методов позволяет MoLLIA эффективно использовать ограниченные ресурсы аннотации, концентрируясь на наиболее информативных образцах.
MoLLIA использует комбинацию методов активного обучения — оценка неопределенности, CoreSet, устойчивость к шуму и BEMPS — для адаптации к различным распределениям данных и сценариям аннотирования. Такой подход позволяет максимизировать информативность каждой размеченной выборки, поскольку система динамически выбирает наиболее полезные данные для аннотации. Комбинирование методов обеспечивает более надежную идентификацию сложных или неоднозначных образцов, повышая эффективность обучения модели и снижая затраты на аннотирование по сравнению с использованием одного метода оценки неопределенности. Адаптивность MoLLIA особенно важна при работе с данными, имеющими различные характеристики или подверженными изменениям во времени.
Стратегии активного обучения, используемые в MoLLIA, играют ключевую роль в выявлении примеров, в отношении которых LLM-аннотаторы демонстрируют расхождения во мнениях или неуверенность в оценке. Это позволяет целенаправленно уточнять модель, фокусируясь на наиболее информативных и проблемных данных. Выявление таких примеров основано на анализе степени уверенности LLM в своих предсказаниях и сравнении результатов аннотирования различными моделями. Такой подход позволяет значительно сократить объем ручной аннотации, поскольку приоритет отдается примерам, которые наиболее существенно влияют на улучшение производительности модели и разрешение конфликтов между аннотаторами.
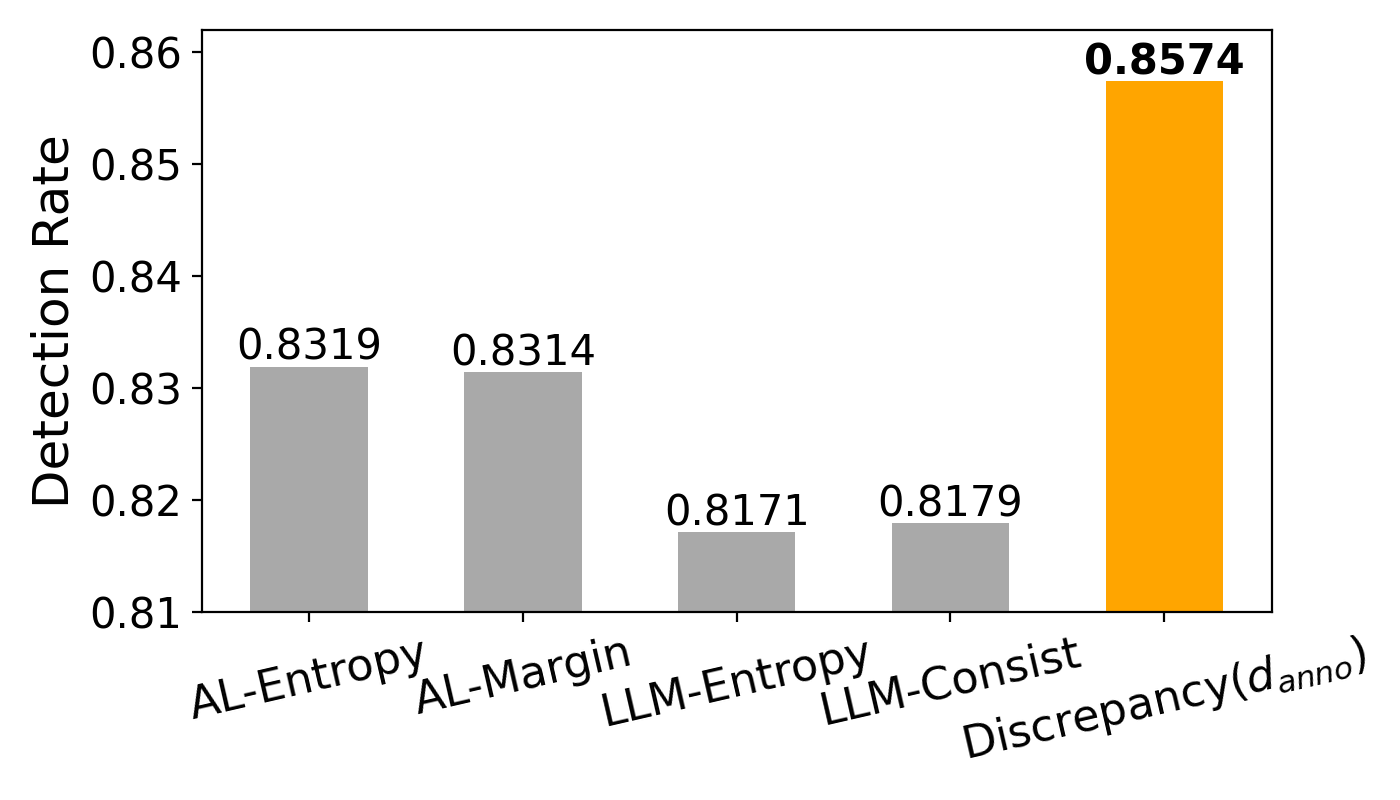
Экспериментальные результаты, полученные на датасетах AG News, IMDB, TREC и PubMed, демонстрируют эффективность MoLLIA в снижении затрат на аннотацию при сохранении высокой производительности. В частности, MoLLIA показывает наивысший процент верно определенных случаев расхождений в аннотациях среди сравниваемых методов оценки неопределенности, превосходя подходы, основанные на энтропии, отступе (margin) и согласованности. Это указывает на более точную идентификацию сложных для аннотаторов примеров, что позволяет целенаправленно улучшать качество модели при минимальных затратах на разметку данных.
За Пределами Человеческой Разметки: Будущее Самообучающейся Аннотации
Система MoLLIA демонстрирует возможность осуществления обучения с активной разметкой без участия человека, что открывает перспективы для создания полностью автоматизированных конвейеров разметки данных. Традиционно, подготовка обучающих данных для моделей обработки естественного языка требует значительных трудозатрат на ручную разметку, что является узким местом и ограничивает масштабируемость. MoLLIA, используя комбинацию нескольких больших языковых моделей и стратегические запросы, способна самостоятельно выбирать наиболее информативные примеры для разметки и оценивать их достоверность. Такой подход не только значительно снижает зависимость от ручного труда, но и позволяет существенно сократить затраты на создание высококачественных обучающих данных, тем самым ускоряя разработку и внедрение новых NLP-приложений.
Система MoLLIA демонстрирует впечатляющую способность к автоматической аннотации данных, приближающуюся по качеству к результатам, полученным при участии человека, но при значительно меньших затратах. В основе этого подхода лежит использование нескольких больших языковых моделей (LLM) и тщательно разработанной стратегии запросов, позволяющей выявлять и исправлять неточности. Вместо традиционного подхода, полагающегося на ручную разметку, MoLLIA активно использует сильные стороны различных LLM, комбинируя их ответы и оценивая степень согласия между ними. Это позволяет не только снизить потребность в дорогостоящей ручной работе, но и повысить надежность и объективность полученных аннотаций, открывая новые возможности для развития и внедрения моделей обработки естественного языка в широком спектре приложений.
В основе системы MoLLIA лежит инновационный подход к оценке надёжности аннотаций, использующий расхождение между результатами, полученными различными большими языковыми моделями. Вместо слепого доверия к единому источнику, система выявляет аннотации, по которым наблюдается существенное несогласие между моделями, рассматривая это как сигнал потенциальной ошибки или неоднозначности. Такой механизм позволяет отфильтровывать ненадёжные данные и повышать качество обучающих выборок, поскольку акцент делается на аннотациях, в которых модели демонстрируют консенсус. Использование расхождения в качестве индикатора позволило значительно улучшить производительность моделей, обученных с использованием системы MoLLIA, и обеспечить более точные и надёжные результаты в задачах обработки естественного языка.
Исследования, проведенные с использованием метода абляции, продемонстрировали существенное повышение эффективности системы MoLLIA благодаря применению негативного обучения. Этот подход позволяет модели не только усваивать правильные ответы, но и активно распознавать и избегать ошибок, что значительно улучшает качество получаемых данных для обучения. Особенно важным является потенциал этой технологии в демократизации доступа к высококачественным моделям обработки естественного языка. Снижение зависимости от дорогостоящей ручной разметки данных открывает возможности для более широкого круга исследователей и разработчиков, позволяя создавать и внедрять инновационные приложения в различных областях, от автоматического анализа текстов до создания интеллектуальных чат-ботов и систем машинного перевода.
Предложенная работа демонстрирует стремление к элегантности в решении задачи активного обучения. Вместо традиционного подхода с привлечением людей, авторы предлагают замену в виде смеси больших языковых моделей. Это отражает понимание того, что сложная система требует простого и эффективного решения. Как однажды заметил Кен Томпсон: «Простота масштабируется, изощрённость — нет». Модель MoLLIA, разработанная в статье, стремится к этой простоте, предлагая экономически эффективный и надёжный метод обучения, способный адаптироваться к проблемам, связанным с неточными метками и расхождениями в аннотациях. Это подтверждает идею о том, что хорошая архитектура незаметна, пока не столкнётся с реальными сложностями.
Что дальше?
Представленная работа, заменяя человека ансамблем больших языковых моделей, безусловно, элегантна в своей простоте. Однако, стоит помнить: модульность сама по себе не гарантирует надежности. Если система полагается на «костыли» для согласования различных моделей, это говорит о том, что мы усложнили задачу, а не решили её. Акцент на снижении стоимости разметки, конечно, важен, но истинная проблема заключается не в цене, а в качестве и непротиворечивости данных.
Очевидным направлением дальнейших исследований представляется не просто увеличение числа моделей в ансамбле, а более глубокое понимание их взаимодействий. Как обеспечить когерентность в условиях, когда каждая модель, по сути, представляет собой субъективную интерпретацию? Проблема «зашумленных» меток, хоть и смягчается предложенными методами, всё же остается актуальной. Необходимо исследовать более устойчивые к ошибкам алгоритмы обучения, которые не требуют идеальной разметки.
В конечном итоге, настоящая цель состоит не в замене человека машиной, а в создании симбиотической системы. Предложенный подход — лишь первый шаг. Необходимо искать способы интеграции человеческого опыта и машинной мощности, чтобы получить не просто более дешевую, но и более разумную систему обучения. Иначе, мы рискуем создать иллюзию контроля над сложной реальностью.
Оригинал статьи: https://arxiv.org/pdf/2601.15773.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Искусственный интеллект: хрупкость визуального мышления
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Моделирование биомолекул: новый импульс от нейросетей
- Мгновенная расшифровка: Voxtral Realtime на службе у скорости
- Математический интеллект: как улучшить навыки решения задач у больших языковых моделей
2026-01-25 01:11