Автор: Денис Аветисян
В статье представлена библиотека FlexLLM, позволяющая создавать настраиваемые и эффективные аппаратные ускорители для обработки больших языковых моделей.

FlexLLM — это компонуемая HLS-библиотека для разработки гибких гибридных ускорителей, обеспечивающая производительность, сопоставимую или превосходящую GPU, при повышенной энергоэффективности и поддержке обработки длинных контекстов.
Постоянно растущие вычислительные потребности больших языковых моделей (LLM) создают серьезные проблемы для существующих аппаратных решений. В данной работе представлена библиотека FlexLLM: Composable HLS Library for Flexible Hybrid LLM Accelerator Design, предназначенная для ускорения LLM посредством компонуемых библиотек высокоуровневого синтеза (HLS). Разработанный подход позволяет создавать гибридные архитектуры с оптимизированной квантизацией и поддержкой обработки длинных контекстов, демонстрируя значительное повышение производительности и энергоэффективности по сравнению с GPU. Каковы перспективы дальнейшей оптимизации и адаптации FlexLLM для поддержки новых поколений LLM и задач искусственного интеллекта?
Разрушая Границы: Взгляд на Большие Языковые Модели
Большие языковые модели (БЯМ) демонстрируют впечатляющие успехи, открывая новые возможности в различных областях. От автоматического перевода и генерации текста до создания чат-ботов и помощи в программировании, БЯМ преобразуют способы взаимодействия человека с информацией и технологиями. Их способность понимать и генерировать связный и релевантный текст позволила добиться прорывов в обработке естественного языка, значительно превзойдя предыдущие поколения систем искусственного интеллекта. В частности, модели, такие как GPT-3 и LaMDA, продемонстрировали удивительную способность решать сложные задачи, требующие креативности и логического мышления, что делает их ценным инструментом для исследователей и разработчиков в самых разных областях — от медицины и образования до финансов и развлечений.
Масштабирование больших языковых моделей (LLM) для решения все более сложных задач сталкивается со значительными вычислительными и аппаратными ограничениями. По мере увеличения размера моделей и объемов обрабатываемых данных, требования к памяти и пропускной способности существенно возрастают, что приводит к экспоненциальному росту затрат на обучение и развертывание. Ограниченность доступных ресурсов, таких как графические процессоры (GPU) и оперативная память, становится узким местом, препятствующим дальнейшему улучшению производительности и расширению возможностей LLM. Более того, хранение и обработка огромных параметров модели требует разработки новых методов сжатия и квантования, которые не приводят к существенной потере точности. Таким образом, преодоление этих вычислительных и аппаратных вызовов является ключевым фактором для реализации всего потенциала больших языковых моделей и обеспечения их широкого применения в различных областях.
Традиционные архитектуры, такие как трансформеры, демонстрируют ограничения при обработке длинных последовательностей данных и решении сложных задач логического вывода. Хотя трансформеры и стали основой для многих современных больших языковых моделей, их вычислительная сложность растет квадратично с увеличением длины входной последовательности, что делает обработку длинных текстов крайне ресурсоемкой. Это связано с механизмом внимания, который требует вычисления взаимодействия между каждой парой токенов во входной последовательности. В результате, модели испытывают трудности с удержанием информации на больших расстояниях и эффективным выполнением задач, требующих сложного анализа контекста и многоступенчатых умозаключений. Поэтому, исследователи активно ищут альтернативные подходы, направленные на снижение вычислительной сложности и повышение способности моделей к логическому мышлению.
Ограничения современных больших языковых моделей (LLM) стимулируют активный поиск инновационных стратегий совместной разработки аппаратного и программного обеспечения, направленных на ускорение процесса инференса. Исследователи и инженеры сосредоточены на создании специализированных архитектур, которые могут эффективно обрабатывать огромные объемы данных и сложные вычисления, необходимые для LLM. Это включает в себя разработку новых типов чипов, оптимизированных для матричных операций, используемых в глубоком обучении, а также совершенствование алгоритмов и программных фреймворков для более эффективного использования аппаратных ресурсов. В частности, изучаются подходы к квантованию, разрежению и дистилляции моделей, позволяющие уменьшить их размер и вычислительную сложность без существенной потери точности. Успешное внедрение этих стратегий позволит значительно снизить задержки и энергопотребление, связанные с инференсом LLM, открывая новые возможности для их применения в различных областях, от обработки естественного языка до компьютерного зрения и робототехники.
Специализированные Ускорители: Путь к Эффективности
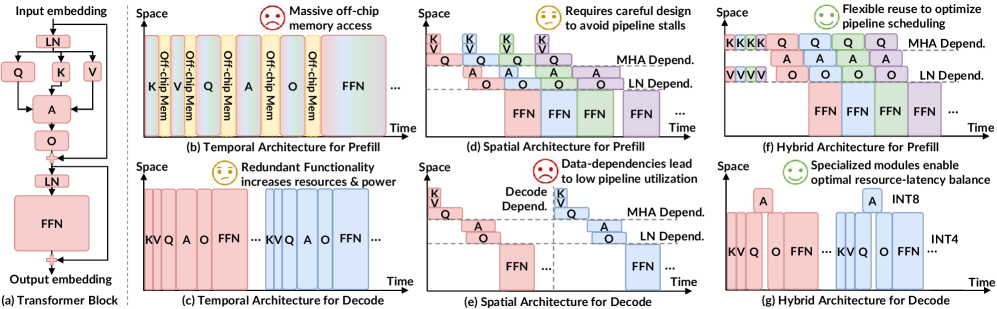
Специализированные ускорители, разработанные для конкретных задач, представляют собой перспективную альтернативу универсальным графическим процессорам (GPU) для выполнения логического вывода больших языковых моделей (LLM). В отличие от GPU, оптимизированных для широкого спектра вычислений, эти ускорители демонстрируют более высокую производительность и энергоэффективность при обработке LLM. Это достигается за счет архитектурных решений, направленных на максимальное использование параллелизма, минимизацию доступа к памяти и снижение вычислительных затрат, специфичных для LLM.
Специализированные ускорители для больших языковых моделей (LLM) используют архитектурные оптимизации, направленные на эффективную обработку специфических характеристик LLM-нагрузок. Ключевым аспектом является максимальное использование параллелизма, достигаемое за счет распараллеливания матричных операций и распределения вычислений между несколькими вычислительными блоками. Одновременно с этим, значительные усилия направлены на минимизацию обращений к памяти, что достигается за счет оптимизации размещения данных, использования локальной памяти и применения техник сжатия весов. Эффективное управление памятью и снижение задержек при доступе к ней критически важны для повышения пропускной способности и снижения энергопотребления при выводе LLM.
В архитектуре специализированных ускорителей для больших языковых моделей (LLM) ключевым принципом является настройка различных этапов (слоев) вычислений независимо друг от друга. Это позволяет оптимизировать каждый этап под конкретные вычислительные требования и характеристики, присущие данному слою LLM. Например, слои, требующие высокой степени параллелизма, могут быть реализованы с использованием большого количества вычислительных блоков, в то время как слои, требующие высокой точности, могут использовать более сложные арифметические операции. Такой подход позволяет значительно повысить общую производительность и энергоэффективность по сравнению с универсальными архитектурами, где все слои обрабатываются одинаково.
Гибридные архитектуры, сочетающие временное повторное использование данных (temporal reuse) и пространственный параллелизм, являются критически важными для достижения высокой пропускной способности и низкой задержки при ускорении LLM-inference. Временное повторное использование подразумевает многократное использование одних и тех же данных в различных вычислениях, снижая потребность в постоянном доступе к памяти. Пространственный параллелизм, напротив, позволяет выполнять несколько операций одновременно, используя различные вычислительные блоки. Эффективная реализация требует тщательного баланса между этими двумя подходами для максимизации использования ресурсов и минимизации накладных расходов, связанных с передачей данных между вычислительными элементами и памятью. Комбинация этих техник позволяет существенно увеличить скорость обработки запросов и снизить энергопотребление по сравнению с традиционными подходами.

FlexLLM: Конструирование Будущего Ускорения LLM
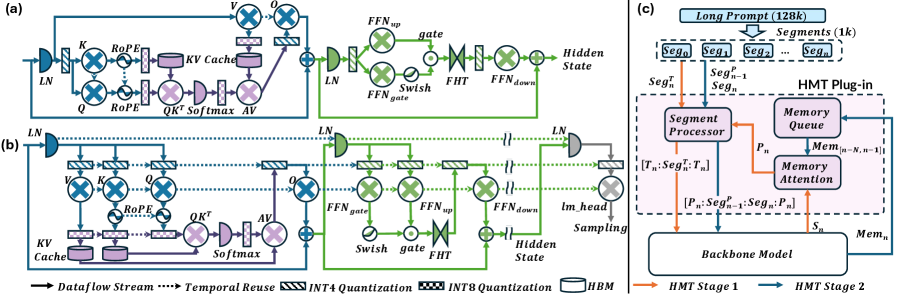
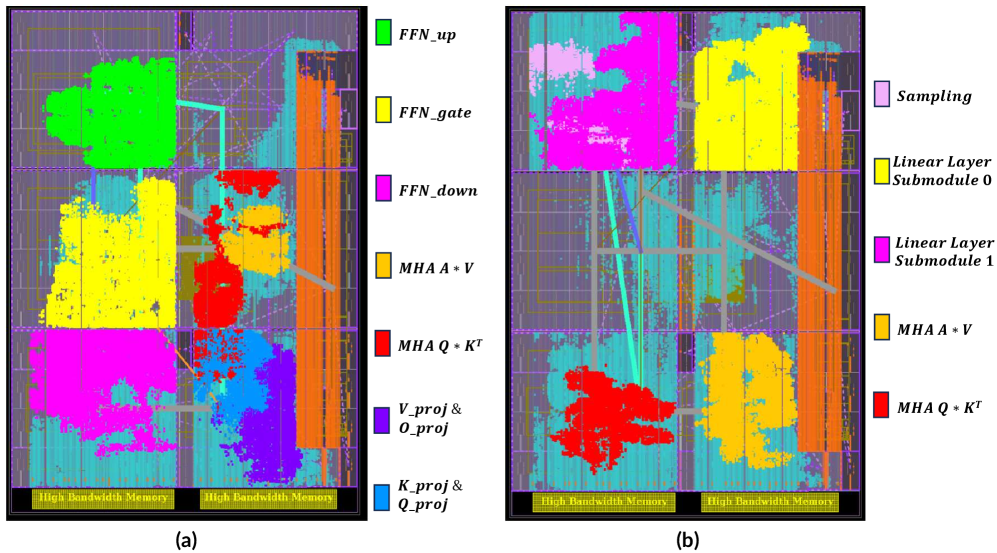
FlexLLM представляет собой компонуемую библиотеку высокоуровневого синтеза (HLS), предназначенную для упрощения разработки специализированных аппаратных ускорителей для больших языковых моделей (LLM). Компонуемость библиотеки позволяет разработчикам собирать и настраивать отдельные модули для создания архитектур, оптимизированных под конкретные задачи и ограничения. Это достигается за счет предоставления набора переиспользуемых компонентов, которые могут быть объединены для реализации различных аспектов LLM, таких как матричные операции, обработка внимания и управление памятью. Такой подход значительно сокращает время разработки и позволяет адаптировать ускорители к специфическим требованиям различных доменов применения.
FlexLLM разрабатывается на основе архитектуры TAPA (Transformer Accelerator Programming Abstraction), предоставляя набор базовых модулей и функциональных блоков, необходимых для аппаратной реализации больших языковых моделей. Данная архитектура обеспечивает абстракцию от низкоуровневых деталей аппаратного обеспечения, позволяя разработчикам сосредоточиться на оптимизации алгоритмов и построении специализированных ускорителей. Ключевые модули включают в себя компоненты для обработки внимания, матричных умножений и других вычислительно интенсивных операций, необходимых для эффективного выполнения LLM. Использование TAPA в качестве основы позволяет FlexLLM поддерживать различные аппаратные платформы и упрощает процесс портирования и масштабирования разработанных решений.
Библиотека FlexLLM включает в себя архитектурные оптимизации, в частности, иерархический трансформатор памяти (Hierarchical Memory Transformer) для обработки длинных контекстов. Данная оптимизация позволяет эффективно управлять и обрабатывать большие объемы данных, характерные для задач обработки естественного языка с длинными последовательностями. Иерархический подход подразумевает организацию памяти и вычислений в несколько уровней, что снижает требования к пропускной способности памяти и повышает скорость обработки за счет локализации данных и вычислений. Это особенно важно для моделей, работающих с большими объемами текста, такими как длинные документы или диалоги, где стандартные методы обработки могут стать узким местом.
FlexLLM использует высокоуровневые фреймворки синтеза (HLS) StreamTensor и Allo для преобразования алгоритмов в аппаратные реализации, что обеспечивает быструю разработку прототипов и развертывание. В ходе тестирования было достигнуто увеличение скорости декодирования до 6.55x и общее ускорение работы системы в 4.71x по сравнению с графическим процессором NVIDIA A100. Использование HLS позволяет автоматизировать процесс оптимизации и генерации аппаратного кода, значительно сокращая время разработки специализированных ускорителей для больших языковых моделей.
Точность и Эффективность: Квантизация и Обработка Выбросов
Квантизация является важнейшей техникой для снижения вычислительной и памяти, необходимой для больших языковых моделей (LLM). Она заключается в представлении весов и активаций модели с использованием меньшего количества битов, чем стандартные 32-битные числа с плавающей точкой. Например, переход от FP32 к INT8 позволяет уменьшить размер модели в четыре раза и значительно ускорить вычисления, особенно на специализированном оборудовании. Это достигается за счет уменьшения точности представления чисел, что может привести к незначительным потерям в точности модели, однако позволяет развертывать LLM на устройствах с ограниченными ресурсами и снизить затраты на хранение и передачу данных. Различные методы квантизации, такие как постобработочная, квантизация во время обучения и динамическая квантизация, предлагают разные компромиссы между точностью и производительностью.
Существуют различные методы квантизации, каждый из которых характеризуется компромиссом между точностью и производительностью. Статическая квантизация (Static Quantization) предполагает предварительное определение диапазонов значений для активаций и весов во время обучения или калибровки, что обеспечивает высокую скорость работы, но может приводить к значительной потере точности. Динамическая квантизация (Dynamic Quantization) выполняет квантизацию “на лету” во время инференса, используя динамически вычисляемые диапазоны, что обеспечивает лучшую точность по сравнению со статической квантизацией, но требует дополнительных вычислительных ресурсов. GPTQ (Generative Post-training Quantization) представляет собой метод постобработочной квантизации, направленный на минимизацию потерь точности за счет оптимизации матриц весов, что позволяет достичь высокой степени сжатия при относительно небольшом снижении производительности. Выбор конкретного метода квантизации зависит от требований к точности, скорости инференса и доступным вычислительным ресурсам.
Агрессивное квантование, подразумевающее значительное снижение разрядности весов и активаций больших языковых моделей, часто приводит к ухудшению точности. Это особенно заметно при наличии выбросов в данных, поскольку квантование усекает значения, что может привести к существенным ошибкам в представлении редких, но важных признаков. Выбросы, как правило, содержат информацию, критичную для правильной работы модели, и их потеря при квантовании непропорционально влияет на конечный результат, снижая общую производительность и надежность системы. Степень ухудшения точности напрямую зависит от степени квантования и доли выбросов в обучающей выборке.
Эффективное управление выбросами является критически важным для сохранения точности моделей при квантовании. Методы, такие как вращение активаций (Activation Rotation) и быстрое преобразование Адамара (Fast Hadamard Transform), позволяют снизить влияние экстремальных значений на процесс квантования. Вращение активаций изменяет распределение данных, уменьшая вероятность появления больших значений, в то время как быстрое преобразование Адамара преобразует данные в пространство, где выбросы менее выражены. Применение этих техник позволяет снизить потери точности, возникающие при переходе к более низкоточным форматам представления чисел, и обеспечить стабильную работу модели после квантования.
Взгляд в Будущее: Эффективность и Масштабируемость LLM
Сочетание специализированного аппаратного обеспечения, оптимизированных архитектур и техник оптимизации точности представляет собой ключевой фактор для раскрытия полного потенциала больших языковых моделей (LLM). Вместо универсальных вычислительных решений, разработка аппаратных платформ, адаптированных под специфические требования LLM, позволяет значительно повысить эффективность и снизить энергопотребление. Одновременно с этим, совершенствование архитектуры самих моделей, например, за счет квантизации весов или применения разреженных матриц, позволяет добиться существенного ускорения вычислений без значительной потери точности. Совместное применение этих подходов открывает возможности для развертывания LLM в новых областях, требующих высокой производительности и ограниченных ресурсов, таких как мобильные устройства и периферийные вычисления, что стимулирует дальнейшие инновации и расширяет сферу применения этих мощных инструментов.
Ускорители на базе ПЛИС (FPGA) становятся ключевым элементом развертывания больших языковых моделей (LLM) непосредственно на периферии сети, благодаря уникальному сочетанию гибкости и энергоэффективности. В отличие от специализированных аппаратных решений, ПЛИС позволяют динамически адаптировать архитектуру под конкретные требования модели и задачи, оптимизируя производительность и снижая энергопотребление. Это особенно важно для приложений, работающих в условиях ограниченных ресурсов, таких как мобильные устройства или автономные системы. Возможность программирования аппаратной логики позволяет добиться значительных улучшений в скорости обработки и уменьшить задержки, что критично для задач, требующих отклика в реальном времени, например, мгновенного перевода или работы персональных ассистентов. Таким образом, ПЛИС открывают новые перспективы для широкого внедрения LLM в разнообразные сферы применения, где важны не только вычислительные мощности, но и энергоэффективность и возможность адаптации к меняющимся требованиям.
Появление высокоэффективных ускорителей больших языковых моделей (LLM) открывает двери для принципиально новых приложений. В частности, становится возможным создание систем мгновенного перевода, способных обрабатывать речь в режиме реального времени, а также персональных ассистентов, адаптирующихся к индивидуальным потребностям пользователя с беспрецедентной скоростью. Автономные системы, от роботов-помощников до беспилотных транспортных средств, также получат значительный импульс, благодаря снижению задержек и повышению энергоэффективности. Так, платформа Versal V80, использующая FlexLLM, демонстрирует в 3.14 раза более высокую энергоэффективность по сравнению с GPU A100 и сокращение времени предварительной обработки (prefill latency) в 23.23 раза при использовании плагина HMT, что существенно расширяет горизонты применения LLM в самых разных областях.
Непрерывные исследования и разработки в области аппаратного ускорения, оптимизации архитектур и снижения точности вычислений обещают дальнейший прогресс в использовании больших языковых моделей (LLM) в различных отраслях. Ожидается, что совершенствование этих технологий позволит преодолеть текущие ограничения, связанные с вычислительными затратами и энергопотреблением, открывая новые возможности для внедрения LLM в такие сферы, как здравоохранение, финансы и транспорт. Повышение эффективности и масштабируемости LLM не только расширит спектр доступных приложений, включая системы реального времени и автономные устройства, но и сделает их более доступными для широкого круга пользователей и организаций, стимулируя инновации и экономический рост.

Исследование демонстрирует, что гибкость архитектуры является ключевым фактором в оптимизации производительности LLM-ускорителей. Подход, предложенный в статье, позволяет создавать специализированные аппаратные решения, адаптированные к конкретным задачам и моделям. Это напоминает о словах Барбары Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не влияли на другие». FlexLLM, подобно тщательно спроектированной системе, обеспечивает модульность и композиционность, позволяя разработчикам легко заменять и обновлять компоненты, не нарушая целостность всей структуры. Возможность поддержки обработки длинного контекста, реализованная в данной работе, подчеркивает важность адаптивности и масштабируемости современных аппаратных решений.
Куда двигаться дальше?
Представленная работа, демонстрируя возможность конструирования специализированных ускорителей для больших языковых моделей на базе FPGA, лишь приоткрывает дверь в лабиринт нерешенных задач. Очевидно, что текущие подходы к квантованию и оптимизации требуют дальнейшей ревизии. Простое уменьшение разрядности не всегда ведет к желаемому результату; необходимо понимать, какие биты информации действительно критичны для сохранения точности, а какие можно безболезненно отбросить. Эта задача, по сути, представляет собой обратную задачу — реконструирование смысла из фрагментированных данных.
Особенно интересным представляется вопрос о масштабируемости. Создание ускорителя для обработки контекста в несколько тысяч токенов — это лишь первый шаг. Реальная задача заключается в создании систем, способных обрабатывать контекст, охватывающий целые книги или даже базы данных. Потребуется не просто увеличение вычислительных ресурсов, но и разработка принципиально новых архитектур, способных эффективно управлять огромными объемами информации. Возможно, стоит взглянуть в сторону нетрадиционных подходов к хранению и обработке данных, вдохновленных принципами работы человеческого мозга.
Наконец, нельзя забывать о прагматической стороне вопроса. Эффективность ускорителя бесполезна, если его сложно интегрировать в существующие системы. Разработка удобных инструментов для автоматической генерации и отладки аппаратного обеспечения — это ключ к широкому распространению подобных технологий. И, конечно, всегда остается открытым вопрос: достаточно ли нам просто ускорить существующие модели, или нам нужно переосмыслить сам подход к искусственному интеллекту?
Оригинал статьи: https://arxiv.org/pdf/2601.15710.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Экзотические разложения: новые грани цилиндрической алгебры
- Командная работа агентов: обучение без обновления модели
2026-01-25 02:57