Автор: Денис Аветисян
Новый статистический подход позволяет выявлять ключевые взаимодействия между аминокислотами и предсказывать влияние мутаций на структуру и функцию белков.
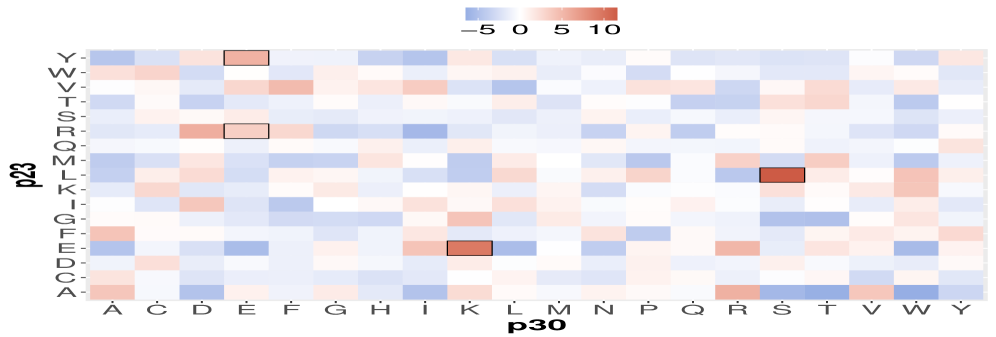
Предложенный метод CATParc использует частичную корреляцию для анализа коэволюции и точного предсказания контактов между остатками белка.
Существующие подходы к анализу мутаций белков часто полагаются на модельные предположения, ограничивая возможность оценки неопределенности предсказаний. В статье ‘Model-Free Inference for Characterizing Protein Mutations through a Coevolutionary Lens’ предложен новый статистический фреймворк, CATParc, использующий частичную корреляцию для точного предсказания контактов между аминокислотными остатками и выявления ключевых комбинаций, определяющих эти взаимодействия. Разработанный подход позволяет проводить статистический вывод без модельных ограничений, обеспечивая контроль над ложноположительными ошибками и повышая точность анализа коэволюции. Сможет ли предложенный фреймворк стать основой для более глубокого понимания влияния мутаций на структуру и функцию белков?
Раскрытие белковых тайн: вызовы предсказания мутаций
Определение влияния мутаций на функционирование белков является основополагающим для прогресса в понимании механизмов развития заболеваний и разработки новых терапевтических стратегий. Белки, будучи ключевыми участниками практически всех биологических процессов, чрезвычайно чувствительны к изменениям в своей структуре, вызванным мутациями. Даже незначительное изменение аминокислотной последовательности может привести к потере функциональности белка или, наоборот, к приобретению новых, нежелательных свойств, что часто лежит в основе развития генетических заболеваний и онкологических процессов. Поэтому точное предсказание последствий мутаций позволяет не только диагностировать заболевания на ранних стадиях, но и разрабатывать персонализированные методы лечения, направленные на коррекцию дефектных белков или компенсацию их потери, открывая перспективы для создания принципиально новых лекарственных препаратов.
Традиционные методы предсказания влияния мутаций на белки часто сталкиваются с трудностями из-за сложности моделирования внутрибелковых взаимодействий. Белки — это не просто линейные цепочки аминокислот, а сложные трехмерные структуры, где каждая аминокислота влияет на другие, определяя функциональность. Старые подходы, как правило, упрощают эти взаимодействия, рассматривая белок как набор отдельных частей, что приводит к неточным прогнозам. Особенно проблематичны слабые взаимодействия, такие как ван-дер-ваальсовы силы и водородные связи, которые хоть и невелики по отдельности, но в совокупности существенно влияют на стабильность и функцию белка. Игнорирование этих нюансов приводит к тому, что предсказания о влиянии мутаций на изменение активности, связывания с другими молекулами или даже на сворачивание белка оказываются ненадежными, что затрудняет понимание механизмов заболеваний и разработку эффективных терапевтических стратегий.
CATParc: новый подход к анализу белковых взаимодействий
CATParc — это фреймворк, не требующий предварительного построения моделей, для анализа взаимодействий между аминокислотами. В основе метода лежит вычисление частичной корреляции, позволяющей выявлять прямые связи между остатками белка, исключая влияние косвенных факторов и конфаундеров. В отличие от методов, требующих априорных знаний о структуре или функциях белка, CATParc использует только данные о множественной последовательности выравнивания (MSA) для оценки статистической зависимости между аминокислотами. Это позволяет выявлять функционально значимые взаимодействия, которые могут быть не очевидны при анализе только ковариаций.
В рамках CATParc, необработанные данные множественного выравнивания последовательностей (MSA Data) подвергаются преобразованию посредством One-Hot кодирования. Этот процесс заключается в представлении каждого аминокислотного остатка в виде бинарного вектора, где каждый элемент вектора соответствует конкретной аминокислоте из стандартного набора. В результате, каждый остаток кодируется как вектор, в котором только один элемент равен 1 (обозначающий присутствие данной аминокислоты), а остальные равны 0. Такое представление позволяет преобразовать категориальные данные MSA в числовой формат, пригодный для статистического анализа и последующего вычисления парных корреляций.
В основе CATParc лежит метод частичной корреляции, позволяющий выявлять прямые связи между аминокислотными остатками, контролируя влияние сопутствующих факторов. В отличие от простой корреляции, которая может указывать на связь из-за общего влияния третьей переменной, частичная корреляция изолирует взаимосвязь между двумя остатками, исключая вклад всех остальных. Это достигается путем вычисления корреляции между двумя остатками при условии, что все остальные переменные остаются постоянными. Математически, частичная корреляция r_{xy \cdot z} между переменными x и y при контроле переменной z вычисляется на основе ковариаций и дисперсий, что позволяет более точно определить прямые функциональные взаимодействия между аминокислотами в анализируемой белковой последовательности.
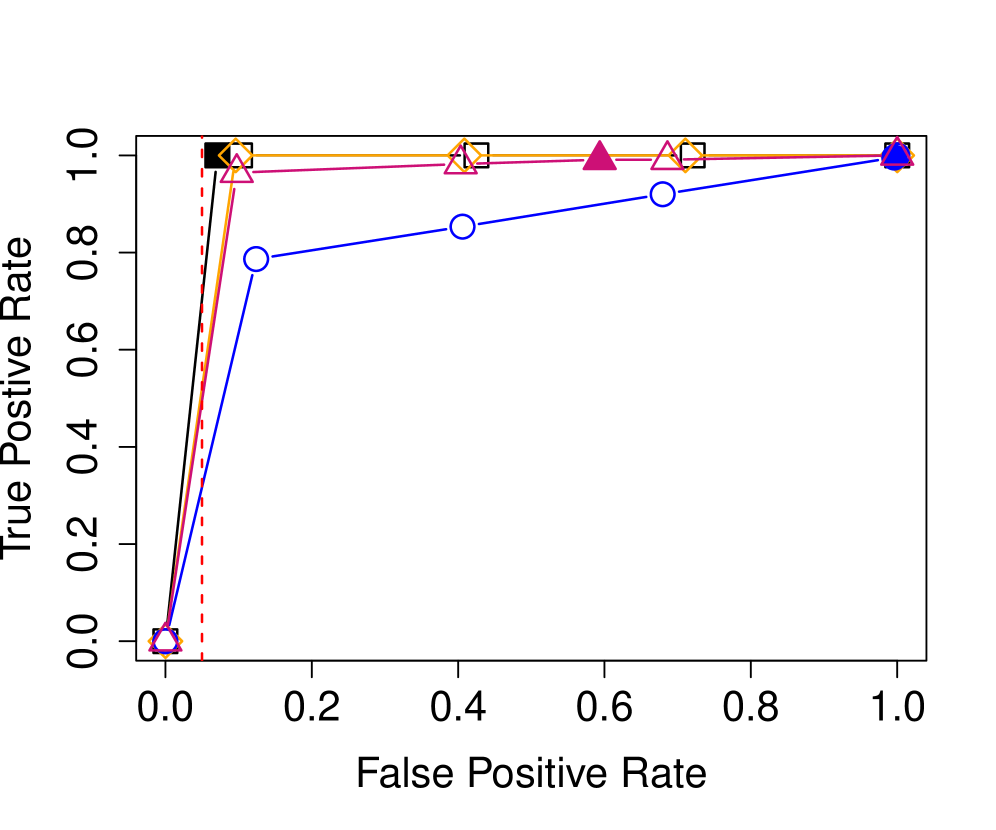
Проверка точности CATParc: от корреляций к предсказаниям
В основе работы CATParc лежит Спектральный тест, используемый для оценки статистической значимости предсказанных контактов между аминокислотными остатками. Данный тест анализирует спектр ковариаций между остатками, определяя, насколько вероятно, что наблюдаемая ковариация возникла случайно. В отличие от традиционных методов, Спектральный тест позволяет более точно определить истинные контакты, минимизируя количество ложноположительных результатов. Принцип работы заключается в построении матрицы ковариаций на основе множественных последовательностей гомологичных белков и последующем применении статистических критериев для выявления значимых ковариаций, указывающих на физическое взаимодействие между остатками.
Метод CATParc обеспечивает точное предсказание контактов между аминокислотными остатками, демонстрируя превосходную производительность в различных семействах белков. Оценка точности предсказаний осуществляется с использованием метрики AUC (Area Under the Curve), которая позволяет количественно оценить способность метода различать истинные контакты от случайных. Результаты показывают, что CATParc превосходит существующие методы в предсказании контактов, что подтверждается более высокими значениями AUC для различных протеиновых семейств и, следовательно, более надежным определением структуры белка.
В CATParc для повышения точности отбора переменных и устойчивости модели используется регуляризация Group Lasso. Этот метод позволяет контролировать количество ложноположительных результатов (Type I error) более эффективно, чем в существующих подходах. Group Lasso осуществляет совместное сокращение (shrinkage) групп коррелированных признаков, что особенно важно при анализе данных о контактах аминокислотных остатков, где соседние остатки часто демонстрируют высокую степень корреляции. В результате применения Group Lasso в CATParc достигается более надежная и интерпретируемая модель предсказания контактов, с уменьшением вероятности ошибочного определения взаимодействий между остатками.
Раскрытие функционального воздействия и эволюционных идей
В основе работы CATParc лежит способность выявлять критически важные комбинации аминокислот, определяющие функциональность белков. Вместо анализа отдельных аминокислот, система фокусируется на взаимодействиях между ними, позволяя обнаружить паттерны, которые напрямую влияют на способность белка выполнять свою роль. Такой подход позволяет установить, какие конкретно пары или группы аминокислот являются ключевыми для поддержания структуры белка, связывания с другими молекулами или каталитической активности. Идентифицируя эти комбинации, CATParc предоставляет ценную информацию о механизмах функционирования белков и позволяет предсказывать, как изменения в аминокислотной последовательности могут повлиять на их работу, открывая новые возможности для изучения и разработки лекарственных препаратов.
В основе CATParc лежит применение самонормализованной частичной корреляции, что позволяет существенно повысить точность и стабильность анализа взаимодействий между аминокислотами в белках. Традиционные методы корреляционного анализа часто сталкиваются с проблемой ложных связей и нестабильностью результатов при работе с большими объемами данных. Самонормализация, в свою очередь, позволяет учесть индивидуальные характеристики каждого аминокислотного остатка и снизить влияние шумовых факторов. Это приводит к более надежной идентификации действительно значимых взаимодействий, определяющих функциональные свойства белка. Использование данного подхода в CATParc обеспечивает не только повышение точности предсказаний, но и устойчивость результатов к изменениям в данных, что особенно важно при анализе сложных биологических систем.
Исследование демонстрирует, что разработанная платформа CATParc значительно повышает точность предсказания влияния мутаций на функционирование белков. Интеграция CATParc с существующими методами эволюционного моделирования (ESM) позволила достичь улучшения в 3% при оценке эффектов мутаций, что подтверждается высоким значением коэффициента корреляции Спирмена, равным 0.85. Этот результат указывает на способность платформы более надежно прогнозировать, как изменения в аминокислотной последовательности белка повлияют на его функциональные свойства, открывая новые возможности для понимания механизмов болезней и разработки новых лекарственных препаратов. Подобная точность имеет критическое значение для изучения влияния генетических вариаций и прогнозирования последствий мутаций в различных биологических системах.
Представленная работа демонстрирует изящный подход к анализу сложных взаимосвязей в белках, избегая жёстких рамок предопределённых моделей. Вместо этого, CATParc опирается на частичную корреляцию, позволяя выявить контакты между аминокислотными остатками непосредственно из данных. Это особенно ценно, поскольку, как однажды заметил Ричард Фейнман: «Если вы не можете объяснить что-то простым способом, значит, вы сами этого не понимаете». Иными словами, истинное понимание структуры и функций белков требует отказа от излишней сложности и стремления к наиболее лаконичному и прозрачному объяснению наблюдаемых взаимодействий. Акцент на статистической значимости и критериях отбора ключевых комбинаций аминокислот, предложенный в работе, подчёркивает важность критического подхода к интерпретации результатов и избежания необоснованных выводов.
Что дальше?
Представленный подход, использующий частичную корреляцию для анализа коэволюции белков, безусловно, открывает новые возможности. Однако, не стоит забывать старую истину: любая модель — это лишь упрощение реальности. Данная работа, хоть и демонстрирует впечатляющие результаты в предсказании контактов между аминокислотными остатками, всё же оперирует с данными, которые сами по себе подвержены шуму и систематическим ошибкам. Воспроизводимость полученных результатов на независимых наборах данных представляется критически важной проверкой, а не просто формальностью.
Перспективным направлением представляется расширение фреймворка CATParc для работы с данными, полученными из различных экспериментальных источников. Интеграция информации о структурной пластичности белков, влиянии посттрансляционных модификаций и эффектах, обусловленных окружающей средой, может значительно повысить точность предсказаний. При этом, необходимо помнить, что корреляция не подразумевает причинно-следственную связь, и простое увеличение объёма данных не всегда приводит к более глубокому пониманию биологических процессов.
В конечном счете, успех этого направления исследований будет зависеть не столько от сложности используемых алгоритмов, сколько от строгости проверки гипотез и готовности признавать ошибки. Если результат не воспроизводится, значит, это анекдот, а не наука. Истинное понимание механизмов мутационного эффекта требует не только вычислительных инструментов, но и критического осмысления полученных данных.
Оригинал статьи: https://arxiv.org/pdf/2601.15566.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Математический интеллект: как улучшить навыки решения задач у больших языковых моделей
2026-01-25 06:15