Автор: Денис Аветисян
В статье представлен инновационный метод обеспечения доверия к результатам, генерируемым масштабными нейронными сетями, за счет криптографической проверки их свойств.
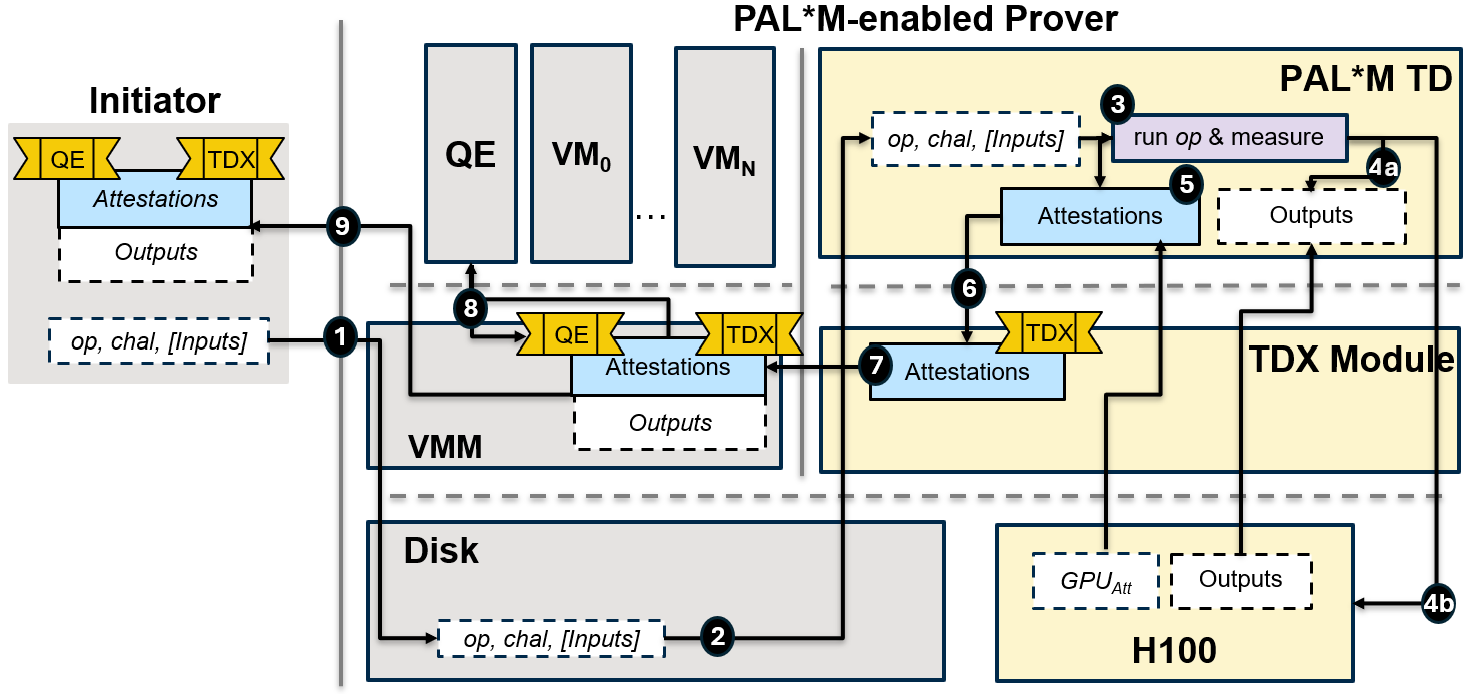
Предложенная система PAL*M использует доверенные среды исполнения и мультисетное хеширование для аттестации целостности данных и масштабируемости вычислений.
В условиях растущей значимости больших генеративных моделей, таких как языковые модели, обеспечение их надежности и соответствия требованиям безопасности становится критически важной задачей. В данной работе представлена система PAL*M: Property Attestation for Large Generative Models — фреймворк, использующий доверенные среды исполнения и мультисетовое хеширование для верифицируемого подтверждения свойств больших генеративных моделей. Предложенное решение позволяет эффективно отслеживать целостность данных и обеспечивать масштабируемость вычислений, что особенно важно для современных LLM. Каким образом подобные системы могут способствовать построению более прозрачных и ответственных решений в области машинного обучения?
Нарастающие риски: целостность данных в эпоху больших языковых моделей
В настоящее время наблюдается стремительное расширение сферы применения больших языковых моделей (LLM) в критически важных областях, таких как здравоохранение, финансы и правовая экспертиза. Это повсеместное внедрение обуславливает исключительную важность обеспечения целостности данных, которые используются для обучения и функционирования этих систем. Любое искажение или компрометация исходной информации может привести к серьезным последствиям, включая принятие ошибочных решений, финансовые потери и даже угрозу безопасности. Таким образом, поддержание высокой степени достоверности данных становится не просто технической задачей, а фундаментальным требованием для надежной и ответственной работы LLM в современном мире.
Традиционные методы проверки целостности данных, такие как проверка контрольных сумм или соответствие формату, оказываются недостаточными при работе с большими языковыми моделями (LLM). Объём и сложность данных, обрабатываемых LLM, значительно превосходят возможности этих подходов. Модели способны генерировать и интерпретировать данные в разнообразных форматах, включая текст, код и изображения, что требует новых методов валидации, способных учитывать семантическое значение и контекст. Простые проверки синтаксиса не могут выявить тонкие манипуляции или предвзятость, внедрённые в данные, а масштабируемость этих методов ограничена из-за вычислительных затрат, связанных с обработкой огромных объёмов информации, генерируемых LLM. Таким образом, необходимы инновационные решения, сочетающие автоматизированные методы с экспертной оценкой, для обеспечения надежности и достоверности данных, используемых в системах искусственного интеллекта.
Компрометация целостности данных представляет собой серьезную угрозу для функционирования систем, основанных на больших языковых моделях (LLM). Искаженные или неточные входные данные могут привести к формированию предвзятых результатов, воспроизводящих и усиливающих существующие социальные или статистические отклонения. Более того, нарушение целостности данных открывает двери для злоумышленников, позволяя им манипулировать LLM с целью получения несанкционированного доступа к информации или внедрения вредоносного кода. В конечном итоге, подрывая доверие к данным, поступающим в систему, и к результатам, которые она генерирует, компрометация целостности данных ставит под сомнение надежность и безопасность всего ИИ-решения, препятствуя его эффективному и ответственному применению в критически важных областях.
Аттестация свойств LLM: фундамент доверия
Аттестация свойств больших языковых моделей (LLM) представляет собой надежный механизм для проверки целостности как самой модели, так и используемых данных. Данный процесс включает в себя криптографическую верификацию, подтверждающую подлинность и неизменность LLM, а также атрибутов данных, на которых она обучалась или выполняет инференс. Это позволяет установить доверие к модели, гарантируя, что она не была модифицирована или скомпрометирована, и что входные данные соответствуют ожидаемым характеристикам. Аттестация выходит за рамки простой проверки контрольных сумм, предоставляя доказательства о состоянии модели и данных в конкретный момент времени, что критически важно для обеспечения надежности и предсказуемости LLM в различных приложениях.
В основе системы аттестации LLM лежит механизм удаленной аттестации (Remote Attestation), обеспечивающий построение цепочки доверия, начинающейся с базового аппаратного обеспечения. Этот процесс предполагает криптографическую проверку подлинности и целостности компонентов системы, начиная с загрузчика и процессора, и распространяется на все уровни программного стека. Удаленная аттестация позволяет убедиться, что LLM функционирует на доверенном оборудовании и не подвергалась несанкционированным изменениям на аппаратном уровне, что критически важно для обеспечения безопасности и надежности работы модели. Результаты аттестации, подписанные доверенной стороной, могут быть использованы для верификации подлинности LLM и подтверждения её неизменности.
Аттестация распространяется на конфигурацию языковой модели (LLM) и характеристики распределения набора данных, используемого для обучения или инференса. Это включает в себя проверку таких параметров, как архитектура модели, количество параметров, используемые веса, а также метаданные набора данных, такие как размер, источники данных, методы предобработки и статистические характеристики. Подтверждение этих атрибутов позволяет установить соответствие между используемой моделью и заявленными спецификациями, а также обеспечить воспроизводимость результатов и предсказуемость поведения LLM. Проверка целостности конфигурации и данных критически важна для предотвращения несанкционированных изменений и обеспечения надежности системы.
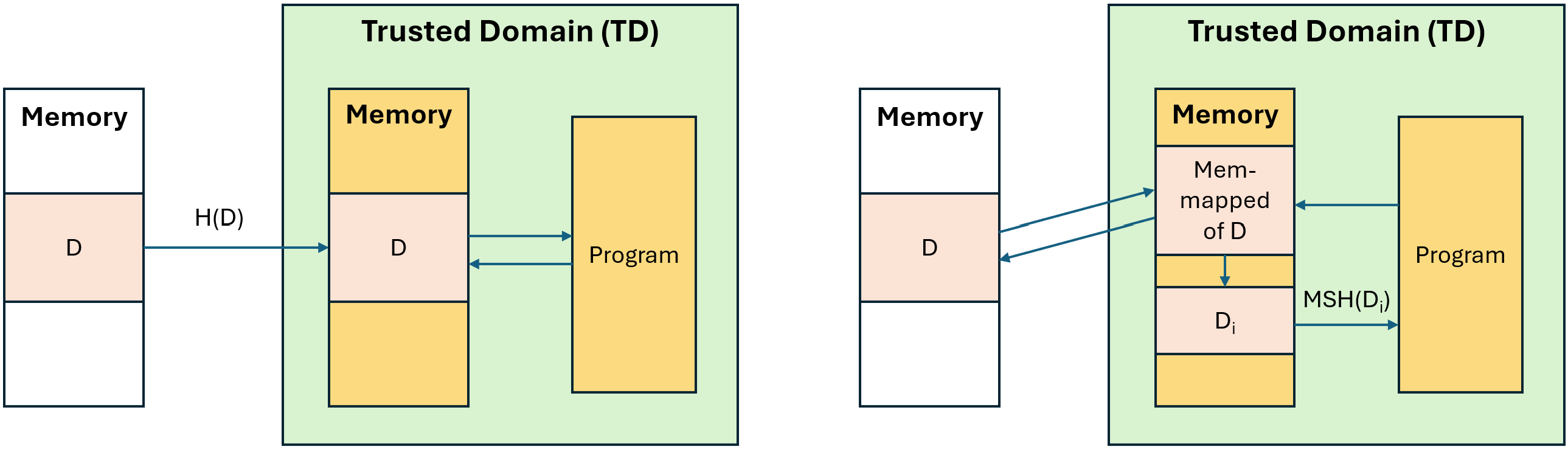
Обеспечение фундамента: аппаратная и программная целостность
Аттестация GPU является неотъемлемой частью аттестации свойств больших языковых моделей (LLM), поскольку она позволяет удостовериться в целостности и неизменности аппаратной платформы, на которой выполняется модель. Этот процесс включает в себя проверку подлинности и конфигурации графического процессора (GPU) для подтверждения, что он не подвергался несанкционированным изменениям или манипуляциям. Успешная аттестация GPU гарантирует, что LLM работает в доверенной среде, что критически важно для обеспечения достоверности результатов и защиты от потенциальных атак, направленных на компрометацию модели или кражу конфиденциальной информации. Процедуры аттестации могут включать в себя проверку прошивки, конфигурации памяти и других ключевых параметров GPU.
Эффективное отслеживание целостности больших наборов данных критически важно для обеспечения достоверности моделей машинного обучения. Инкрементальный мультисетовый хеширование (Incremental Multiset Hashing, MSH) представляет собой масштабируемое решение, позволяющее эффективно проверять целостность данных по мере их изменения. В отличие от традиционных методов хеширования, MSH позволяет вычислять хеш-сумму набора данных без необходимости повторной обработки всего объема данных при добавлении или изменении отдельных элементов. Это достигается за счет использования хеш-функций, устойчивых к коллизиям, и инкрементного обновления хеш-суммы при каждой операции над данными. Благодаря этому MSH позволяет значительно снизить вычислительные затраты и время, необходимые для проверки целостности больших наборов данных, что особенно важно для задач обучения и дообучения больших языковых моделей.
Структуры Merkle Tree дополняют Incremental Multiset Hashing (MSH), предоставляя верифицируемое суммарное представление целостности данных, что позволяет обнаруживать даже незначительные изменения. В рамках платформы PAL∗M, при использовании отображаемых в память наборов данных, достигается накладной расход всего 5.66% при формировании доказательства обучения Proof \ of \ Training . Это достигается за счет эффективного построения дерева Merkle, представляющего хеши данных, что позволяет быстро и надежно подтверждать целостность больших объемов информации, используемых в процессе обучения моделей.
В процессе доказательства тонкой настройки (Proof of Fine-tuning) с использованием метода LoRA (Low-Rank Adaptation), разработанная система демонстрирует незначительные накладные расходы, составляющие всего 1.35%. Данный показатель указывает на высокую эффективность предложенного подхода к обеспечению целостности и подтверждению происхождения модели, минимизируя влияние на производительность и вычислительные ресурсы при адаптации предварительно обученной модели к новым данным или задачам. Низкий процент накладных расходов позволяет применять данную систему в производственных средах без существенного увеличения времени обучения или потребления ресурсов.
Последствия и перспективы развития
Аттестация свойств больших языковых моделей (LLM) открывает новые возможности для повышения доверия к системам искусственного интеллекта, что особенно важно для их внедрения в критически важные сферы применения. Данный подход позволяет подтверждать соответствие LLM заданным требованиям, например, в отношении безопасности, точности или конфиденциальности данных. Подтверждение этих свойств создает основу для более уверенного использования LLM в таких областях, как здравоохранение, финансы и юридические услуги, где надежность и предсказуемость результатов имеют первостепенное значение. Повышение прозрачности и проверяемости работы LLM способствует преодолению опасений, связанных с непредсказуемым поведением моделей, и стимулирует более широкое принятие технологий искусственного интеллекта в обществе.
Предложенная система значительно повышает безопасность больших языковых моделей, эффективно снижая риски, связанные с отравлением данных и злонамеренным манипулированием моделью. Защита от отравления данных достигается путем верификации целостности входных данных и отслеживания их влияния на выходные результаты модели. Более того, система предотвращает несанкционированное изменение параметров модели, гарантируя, что модель функционирует в соответствии с заданными спецификациями и не подвержена внешнему воздействию, направленному на искажение её поведения или компрометацию результатов. Это особенно важно в приложениях, где требуется высокая степень надежности и достоверности, таких как финансовые сервисы или системы здравоохранения, где даже незначительные отклонения могут привести к серьезным последствиям.
Исследования показали, что предложенная схема аттестации свойств больших языковых моделей (LLM) демонстрирует накладные расходы в 64.34% при доказательстве корректности вычислений для модели Llama-3.1-8B. Однако, применение сессионного вывода, когда аттестация выполняется для последовательных запросов в рамках одной сессии, позволяет существенно снизить эти накладные расходы до 11.03%. Данное снижение указывает на перспективность оптимизации процесса аттестации, особенно в сценариях, где LLM взаимодействует с пользователем в режиме диалога или последовательной обработки данных, что открывает возможности для более эффективного и экономичного обеспечения доверия к искусственному интеллекту.
Предстоящие исследования направлены на полную автоматизацию процесса аттестации больших языковых моделей (LLM), что позволит существенно снизить затраты и повысить масштабируемость системы. Планируется расширить спектр проверяемых свойств LLM, включив в него не только текущие характеристики, но и такие аспекты, как устойчивость к предвзятости, способность к генерации этичного контента и корректность работы с различными типами данных — от текста и изображений до аудио и видео. Автоматизация позволит непрерывно отслеживать соответствие моделей заданным критериям на протяжении всего жизненного цикла, обеспечивая более высокий уровень доверия к искусственному интеллекту и открывая новые возможности для его применения в критически важных областях.
Исследование демонстрирует, что даже самые передовые модели, такие как LLM, нуждаются в подтверждении целостности данных и вычислений. Система PAL\M, основанная на доверенных окружениях и мультисетовых хэшах, пытается решить эту задачу, но, как показывает опыт, любое решение порождает новые сложности. Впрочем, это и не удивительно. Как однажды заметил Андрей Колмогоров: «Математики не решают задачи, они учатся понимать их». По сути, PAL\M — это попытка формализовать доверие к результатам, полученным от моделей, чья внутренняя работа остается непрозрачной. И, вероятно, через несколько лет эта архитектура станет очередным примером технического долга, требующего рефакторинга.
Что дальше?
Представленный подход, использующий доверенные среды исполнения и мультисетовое хеширование для аттестации свойств больших генеративных моделей, неизбежно столкнется с тем, что «продакшен найдёт способ сломать элегантную теорию». Аттестация — это хорошо, но кто-нибудь должен подумать о том, что произойдет, когда модель решит, что ей не нравится аттестуемая реальность. Или, что более вероятно, когда кто-нибудь обнаружит способ обойти аттестацию, чтобы получить чуть больше производительности. Если система стабильно падает, значит, она хотя бы последовательна, и эту последовательность нужно учитывать.
Проблема масштабируемости, конечно, никуда не денется. Каждая «революционная» технология завтра станет техдолгом. “Cloud-native” — это всё то же самое, только дороже. Вопрос в том, насколько быстро вырастет стоимость аттестации по сравнению с затратами на обнаружение и исправление скомпрометированных моделей. И, конечно, кто-нибудь обязательно захочет аттестовать аттестацию, создавая бесконечную рекурсию, в которой теряется всякая надежда на практическую пользу.
В конечном счете, данная работа — это ещё один шаг в направлении создания систем, которые утверждают, что они делают то, что должны. Мы не пишем код — мы просто оставляем комментарии будущим археологам. Остается надеяться, что те, кто раскопает эти комментарии, найдут в них хоть немного юмора и смирения перед лицом неизбежной энтропии.
Оригинал статьи: https://arxiv.org/pdf/2601.16199.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Квантовая механика: скрытый детерминизм?
- Моделирование биомолекул: новый импульс от нейросетей
- Командная работа агентов: обучение без обновления модели
2026-01-25 09:33