Автор: Денис Аветисян
Новый подход позволяет рекомендательным системам динамически адаптироваться к изменяющимся предпочтениям пользователей и использовать данные из разных источников.
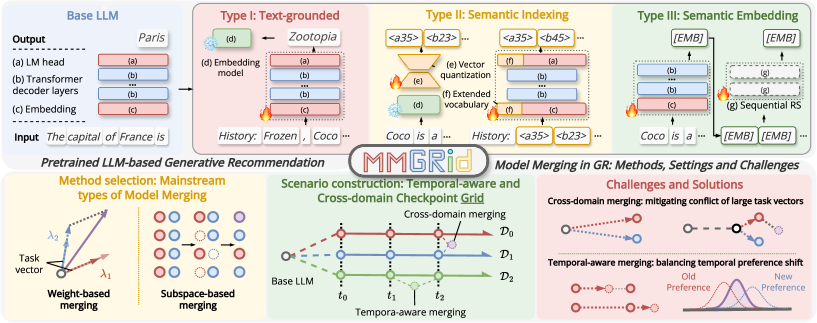
В статье представлена методика систематического изучения объединения моделей в генеративных рекомендательных системах, позволяющая балансировать исторические данные и текущие запросы пользователей для повышения точности.
Несмотря на успехи генеративных рекомендательных систем (GRS), их масштабируемость и адаптация к изменяющимся условиям остаются сложной задачей. В данной работе, ‘MMGRid: Navigating Temporal-aware and Cross-domain Generative Recommendation via Model Merging’, предложен систематический подход к объединению моделей GRS, обученных на данных различных доменов и периодов времени. Исследование выявило, что конфликты параметров и смещение в сторону недавних данных могут снижать эффективность объединения моделей, однако предложенные стратегии взвешенного слияния и замены базовой модели позволяют смягчить эти проблемы. Как можно эффективно использовать полученные знания для создания адаптивных и устойчивых рекомендательных систем, способных учитывать как исторические, так и текущие предпочтения пользователей?
Преодолевая Холодный Старт: Новое Поколение Рекомендательных Систем
Традиционные системы рекомендаций часто сталкиваются с серьезными трудностями при работе с новыми пользователями или товарами, что известно как проблема «холодного старта». В этих случаях, из-за отсутствия достаточной информации об истории взаимодействия, система не может предложить релевантные рекомендации. Кроме того, многие существующие алгоритмы ограничиваются анализом отдельных характеристик пользователей и товаров, не учитывая сложные паттерны поведения и индивидуальные предпочтения. Это приводит к тому, что рекомендации часто оказываются общими и недостаточно персонализированными, не учитывая нюансы интересов конкретного пользователя и, как следствие, снижая эффективность всей системы. Подобные ограничения особенно заметны в условиях быстро меняющегося ассортимента и появления новых трендов, когда система не успевает адаптироваться к изменяющимся потребностям аудитории.
Рекомендательные системы нового поколения, известные как генеративные рекомендации, представляют собой кардинальный сдвиг в подходе к предсказанию предпочтений пользователей. Вместо традиционных методов, основанных на сопоставлении характеристик товаров и пользователей, эти системы используют мощь больших языковых моделей. Обученные на огромных объемах данных о взаимодействиях пользователей, они способны выявлять сложные закономерности и генерировать персонализированные рекомендации, предсказывая, какие товары или контент могут заинтересовать конкретного человека. В отличие от предыдущих поколений систем, генеративные рекомендации способны не просто предлагать похожие товары, но и учитывать контекст взаимодействия, историю предпочтений и даже скрытые взаимосвязи между различными элементами, что позволяет достичь значительно более высокой точности и релевантности предложений.
В основе генеративных рекомендательных систем лежит задача последовательных рекомендаций, фокусирующаяся на прогнозировании следующего элемента во взаимодействии пользователя. Вместо анализа статических предпочтений, данный подход рассматривает историю действий пользователя — последовательность просмотренных товаров, прослушанных песен или прочитанных статей — как сигнал для предсказания дальнейшего интереса. Используя модели глубокого обучения, такие как рекуррентные нейронные сети или трансформеры, системы анализируют эту последовательность, выявляя скрытые закономерности и зависимости между элементами. Такой метод позволяет учитывать динамику предпочтений пользователя, его текущий контекст и даже временные тренды, значительно повышая точность и релевантность рекомендаций по сравнению с традиционными подходами. Фактически, система учится «предсказывать будущее» пользователя, основываясь на его прошлом опыте, что открывает новые возможности для персонализированного взаимодействия.
Объединение Моделей: Новый Подход к Повышению Генеративных Возможностей
Объединение моделей (Model Merging) представляет собой инновационный подход к повышению производительности генеративных моделей, позволяющий комбинировать знания, полученные из нескольких предварительно обученных моделей, без необходимости их повторного обучения или доступа к исходным данным обучения. В отличие от традиционных методов, требующих значительных вычислительных ресурсов для обучения единой модели с нуля или тонкой настройки, объединение моделей позволяет эффективно использовать существующие ресурсы. Этот процесс заключается в комбинировании весов параметров различных моделей, создавая новую модель, которая наследует и объединяет сильные стороны каждой из исходных. Таким образом, объединение моделей предоставляет возможность создавать более мощные и универсальные модели, не требуя дорогостоящих и трудоемких операций обучения.
Методы объединения моделей, такие как взвешенное объединение (Weighted-based Merging) и объединение на основе подпространств (Subspace-based Merging), предлагают различные подходы к комбинированию параметров предобученных моделей. Взвешенное объединение предполагает простое усреднение весов моделей с применением различных коэффициентов, что позволяет акцентировать вклад каждой модели в итоговый результат. Преимуществом данного метода является его простота и вычислительная эффективность. В свою очередь, объединение на основе подпространств предполагает выявление и комбинирование ключевых направлений в пространстве параметров, что позволяет более эффективно использовать возможности каждой модели и снизить риск ухудшения производительности за счет конфликтующих параметров. Выбор конкретного метода зависит от характеристик объединяемых моделей и поставленной задачи.
Концепция «Вектора Задачи» играет ключевую роль в процессе объединения моделей, поскольку представляет собой векторное представление разницы между параметрами различных предварительно обученных моделей. Этот вектор, рассчитываемый как разность соответствующих весов моделей, позволяет количественно оценить, какие именно параметры отвечают за выполнение определенной задачи или обладают специфическими знаниями. Анализ и манипулирование вектором задачи позволяет оптимизировать процесс слияния, например, путем масштабирования или комбинирования векторов задачи для достижения желаемого поведения объединенной модели. \Delta w = w_1 - w_2 , где \Delta w — вектор задачи, w_1 и w_2 — веса двух моделей. Понимание структуры вектора задачи необходимо для эффективного переноса знаний между моделями и создания более мощных и гибких генеративных систем.
MMGRid: Платформа для Систематического Изучения Объединения Моделей
MMGRid представляет собой унифицированную платформу, разработанную для изучения методов объединения моделей в задачах генеративных рекомендательных систем. Данная платформа обеспечивает контролируемые эксперименты и анализ, позволяя исследователям систематически оценивать различные стратегии объединения моделей и их влияние на качество рекомендаций. Ключевой особенностью MMGRid является стандартизация процесса экспериментирования, что позволяет сравнивать результаты, полученные разными исследователями, и ускоряет прогресс в области генеративных рекомендаций. Платформа предоставляет инструменты для настройки параметров объединения, сбора метрик производительности и визуализации результатов, упрощая процесс разработки и оценки новых подходов.
MMGRid предоставляет возможность объединения моделей, обученных на различных предметных областях (Cross-Domain Merging), и моделей, учитывающих временную динамику данных (Temporal Merging). Это позволяет создавать рекомендательные системы, способные обобщать знания, полученные из разных категорий товаров, и адаптироваться к изменяющимся предпочтениям пользователей. Кросс-доменное объединение позволяет модели эффективно рекомендовать товары из незнакомых категорий, используя знания, полученные из похожих. Временное объединение учитывает, что предпочтения пользователей меняются со временем, и позволяет модели адаптироваться к этим изменениям, улучшая качество рекомендаций для новых или редко взаимодействующих товаров.
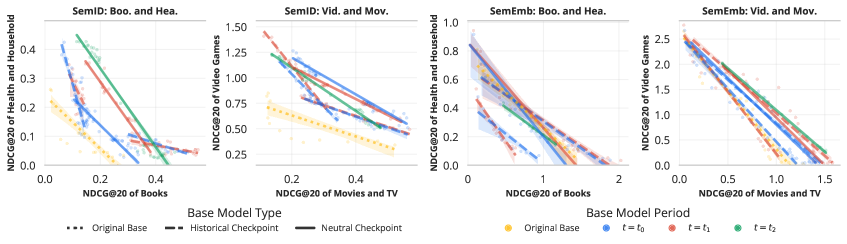
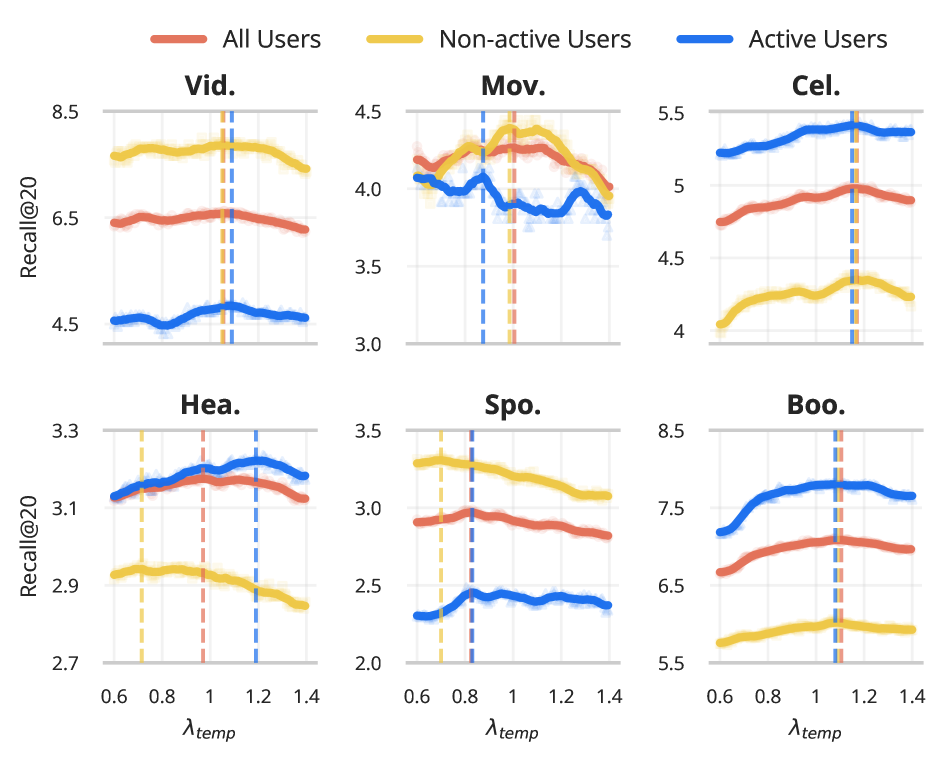
Исследования, проведенные с использованием MMGRid, показали, что стратегическое объединение моделей, основанное на анализе характеристик предметных областей и временных факторов, позволяет превзойти производительность моделей, обученных на единой контрольной точке. Наблюдаемый положительный корреляционный коэффициент между актуальностью (недавностью) товаров и оптимальным весом объединения подтверждает эффективность использования характеристик предметной области для разработки эффективных стратегий объединения моделей. Величина улучшения производительности варьируется в зависимости от конкретной предметной области, что указывает на необходимость адаптации стратегий объединения к специфике данных.
Семантическое Обогащение: Расширение Возможностей Генеративных Моделей
Методы семантического моделирования идентификаторов и встраивания, такие как Semantic ID Modeling и Semantic Embedding Modeling, значительно расширяют возможности генеративных моделей в понимании и представлении информации о товарах. Вместо простого анализа паттернов взаимодействия, эти подходы позволяют учитывать смысловое содержание товаров — их характеристики, категории и связи с другими элементами. Это достигается путем кодирования семантической информации в векторные представления, которые затем используются генеративной моделью для более точного предсказания предпочтений пользователей. В результате, система способна предлагать релевантные рекомендации даже для новых или малоизвестных товаров, для которых недостаточно данных о взаимодействиях, что делает её особенно ценной в ситуациях «холодного старта».
Методы, обогащающие генеративные модели семантическими знаниями, позволяют значительно повысить точность и релевантность рекомендаций, особенно в ситуациях, когда информации о взаимодействии с товарами недостаточно. Традиционные алгоритмы часто испытывают трудности при работе с новыми или малоизвестными элементами, поскольку полагаются на историю взаимодействий. Однако, интегрируя семантическое понимание — например, описание товара, его категорию или атрибуты — эти модели способны делать более обоснованные предположения и предлагать релевантные альтернативы, даже при отсутствии достаточного количества данных о взаимодействии. Это особенно важно для платформ, стремящихся предоставлять персонализированные рекомендации для широкого спектра товаров, включая те, которые только начинают набирать популярность.
В основе данных генеративных систем часто лежат мощные большие языковые модели, такие как Qwen3-0.6B, обеспечивающие надежный фундамент для предсказаний. Эта модель, обладая значительным объемом предварительно обученных знаний и способностью к пониманию сложных взаимосвязей, позволяет эффективно моделировать вероятности появления различных элементов. Qwen3-0.6B не просто прогнозирует следующие элементы в последовательности, но и учитывает семантический контекст, что особенно важно при работе с данными, где количество взаимодействий ограничено. Благодаря своей архитектуре и масштабу, эта языковая модель способна извлекать и использовать скрытые закономерности, значительно повышая точность и релевантность генерируемых рекомендаций и предсказаний.
Исследование, представленное в статье, подчеркивает важность системного подхода к объединению моделей в генеративных рекомендательных системах. Авторы акцентируют внимание на проблемах контекстных конфликтов и необходимости балансировки исторических и новых предпочтений пользователей. Это согласуется с философией элегантного дизайна, где ясность структуры определяет поведение системы. Как однажды заметил Брайан Керниган: «Простота — это высшая степень утонченности». Данная цитата отражает суть работы, поскольку эффективное объединение моделей требует отхода от избыточной сложности в пользу четких и понятных принципов, позволяющих учитывать временные изменения и междоменные связи в данных о пользователях. Подход, предложенный в статье, стремится к созданию именно такой системы — живого организма, где каждая часть взаимодействует с целым, а масштабируемость достигается не за счет серверной мощности, а за счет ясности идей.
Куда двигаться дальше?
Представленная работа, исследуя слияние моделей в генеративных рекомендательных системах, выявляет закономерную сложность: каждая новая зависимость — скрытая цена свободы. Элегантное решение, казалось бы, простое объединение моделей, обнажает конфликт контекстов и необходимость тонкого баланса между историческими предпочтениями пользователя и их текущей эволюцией. Иронично, но поиск оптимальной структуры приводит к осознанию, что идеальная модель — это не статичный объект, а динамическая система, постоянно адаптирующаяся к изменчивости мира.
Очевидным направлением дальнейших исследований представляется углубленное изучение механизмов разрешения конфликтов между доменами. Недостаточно просто объединять модели; необходимо понимать, как их взаимодействие влияет на целостную картину предпочтений пользователя. Требуется разработка методов, позволяющих оценивать и контролировать “стоимость” интеграции новых зависимостей, избегая нежелательных побочных эффектов и сохраняя когерентность рекомендаций.
В конечном счете, представленная работа подчеркивает фундаментальную истину: структура определяет поведение. Эффективная рекомендательная система — это не просто набор алгоритмов, а сложный живой организм, требующий постоянного наблюдения и тонкой настройки. Будущие исследования должны быть направлены на создание более гибких и адаптивных архитектур, способных справляться с непредсказуемостью реального мира и сохранять свою эффективность во времени.
Оригинал статьи: https://arxiv.org/pdf/2601.15930.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Самообучающиеся признаки: новый подход к машинному обучению
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Математический интеллект: как улучшить навыки решения задач у больших языковых моделей
- Биомолекулярные связи: новый тест для искусственного интеллекта
2026-01-25 18:00