Автор: Денис Аветисян
Исследователи предлагают стратегию декодирования, фокусирующуюся на наиболее неопределенных токенах для повышения точности и надежности языковых моделей.
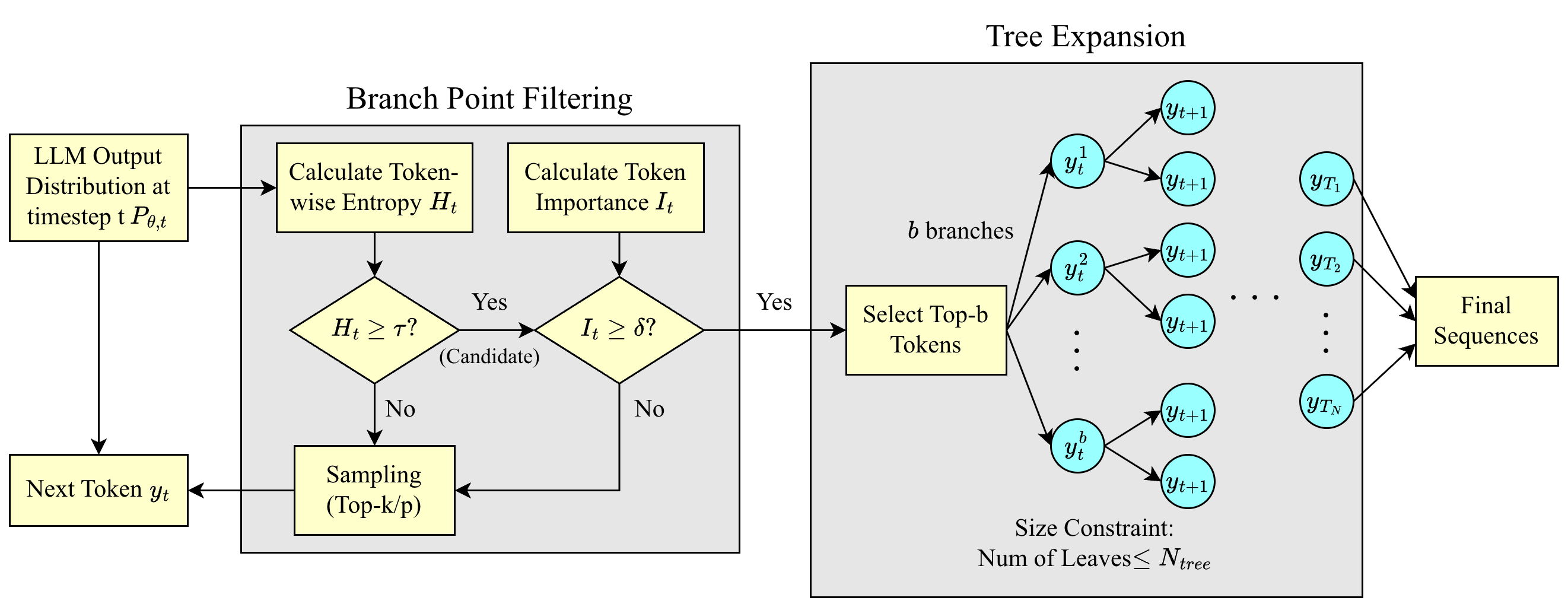
Представлена методика Entropy-Tree, использующая поиск по дереву для исследования пространства вероятностей и улучшения самосогласованности генерируемого текста.
Несмотря на впечатляющую производительность больших языковых моделей в задачах рассуждения, существующие стратегии декодирования либо слепо исследуют пространство вариантов, либо избыточно используют независимое многократное семплирование. В данной работе представлена методика Entropy-Tree, основанная на построении дерева поиска с использованием энтропии для определения направлений ветвления — расширение дерева происходит только в позициях, где модель демонстрирует реальную неопределенность. Предложенный подход позволяет добиться повышения точности и калибровки результатов в задачах рассуждения, превосходя Multi-chain по метрике pass@k и демонстрируя лучшую AUROC по сравнению с традиционными показателями оценки неопределенности. Способна ли Entropy-Tree стать универсальным решением для эффективного и надежного декодирования в больших языковых моделях?
Хрупкость Жадного Декодирования: Пророчество Сбоя
Несмотря на впечатляющую способность современных больших языковых моделей генерировать текст, часто используется метод “жадного декодирования” (Greedy Decoding). Этот подход, стремящийся к немедленному выбору наиболее вероятного следующего слова, приводит к формированию хрупких и предсказуемых результатов. Модель, действуя подобно человеку, который выбирает первый пришедший в голову вариант, упускает из виду множество других, потенциально более точных или креативных решений. В результате генерируемый текст может казаться шаблонным, лишенным нюансов и неспособным адекватно отражать сложность исходной задачи, что снижает общую надежность и полезность системы.
Применение жадных алгоритмов декодирования в сложных задачах рассуждений часто приводит к недостаточно точным результатам, поскольку они не способны адекватно отразить присущую этим задачам неопределенность. Вместо того чтобы учитывать множество возможных путей решения, такие методы склонны выбирать наиболее вероятный вариант на каждом шагу, игнорируя альтернативные, потенциально верные, ответы. Это приводит к хрупкости модели, когда встречаются неоднозначные или неполные данные, а также к снижению надежности в ситуациях, требующих учета различных интерпретаций и вероятностей. Отсутствие репрезентации неопределенности ограничивает способность модели к адаптации и коррекции ошибок, что особенно критично в задачах, где требуется не просто найти ответ, а оценить степень его достоверности.
Несмотря на то, что такие методы, как Beam Search и Self-Consistency, действительно улучшают качество генерируемых текстов по сравнению с жадным декодированием, они все еще сталкиваются с ограничениями в полноценном охвате всего спектра возможных решений. Beam Search, хотя и рассматривает несколько наиболее вероятных последовательностей, часто фокусируется на локальных оптимумах, упуская из виду более креативные или неожиданные, но потенциально верные ответы. Self-Consistency, стремясь к согласованности между множеством сгенерированных ответов, может подавлять менее распространенные, но все же валидные варианты, особенно в задачах, требующих диверсификации и инноваций. Таким образом, существующие подходы, хотя и являются шагом вперед, все еще не способны полностью отразить всю сложность и неопределенность, присущие сложным задачам рассуждения, что ограничивает надежность и гибкость языковых моделей.
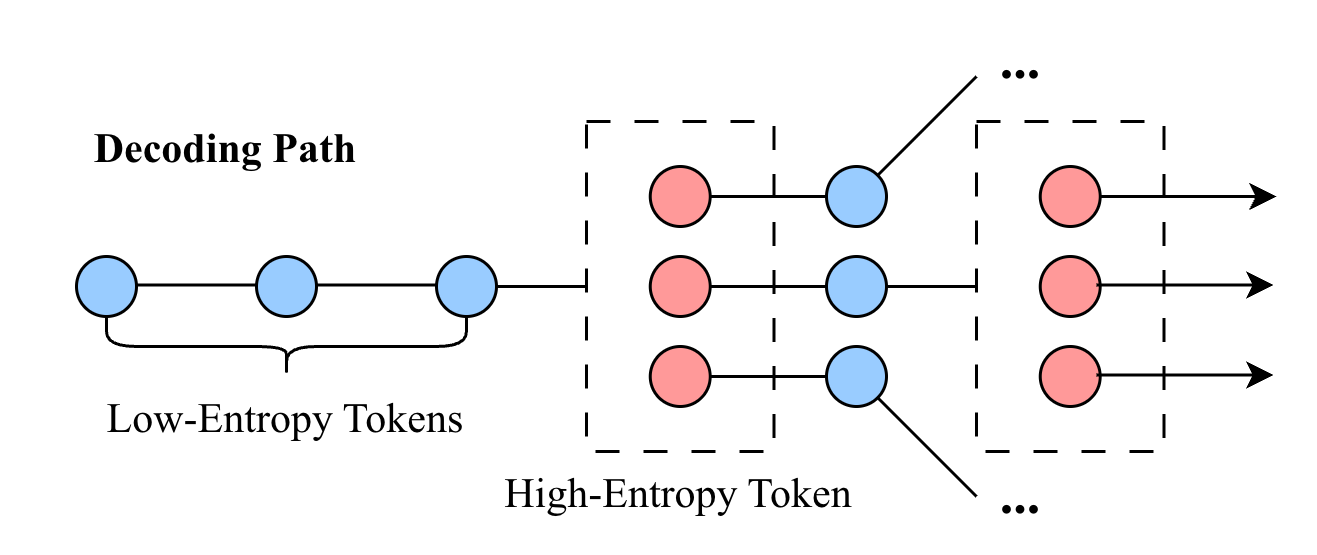
Разветвляющееся Дерево Энтропии: Новый Путь Декодирования
Декодирование с использованием Entropy-Tree динамически разветвляет процесс генерации текста в моменты, когда текущий токен характеризуется высокой неопределенностью (High-Entropy Tokens). Высокая энтропия токена определяется как значительная степень вероятностной неоднозначности при выборе следующего токена из словарного запаса. В таких случаях, вместо выбора наиболее вероятного токена, алгоритм создает несколько ветвей декодирования, каждая из которых представляет собой потенциальный путь развития последовательности. Это позволяет исследовать различные варианты продолжения текста, учитывая вероятностное распределение, заданное моделью, и снижает риск застревания в локальном оптимуме при генерации.
В процессе ветвления алгоритма Entropy-Tree Decoding, исследование множественных путей рассуждений осуществляется посредством механизма Self-Attention, который оценивает взаимосвязи между токенами для определения наиболее вероятных продолжений. Оценка потенциальных продолжений производится на основе значений Model Logits — выходных данных модели, отражающих уверенность в каждом возможном следующем токене. Self-Attention позволяет модели учитывать контекст при оценке Logits, что повышает точность выбора наиболее перспективных ветвей декодирования и способствует более полному исследованию пространства решений.
Метод декодирования Entropy-Tree расширяет возможности существующих стратегий, таких как Beam Search и Self-Consistency, обеспечивая более надежное исследование пространства решений. В отличие от Beam Search, который ограничивается фиксированным количеством наиболее вероятных последовательностей, Entropy-Tree динамически ветвится на основе оценки неопределенности токенов, что позволяет рассмотреть большее количество потенциальных путей рассуждений. По сравнению с Self-Consistency, которая генерирует несколько независимых выборок, Entropy-Tree интегрирует информацию о распределении вероятностей, полученную с помощью Self-Attention и Model Logits, для более эффективной оценки и отбора перспективных продолжений. Это приводит к снижению вероятности застревания в локальных оптимумах и повышению устойчивости к неоднозначным или сложным входным данным.
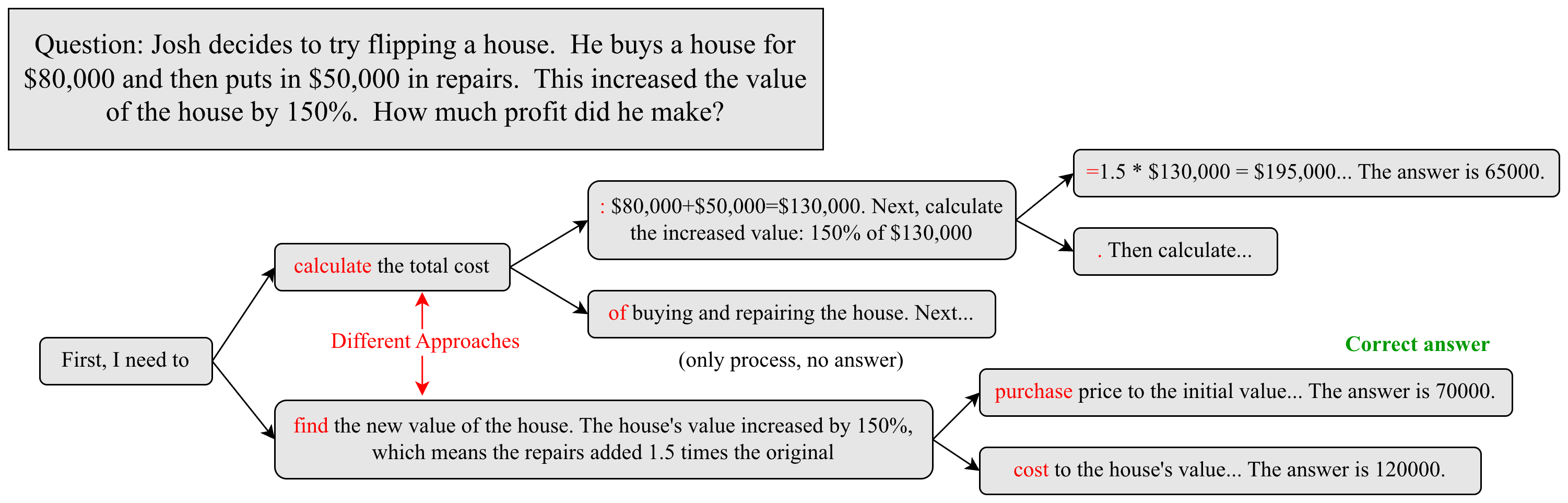
Количественная Оценка Неопределенности: Энтропия как Мера Разветвления
Для выявления моментов высокой неопределенности в процессе декодирования используется энтропия токенов. Этот показатель рассчитывается как мера случайности распределения вероятностей предсказываемых токенов моделью на каждом шаге. Высокая энтропия токенов указывает на то, что модель не уверена в следующем токене, что сигнализирует о потенциальной возможности ветвления в процессе генерации. Практически, это означает, что модель рассматривает несколько токенов как равновероятные, и выбор между ними может привести к различным, но валидным результатам. H = - \sum_{i} p(x_i) \log p(x_i), где H — энтропия, а p(x_i) — вероятность i-го токена.
Прогнозируемая энтропия, обеспечиваемая такими методами, как Байесовские нейронные сети, представляет собой более широкую оценку уверенности модели в своих предсказаниях. В отличие от оценки неопределенности в конкретной точке декодирования, прогнозируемая энтропия оценивает распределение вероятностей по всему пространству возможных выходных данных. Байесовские нейронные сети, в частности, позволяют моделировать неопределенность, предоставляя распределение по весам сети, что приводит к распределению вероятностей по прогнозируемым значениям. H(p) = - \sum_{i} p(i) \log p(i) — формула расчета энтропии, где p(i) — вероятность i-го исхода. Более высокая прогнозируемая энтропия указывает на меньшую уверенность модели и, следовательно, большую неопределенность в ее предсказаниях, что может сигнализировать о необходимости дальнейшего исследования альтернативных решений.
Семантическая энтропия уточняет оценку неопределенности, учитывая семантическую эквивалентность различных решений. Это означает, что алгоритм не просто рассматривает лексическое разнообразие, но и оценивает, насколько близко по смыслу являются различные варианты. В отличие от традиционной энтропии, которая может переоценивать неопределенность из-за синонимичных выражений, семантическая энтропия позволяет сосредоточиться на действительно значимых различиях, обеспечивая более осмысленное исследование альтернативных решений и избегая избыточного ветвления при декодировании. Это достигается путем применения семантических моделей, которые оценивают близость представлений различных вариантов, что позволяет алгоритму более эффективно исследовать пространство решений и выбирать наиболее подходящие варианты, учитывая контекст и смысл.
Эмпирическая Валидация и Прирост Производительности: Подтверждение Эффективности
Эксперименты, проведенные с использованием моделей серии Qwen2.5, однозначно демонстрируют превосходство метода Entropy-Tree Decoding над стандартными подходами к декодированию. В ходе исследований было установлено, что данный метод стабильно обеспечивает более качественные результаты в задачах генерации текста, предлагая повышенную точность и согласованность генерируемых последовательностей. В частности, Entropy-Tree позволяет достичь сопоставимых показателей качества при значительно меньшем объеме вычислений, что делает его эффективным решением для ресурсоемких приложений и задач, требующих высокой скорости обработки. Полученные данные подтверждают, что Entropy-Tree Decoding представляет собой перспективный инструмент для улучшения производительности и качества языковых моделей.
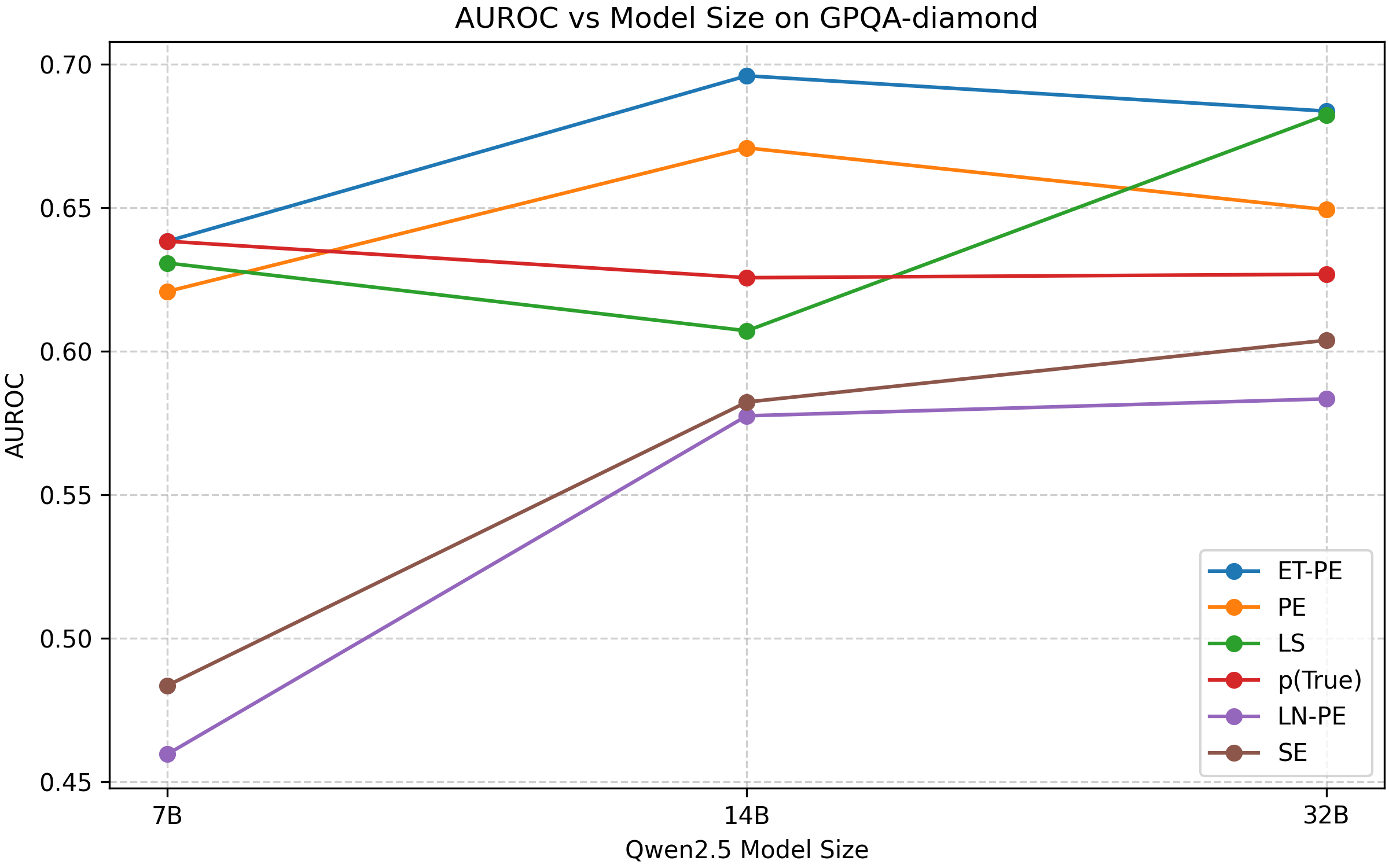
Оценка с использованием метрик Pass@K и AUROC подтверждает способность разработанного метода генерировать более точные и откалиброванные результаты. Pass@K измеряет вероятность того, что хотя бы одна из K сгенерированных последовательностей соответствует ожидаемому ответу, что позволяет оценить разнообразие и релевантность выходных данных. В свою очередь, AUROC (площадь под ROC-кривой) отражает способность модели различать правильные и неправильные ответы, демонстрируя ее калибровку и уверенность в предсказаниях. Высокие значения обеих метрик указывают на то, что модель не только генерирует правильные ответы, но и способна оценивать свою уверенность в этих ответах, что особенно важно для приложений, требующих надежности и предсказуемости.
Экспериментальные исследования показали, что метод Entropy-Tree позволяет достигать сопоставимых результатов Pass@K, оценивающих точность сгенерированного текста, используя примерно на треть меньший объем выборок — 13 против 20, необходимых для Multi-chain sampling. Это означает, что для получения аналогичного уровня точности, Entropy-Tree требует значительно меньше вычислительных ресурсов и времени, что особенно важно при работе с большими языковыми моделями и обширными наборами данных. Эффективность метода заключается в оптимизированном подходе к отбору наиболее вероятных вариантов продолжения текста, что позволяет снизить потребность в большом количестве семплов для достижения приемлемого качества генерации.
Исследования показали, что предсказательная энтропия, полученная с использованием метода Entropy-Tree, демонстрирует превосходные результаты по сравнению с семантической энтропией и традиционными подходами к предсказательной энтропии. В ходе экспериментов на различных моделях и наборах данных, Entropy-Tree последовательно обеспечивал оптимальную производительность, позволяя более точно оценивать вероятность различных вариантов продолжения текста. Этот подход позволяет значительно улучшить калибровку выходных данных, то есть, соответствие предсказанных вероятностей фактическим результатам, что особенно важно для приложений, требующих надежной оценки неопределенности, таких как принятие решений и генерация текста с контролируемыми характеристиками. Превосходство Entropy-Tree над альтернативными методами подтверждается как теоретически, так и эмпирически, что делает его перспективным инструментом для улучшения качества и надежности языковых моделей.
В ходе экспериментов с различными наборами данных и моделями продемонстрирована повышенная точность декодирования Entropy-Tree по сравнению с методом Multi-chain. Результаты, отраженные в показателях Pass@10 и Pass@20, последовательно указывают на превосходство Entropy-Tree в генерации более корректных ответов. Это означает, что при оценке десяти или двадцати сгенерированных вариантов, Entropy-Tree чаще предлагает правильный ответ, чем Multi-chain, подтверждая эффективность предложенного подхода к оптимизации процесса декодирования и повышению качества генерируемого текста.
Представленное исследование демонстрирует, что стремление к стабильности в генеративных моделях может быть обманчиво. Авторы предлагают стратегию Entropy-Tree, которая намеренно фокусируется на исследовании наиболее неопределенных, высокоэнтропийных токенов. Это подход, далекий от простого стремления к максимизации правдоподобия. Как однажды заметил Карл Фридрих Гаусс: «Если я должен выбрать между высокой точностью и высокой надежностью, я выберу надежность». Данная работа подтверждает эту мысль, показывая, что исследование неопределенности, а не только выбор наиболее вероятного пути, ведет к более отказоустойчивым и откалиброванным результатам. Система, стремящаяся к самосогласованности через исследование, предстает не как статичная конструкция, а как развивающаяся экосистема, способная адаптироваться к неизбежным ошибкам.
Что Дальше?
Представленная работа, касающаяся стратегии декодирования Entropy-Tree, лишь осторожно прикоснулась к краешку бездны неопределенности, присущей большим языковым моделям. Поиск по дереву, управляемый энтропией, — это, конечно, шаг в направлении более калиброванных и точных генераций, но иллюзия контроля над хаосом всегда обманчива. Архитектура — это лишь способ откладывать хаос, а не побеждать его.
Вопрос не в том, как найти «лучшую» стратегию декодирования, ведь не существует лучших практик, есть лишь выжившие. Более продуктивным представляется изучение того, как модели сами учатся оценивать и управлять собственной неопределенностью. Исследование высокоэнтропийных токенов — это лишь первая ласточка. Следующим шагом видится разработка механизмов, позволяющих модели не просто выбирать наиболее вероятный путь, но и осознавать вероятность собственного заблуждения.
Порядок — это кеш между двумя сбоями. Поэтому, в конечном счете, истинная ценность исследований в этой области заключается не в создании идеально откалиброванных моделей, а в понимании того, как они терпят неудачу, и как эти неудачи могут быть использованы для построения более устойчивых и адаптивных систем. Иначе говоря, нам следует учиться не у успеха, а у выживания.
Оригинал статьи: https://arxiv.org/pdf/2601.15296.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Самообучающиеся признаки: новый подход к машинному обучению
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Мгновенная расшифровка: Voxtral Realtime на службе у скорости
- Навыки агентов: Новый уровень интеллекта ИИ
2026-01-25 18:02