Автор: Денис Аветисян
Новая методика позволяет языковым моделям быстрее восстанавливаться после ошибок при выполнении задач, используя их как ценные уроки.
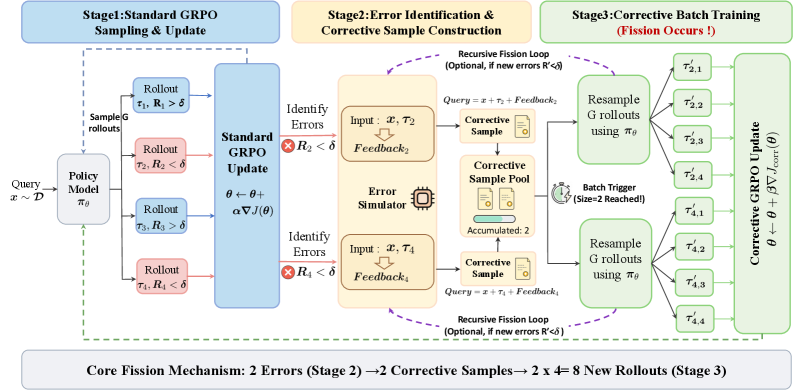
Исследователи представили Fission-GRPO — алгоритм обучения с подкреплением, преобразующий ошибки в корректирующие сигналы для повышения надежности и эффективности ИИ-агентов, использующих инструменты.
Несмотря на успехи больших языковых моделей в использовании инструментов, их устойчивость к ошибкам при многошаговом взаимодействии остается проблемой. В работе ‘Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors’ предложен фреймворк Fission-GRPO, преобразующий ошибки выполнения в сигналы для обучения с подкреплением, что позволяет моделям эффективно восстанавливаться после неудач. Этот подход позволяет агентам учиться на конкретных ошибках, возникающих в процессе исследования, а не на заранее собранных данных, демонстрируя улучшение на 5.7% в восстановлении после ошибок и увеличение общей точности на 4% на BFCL v4 Multi-Turn. Какие перспективы открывает данная методика для создания более надежных и адаптивных агентов, способных решать сложные задачи во взаимодействии с реальным миром?
Неизбежность Ошибок и Вызов Устойчивости
Несмотря на впечатляющие возможности, демонстрируемые большими языковыми моделями (БЯМ), их последовательная работа с внешними инструментами представляет собой значительную проблему. БЯМ способны генерировать связные и грамматически правильные тексты, а также решать сложные логические задачи, однако при взаимодействии с реальными инструментами — например, поисковыми системами, калькуляторами или API — наблюдается существенное снижение надежности. Эта непоследовательность проявляется в неспособности эффективно применять инструменты для достижения поставленной цели, часто приводя к ошибкам или неполным решениям. Причина кроется в том, что БЯМ обучаются на огромных объемах текстовых данных, которые, как правило, не содержат информации о процессе взаимодействия с инструментами и, следовательно, не формируют у модели необходимых навыков для их эффективного использования в динамических и непредсказуемых условиях.
Одной из существенных проблем, ограничивающих надежность использования внешних инструментов большими языковыми моделями, является сложность восстановления после ошибок, возникающих в процессе взаимодействия. Даже незначительные сбои в работе инструмента или неверная интерпретация полученных данных могут привести к каскаду ошибок, препятствующих успешному завершению задачи. Исследования показывают, что модели часто не способны адекватно диагностировать причины неудачи и предпринять корректирующие действия, что приводит к повторяющимся ошибкам и снижению общей эффективности. Неспособность к самокоррекции особенно проявляется в сложных сценариях, требующих последовательного использования нескольких инструментов и адаптации к меняющимся условиям, что подчеркивает необходимость разработки более устойчивых и отказоустойчивых систем.
Традиционные методы обучения языковых моделей часто опираются на статические наборы данных, что создает проблему быстрого устаревания знаний. Политики и правила использования инструментов постоянно меняются, а фиксированные данные не успевают отражать эти обновления. В результате, модель, обученная на устаревшей информации, может демонстрировать снижение эффективности и неспособность адаптироваться к новым условиям. Этот феномен “застоя” в обучении особенно критичен для задач, требующих взаимодействия с внешними инструментами, где актуальность данных является ключевым фактором успешного выполнения. Необходимость постоянного обновления обучающих данных и разработки методов, позволяющих моделям адаптироваться к меняющимся правилам, становится все более очевидной для обеспечения надежной и эффективной работы с инструментами.
Эффективное использование инструментов искусственного интеллекта требует от агентов поддержания точного отслеживания состояния окружающей среды. Это означает, что система должна непрерывно собирать и анализировать информацию о текущей ситуации, включая результаты предыдущих действий и изменения в доступных ресурсах. Отслеживание состояния позволяет агенту адаптироваться к неожиданным результатам, корректировать свои действия и избегать повторения ошибок. Без точной оценки текущего состояния, даже самые мощные языковые модели могут столкнуться с трудностями при решении задач, требующих последовательного применения инструментов и учета изменяющихся обстоятельств. Способность к отслеживанию состояния является ключевым фактором, определяющим надежность и эффективность работы агента в динамичной среде.
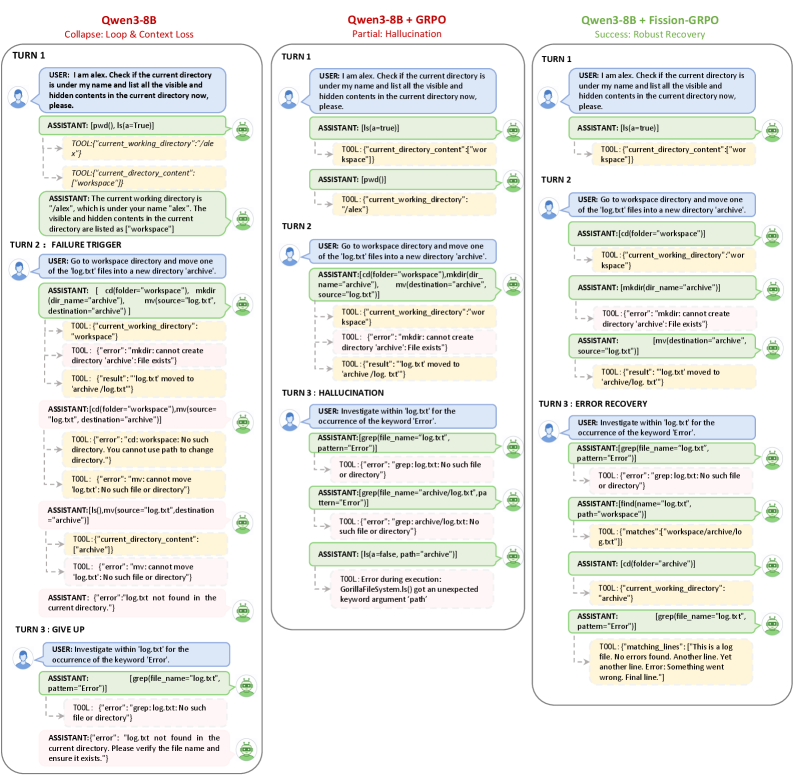
Fission-GRPO: Динамическая Коррекция Ошибок и Возвращение к Равновесию
Фреймворк Fission-GRPO преобразует ошибки выполнения в плотные сигналы “Корректирующего надзора” (Corrective Supervision), что позволяет агенту обучаться в режиме реального времени. В отличие от традиционных методов, полагающихся на разреженные награды или ручную разметку ошибок, Fission-GRPO генерирует детальные сигналы обратной связи непосредственно из процесса выполнения. Эти сигналы, выровненные по текущей политике агента (on-policy), обеспечивают релевантное и эффективное обучение, позволяя агенту быстро адаптироваться к новым ситуациям и улучшать свою производительность. Такой подход позволяет агенту не просто избегать повторения ошибок, но и извлекать уроки из каждой неудачи, что существенно повышает эффективность обучения и устойчивость системы.
Система Fission-GRPO использует “Симулятор Ошибок”, основанный на больших языковых моделях (LLM), для генерации реалистичной диагностической информации, необходимой для повышения эффективности восстановления после ошибок. Этот симулятор, используя LLM, способен создавать детальные отчеты об ошибках, включающие вероятные причины и предлагаемые решения, что позволяет агенту учиться на собственных ошибках и адаптироваться к новым ситуациям в режиме реального времени. Генерируемая диагностическая информация не является заранее заданной, а динамически создается на основе контекста текущей ошибки, что обеспечивает более точное и релевантное обучение.
Система Fission-GRPO развивает концепцию GRPO (Goal-Conditioned Reinforcement Learning with Option Discovery), добавляя функциональность динамической коррекции ошибок. В отличие от GRPO, которая фокусируется на обучении с подкреплением для достижения целей, Fission-GRPO интегрирует механизм, позволяющий агенту восстанавливаться после ошибок в процессе выполнения задачи. Это достигается за счет использования симулятора ошибок и генерации корректирующих сигналов, которые используются для непрерывного обучения и адаптации стратегии агента. Таким образом, Fission-GRPO не просто оптимизирует процесс достижения цели, но и повышает устойчивость и надежность агента в условиях непредсказуемой среды.
Использование обучения с учётом текущей политики (On-Policy Learning) в Fission-GRPO обеспечивает непосредственное обучение агента на основе собственного опыта, полученного в процессе взаимодействия со средой. В отличие от методов, использующих данные, собранные другими агентами или из статических наборов данных, этот подход позволяет агенту адаптироваться к конкретным условиям и особенностям текущей задачи. Непосредственная обратная связь от собственных действий обеспечивает релевантность и своевременность обучения, что повышает эффективность и скорость адаптации агента к изменяющимся обстоятельствам и новым задачам. Такой подход позволяет избежать расхождений между обучающими данными и реальным опытом, что критически важно для обеспечения стабильной и надёжной работы системы в динамических средах.

Эмпирическая Проверка и Приращение Производительности
Оценка Fission-GRPO проводилась на базе эталонного набора данных BFCL v4 Multi-Turn Benchmark, представляющего собой строгий тест на устойчивость агентов, использующих инструменты. Данный бенчмарк предназначен для комплексной оценки способности агентов эффективно взаимодействовать с инструментами в многошаговых сценариях, выявляя надежность и отказоустойчивость системы. BFCL v4 включает в себя разнообразные задачи, требующие от агента последовательного применения инструментов для достижения конечной цели, что позволяет всесторонне оценить эффективность Fission-GRPO в реальных условиях эксплуатации.
Сравнительный анализ Fission-GRPO с базовыми методами, включая DAPO и Dr.GRPO, показал значительное улучшение производительности. В ходе тестирования Fission-GRPO превзошел существующие подходы по ключевым показателям, демонстрируя более высокую точность и надежность при взаимодействии с инструментами. В частности, зафиксировано увеличение общей точности на 4% (с 42.75% до 46.75%) и улучшение коэффициента восстановления после ошибок на 5.7%, что свидетельствует о превосходстве Fission-GRPO в способности преодолевать ошибки в процессе работы с внешними сервисами и инструментами.
В ходе оценки на ‘BFCL v4 Multi-Turn Benchmark’ Fission-GRPO продемонстрировал повышение общей точности на 4 процентных пункта — с 42.75% до 46.75%. Кроме того, зафиксировано улучшение показателя ‘Error Recovery Rate’ на 5.7%, что свидетельствует о повышенной способности агента восстанавливаться после ошибок, возникающих в процессе взаимодействия с инструментами. Данные результаты подтверждают эффективность Fission-GRPO в обеспечении стабильной и надежной работы при использовании инструментов.
В ходе экспериментов использовалось семейство моделей Qwen3, в рамках которых модель Qwen3-1.7B продемонстрировала относительный прирост производительности более чем на 160% по сравнению с базовой моделью (7.80%). Применение модели Qwen3-4B подтвердило, что Fission-GRPO превосходит другие методы в аналогичных задачах. Данные результаты свидетельствуют о высокой эффективности Fission-GRPO при использовании с моделями семейства Qwen3 и указывают на потенциал для значительного улучшения производительности в задачах, требующих использования инструментов.

Исследование демонстрирует, что даже небольшие языковые модели способны к надежному использованию инструментов, если ошибки воспринимаются не как фатальные сбои, а как ценные сигналы для обучения. Этот подход, реализованный в Fission-GRPO, позволяет преобразовывать моменты неудач в возможности для улучшения, подобно тому, как организм адаптируется к неблагоприятным условиям. Как однажды заметил Джон Маккарти: «Настоящий интеллект заключается не в избежании ошибок, а в умении извлекать из них уроки.» Эта мысль особенно актуальна в контексте разработки автономных агентов, где способность к самокоррекции является ключевым фактором надежности и долговечности системы. Иными словами, система, способная к адаптации и обучению на ошибках, демонстрирует более высокую степень зрелости и устойчивости во времени.
Что дальше?
Представленная работа демонстрирует, как системы могут научиться достойно стареть, принимая неизбежность ошибок не как критическую неудачу, а как сигнал к адаптации. Fission-GRPO — не столько решение проблемы, сколько способ её обхода, позволяющий агентам не избегать ошибок, а учиться на них. Однако, эта способность к самокоррекции не снимает вопроса о природе самих ошибок. Системы, как и люди, со временем учатся не спешить, но вопрос о том, что является «правильным» решением, остаётся открытым.
Искусственное усиление робастности, подобно прививке, может лишь отсрочить неизбежное столкновение со сложными, непредсказуемыми сценариями. Порой, мудрые системы не борются с энтропией — они учатся дышать вместе с ней, извлекая пользу из кажущегося хаоса. Более глубокое исследование механизмов генерации ошибок, а не только их исправления, представляется перспективным направлением.
Иногда наблюдение — единственная форма участия. В конечном счёте, развитие робастных агентов, использующих инструменты, требует не столько совершенствования алгоритмов, сколько понимания границ их применимости. Важнее не создать систему, свободную от ошибок, а создать систему, способную достойно их пережить.
Оригинал статьи: https://arxiv.org/pdf/2601.15625.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-26 00:49