Автор: Денис Аветисян
Исследователи предлагают инновационный подход к анализу звука на граничных устройствах, сочетающий локальную обработку и облачные вычисления для повышения точности и конфиденциальности.
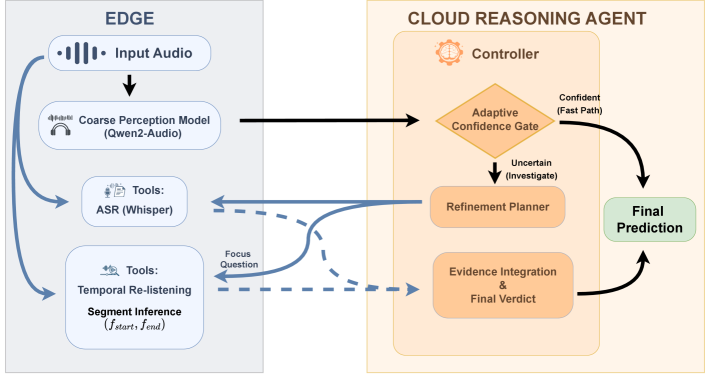
Представлена архитектура CoFi-Agent, использующая многоуровневое рассуждение и адаптивные механизмы для эффективной обработки аудиоданных с сохранением приватности.
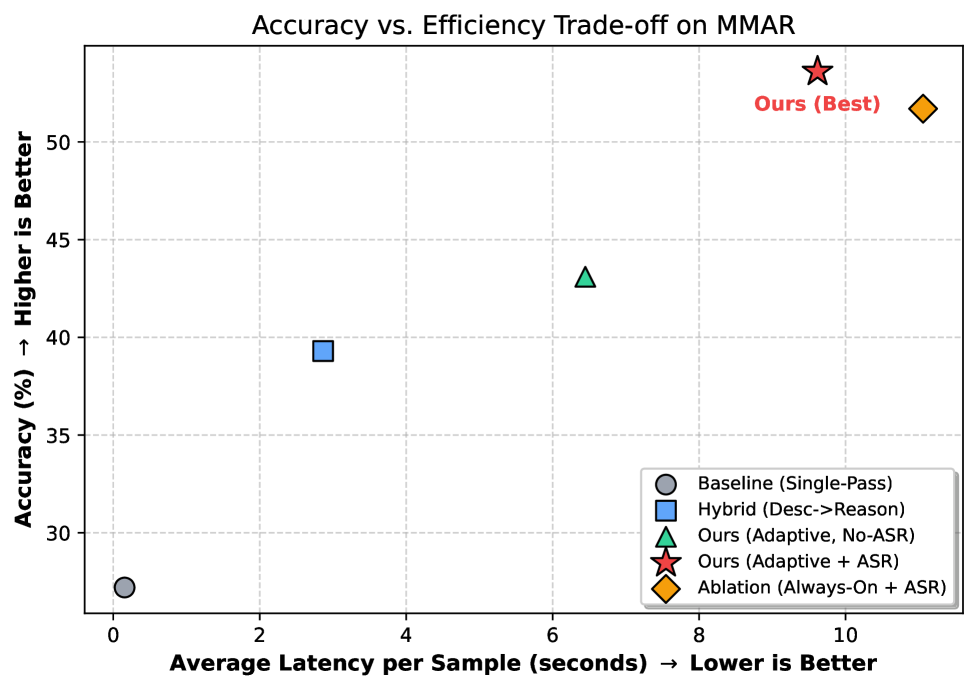
Развертывание моделей «аудио-язык» на периферийных устройствах сталкивается с противоречием между глубиной восприятия и вычислительной эффективностью. В работе ‘Bridging the Perception Gap: A Lightweight Coarse-to-Fine Architecture for Edge Audio Systems’ предложена архитектура CoFi-Agent, сочетающая локальную и облачную обработку для повышения точности анализа аудиоданных. CoFi-Agent использует принцип последовательного уточнения, направляя сложные запросы на локальные инструменты, что позволяет достичь значительного улучшения точности — с 27.20% до 53.60% на бенчмарке MMAR — при сохранении приватности акустической информации. Способна ли данная гибридная архитектура стать стандартом для систем анализа аудио на периферийных устройствах, требующих высокой точности и эффективности?
Звук и Разум: Вызовы и Возможности
Традиционные методы обработки звука зачастую требуют значительных вычислительных ресурсов, что связано с необходимостью выполнения сложных алгоритмов анализа и синтеза. Эта потребность в вычислительной мощности часто приводит к тому, что обработка перемещается в облачные среды, что, в свою очередь, создает задержки и зависимость от сетевого подключения. Такая архитектура существенно ограничивает возможности применения звуковых технологий в реальном времени, например, в системах мгновенного распознавания речи, интерактивных музыкальных приложениях или системах помощи водителям. Подобные ограничения особенно критичны в сценариях, где важна немедленная реакция системы, а надежность соединения не гарантирована.
Эффективное акустическое рассуждение требует от систем способности обрабатывать сложные звуковые сигналы без потери точности, что представляет собой значительную проблему для современных технологий. Исследования показывают, что традиционные методы обработки звука часто оказываются вычислительно затратными и неэффективными в реальном времени, особенно при работе с зашумленными или многокомпонентными сигналами. Для достижения оптимальной производительности необходимы алгоритмы, способные к параллельной обработке данных, интеллектуальному отсеву несущественной информации и адаптации к изменяющимся условиям окружающей среды. Успешное решение этой задачи откроет возможности для создания интеллектуальных устройств и систем, способных понимать и реагировать на звуковую информацию в режиме реального времени, от автономных роботов до улучшенных систем распознавания речи и мониторинга окружающей среды.
CoFi-Agent: От Грубого к Изысканному
CoFi-Agent использует гибридную архитектуру, объединяющую ресурсы непосредственно на устройстве и облачные вычисления для оптимизации обработки аудиоданных. Первичный анализ, требующий минимальной задержки и вычислительной мощности, выполняется локально. В случае необходимости, для более сложных задач и повышения точности, данные передаются в облако для выполнения ресурсоемких вычислений. Такой подход позволяет снизить задержку, уменьшить энергопотребление устройства и одновременно обеспечить высокую производительность в задачах аудио-рассуждений.
Система CoFi-Agent использует стратегию последовательного уточнения анализа, начиная с быстрой первичной обработки аудиоданных. В случае необходимости, для повышения точности, сложность анализа последовательно увеличивается с привлечением дополнительных ресурсов. На бенчмарке MMAR данный подход демонстрирует почти двукратное увеличение точности по сравнению с локальной моделью размером 7B, выполняющей анализ за один проход. Это позволяет оптимизировать использование вычислительных ресурсов и повысить эффективность решения задач, связанных с анализом аудио.
Внутреннее Устройство CoFi-Agent: Как Это Работает
Первичный анализ аудио выполняется непосредственно на устройстве с использованием языковой модели для аудио Qwen2-Audio-7B-Instruct и системы автоматического распознавания речи (ASR) Whisper. Qwen2-Audio-7B-Instruct обрабатывает аудиосигнал для извлечения семантической информации, в то время как Whisper преобразует аудио в текстовый формат. Данный подход позволяет снизить задержку и обеспечить конфиденциальность данных, поскольку обработка осуществляется локально, без передачи данных на внешние серверы. Комбинация этих технологий обеспечивает основу для последующего анализа и обработки аудиозапросов.
Процесс выделения релевантных фрагментов аудио осуществляется посредством модуля Segment Proposer, который идентифицирует и сегментирует аудиопоток. Последующая оценка качества и однозначности первичного анализа выполняется Confidence Gate. Этот модуль анализирует полученные сегменты на предмет неоднозначности или недостаточной уверенности в корректности распознавания, что позволяет отфильтровать нерелевантные или требующие дополнительной обработки фрагменты. Результаты работы Confidence Gate служат основой для принятия решения о необходимости эскалации запроса на более глубокий анализ или использовании дополнительных инструментов.
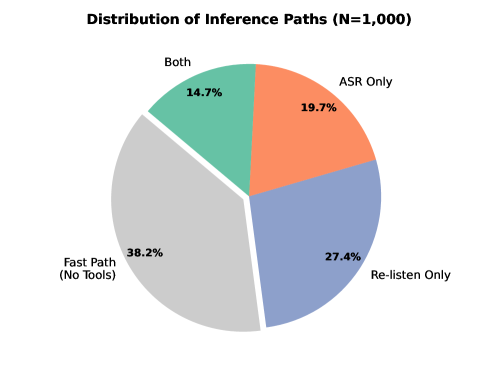
Адаптивное управление (Adaptive Gating) в CoFi-Agent осуществляет эскалацию неопределенных запросов для дальнейшего анализа. Около 62% всех запросов направляются по пути исследования (investigation path) для более тщательной обработки. В 27.4% случаев эскалированных запросов используется метод Temporal Re-listening — повторное прослушивание аудиофрагмента с учетом временного контекста. Дополнительно применяется аугментация инструментами (tool augmentation) для повышения точности анализа сложных запросов, что позволяет системе эффективно справляться с неоднозначными ситуациями и минимизировать количество ошибок.
Подтверждение Эффективности и Широкие Последствия
Оценка CoFi-Agent на бенчмарке MMAR продемонстрировала впечатляющую способность к решению сложных задач, связанных с аудио-рассуждениями. Система достигла точности в 53.60%, что почти вдвое превышает показатели однопроходной локальной модели размером 7B. Данный результат свидетельствует о значительном прогрессе в области обработки звуковой информации и открывает новые возможности для создания интеллектуальных систем, способных эффективно анализировать и интерпретировать аудиоданные в различных сферах применения, от автоматического распознавания речи до анализа звуковых ландшафтов.
Архитектура CoFi-Agent изначально спроектирована с учетом принципов минимизации данных, что значительно повышает уровень конфиденциальности пользователей. В отличие от традиционных систем, требующих передачи больших объемов аудиоинформации на централизованные облачные серверы для обработки, CoFi-Agent стремится выполнять максимальное количество вычислений непосредственно на устройстве. Такой подход не только снижает задержки и повышает скорость отклика, но и минимизирует риски, связанные с несанкционированным доступом к личным данным. Сокращение объема передаваемой информации в облако означает, что потенциальная поверхность атаки для злоумышленников существенно уменьшается, обеспечивая более надежную защиту конфиденциальной информации пользователей.
Исследования показали, что CoFi-Agent демонстрирует высокую эффективность в обработке аудиоданных, позволяя завершить 38.2% запросов непосредственно, без использования дополнительных инструментов. В случаях, требующих расширенного анализа, аугментация с помощью автоматического распознавания речи (ASR) покрывает 19.7% сложных задач, а использование комбинации инструментов — еще 14.7%. Такая архитектура открывает значительные возможности для создания приложений реального времени, особенно в областях, требующих мгновенной реакции и обработки данных, таких как системы помощи людям с ограниченными возможностями и решения для Интернета вещей (IoT), где быстрая и эффективная обработка аудиосигналов является ключевым фактором.
Исследование представляет собой элегантную попытку обойти ограничения традиционных систем, применяя принцип последовательного уточнения — от грубой оценки к детальному анализу. Этот подход, как и многие прорывные идеи, напоминает внутренний «exploit of insight», когда неопределенность рассеивается благодаря итеративному процессу. В духе этого, Джон фон Нейманн однажды сказал: «В науке не бывает абсолютной точности, только степени вероятности». CoFi-Agent, за счет адаптивной фильтрации и выборочной передачи запросов в облако, демонстрирует, что эффективное решение сложных задач часто кроется не в грубой силе, а в умении правильно расставить приоритеты и сосредоточиться на ключевых аспектах, подобно тому, как решаются задачи в реверс-инжиниринге системы.
Куда же дальше?
Представленная архитектура CoFi-Agent, безусловно, представляет собой шаг к более разумным и эффективным системам обработки звука на периферии. Однако, как всегда, решение одной задачи неизбежно выявляет новые грани нерешенных проблем. Вопрос не в том, насколько хорошо система справляется с определенными запросами, а в том, как она адаптируется к хаосу непредсказуемых акустических ландшафтов. По сути, это всегда игра в «угадайку» с более сложными правилами.
Очевидным направлением дальнейших исследований является расширение спектра инструментов, доступных агенту. Простое «уточнение» запроса недостаточно. Необходимо исследовать возможность использования инструментов, способных к генерации альтернативных интерпретаций, к самопроверке, к построению контр-аргументов. Система должна не просто отвечать на вопросы, а сомневаться в своих ответах. Иначе это всего лишь сложный эхолот, а не разумный агент.
Наконец, стоит признать, что сохранение акустической приватности — это лишь одна сторона медали. Более глубокий вопрос заключается в этике использования таких систем. Кто определяет, какие запросы «неопределенные» и требуют эскалации? Кто контролирует инструменты, используемые для «уточнения»? В конечном счете, самое интересное — это не сама технология, а те скрытые механизмы власти, которые она неизбежно обнажает.
Оригинал статьи: https://arxiv.org/pdf/2601.15676.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Робот-исследователь: новый подход к автономной навигации
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
2026-01-26 04:09