Автор: Денис Аветисян
Новая система прямого преобразования речи в речь позволяет переводить языки, точно воссоздавая индивидуальные особенности голоса говорящего.
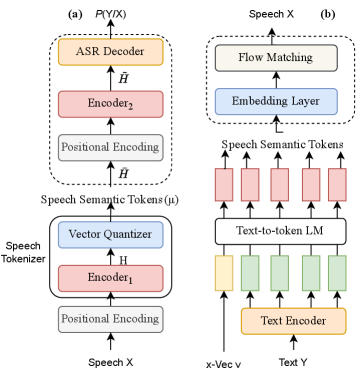
Исследователи представили DS22ST-LM — систему прямого перевода речи в речь, основанную на больших языковых моделях и семантических токенах, обеспечивающую контроль над тембром и расширяемую на несколько языковых пар.
Несмотря на значительный прогресс в машинном переводе речи, прямые системы преобразования речи в речь (S2ST) по-прежнему сталкиваются с проблемами стабильности и масштабируемости. В данной работе, посвященной теме ‘Timbre-Aware LLM-based Direct Speech-to-Speech Translation Extendable to Multiple Language Pairs’, представлена новая архитектура DS2ST-LM, использующая большие языковые модели и семантические токены для прямого перевода речи. Эксперименты показали, что предложенный подход превосходит традиционные каскадные системы и обеспечивает сохранение тембра голоса, расширяя возможности многоязыкового перевода на такие языки, как французский, немецкий, хинди и другие. Каким образом дальнейшее развитие моделей семантического представления речи и контроля над характеристиками голоса может привести к созданию еще более естественных и эффективных систем S2ST?
Каскады и их ограничения: Почему традиционный перевод речи устарел
Традиционные системы речевого перевода (S22ST) функционируют на основе последовательного конвейера, состоящего из автоматического распознавания речи (ASR), машинного перевода (MT) и синтеза речи (TTS). Каждый этап этого процесса подвержен ошибкам, которые, накапливаясь, приводят к снижению точности и естественности перевода. Например, неточность распознавания на этапе ASR может привести к неправильной интерпретации смысла, что, в свою очередь, повлияет на качество машинного перевода. Кроме того, последовательная обработка каждого компонента конвейера создает значительную задержку, что делает перевод менее оперативным и затрудняет взаимодействие в реальном времени. Таким образом, архитектура, основанная на конвейере, представляет собой ключевое ограничение для достижения плавного и точного речевого перевода.
Каскадные системы речевого перевода, состоящие из последовательных этапов распознавания, машинного перевода и синтеза речи, зачастую испытывают трудности с передачей тонкостей просодии и индивидуальных характеристик говорящего. В результате переведенная речь может звучать неестественно, лишенной интонационных акцентов и тембральных особенностей, присущих оригинальному высказыванию. Это связано с тем, что каждый этап обработки вносит собственные искажения, а сложность сохранения и воспроизведения просодических характеристик при последовательном преобразовании сигнала представляет собой значительную техническую проблему. Потеря нюансов, связанных с эмоциональной окраской, ритмом и темпом речи, негативно влияет на восприятие и понимание переведенного сообщения, снижая его естественность и выразительность.
Поддержание и оптимизация каждого звена в каскадной системе автоматического речевого перевода представляет собой сложную инженерную задачу. Необходимость индивидуальной настройки и постоянного совершенствования компонентов автоматического распознавания речи, машинного перевода и синтеза речи требует значительных вычислительных ресурсов и квалифицированных специалистов. Каждый модуль подвержен собственным ошибкам и ограничениям, что усугубляется взаимодействием между ними. Постоянное отслеживание производительности, выявление узких мест и внесение корректировок в каждый компонент — это непрерывный процесс, требующий значительных затрат времени и усилий. С ростом объемов данных и усложнением языковых моделей, сложность поддержания и оптимизации каскадных систем только возрастает, подчеркивая потребность в более эффективных подходах к автоматическому речевому переводу.
DS22ST-LM: Прямой путь к качественному переводу речи
Архитектура DS22ST-LM представляет собой принципиально новый подход к машинному переводу речи, осуществляя прямое преобразование аудиосигнала в речь на целевом языке без промежуточной стадии текстовой транскрипции. Традиционные системы обычно полагаются на распознавание речи с последующим машинным переводом текста, что вносит дополнительные ошибки и задержки. DS22ST-LM, напротив, позволяет избежать этих проблем, обрабатывая аудиопоток напрямую и генерируя речевой выход, что потенциально повышает точность и скорость перевода, а также снижает вычислительную сложность.
В основе системы DS22ST-LM лежит кодировщик Whisper, преобразующий входной аудиосигнал в векторные представления признаков. Этот кодировщик, предварительно обученный на обширном наборе данных, обеспечивает высокую устойчивость к шумам и вариациям в речи, а также точность извлечения лингвистически значимых характеристик. В результате, система получает надежный и информативный входной сигнал для последующего этапа семантического перевода, минимизируя влияние акустических помех и обеспечивая стабильную работу даже в сложных акустических условиях.
В основе системы DS22ST-LM лежит большая языковая модель Qwen22, выполняющая функцию основного движка перевода. Она преобразует признаки, полученные от кодировщика Whisper, в последовательность семантических токенов. Эти токены представляют собой сжатое, но информативное представление смысла исходной речи, позволяющее модели Qwen22 эффективно выполнять перевод без необходимости промежуточного текстового представления. Использование семантических токенов повышает точность и скорость перевода, а также обеспечивает сохранение нюансов и контекста исходного высказывания.
В DS22ST-LM для синтеза речи используется тембро-контролируемый вокодер, обеспечивающий генерацию естественного звучания с возможностью управления характеристиками голоса. Данный вокодер позволяет сохранять индивидуальные особенности тембра, что обеспечивает узнаваемость голоса в синтезированной речи. Это достигается путем контроля параметров, определяющих акустические характеристики звука, таких как спектральная огибающая и форманты, что позволяет создавать синтезированную речь, максимально приближенную к голосу говорящего.
Проверка на прочность: Данные и оценка качества DS22ST-LM
Производительность системы DS22ST-LM значительно повышается за счет использования масштабных наборов данных, в частности GigaS22S-1000, предоставляющего 1000 часов выровненных речевых данных для обучения. Объем и качество данных GigaS22S-1000 позволяют модели эффективно обучаться и обобщать знания, что критически важно для достижения высокой точности и естественности синтезированной речи. Выравнивание данных гарантирует соответствие между речью и текстом, что необходимо для эффективного обучения моделей преобразования речи в речь и наоборот.
Для повышения разнообразия обучающих данных и обеспечения устойчивости работы вокодера в системе DS22ST-LM используется синтез речи на основе XTTS-v2. Данная технология позволяет генерировать искусственные образцы речи с различными характеристиками, дополняя реальные записи и расширяя охват акустических признаков. Это особенно важно для улучшения обобщающей способности модели и повышения её производительности при работе с новыми голосами и акцентами, а также для компенсации недостатка данных в определенных сегментах акустического пространства.
Для оценки качества перевода в системе DS22ST-LM используется комплекс метрик, включающий BLEU, METEOR, BLEURT и COMET. BLEU и METEOR оценивают точность соответствия с эталонными переводами, фокусируясь на n-граммах и синонимах, соответственно. BLEURT и COMET, в свою очередь, используют более сложные модели машинного обучения для оценки семантического соответствия и общей качества перевода, учитывая контекст и смысл предложения. Применение нескольких метрик позволяет получить всестороннюю оценку качества перевода, охватывая как лексическую точность, так и семантическую адекватность.
Система DS22ST-LM демонстрирует превосходство в сохранении характеристик голоса, достигая показателя схожести голосов 0.83. В ходе сравнительного анализа, системы TransVIP, DA-Speech, Translatotron22 и Translatotron показали результаты 0.40, 0.37, 0.43 и 0.32 соответственно. Данный результат указывает на значительное улучшение в способности DS22ST-LM воспроизводить тембр и индивидуальные особенности голоса говорящего по сравнению с существующими решениями.
Оценка перцептивного качества синтезированной речи проводилась с использованием метрики DNSMOS, которая позволяет количественно оценить субъективное восприятие естественности звучания. Система DS22ST-LM достигла показателя в 3.54 балла по DNSMOS, что демонстрирует высокую степень приближения к качеству эталонной (ground truth) аудиозаписи, получившей оценку 3.86. Данный результат свидетельствует о том, что система генерирует речь, воспринимаемую слушателями как достаточно естественная и близкая к человеческой.
За горизонтом: Многоязычность и перспективы развития DS22ST-LM
Система DS22ST-LM продемонстрировала впечатляющие результаты на различных многоязычных наборах данных, включая Seamless-Align, CVSS и Bhasaanuvaad. Эти тесты подтверждают способность системы эффективно обрабатывать и переводить речь на нескольких языках, обеспечивая высокую точность и понятность. Особенно примечательно, что система успешно справляется с задачами, требующими понимания нюансов и контекста в различных лингвистических средах. Такая производительность открывает перспективы для создания более доступных и инклюзивных коммуникационных технологий, позволяющих преодолевать языковые барьеры и способствовать глобальному взаимодействию.
Исследование посвящено оптимизации процесса преобразования речевых представлений в формат, понятный большим языковым моделям (LLM). Для этого были изучены различные методы проецирования, включая линейное проецирование, проецирование Q-Former и комбинированный подход Conv1D-линейного проецирования. Каждый из этих методов направлен на эффективное отображение акустических признаков речи в семантическое пространство, необходимое для LLM. Эксперименты показали, что выбор метода проецирования существенно влияет на качество получаемого представления и, как следствие, на производительность системы в задачах распознавания и перевода речи. Особое внимание уделялось поиску баланса между вычислительной сложностью и точностью преобразования, что критически важно для практического применения разработанной технологии.
Данное исследование открывает новые перспективы для преодоления языковых барьеров и создания более естественной коммуникации между людьми. Разработанные технологии позволяют приблизиться к ситуации, когда язык не является препятствием для понимания и обмена информацией, способствуя тем самым углублению международного сотрудничества и взаимопонимания. Возможность беспрепятственного обмена идеями и знаниями, вне зависимости от лингвистической принадлежности, может значительно ускорить прогресс в различных областях — от науки и технологий до культуры и образования, формируя более сплоченное и информированное глобальное сообщество.
Дальнейшие исследования направлены на оптимизацию системы, с акцентом на снижение вычислительных затрат, что позволит использовать её на более широком спектре устройств. Особое внимание уделяется повышению устойчивости к шумам и помехам, характерным для реальных условий использования, для обеспечения надёжной работы в различных акустических средах. Кроме того, планируется изучение возможностей персонализации, чтобы адаптировать систему к индивидуальным особенностям речи и предпочтениям пользователей, что значительно улучшит пользовательский опыт и сделает взаимодействие более естественным и интуитивно понятным.
Исследование демонстрирует, как легко элегантные архитектуры сталкиваются с реальностью. DS22ST-LM, с его акцентом на семантические токены и контроль тембра, кажется почти изящным решением задачи прямого преобразования речи. Но, как показывает опыт, любой «state-of-the-art» алгоритм рано или поздно столкнется с неожиданным акцентом, шумом на линии или просто желанием пользователя говорить быстрее. Как говорил Джон Дьюи: «Образование — это не подготовка к жизни; образование — это сама жизнь». В данном случае, развитие моделей перевода речи — это непрерывный процесс адаптации к хаосу реального мира, а не достижение идеальной, статичной системы. И, конечно, багтрекер рано или поздно заполнится отчётами о новых «особенностях».
Что дальше?
Представленная работа, безусловно, добавляет ещё один слой абстракции между исходным сигналом и неизбежным хаосом его воспроизведения. Эта «осознанность тембра» — любопытный штрих, но, как показывает опыт, любые попытки контролировать неконтролируемое лишь усложняют процесс отладки. Когда система начнёт переводить с акцентом, имитирующим сломанный динамик, тогда можно будет говорить о настоящем прогрессе. А пока — это всего лишь ещё один компонент, который рано или поздно придёт в негодность.
Разумеется, расширение до нескольких языковых пар — это хорошо, но истинный вызов — не в количестве поддерживаемых языков, а в способности системы сохранять хоть какую-то связность при переводе с языка, о котором никто толком не знает. Впрочем, документацию на этот случай наверняка уже пишут — форма коллективного самообмана, как известно, необходима на любом этапе разработки.
И, напоследок, стоит отметить, что если баг воспроизводится стабильно — значит, у нас стабильная система. Это фундаментальный принцип, который, к сожалению, часто забывают. А «самовосстановление» — это просто означает, что поломка ещё не произошла. Ждём с нетерпением первой крупной миграции и последующего апокалипсиса.
Оригинал статьи: https://arxiv.org/pdf/2601.16023.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
2026-01-26 05:52