Автор: Денис Аветисян
Новое исследование представляет DeepSurvey-Bench — инструмент для оценки академической значимости научных опросов, генерируемых искусственным интеллектом.

DeepSurvey-Bench позволяет комплексно оценивать информативность, качество коммуникации и полезность сгенерированных опросов для научных исследований.
Существующие подходы к оценке автоматически генерируемых научных обзоров часто полагаются на поверхностные метрики, упуская из виду их реальную академическую ценность. В данной работе представлена новая методика оценки, реализованная в виде эталонного набора данных DeepSurvey-Bench: Evaluating Academic Value of Automatically Generated Scientific Survey, предназначенная для всесторонней проверки качества генерируемых обзоров. Предложенный подход оценивает информационную ценность, коммуникативную значимость и практическую направленность обзора, формируя надежный набор данных с аннотациями академической ценности. Позволит ли эталонный набор данных DeepSurvey-Bench продвинуть разработку систем автоматического создания научных обзоров, способных предоставлять действительно полезную и глубокую аналитику?
Основы автоматизированного анализа: вызовы и перспективы
Создание высококачественных научных обзоров является краеугольным камнем прогресса в любой области знания, однако традиционно этот процесс требует колоссальных затрат времени и усилий экспертов. Тщательный анализ существующей литературы, выявление ключевых тенденций и пробелов, а также структурирование информации в логичный и всеобъемлющий обзор — задачи, которые ранее полностью ложились на плечи исследователей. Этот ручной подход, несмотря на свою эффективность в руках опытных ученых, имеет ряд ограничений, включая высокую стоимость, трудоемкость и зависимость от индивидуальных знаний и предубеждений. В результате, даже самые необходимые обзоры могут задерживаться, ограничивая возможности для быстрого распространения новых знаний и выявления перспективных направлений исследований. Подобная ситуация подчеркивает острую необходимость в разработке автоматизированных методов, способных облегчить и ускорить процесс создания научных обзоров, сохраняя при этом высокое качество и объективность.
Существующие методы синтеза научных знаний часто оказываются в затруднительном положении, пытаясь охватить широкий спектр информации, не жертвуя при этом глубиной анализа. Как следствие, многие обзоры и мета-анализы, несмотря на свою обширность, дают лишь поверхностное понимание исследуемой проблемы. Стремление к максимальному охвату приводит к упрощению сложных взаимосвязей и недостаточному вниманию к нюансам, что снижает ценность полученных выводов. В результате, научное сообщество сталкивается с проблемой переизбытка информации, которая не всегда приводит к реальному прогрессу в понимании ключевых вопросов, а скорее создает иллюзию всестороннего анализа, не подкрепленную достаточной аналитической проработкой.
В настоящее время потребность в масштабируемых, автоматизированных методах создания обзоров научной литературы становится все более актуальной. Традиционные подходы, требующие значительных временных затрат экспертов, не успевают за экспоненциальным ростом научных публикаций. Автоматизация позволяет охватить гораздо больший объем информации, выявляя закономерности и тенденции, которые могли бы остаться незамеченными при ручном анализе. Важно, чтобы такие автоматизированные системы не просто компилировали данные, а действительно способствовали углублению научного понимания, выявляя пробелы в знаниях и формулируя новые исследовательские вопросы. Разработка подобных инструментов является ключевым шагом к ускорению научного прогресса и эффективному использованию накопленных знаний.

Механизмы генерации: расширяя горизонты автоматизации
Современные системы автоматической генерации опросов используют такие методы, как Retrieval-Augmented Generation (RAG) и многодокументное суммирование для сбора и синтеза информации. RAG предполагает динамический поиск релевантных знаний из внешних источников в процессе генерации, что позволяет создавать более точные и контекстуально уместные вопросы. Многодокументное суммирование позволяет извлекать ключевую информацию из большого количества документов, что особенно полезно при создании опросов, требующих широкого охвата предметной области. Эти подходы отличаются от традиционных методов, которые полагаются на заранее заданные шаблоны и ограниченные наборы данных, обеспечивая более гибкую и адаптивную генерацию контента.
В отличие от традиционных методов генерации опросов, использующих статичные базы знаний, современные системы применяют динамический поиск релевантной информации непосредственно в процессе создания вопросов. Это достигается за счет интеграции механизмов извлечения знаний (например, поиск по базам данных, научным публикациям или специализированным корпусам текстов) и последующего использования полученных данных для формирования более точных и актуальных вопросов. Динамическое извлечение знаний позволяет учитывать контекст запроса, избегать устаревшей информации и генерировать вопросы, более точно отражающие текущее состояние изучаемой области, что существенно повышает релевантность и достоверность получаемых ответов.
Различные платформы автоматической генерации опросов, такие как SurveyX, AutoSurvey и SurveyForge, применяют специализированные подходы для адаптации к конкретным научным областям. SurveyX ориентирован на медицинские исследования, используя онтологии и базы данных медицинских знаний для создания релевантных вопросов. AutoSurvey специализируется на социологических и психологических исследованиях, применяя методы анализа больших объемов текстовых данных и выявления ключевых тем. SurveyForge, в свою очередь, предназначен для инженерных и технических дисциплин, используя техническую документацию и стандарты для генерации вопросов, ориентированных на оценку знаний и навыков в конкретной области. Каждая платформа использует уникальные алгоритмы и источники данных для повышения точности и релевантности генерируемых опросов.
Количественная оценка академической ценности: эталон DeepSurvey-Bench
DeepSurvey-Bench представляет собой новый эталон для всесторонней оценки академической ценности автоматизированных опросов. Эталон состоит из набора данных, включающего 163 высококачественных, академически аннотированных опроса, содержащих в общей сложности 8715 разделов структуры и 5692 непосредственно цитируемых источника. Ключевой особенностью является высокая степень соответствия результатов, полученных с помощью эталона, оценкам, данным экспертами-людьми. Подтверждено достижение коэффициента Коэна κ = 0.76 для согласованности между аннотаторами, что указывает на существенное согласие между экспертами, а также сильная корреляция между оценками, полученными с помощью больших языковых моделей (LLM) и людьми, что подтверждает валидность предложенного подхода к оценке.
Оценка поверхностного качества является основой предложенной системы, включающей в себя анализ качества структуры, содержания и ссылок. Оценка качества структуры (Outline Quality) фокусируется на логической организации и иерархии информации в обзоре. Качество содержания (Content Quality) оценивает точность, полноту и ясность представленных данных. Оценка качества ссылок (Reference Quality) проверяет корректность цитирования источников и соответствие цитат представленному содержанию. Комбинация этих трех оценок позволяет установить базовый уровень структурной и презентационной строгости, необходимый для всесторонней оценки академической ценности автоматизированных обзоров.
Оценка академической ценности в DeepSurvey-Bench осуществляется с использованием как устоявшихся метрик, так и инновационных подходов. Традиционные метрики, такие как ROUGE и BLEU, применяются для оценки совпадения текста и качества перевода, соответственно. Кроме того, используется Heading Soft Recall (HSR) — метрика, оценивающая полноту и точность отражения ключевых тем в заголовках. Для получения более детальной оценки, применяется подход LLM-as-a-Judge, использующий большие языковые модели в качестве экспертов для оценки качества и релевантности контента, что позволяет выявить нюансы, которые могут быть упущены при использовании только автоматических метрик.
Для проведения оценки автоматизированных опросов был создан эталонный набор данных, состоящий из 163 высококачественных академических опросов, прошедших ручную аннотацию. Этот набор данных включает в себя в общей сложности 8715 разделов структуры опросов и 5692 непосредственно указанных ссылок на источники. Большой объем и качество аннотированных данных обеспечивают надежную основу для количественной оценки академической ценности и позволяют проводить статистически значимые сравнения различных подходов к автоматизации опросов.
Для оценки надежности разработанной системы оценки академической ценности, была проведена оценка согласованности между несколькими аннотаторами-людьми. Полученный коэффициент Коэна κ = 0.76 указывает на существенное согласие между оценками, что подтверждает стабильность и объективность методики. Кроме того, была установлена высокая корреляция между оценками, полученными с использованием языковой модели (LLM) в качестве эксперта, и оценками, данными людьми, что дополнительно валидирует предложенный подход и подтверждает возможность автоматизированной оценки академического качества.
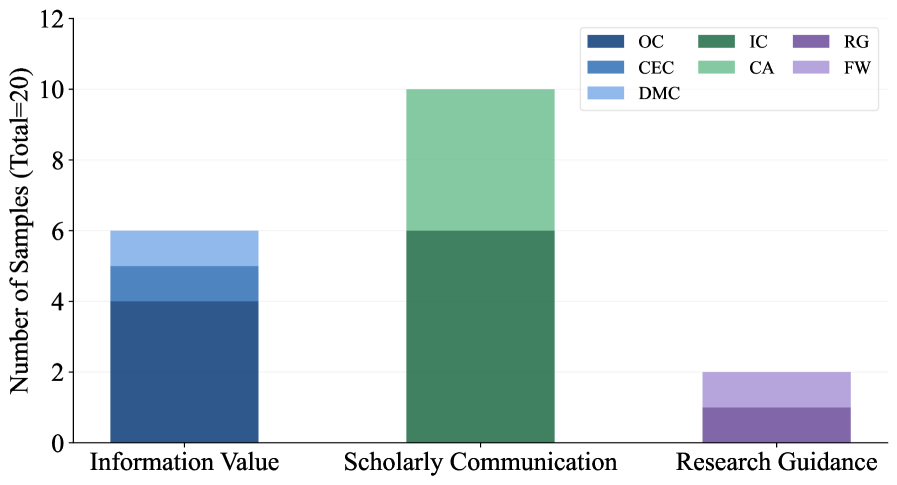
Оценка академической ценности в данном фреймворке строится на трех ключевых измерениях: информационная ценность (Information Value), отражающая полноту и точность представленной информации; ценность академической коммуникации (Scholarly Communication Value), определяющая ясность и структурированность изложения для обеспечения эффективного обмена знаниями; и ценность для руководства исследованиями (Research Guidance Value), характеризующая способность материала направлять дальнейшие научные изыскания. Совместное рассмотрение этих трех аспектов обеспечивает всестороннюю и объективную оценку академической значимости оцениваемых материалов.
Представленный труд демонстрирует стремление к оценке не только формальных аспектов научных опросов, но и их фактической ценности для развития исследований. Это созвучно взглядам Винтона Серфа, который однажды заметил: «Время — не метрика, а среда, в которой существуют системы». DeepSurvey-Bench, как новый эталон оценки, позволяет рассматривать научные опросы не как статичные инструменты, а как элементы динамичной исследовательской экосистемы. Подобно тому, как системы стареют, научные вопросы требуют постоянной переоценки и адаптации, а данный подход подчеркивает необходимость учитывать исторический контекст и эволюцию научных знаний для обеспечения их долгосрочной значимости.
Куда же дальше?
Представленный здесь DeepSurvey-Bench — не финал, а скорее очередной коммит в летописи автоматической генерации научных опросов. Каждая версия, от простейших шаблонов до сложных языковых моделей, несет в себе отпечаток времени и амбиций создателей. И, как известно, задержка с исправлением ошибок — это неизбежный налог на эти самые амбиции. Оценка академической ценности, как показала работа, выходит далеко за рамки поверхностных метрик, требуя анализа информационной ценности и способности опроса направлять научный поиск.
Очевидным направлением для дальнейших исследований является разработка более тонких критериев оценки, учитывающих контекст конкретной научной дисциплины. Более того, следует изучить возможность автоматической адаптации опросов к различным уровням подготовки респондентов. Система, которая способна генерировать опрос как для аспиранта, так и для студента-первокурсника, — вот истинная задача.
Однако, следует помнить: любая система стареет. И вопрос не в том, как избежать этого процесса, а в том, чтобы обеспечить ей достойное старение. Необходимо заложить в основу разработки возможность эволюции, самообучения и адаптации к меняющимся требованиям научного сообщества. Ведь время — это не метрика, а среда, в которой существуют системы, и в которой они неизбежно меняются.
Оригинал статьи: https://arxiv.org/pdf/2601.15307.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
2026-01-26 05:58