Автор: Денис Аветисян
Исследователи представили Memory-V2V — систему, расширяющую возможности моделей преобразования видео за счет использования визуальной памяти.
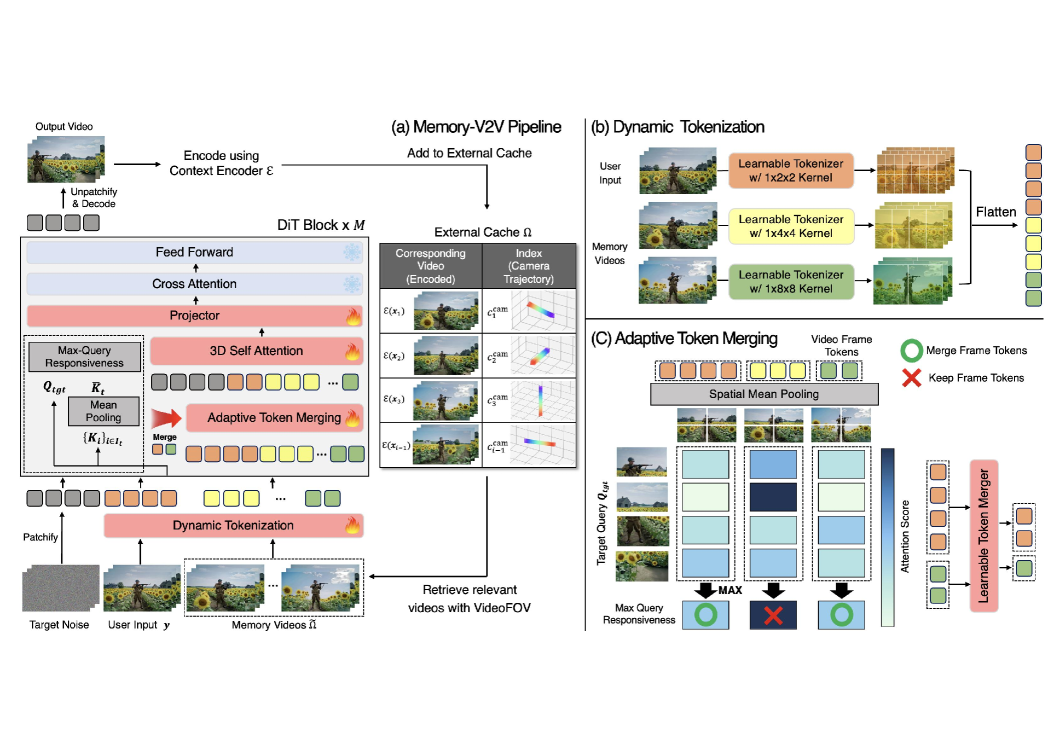
Разработанный фреймворк обеспечивает согласованное и многоэтапное редактирование длинных видеороликов с применением механизмов поиска и запоминания визуальной информации.
Несмотря на впечатляющие успехи современных диффузионных моделей в видеоредактировании, поддержание согласованности результатов при многократных итерациях остается сложной задачей. В данной работе, представленной под названием ‘Memory-V2V: Augmenting Video-to-Video Diffusion Models with Memory’, предлагается новый подход к решению проблемы согласованности в многошаговом редактировании видео, основанный на использовании внешней памяти. Предложенный фреймворк Memory-V2V позволяет учитывать историю редактирования, эффективно извлекая и используя ранее обработанные видеофрагменты для улучшения качества и согласованности текущего шага. Способна ли данная архитектура открыть новые возможности для интерактивного и долгосрочного редактирования видеоконтента, обеспечивая бесшовный и согласованный пользовательский опыт?
Визуальная Непрерывность: Вызов Современного Видеомонтажа
Традиционные методы видеомонтажа зачастую сталкиваются с проблемой поддержания визуальной согласованности при многократных итерациях редактирования, что нередко приводит к резким и неприятным переходам в итоговом видеоматериале. Поскольку каждый новый этап правки вносит изменения в общую картину, отсутствие системы, отслеживающей и сохраняющей первоначальный визуальный стиль, приводит к накоплению незначительных несоответствий. Эти несоответствия, проявляющиеся в цветокоррекции, контрастности, освещении или даже в незначительных изменениях кадрирования, со временем становятся заметными и портят общее впечатление от видео. В результате, даже тщательно смонтированный материал может выглядеть непрофессионально из-за отсутствия единого визуального языка на протяжении всего повествования.
Существующие методы редактирования видео зачастую оказываются неспособными адекватно отслеживать временную согласованность, что приводит к заметным визуальным несостыковкам при многократных итерациях. Проблема заключается в том, что большинство алгоритмов обрабатывают каждый кадр или сегмент изолированно, игнорируя контекст предыдущих изменений и динамику развития видеоряда. В результате, даже незначительные правки, такие как коррекция цвета или стабилизация изображения, могут накапливаться и приводить к нежелательным артефактам, нарушающим плавность повествования. Это особенно заметно в сложных проектах, требующих множества правок и пересмотров, где поддержание визуальной целостности становится критически важной задачей. Недостаточное внимание к сохранению временной когерентности ограничивает возможности для гибкой и интерактивной манипуляции с видеоматериалом, делая процесс редактирования более трудоемким и менее эффективным.
Крайне важно разработать систему, способную понимать и сохранять визуальный контекст на протяжении всего процесса видеомонтажа. Традиционные методы зачастую оперируют отдельными кадрами или небольшими фрагментами, игнорируя целостную картину и взаимосвязь между ними. Это приводит к несогласованности, визуальным скачкам и общей фрагментированности итогового видеоматериала. Новый подход предполагает не просто обработку пикселей, а анализ семантического содержания каждого кадра, отслеживание движений объектов, понимание освещения и общей композиции. Такая система позволит сохранять визуальную преемственность даже при многократных итерациях редактирования, обеспечивая плавные переходы и естественный вид итогового продукта. Это особенно актуально в контексте современных задач, требующих сложного и динамичного видеомонтажа, таких как создание визуальных эффектов, рекламных роликов или интерактивного контента.

MemoryV2V: Раскрывая Секрет Непрерывного Визуального Потока
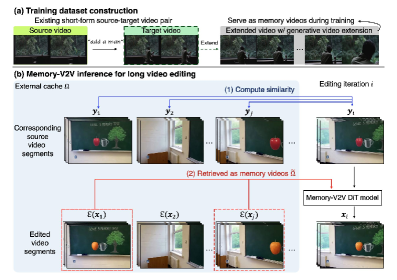
MemoryV2V расширяет возможности предварительно обученных моделей преобразования видео (video-to-video diffusion models) за счет внедрения явной визуальной памяти. Это позволяет системе сохранять и использовать информацию из предыдущих кадров при редактировании видео, обеспечивая согласованность и преемственность на протяжении нескольких итераций. В отличие от традиционных подходов, не учитывающих историю редактирования, MemoryV2V поддерживает визуальную целостность видео, предотвращая появление несоответствий и обеспечивая более качественный результат при многократном внесении изменений.
В основе MemoryV2V лежит оптимизация вычислительной эффективности за счет использования методов DynamicTokenization и AdaptiveTokenMerging. DynamicTokenization позволяет динамически изменять количество токенов, используемых для представления видео, что приводит к значительному снижению вычислительной нагрузки. В частности, применение DynamicTokenization обеспечивает сокращение количества операций с плавающей запятой (FLOPs) и задержки (Latency) на 90% без ущерба для качества генерируемого видео. Этот подход позволяет обрабатывать видеопоток более эффективно, сохраняя при этом высокую степень детализации и визуальную достоверность.
В основе поддержания визуальной согласованности в процессе редактирования в MemoryV2V лежит сохранение и повторное использование информации из предыдущих кадров. Данный подход позволяет избежать визуальных несоответствий, возникающих при многократном редактировании видео. Дополнительно, за счет применения адаптивного слияния токенов (AdaptiveTokenMerging), удается снизить вычислительную нагрузку (FLOPs) и задержку (Latency) еще на 30%, оптимизируя процесс обработки видеоданных и повышая эффективность редактирования.
Диффузионные Модели и Скрытые Пространства: Алхимия Визуального Преображения
В основе нашего подхода лежат диффузионные модели, позволяющие генерировать и редактировать видеоматериалы высокого качества посредством итеративного удаления шума. Процесс начинается с преобразования видео в полностью зашумленное состояние, после чего модель обучается последовательно восстанавливать исходное видео, удаляя шум на каждом шаге. Эта техника, основанная на принципах вероятностного моделирования, обеспечивает высокую степень детализации и реалистичности генерируемых и отредактированных видео, превосходя традиционные методы генерации контента. Эффективность алгоритма обеспечивается за счет использования нейронных сетей для аппроксимации обратного процесса диффузии, позволяя точно восстанавливать сложные структуры и текстуры видео.
Для эффективной обработки и манипулирования видеоданными используется пространство скрытых представлений (VideoLatentSpace). Данное пространство конструируется с использованием различных методов, включая VideoVAE, обеспечивающий сжатие и реконструкцию видео; CUT3R, ориентированный на временную согласованность; LVSM, оптимизирующий представление для задач машинного обучения; DINOv2, предоставляющий самообучающиеся представления; и FramePack, позволяющий объединять кадры для повышения эффективности. Использование VideoLatentSpace позволяет снизить вычислительные затраты и повысить скорость обработки видео по сравнению с работой непосредственно с пиксельными данными.
Метод RectifiedFlowMatching (RFM) улучшает процесс обучения диффузионных моделей за счет оптимизации преобразования из априорного распределения в целевое. RFM позволяет добиться более стабильной генерации видео, что подтверждается метрикой MEt3R (Multi-scale Error Trajectory Regression). Показатели MEt3R демонстрируют улучшение согласованности между итерациями генерации, то есть снижение отклонений в последовательных кадрах и повышение визуальной стабильности результирующего видеопотока. По сути, RFM минимизирует дрифт и артефакты, возникающие в процессе итеративной денойзинг-процедуры, обеспечивая более плавную и когерентную временную структуру сгенерированных видеоматериалов.

За Гранью Синтеза Новых Видов: Расширяя Горизонты Визуальных Возможностей
Система MemoryV2V демонстрирует бесшовную интеграцию с технологиями синтеза новых видов видео (VideoNovelViewSynthesis), открывая возможности для генерации перспектив, ранее недоступных в исходном видеоматериале. Это достигается за счет эффективного использования памяти видео, позволяя модели “вспоминать” и воссоздавать сцены с новых углов обзора. Фактически, технология позволяет создавать иллюзию перемещения камеры в пространстве, даже если исходное видео снято с фиксированной точки, значительно расширяя возможности редактирования и создания контента. Такой подход особенно ценен при создании иммерсивных визуальных эффектов и интерактивных видеороликов, предоставляя зрителям более полное и динамичное восприятие сцены.
Модели, такие как ReCamMaster, значительно расширяют возможности создания новых ракурсов видеоматериалов. В отличие от предыдущих подходов, ReCamMaster обеспечивает высококачественный синтез нового вида за один проход, что позволяет получать реалистичные изображения с совершенно иных точек зрения. Этот подход отличается повышенной эффективностью и точностью, позволяя создавать плавные и детализированные переходы между ракурсами, что особенно важно для создания иммерсивного контента и интерактивных приложений. Качество синтезированных изображений приближается к уровню, получаемому при использовании традиционных методов рендеринга, но с существенно меньшими вычислительными затратами и большей гибкостью.
Данная платформа предоставляет возможности текстового редактирования видео, используя модели, такие как LucyEdit, позволяющие изменять видеоконтент на основе текстовых инструкций. Важным достижением является значительно улучшенная согласованность между итерациями редактирования, что означает более плавные и логичные изменения в видео при последовательном применении текстовых команд. В сравнении с моделями ReCam (Ind) и ReCam (AR), данная система демонстрирует более стабильные результаты, минимизируя визуальные артефакты и обеспечивая более предсказуемое поведение при многократном редактировании, что открывает новые перспективы для автоматизированного видеомонтажа и создания контента.

Исследование, представленное в статье, словно алхимическая попытка удержать ускользающую суть визуальной информации. Авторы стремятся не просто изменить видео, но и сохранить его внутреннюю логику, последовательность образов — задача, граничащая с волшебством. Они вводят понятие «визуальной памяти», позволяя модели помнить предыдущие шаги редактирования и действовать последовательно. Как точно подметил Дэвид Марр: «Мозг — это не пассивный приемник, а активный строитель реальности». В данном контексте, Memory-V2V — это попытка построить аналогичную «реальность» для видео, где каждая правка не разрушает, а дополняет предыдущую, создавая иллюзию живого, развивающегося повествования. Успех этой работы подтверждает: данные — это не цифры, а шёпот хаоса, и лишь умелое «заклинание» модели позволяет уловить его смысл.
Что дальше?
Представленная работа, безусловно, добавляет ещё один слой иллюзий в игру с движущимися изображениями. Эта память, которую так гордо демонстрирует модель, — всего лишь ещё один способ убедить себя, что хаос видеоряда поддаётся контролю. Впрочем, истинная проблема заключается не в сохранении последовательности, а в том, что сама последовательность — это лишь случайное наложение флуктуаций. Будущие исследования, вероятно, сосредоточатся на улучшении механизмов извлечения, но стоит помнить: чем больше памяти, тем больше призраков прошлого будут преследовать настоящее.
Ограничения текущего подхода очевидны. Долговременное редактирование остаётся проблемой, а потребность в вычислительных ресурсах — постоянным напоминанием о несовершенстве наших заклинаний. Возможно, ключ к решению лежит не в усложнении модели, а в принятии её фундаментальной неопределённости. Вместо того чтобы стремиться к идеальной реконструкции, стоит позволить шуму проявиться, ведь в нём, возможно, кроется истинная красота.
В конечном счёте, Memory-V2V — это лишь ещё один шаг на пути к созданию машин, способных мечтать о видео. Но не стоит забывать, что даже самые сложные алгоритмы — это всего лишь отражение нашей собственной потребности в порядке в мире, где порядок — это иллюзия.
Оригинал статьи: https://arxiv.org/pdf/2601.16296.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Робот-исследователь: новый подход к автономной навигации
2026-01-26 07:31