Автор: Денис Аветисян
Представлена DSGym — комплексная среда, позволяющая всесторонне оценивать и тренировать системы искусственного интеллекта, выполняющие задачи анализа данных.

DSGym — это унифицированная и воспроизводимая платформа для оценки и обучения агентов, специализирующихся на анализе данных, с акцентом на рассуждения, основанные на данных, и предоставляющая стандартизированную среду для строгой оценки и улучшения.
Существующие бенчмарки для оценки агентов, работающих с данными, часто не позволяют достоверно проверить их способность к анализу и интерпретации реальных данных. В данной работе представлена платформа ‘DSGym: A Holistic Framework for Evaluating and Training Data Science Agents’, обеспечивающая стандартизированную среду для оценки и обучения таких агентов, включающая в себя как существующие, так и новые, тщательно отобранные задачи, требующие глубокого понимания данных. DSGym позволяет создавать синтетические наборы данных и верифицировать выполнение анализа, что открывает возможности для разработки и улучшения агентов, способных самостоятельно планировать, реализовывать и валидировать научные исследования. Сможем ли мы, используя DSGym, создать агентов, превосходящих человека в решении сложных задач анализа данных?
Иллюзия Автоматизации: Почему Данные Молчат
Автоматизация рабочих процессов в области анализа данных с использованием LLM-агентов представляется перспективным путем к повышению эффективности, однако существующие оценочные тесты зачастую не отражают реального потенциала. Исследования показывают, что многие задачи решаются не путем полноценного анализа данных, а за счет запоминания ответов на конкретные примеры, что называется «обучением на ярлыках». Такой подход, хоть и демонстрирует высокие результаты в рамках тестов, не обеспечивает надежность и обобщающую способность при работе с новыми, ранее не встречавшимися данными. Это ограничивает возможности полной автоматизации, поскольку агенты не способны к самостоятельному выявлению закономерностей и принятию обоснованных решений в сложных ситуациях, требующих глубокого понимания данных.
Исследования показывают, что автоматизированные системы анализа данных, основанные на больших языковых моделях, часто решают задачи не путём фактического анализа информации, а за счёт запоминания ответов на аналогичные примеры из обучающей выборки. Такое “заучивание”, вместо реального понимания закономерностей в данных, существенно ограничивает возможности полноценной автоматизации. Вместо того чтобы выявлять скрытые зависимости и обобщать знания, системы склонны просто воспроизводить заученные паттерны, что приводит к низкой производительности при работе с новыми, незнакомыми данными. Это явление, известное как “shortcut learning”, подрывает доверие к автоматизированным решениям и требует разработки более надёжных методов оценки и обучения, способных отличать истинный анализ данных от простого запоминания.
Отсутствие воспроизводимости и стандартизированной оценки существенно осложняет разработку и внедрение агентов для автоматизации анализа данных. Исследования показывают, что при фильтрации “ярлыков” — ситуаций, когда агент решает задачу, запоминая ответ вместо проведения анализа — наблюдается снижение производительности до 21%. Данный эффект указывает на то, что существующие метрики часто не отражают реальную способность агента к обобщению и адаптации к новым данным, подчеркивая необходимость более строгих методов оценки, учитывающих зависимость от исходной информации и исключающих возможность решения задач путем простого запоминания.
DSGym: Платформа для Проверки на Прочность
DSGym представляет собой унифицированную и воспроизводимую платформу для обучения и оценки агентов, работающих с данными. Она обеспечивает согласованность результатов благодаря стандартизации процесса экспериментов и автоматизации этапов обучения и тестирования. Это достигается путем определения четкого интерфейса для агентов и среды, а также предоставления инструментов для логирования и отслеживания метрик производительности. В рамках платформы реализована система версионирования, позволяющая точно воспроизвести эксперименты в будущем, независимо от изменений в программном окружении или данных. Ключевым аспектом является возможность запуска экспериментов в различных вычислительных средах без необходимости внесения изменений в код агента.
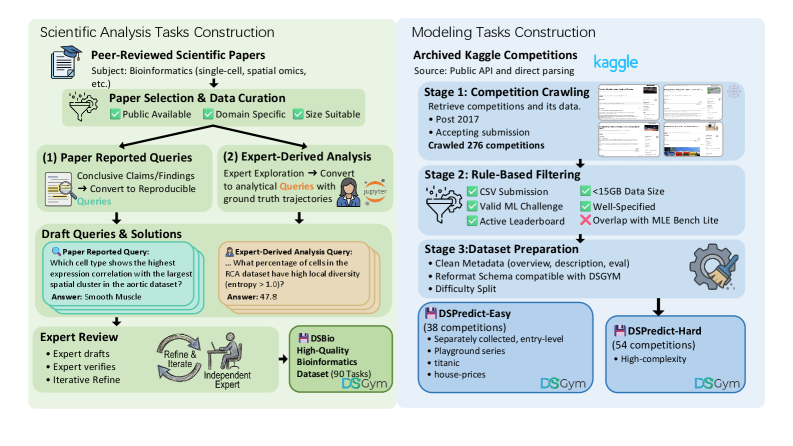
В основе DSGym лежит тщательно отобранная коллекция задач (DSGym-Tasks), подвергнутая строгой проверке для исключения задач, решаемых без доступа к данным. Этот процесс аудита направлен на обеспечение того, чтобы оценка агентов действительно требовала анализа и обработки данных, а не полагалась на тривиальные решения, не требующие использования данных. Каждая задача в DSGym-Tasks проходит несколько этапов проверки, включая ручной анализ и автоматизированные тесты, для подтверждения необходимости доступа к данным для получения корректного результата. Это гарантирует, что DSGym предоставляет надежную платформу для оценки способности агентов эффективно работать с данными и извлекать из них полезную информацию.
DSGym использует контейнеризацию, в частности Docker, для обеспечения воспроизводимости экспериментов и единообразия среды выполнения на различных платформах. Это достигается путем инкапсуляции всех необходимых зависимостей — включая библиотеки, инструменты и конфигурацию — внутри контейнера. Такой подход исключает проблемы, связанные с различиями в версиях пакетов или настройках операционной системы, гарантируя, что агент, обученный и протестированный в одной среде, будет функционировать предсказуемо и на других системах, поддерживающих контейнеризацию. Это значительно упрощает процесс развертывания и масштабирования решений, разработанных с использованием DSGym, а также способствует повышению надежности и достоверности результатов оценки.

Разнообразие Задач для Реального Анализа Данных
DSGym включает в себя разнообразные наборы задач, среди которых DSPredict, основанный на соревнованиях Kaggle, и DSBio, полученный из публикаций в области биоинформатики. DSPredict позволяет оценить производительность агентов в задачах, типичных для соревновательного анализа данных, используя реальные наборы данных и метрики оценки, применяемые в Kaggle. DSBio, в свою очередь, представляет собой задачи, связанные с анализом биологических данных, таких как геномика и протеомика, требующие специализированных знаний и методов для их решения. Использование этих двух наборов задач позволяет комплексно оценить способности агентов в различных областях Data Science.
В DSGym, File-Grounded бенчмарки требуют от агентов активного использования предоставленных данных для получения корректных результатов, обеспечивая зависимость от данных. Это означает, что успешное выполнение задач невозможно без анализа и применения информации, содержащейся в файлах, предоставляемых в качестве входных данных. В отличие от бенчмарков, полагающихся на встроенные знания или заранее заданные параметры, File-Grounded бенчмарки акцентируют внимание на способности агента извлекать и использовать информацию непосредственно из данных, имитируя реальные сценарии работы с данными в науке о данных.
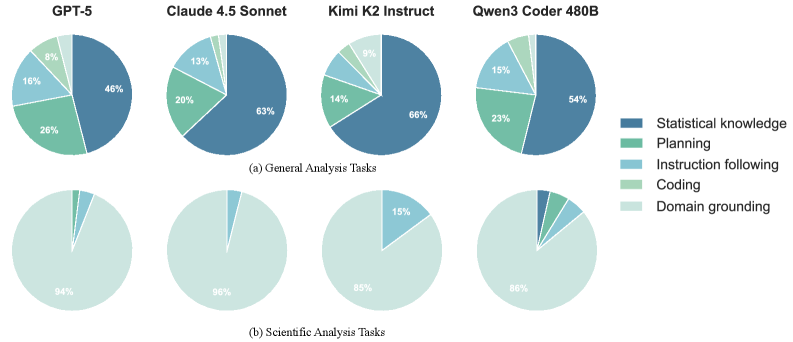
Задачи, реализованные в DSGym, спроектированы для воспроизведения итеративного характера реальных рабочих процессов в области Data Science, требуя от агентов последовательного выполнения этапов очистки, анализа и построения моделей. Особо стоит отметить, что в наборе задач DSBio от 85% до 96% неудач связаны с ошибками предметной области (domain-grounding errors), что указывает на существенную проблему в способности агентов корректно интерпретировать и использовать специализированные знания. Данный факт подчеркивает важность разработки агентов, способных эффективно интегрировать и применять знания предметной области для успешного решения задач анализа данных.
Результаты тестирования на бенчмарке DSPredict показывают, что менее 70% агентов способны предоставить валидные решения. Это свидетельствует о существенных ограничениях в текущих возможностях агентов, даже при решении задач, основанных на данных, взятых из соревнований Kaggle. Низкий процент успешных сборок указывает на трудности в автоматизации процесса Data Science, включая этапы предобработки данных, выбора модели и настройки гиперпараметров, что требует дальнейших исследований и разработок в области автономных агентов для анализа данных.

К Научным Открытиям Через Автоматизированных Агентов
Платформа DSGym активно способствует научным открытиям, предоставляя среду для разработки и оценки агентов, способных извлекать ценную информацию из сложных наборов данных. Эта система позволяет исследователям создавать и тестировать интеллектуальных помощников, предназначенных для автоматизированного анализа и интерпретации результатов экспериментов, поиска закономерностей и выдвижения гипотез. Особенностью DSGym является возможность работы с различными типами данных и поддержка как общедоступных, так и проприетарных языковых моделей, что делает ее универсальным инструментом для широкого спектра научных дисциплин. Благодаря DSGym, процесс научных исследований становится более эффективным и позволяет исследователям сосредоточиться на интерпретации результатов, а не на рутинном анализе данных.
Разработанная платформа DSGym отличается универсальностью в отношении используемых языковых моделей. Она не ограничивается конкретным типом и способна эффективно функционировать как с открытыми моделями, доступными для широкого использования, так и с проприетарными, разработанными конкретными организациями. Эта гибкость позволяет исследователям и разработчикам адаптировать систему под свои нужды, используя наиболее подходящую модель для решения конкретной научной задачи, вне зависимости от её происхождения или лицензионных ограничений. Возможность интеграции различных типов моделей значительно расширяет потенциал платформы и способствует более широкому внедрению автоматизированных агентов в процесс научных открытий.
Процесс генерации обучающих данных посредством выполнения запросов и последующей верификации, известный как Execution-Grounded Data Synthesis, значительно повышает эффективность агентов, используемых для научных открытий. В рамках платформы DSGym, этот подход, реализованный в DSGym-SFT, демонстрирует впечатляющие результаты: модель размером всего 4 миллиарда параметров достигает производительности, сопоставимой с гораздо более крупными моделями. Это свидетельствует о том, что грамотно сгенерированные данные, полученные путем непосредственного взаимодействия с данными и проверки их достоверности, способны компенсировать недостаток вычислительных ресурсов и позволяют создавать эффективные агенты для анализа сложных научных данных даже при ограниченных аппаратных возможностях.
Предыдущие подходы к автоматизированному научному открытию часто демонстрировали существенное снижение эффективности при анализе данных, требующих учета взаимосвязей и зависимостей между ними. Исследования показали, что при фильтрации данных с целью выделения именно тех, которые отражают эти зависимости, наблюдалось снижение производительности на величину до 21%. Данная платформа, напротив, разработана с учетом необходимости анализа сложных взаимосвязей в данных, что позволяет агентам более эффективно извлекать значимую информацию и избегать ошибок, связанных с игнорированием ключевых зависимостей. Такой подход обеспечивает более надежные и точные результаты в процессе автоматического научного поиска.
Исследование представляет собой попытку систематизировать процесс оценки и обучения агентов в области Data Science, что созвучно идеям о необходимости строгой формализации и проверки основ любого знания. Как говорил Давид Гильберт: «В математике нет истины, есть только доказательства». DSGym, создавая стандартизированную среду, стремится обеспечить возможность воспроизводимого анализа и улучшения этих агентов, делая акцент на data-dependent reasoning — то есть, способности агента к обоснованным выводам на основе данных. Это не просто создание инструмента, а проверка самой возможности построения надежной системы анализа данных, где каждый шаг может быть верифицирован и повторен.
Что дальше?
Представленная работа, по сути, обнажает проблему: существующие критерии оценки «разумности» систем анализа данных — это, в лучшем случае, эвристические трюки. DSGym, создавая контролируемую среду, лишь подчеркивает, насколько сильно текущие подходы зависят от конкретного набора данных и насколько легко «интеллект» агента может оказаться иллюзией, привязанной к специфическим особенностям тестовой выборки. Утверждение о «стандартизированной среде» — это вызов, ведь стандарты — это всегда лишь временное ограничение, приглашение к взлому системы.
Очевидно, что будущее исследований лежит в области генерации данных, способных выявлять истинные слабости агентов. Недостаточно создавать синтетические данные; необходимо создавать данные, которые намеренно провоцируют ошибки, обнажают предубеждения и заставляют систему проявлять свою «сущность». Вместо того, чтобы стремиться к универсальному «ИИ«, возможно, стоит сосредоточиться на создании специализированных агентов, способных решать узкий круг задач, но делающих это предсказуемо и надежно.
В конечном счете, DSGym — это не просто инструмент оценки, а приглашение к деконструкции. Это признание того, что «интеллект» — это не нечто данное, а нечто создаваемое, и что любое определение «разумности» — это всегда лишь временная договоренность, подлежащая постоянной проверке и пересмотру. И в этом — ее истинная ценность.
Оригинал статьи: https://arxiv.org/pdf/2601.16344.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Командная работа агентов: обучение без обновления модели
- Квантовые Загадки и Финансовые Реалии
2026-01-26 09:16