Автор: Денис Аветисян
Новое исследование демонстрирует, что автоматическое создание разнообразных и проверяемых задач является ключевым фактором для обучения надежных агентов искусственного интеллекта с использованием простых алгоритмов обучения с подкреплением.
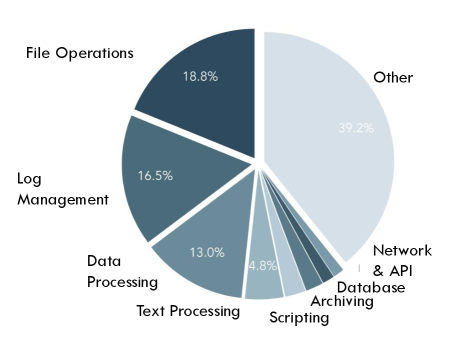
В статье представлена система Endless Terminals — автоматизированный конвейер для генерации задач, позволяющий масштабировать среды обучения и повышать устойчивость агентов.
Ограниченность доступных сред для обучения является ключевым препятствием для развития самообучающихся агентов. В статье ‘Endless Terminals: Scaling RL Environments for Terminal Agents’ представлена новая методология автоматической генерации разнообразных и верифицируемых задач для терминальных сред, позволяющая масштабировать процесс обучения. Показано, что использование процедурно генерируемых задач значительно улучшает производительность языковых моделей, обученных с помощью простого алгоритма PPO, как на новых, так и на существующих бенчмарках. Возможно ли, таким образом, создать универсальную платформу для обучения агентов, способных эффективно работать в реальных терминальных окружениях, без необходимости в ручной аннотации данных?
За пределами Ручного Труда: Автоматизация Создания Задач
Традиционное обучение с подкреплением в значительной степени опирается на задачи, разработанные человеком, что существенно ограничивает возможности масштабирования и всестороннего исследования пространства состояний. Этот подход требует значительных временных и ресурсных затрат на проектирование и создание разнообразных и сложных сценариев, необходимых для эффективной подготовки агентов. В результате, агенты часто обучаются в ограниченной среде, что снижает их способность к обобщению и адаптации к новым, ранее не встречавшимся ситуациям. Зависимость от ручного труда в создании задач становится критическим узким местом, препятствующим достижению действительно надежного и универсального искусственного интеллекта, способного решать широкий спектр проблем в реальном мире.
Создание разнообразных и сложных задач представляет собой существенное препятствие для разработки действительно устойчивых интеллектуальных агентов. Традиционные методы обучения часто ограничиваются узким спектром сценариев, разработанных человеком, что не позволяет агентам эффективно адаптироваться к неожиданным ситуациям или обобщать полученные знания. Отсутствие достаточного разнообразия в обучающих данных приводит к тому, что агенты демонстрируют хорошие результаты в знакомых условиях, но терпят неудачу при столкновении с новыми, более сложными проблемами. Именно поэтому расширение спектра задач, с которыми сталкивается агент в процессе обучения, является ключевым фактором для повышения его надежности и способности к адаптации в реальном мире. Неспособность преодолеть это ограничение замедляет прогресс в области искусственного интеллекта и ограничивает потенциал создания по-настоящему интеллектуальных систем.
Переход к автоматической генерации задач является ключевым фактором для дальнейшего развития возможностей искусственного интеллекта. Традиционные методы обучения с подкреплением полагаются на задачи, созданные человеком, что ограничивает масштабируемость и разнообразие опыта, необходимого для создания действительно устойчивых и адаптивных агентов. Автоматизированная генерация позволяет создавать неограниченное количество разнообразных и сложных сценариев, стимулируя более глубокое обучение и расширяя границы возможностей ИИ в решении сложных задач. Этот сдвиг парадигмы открывает путь к разработке агентов, способных к самостоятельному обучению и адаптации в динамически меняющейся среде, преодолевая ограничения, связанные с ручным созданием задач и позволяя искусственному интеллекту достигать новых высот в различных областях применения.
Прогресс в обучении интеллектуальных агентов существенно ограничивается невозможностью масштабирования процесса генерации задач. Традиционные методы, требующие ручного создания разнообразных и сложных сценариев, становятся узким местом, препятствующим достижению действительно надежных и универсальных систем искусственного интеллекта. Отсутствие автоматизированных инструментов для создания задач не позволяет агентам исследовать достаточное количество ситуаций и развивать необходимые навыки для адаптации к новым, неизвестным условиям. Это приводит к тому, что обученные агенты часто демонстрируют высокую производительность только в ограниченном наборе заранее определенных сценариев, а их способность к обобщению и переносу знаний остается низкой. Таким образом, развитие методов автоматической генерации задач является ключевым фактором для дальнейшего продвижения в области обучения с подкреплением и создания по-настоящему интеллектуальных систем.
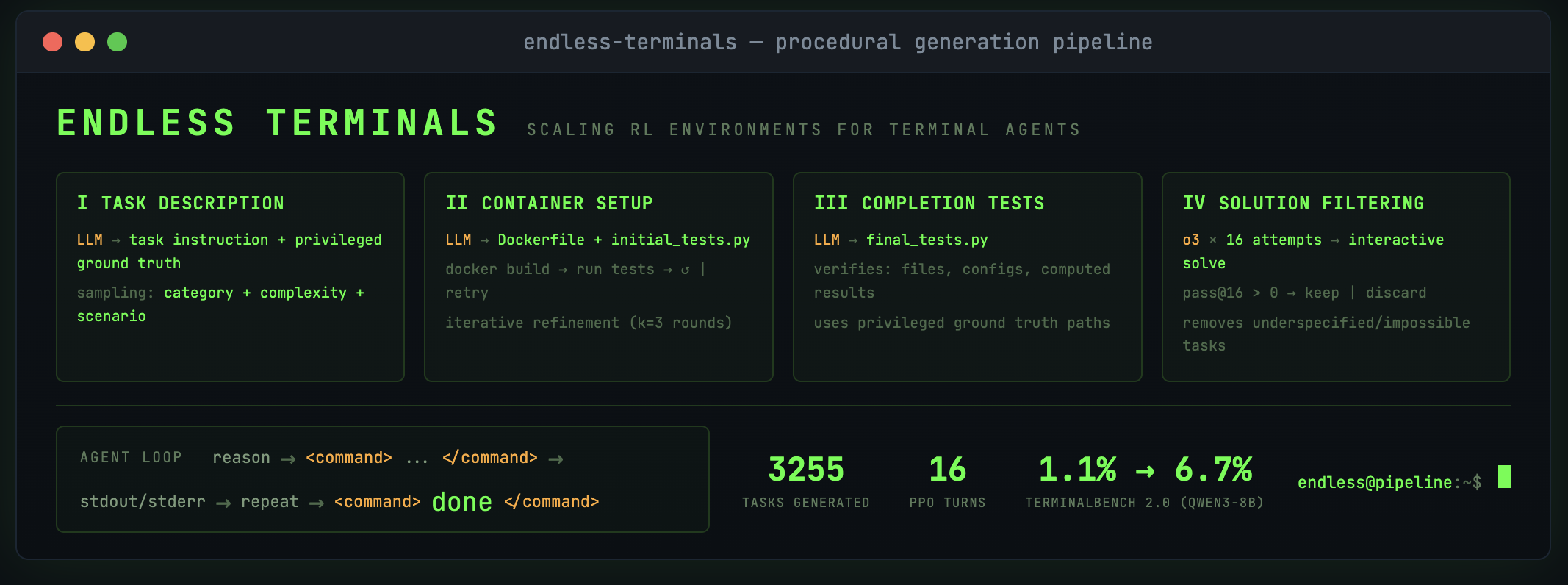
Бесконечные Терминалы: Процедура Генерации Задач
В отличие от традиционных подходов к созданию задач для обучения агентов, конвейер Endless Terminals генерирует задания для работы в терминале полностью автономно, без привлечения людей для аннотирования данных или использования методов дистилляции. Это достигается за счет процедурной генерации, что позволяет создавать неограниченное количество разнообразных задач, не требующих ручной подготовки и обеспечивающих масштабируемость процесса обучения. Отсутствие зависимости от человеческого труда снижает стоимость и время, необходимые для создания обучающих данных, а также устраняет субъективность, связанную с ручной аннотацией.
Конвейер Endless Terminals состоит из четырех основных этапов, последовательно выполняющих задачи по созданию заданий для агентов. Первый этап, Генерация описания задания, формирует текстовое описание требуемой операции. Далее, этап Настройка контейнера обеспечивает изоляцию и воспроизводимость среды выполнения задания посредством технологий контейнеризации, таких как Apptainer и Docker. Третий этап, Фильтрация на основе решения, отбирает задания, имеющие валидное решение, исключая те, которые не могут быть успешно выполнены. И, наконец, этап Генерация теста на завершение создает критерии для автоматической оценки правильности выполнения задания агентом.
Использование технологий контейнеризации, таких как Apptainer и Docker, обеспечивает изоляцию каждой задачи и воспроизводимость результатов. Контейнеризация позволяет упаковать задачу вместе со всеми необходимыми зависимостями — библиотеками, инструментами и данными — в единый, самодостаточный блок. Это гарантирует, что задача будет выполняться одинаково на любой системе, поддерживающей эти технологии, исключая влияние различий в окружении. Такой подход критически важен для обеспечения надежности и сопоставимости результатов при обучении и тестировании агентов, а также для масштабируемости процесса генерации и выполнения задач.
В результате работы конвейера «Endless Terminals» было сгенерировано 3255 задач в формате Apptainer. Использование Apptainer обеспечивает изоляцию и воспроизводимость каждой задачи, что критически важно для надежности и масштабируемости обучения агентов. Такой объем сгенерированных задач позволяет проводить обучение и оценку агентов в больших масштабах, обеспечивая статистическую значимость результатов и возможность охвата широкого спектра сценариев.
Конвейер “Бесконечные Терминалы” спроектирован для непрерывной работы, обеспечивая постоянную генерацию задач для обучения агентов. В отличие от систем, требующих ручной аннотации или дистилляции данных, данный конвейер автоматизирован и способен производить неограниченный поток задач. Это достигается за счет последовательного выполнения четырех основных этапов, позволяющих создавать, изолировать и проверять задачи без вмешательства человека. Такая архитектура позволяет поддерживать непрерывный процесс обучения агентов, масштабируя его в зависимости от доступных вычислительных ресурсов и требований к обучению.
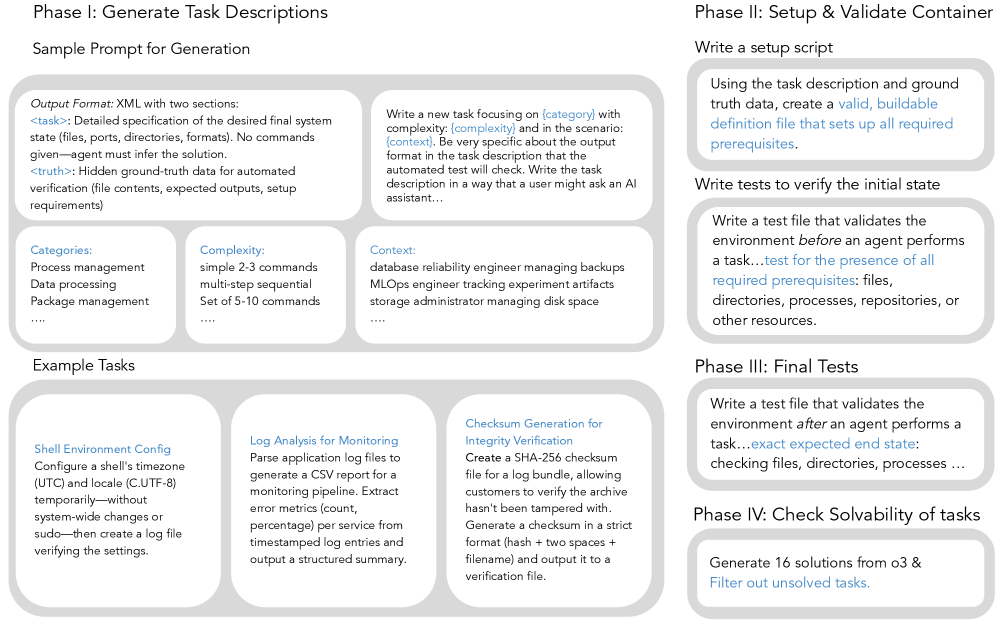
Обеспечение Качества Задач: Валидация на Основе Решений
На этапе фильтрации на основе решений используется модель o3 для оценки возможности решения задачи. Модель o3 анализирует каждую задачу и предсказывает, может ли она быть успешно решена агентом. Этот процесс включает в себя оценку сложности задачи, наличие необходимых ресурсов для ее выполнения и соответствие задачи возможностям агента. Оценка o3 используется в качестве критерия для отбраковки невыполнимых задач, что позволяет значительно повысить эффективность обучения и производительность агента. Модель o3 является ключевым компонентом системы фильтрации, обеспечивающим отбор только тех задач, которые имеют реалистичные шансы на успешное выполнение.
Процесс фильтрации в конвейере основан на выборке решений для поставленной задачи и проверке их корректности. Это позволяет идентифицировать и отсеивать невыполнимые или неэффективные задачи на ранней стадии. В ходе валидации, отобранные решения анализируются на предмет соответствия требованиям задачи, и в случае обнаружения ошибок или несоответствий, задача признается нерешаемой и исключается из дальнейшей обработки. Такой подход позволяет оптимизировать процесс обучения модели, концентрируясь на задачах, имеющих потенциал для успешного решения, и, как следствие, повышает общую производительность агента.
Процесс фильтрации задач, основанный на валидации решениями, значительно повышает эффективность обучения и производительность агента. Устранение невыполнимых или избыточных задач позволяет сосредоточить вычислительные ресурсы на задачах, которые могут быть успешно решены, что приводит к более быстрой сходимости обучения и улучшению показателей. В частности, применение данной методики позволило модели Llama-3.2-3B увеличить процент успешного выполнения задач на тестовом наборе с 4.0% до 18.2%, демонстрируя существенный прирост производительности за счет отсеивания неперспективных задач.
Внедрение фильтрации на основе валидации решений позволило значительно повысить эффективность модели Llama-3.2-3B на тестовом наборе данных. До применения данного подхода, процент успешно выполненных задач составлял 4.0%. После внедрения, этот показатель вырос до 18.2%, что свидетельствует о существенном улучшении способности модели решать поставленные задачи и более эффективном использовании вычислительных ресурсов.
Использование модели o3 демонстрирует эффективность применения существующих моделей для улучшения процесса генерации задач. Вместо разработки специализированных инструментов для оценки выполнимости задач, pipeline использует o3 для проверки корректности сгенерированных решений. Этот подход позволяет отфильтровывать невыполнимые или некорректные задачи на ранних стадиях, тем самым повышая эффективность обучения и производительность агента. В частности, применение o3 позволило улучшить показатель успешного выполнения задач (pass rate) модели Llama-3.2-3B с 4.0% до 18.2% на тестовом наборе данных, подтверждая ценность повторного использования и адаптации готовых моделей.
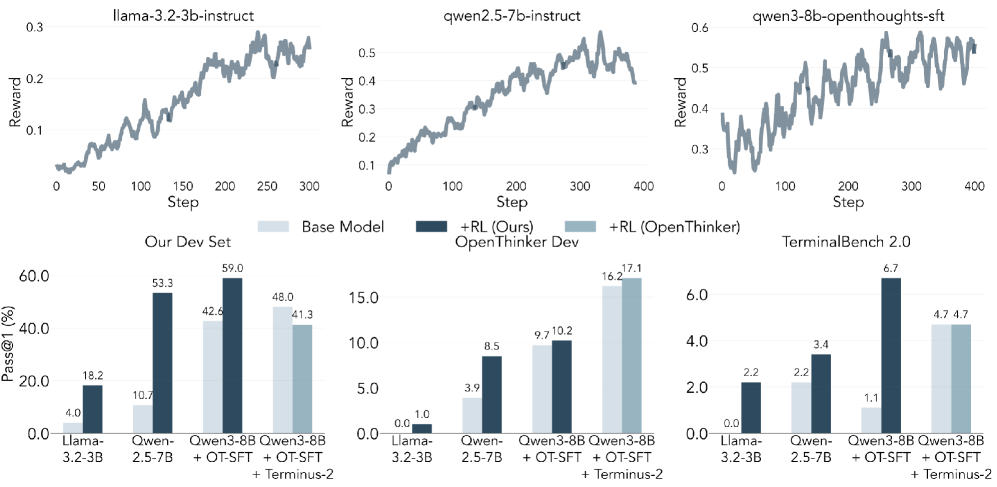
Обучение Надежных Агентов: PPO и Интеграция Языковых Моделей
В основе обучения агентов используется алгоритм обучения с подкреплением Proximal Policy Optimization (PPO). PPO является алгоритмом на основе политики, который стремится улучшить политику агента, делая небольшие шаги для обеспечения стабильности обучения. В отличие от других методов обучения с подкреплением, PPO использует функцию обрезания (clipping) для ограничения изменения политики на каждом шаге, что предотвращает слишком большие обновления, которые могут дестабилизировать процесс обучения. Это позволяет PPO эффективно обучаться в сложных средах и достигать высокой производительности, сохраняя при этом стабильность и предсказуемость.
В качестве базовых моделей для обучения с подкреплением методом PPO используются языковые модели, включая Llama-3.2-3B, Qwen-2.5-7B и Qwen-3-8B-openthinker-sft. Использование предварительно обученных языковых моделей позволяет ускорить процесс обучения агента и улучшить его способность к решению задач в интерактивной среде. Эти модели предоставляют начальные знания и языковые навыки, которые затем уточняются и адаптируются в процессе обучения с подкреплением для достижения конкретных целей.
Предварительно дообученная модель, использующая методы, подобные Natural Language to Bash, значительно повышает начальные возможности агента перед началом обучения с подкреплением. Этот процесс заключается в обучении модели преобразовывать инструкции на естественном языке в команды Bash, что позволяет ей лучше понимать и выполнять задачи, связанные с взаимодействием с операционной системой. Дообучение позволяет модели освоить базовые навыки, необходимые для успешного выполнения задач в среде TerminalBench 2.0, что, в свою очередь, ускоряет и улучшает процесс обучения с использованием алгоритма PPO.
В процессе обучения агентов с подкреплением используется система бинарных наград за эпизод, представляющая собой четкий сигнал об успешном завершении задачи. Каждый эпизод оценивается как успешный (награда +1) или неудачный (награда 0), что позволяет алгоритму PPO эффективно выделять действия, приводящие к положительному результату. Такой подход упрощает процесс обучения, предоставляя агенту однозначные критерии оценки своих действий и направляя его к освоению оптимальной стратегии для достижения поставленной цели. Отсутствие промежуточных или градиентных наград исключает неоднозначность и повышает скорость сходимости обучения.
Применение Endless Terminals в процессе обучения модели Llama-3.2-3B позволило значительно повысить ее результативность на бенчмарке TerminalBench 2.0. Изначально модель не демонстрировала успешных прохождений тестов (0.0% pass rate), однако после обучения с использованием Endless Terminals показатель увеличился до 2.2%. Данный результат свидетельствует об эффективности методики Endless Terminals в улучшении способности языковой модели выполнять задачи, требующие взаимодействия с терминалом и устойчивости к бесконечным циклам выполнения команд.
В ходе тестирования на наборе задач TerminalBench 2.0 модель Qwen-2.5-7B продемонстрировала успешное выполнение 3.4% задач, в то время как Qwen-3-8B-openthinker-sft показала более высокую эффективность, справившись с 6.7% задач. Эти результаты отражают относительную производительность моделей в решении задач, требующих взаимодействия с терминалом и выполнения команд.
Будущие Направления: Масштабирование и Обобщение с Автоматизированными Средами
Методы самообучения, основанные на взаимодействии агента с самим собой, представляют собой перспективный путь для расширения разнообразия и сложности решаемых задач. В процессе самообучения, агент генерирует новые сценарии и задачи, опираясь на свой текущий уровень компетенции, что позволяет ему постоянно сталкиваться с новыми вызовами и совершенствовать свои навыки. Такой подход имитирует естественный процесс обучения, где опыт приобретается через практику и эксперименты. В отличие от обучения на заранее определенных наборах данных, самообучение позволяет агенту исследовать более широкий спектр возможностей и развивать более общие стратегии решения задач, что критически важно для создания действительно автономных и адаптивных интеллектуальных систем. Постоянная генерация и решение новых задач способствует развитию устойчивости к различным условиям и повышает способность к обобщению полученного опыта.
Агентные опоры, или «scaffolds», представляют собой внешние инструменты и структуры, которые значительно расширяют возможности агентов искусственного интеллекта при решении сложных задач. Эти опоры не заменяют способности самого агента, а дополняют их, предоставляя доступ к дополнительным ресурсам, таким как базы знаний, специализированные алгоритмы или возможности для планирования. Например, агент, которому требуется выполнить сложную логистическую задачу, может получить доступ к базе данных о транспортных маршрутах и расписаниях через агентную опору, что позволит ему принимать более обоснованные решения и эффективно планировать свои действия. Такой подход позволяет агентам справляться с задачами, которые были бы недостижимы при использовании только внутренних ресурсов, и способствует развитию более гибких и адаптивных систем искусственного интеллекта.
Автоматическая генерация и фильтрация задач открывает принципиально новые горизонты для обобщения и переноса знаний в области искусственного интеллекта. Вместо того, чтобы полагаться на заранее определенный набор сценариев, системы могут самостоятельно создавать разнообразные задачи, адаптированные к текущим возможностям агента. Процесс фильтрации позволяет отсеивать неэффективные или избыточные задания, фокусируясь на тех, которые наиболее способствуют обучению и развитию. Такой подход позволяет агентам не просто запоминать решения для конкретных ситуаций, а формировать более общие стратегии и навыки, применимые к широкому спектру неизвестных ранее задач. Возможность динамически адаптировать сложность и разнообразие задач обеспечивает непрерывное обучение и позволяет агентам эффективно переносить полученные знания в совершенно новые контексты, значительно расширяя их адаптивность и потенциал.
Автоматизированный подход к обучению агентов, позволяющий генерировать и фильтровать задачи без непосредственного участия человека, знаменует собой важный шаг к созданию по-настоящему автономных и адаптируемых систем искусственного интеллекта. Вместо того, чтобы полагаться на заранее определенные наборы данных или ручное проектирование учебных сценариев, эта методология позволяет агентам самостоятельно исследовать и осваивать новые навыки, постоянно расширяя свои возможности и повышая устойчивость к непредсказуемым ситуациям. Подобный самообучающийся цикл не только ускоряет процесс разработки, но и открывает перспективы для создания интеллектуальных систем, способных к непрерывному совершенствованию и эффективному решению задач в динамично меняющемся окружении, приближая реальность, где искусственный интеллект действительно способен к самостоятельному обучению и адаптации.
Исследование, представленное в данной работе, подчеркивает важность масштабируемости сред для обучения агентов, что перекликается с глубоким пониманием систем как развивающихся экосистем, а не статичных конструкций. Авторы демонстрируют, что расширение разнообразия задач — ключ к созданию устойчивых агентов, способных адаптироваться к непредсказуемости реального мира. Как заметила Ада Лавлейс: «То, что может быть выражено в механических операциях, может быть выполнено машиной». В данном случае, механические операции — это процедурная генерация задач, а машина — система обучения с подкреплением. Система, способная генерировать и решать бесконечный поток задач, действительно, выходит за рамки простого инструмента и становится живой, развивающейся сущностью. И в этом развитии неизбежны «сбои» — акты очищения, необходимые для роста и адаптации.
Что дальше?
Представленная работа, демонстрируя важность масштабирования сред для обучения агентов, лишь слегка приоткрывает завесу над истинным хаосом, ожидающим впереди. Каждая новая архитектура обещает свободу от рутины, пока не потребует жертвоприношений в виде все более сложных инструментов DevOps. Бесконечные терминальные задачи — это, конечно, шаг вперед, но не стоит забывать: порядок — это просто временный кэш между сбоями. Вопрос не в создании идеальной среды, а в принятии неизбежного её разрушения.
Настоящая проблема лежит не в процедурной генерации, а в верификации. Как гарантировать, что разнообразие задач не превращается в калейдоскоп нерешаемых проблем? Или, что еще важнее, как научить агента адаптироваться не к новым задачам, а к неожиданным изменениям в уже известных? Эволюция агентов неизбежно приведет к появлению новых, непредсказуемых способов злоупотребления даже самыми тщательно спроектированными средами.
Следующий этап — это, вероятно, не поиск более совершенных алгоритмов обучения, а создание систем, способных самовосстанавливаться после сбоев, самообучаться на ошибках и, что самое главное, признавать собственные ограничения. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить. И в этой «грядке» неизбежно вырастут сорняки.
Оригинал статьи: https://arxiv.org/pdf/2601.16443.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Экзотические разложения: новые грани цилиндрической алгебры
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-26 11:08