Автор: Денис Аветисян
Исследователи предлагают SALAD — инновационный механизм внимания, сочетающий разреженность и линейность для значительного ускорения и снижения вычислительных затрат при генерации видео.
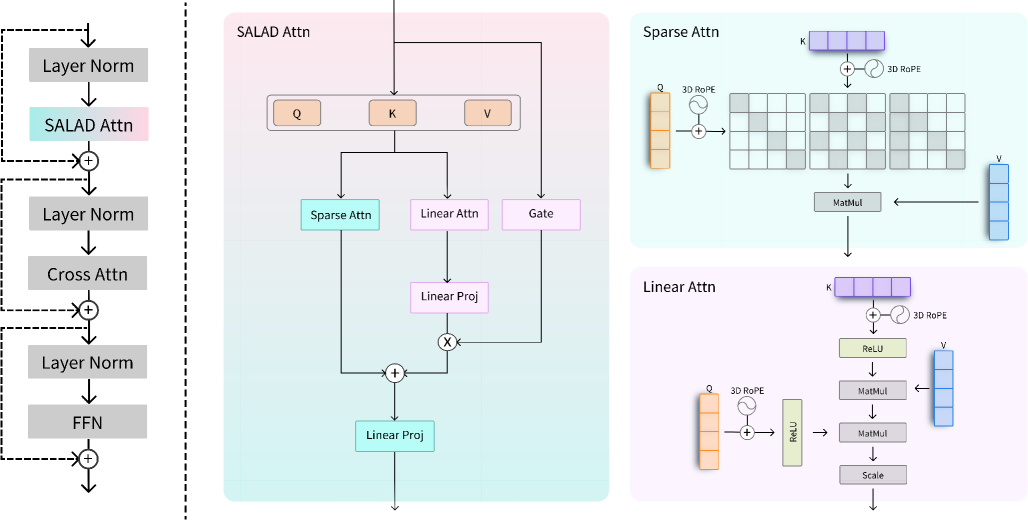
Метод SALAD обеспечивает высокую степень разреженности внимания за счет эффективной настройки линейного внимания с использованием входного затвора, что позволяет достичь сравнимого качества генерации видео при существенном снижении вычислительной нагрузки.
Несмотря на впечатляющие результаты, современные диффузионные трансформеры для генерации видео сталкиваются с ограничениями, связанными с вычислительной сложностью внимания к длинным последовательностям. В данной работе, представленной под названием ‘SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer’, предложен новый механизм внимания, сочетающий разреженное и линейное внимание с использованием управляемого входом образом гейта. Такой подход позволяет достичь высокой разреженности до 90% и ускорения вывода в 1.72 раза, сохраняя при этом качество генерации, сравнимое с полным вниманием. Каковы перспективы дальнейшей оптимизации и масштабирования SALAD для обработки еще более длинных видеопоследовательностей и повышения эффективности генерации?
Генерация Видео: Между Теоретическими Возможностями и Проклятием Масштаба
Генерация видео с использованием трансформеров представляет собой сложную задачу, требующую значительных вычислительных ресурсов. Обучение и применение этих моделей, способных создавать реалистичные и последовательные видеоролики, сопряжено с огромными затратами памяти и времени обработки. Это обусловлено необходимостью обработки больших объемов данных, представляющих последовательность кадров, и сложными вычислениями, выполняемыми для каждого кадра. В результате, широкое внедрение и доступность технологий генерации видео на основе трансформеров ограничены из-за высокой стоимости оборудования и энергопотребления, что препятствует их использованию в реальном времени и ограничивает возможности для исследователей и разработчиков с ограниченными ресурсами.
Традиционные механизмы внимания, лежащие в основе многих современных моделей генерации видео, демонстрируют квадратичную сложность, что означает, что вычислительные затраты и потребность в памяти растут пропорционально квадрату длины обрабатываемой последовательности. Это фундаментальное ограничение становится критическим препятствием при работе с длинными видео, поскольку экспоненциальный рост требований к ресурсам быстро делает генерацию реалистичных и продолжительных видеороликов практически невозможной на доступном оборудовании. По сути, при увеличении длительности видео, обработка каждого нового кадра требует учета взаимодействия со всеми предыдущими кадрами, что приводит к непомерному росту вычислительной нагрузки и усложняет задачу создания видео высокого разрешения и качества.
Существующие методы генерации видео сталкиваются с серьезной проблемой баланса между качеством, скоростью обработки и объемом необходимой памяти для достижения реалистичного результата. В стремлении к высокодетализированным и правдоподобным кадрам, алгоритмы часто требуют колоссальных вычислительных ресурсов, что существенно замедляет процесс генерации и делает его недоступным для широкого круга пользователей и устройств. Кроме того, сохранение высокого качества видео при одновременном снижении потребления памяти представляет собой сложную задачу, поскольку увеличение разрешения и детализации обычно требует экспоненциального роста объема данных. В результате, существующие подходы часто вынуждены идти на компромиссы, жертвуя либо качеством изображения, либо скоростью обработки, что ограничивает их практическое применение и сдерживает развитие этой перспективной области.
Потребность в более эффективных механизмах внимания обусловлена фундаментальными ограничениями, с которыми сталкиваются современные методы генерации видео. Традиционные подходы, основанные на квадратичной сложности вычислений, становятся узким местом при обработке длинных последовательностей кадров, необходимых для реалистичного и продолжительного видеоряда. Исследования направлены на разработку альтернативных архитектур внимания, которые позволяют снизить вычислительную нагрузку и потребление памяти, не жертвуя при этом качеством генерируемого видео. Успешная реализация таких механизмов откроет возможности для создания более сложных и детализированных видео, а также для расширения доступности технологий генерации видео для более широкого круга пользователей и приложений, включая интерактивные медиа, виртуальную реальность и автоматизированное создание контента.

Разреженное Внимание: Путь к Эффективности, или Как Уменьшить Сложность, Не Потеряв Качество
Механизмы разреженного внимания (sparse attention) снижают вычислительные затраты за счет ограничения взаимодействий между токенами в последовательности. Традиционный механизм внимания требует вычисления внимания между каждым токеном и всеми остальными, что приводит к квадратичной сложности O(n^2), где n — длина последовательности. Разреженное внимание, напротив, рассматривает лишь подмножество токенов для каждого токена, уменьшая количество необходимых вычислений и, соответственно, сложность до O(n \cdot k), где k — количество рассматриваемых токенов для каждого токена. Это позволяет обрабатывать значительно более длинные последовательности данных, что критически важно для задач, требующих анализа контекста на больших расстояниях, таких как обработка длинных текстов или генерация видео.
Механизмы внимания, такие как «Скользящее окно» (Sliding Window Attention) и «Топ-K Внимание» (Top-K Attention), повышают эффективность обработки последовательностей за счет стратегического отбора релевантных токенов для вычисления внимания. «Скользящее окно» ограничивает взаимодействие каждого токена с фиксированным числом соседних токенов, что снижает вычислительную сложность с O(n^2) до O(n*w), где ‘n’ — длина последовательности, а ‘w’ — размер окна. «Топ-K Внимание» вместо этого выбирает K наиболее значимых токенов для каждого токена, основываясь на оценке их релевантности, что также уменьшает число необходимых вычислений. Оба метода позволяют обрабатывать более длинные последовательности при сравнимых вычислительных ресурсах, что особенно важно для задач обработки видео и других больших объемов данных.
Переупорядочивание токенов является методом оптимизации разреженного внимания, направленным на увеличение локальных взаимодействий. Этот подход заключается в изменении последовательности входных токенов таким образом, чтобы семантически близкие элементы располагались рядом друг с другом. Это позволяет разреженным механизмам внимания, таким как оконное или Top-K внимание, эффективно концентрироваться на локальном контексте, снижая потребность в вычислениях для дальних зависимостей. Эффективность достигается за счет уменьшения расстояния между релевантными токенами, что приводит к снижению вычислительной сложности и повышению скорости обработки последовательностей.
Применение методов разреженного внимания, таких как скользящее окно и Top-K внимание, в сочетании с переупорядочиванием токенов, предоставляет возможность масштабирования генерации видео без существенной потери производительности. Эти техники позволяют обрабатывать более длинные последовательности данных, необходимые для видео, за счет снижения вычислительных затрат, связанных с механизмом внимания. Это достигается путем ограничения количества взаимодействий между токенами, фокусируясь на наиболее релевантных элементах последовательности, что позволяет существенно сократить требования к памяти и вычислительной мощности без ущерба для качества генерируемого видеоконтента.

SALAD: Гибридный Подход к Эффективному Вниманию, или Как Совместить Лучшее от Разных Миров
Архитектура SALAD представляет собой гибридный подход к механизму внимания, объединяющий разреженное (sparse) внимание с параллельной ветвью линейного внимания. Ключевой особенностью является достижение уровня разреженности в 90%, что позволяет значительно сократить вычислительные затраты и объем памяти, необходимые для обработки последовательностей. Реализация достигается путем выборочного применения разреженного внимания к входным данным, в то время как линейное внимание обрабатывает ту же последовательность параллельно. Такой подход позволяет сочетать преимущества обоих типов внимания — высокую точность разреженного внимания и эффективность линейного внимания — в единой архитектуре.
В архитектуре SALAD для динамического управления вкладом каждой ветви внимания используется вход-зависимый скалярный гейт. Этот гейт, функционирующий как весовой коэффициент, рассчитывается на основе входных данных и определяет степень участия разреженного и параллельного линейного внимания в формировании выходного представления. Такой подход позволяет модели адаптироваться к различным входным последовательностям, направляя вычислительные ресурсы на наиболее значимые участки и оптимизируя общую производительность, поскольку вклад каждой ветви внимания регулируется в зависимости от специфики входных данных.
Архитектура SALAD использует 3D вращающиеся позиционные вложения (Rotary Position Embeddings, RoPE) для эффективного кодирования пространственно-временной информации в токенах видео. В отличие от традиционных позиционных кодировок, RoPE применяет вращения к векторам запросов и ключей, что позволяет модели учитывать относительные позиции токенов в трехмерном пространстве (ширина, высота, время). Это особенно важно для видеоданных, где порядок токенов во времени и пространстве имеет критическое значение для понимания содержания. В SALAD, 3D RoPE позволяет модели эффективно обрабатывать последовательности видеотокенов, сохраняя информацию об их пространственном расположении и временной зависимости.
Для дальнейшей оптимизации производительности и снижения затрат на обучение модели SALAD применяется метод LoRA (Low-Rank Adaptation). LoRA предполагает заморозку предварительно обученных весов модели и введение небольшого количества обучаемых параметров низкого ранга. Это значительно сокращает количество параметров, которые необходимо обновлять во время тонкой настройки, что снижает вычислительные требования и потребление памяти. Эффективность LoRA заключается в адаптации предварительно обученных знаний к конкретной задаче без необходимости полной переобучения модели, что обеспечивает существенное снижение затрат и времени обучения, сохраняя при этом высокую точность.

Подтверждение Эффективности: Результаты Тестирования SALAD на Стандартных Наборах Данных
В ходе оценки SALAD на эталонном наборе данных VBench были продемонстрированы значительные улучшения в качестве и согласованности генерируемых видео. Система успешно превзошла существующие методы, обеспечивая более четкое и реалистичное отображение объектов и сцен. Данный результат подтверждает способность SALAD создавать видеоматериалы, которые не только визуально привлекательны, но и логически связны, обеспечивая целостность повествования и более естественное восприятие контента зрителем. Такие достижения открывают новые возможности для применения в различных областях, включая создание контента, визуальные эффекты и обучение с помощью видеоматериалов.
Оценка SALAD на стандартном бенчмарке VBench демонстрирует значительное улучшение ключевых показателей. В частности, наблюдается прирост качества изображения, а также повышение согласованности текста и сохранения идентичности объектов в видеоряде. SALAD достигает впечатляющего результата в 96.01 по параметру VBench Subject Consistency, что свидетельствует о высокой степени сохранения визуальной идентичности героев и предметов. Кроме того, показатель VBench Text Consistency составляет 25.48, подтверждая способность модели генерировать видео, последовательное с заданным текстовым описанием. Эти результаты указывают на то, что SALAD обеспечивает более реалистичные и логичные видеоматериалы, что особенно важно для задач, требующих высокой степени визуальной и смысловой точности.
Для обеспечения надёжности и воспроизводимости результатов, обучение и оценка модели SALAD проводились с использованием масштабных наборов данных Koala-36M и Mixkit Dataset. Koala-36M, содержащий миллионы видеофрагментов с разнообразными сценами и объектами, позволил модели эффективно усваивать сложные визуальные закономерности. В свою очередь, Mixkit Dataset предоставил широкий спектр видеоматериалов, необходимых для оценки обобщающей способности SALAD на различных типах контента. Использование этих обширных и разнообразных наборов данных позволило гарантировать, что полученные улучшения в качестве и консистентности видео не являются случайными, а отражают реальную способность модели к генерации высококачественного видеоконтента.
Исследование демонстрирует значительное повышение эффективности системы SALAD в процессе генерации видео. В частности, зафиксировано ускорение вывода в 1.72 раза по сравнению с плотными моделями, что позволяет существенно сократить время обработки. При этом, для обучения системы потребовалось всего лишь 20.6 GPU-часов, что значительно меньше, чем у альтернативных подходов. Полученные результаты свидетельствуют о потенциале SALAD для оптимизации ресурсов и повышения производительности в задачах генерации видеоконтента, открывая новые возможности для широкого спектра приложений.
Полученные результаты демонстрируют значительный потенциал SALAD для существенного прогресса в области генерации видео. Высокие показатели по ключевым метрикам, таким как согласованность текста и субъектов, в сочетании со значительным увеличением скорости вывода и снижением затрат на обучение, указывают на то, что SALAD представляет собой перспективный подход к созданию высококачественного и реалистичного видеоконтента. Эффективность модели, подтвержденная на масштабных датасетах и бенчмарках, позволяет предположить, что SALAD может стать основой для разработки новых приложений и сервисов в сфере визуальных медиа, открывая новые возможности для творчества и инноваций.

Перспективы Развития: К Реальному Времени и Высокодетализированному Видео
Дальнейшие исследования сосредоточены на оптимизации архитектуры SALAD и изучении инновационных механизмов внимания. Ученые стремятся к повышению эффективности обработки данных и снижению вычислительных затрат без потери качества генерируемого видео. Особое внимание уделяется разработке более сложных и адаптивных систем внимания, способных динамически фокусироваться на наиболее важных элементах видеоряда. Предполагается, что усовершенствование этих механизмов позволит значительно улучшить реалистичность и детализацию генерируемых видео, открывая новые горизонты для приложений в области виртуальной реальности, создания контента и обработки видеоданных.
Исследования направлены на разработку адаптивных методов разреженности, которые позволяют динамически изменять паттерны внимания в процессе обработки видео. Вместо использования фиксированных схем, система будет анализировать содержание каждого кадра и выделять наиболее значимые области, концентрируя вычислительные ресурсы именно на них. Такой подход позволит значительно снизить вычислительную нагрузку, не теряя при этом качества генерируемого видео, поскольку внимание будет перераспределяться в зависимости от сложности и динамики сцены. Это означает, что система сможет более эффективно обрабатывать сложные видео с множеством деталей, а также быстрее реагировать на изменения в кадре, обеспечивая генерацию высококачественного видео в реальном времени.
Дальнейшее расширение обучающего набора данных для SALAD и интеграция мультимодальных входных сигналов открывают принципиально новые творческие горизонты. Исследования показывают, что увеличение объема данных позволяет модели более точно улавливать сложные взаимосвязи в видеоматериалах, что ведет к генерации более реалистичных и детализированных кадров. Включение дополнительных модальностей, таких как звук или текстовые описания, способно значительно обогатить процесс генерации, позволяя SALAD создавать видеоролики, более точно соответствующие заданным параметрам и творческим задачам. Такой подход не только повышает качество генерируемого видео, но и открывает возможности для создания интерактивных и персонализированных видеоматериалов, адаптированных к конкретным потребностям пользователя.
Конечной целью представленных исследований является создание технологий генерации видео в реальном времени и с высокой степенью детализации, что открывает широкие перспективы для различных сфер применения. Возможность мгновенного создания реалистичного видеоконтента может революционизировать индустрию развлечений, образование, виртуальную и дополненную реальность, а также значительно упростить процессы визуализации в науке и инженерии. Разработка подобных систем позволит создавать интерактивные медиа, персонализированные обучающие материалы и сложные симуляции с беспрецедентной скоростью и качеством, преодолевая ограничения существующих методов и открывая новые горизонты для творчества и инноваций.

Исследование представляет SALAD — попытку оптимизировать внимание в диффузионных моделях для видео. Авторы стремятся к разреженности внимания, что, в теории, должно снизить вычислительные затраты. Однако, как показывает практика, любая «оптимизация» рано или поздно превращается в новый уровень сложности. Дэвид Марр однажды заметил: «Всякая вычислительная система, как и любая другая, должна быть способна справляться с непредсказуемостью реального мира». Иными словами, элегантная архитектура SALAD, стремящаяся к высокой разреженности, неизбежно столкнется с реальными данными, которые потребуют дополнительных ухищрений. В конечном итоге, достижение высокой разреженности внимания — это не столько про создание принципиально нового алгоритма, сколько про умение находить компромиссы между теорией и неизбежными костылями продакшена.
Что дальше?
Предложенный подход, безусловно, добавляет ещё один слой абстракции к и без того сложному миру attention-механизмов. Ускорение генерации видео — это хорошо, конечно, но не стоит забывать, что каждая оптимизация — это компромисс. На практике, как показывает опыт, “разряженный” attention неизбежно сталкивается с проблемой потери информации, особенно при работе с динамичными сценами. Очевидно, что потребуется разработка более совершенных методов для адаптивного управления степенью разреженности, чтобы не жертвовать качеством ради скорости.
Вполне вероятно, что в ближайшем будущем мы увидим ещё больше вариаций на тему линейного attention и low-rank adaptation. Каждая новая библиотека, обещающая “революционное” ускорение, станет лишь очередной обёрткой над старыми багами. Впрочем, это закономерно. Продакшен всегда найдёт способ сломать элегантную теорию. И тогда придётся снова копаться в оптимизациях и патчах.
В конечном итоге, вся эта гонка за эффективностью сводится к одному: всё новое — это просто старое с худшей документацией. Истина же, как всегда, где-то посередине. Наверное, стоит вернуться к основам и задуматься, не усложнили ли мы всё до абсурда. Ведь в конце концов, видео должно просто работать.
Оригинал статьи: https://arxiv.org/pdf/2601.16515.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-01-26 12:43