Автор: Денис Аветисян
Новый подход к оптимизации баз данных использует мощь больших языковых моделей для выявления стратегий, превосходящих возможности человека.
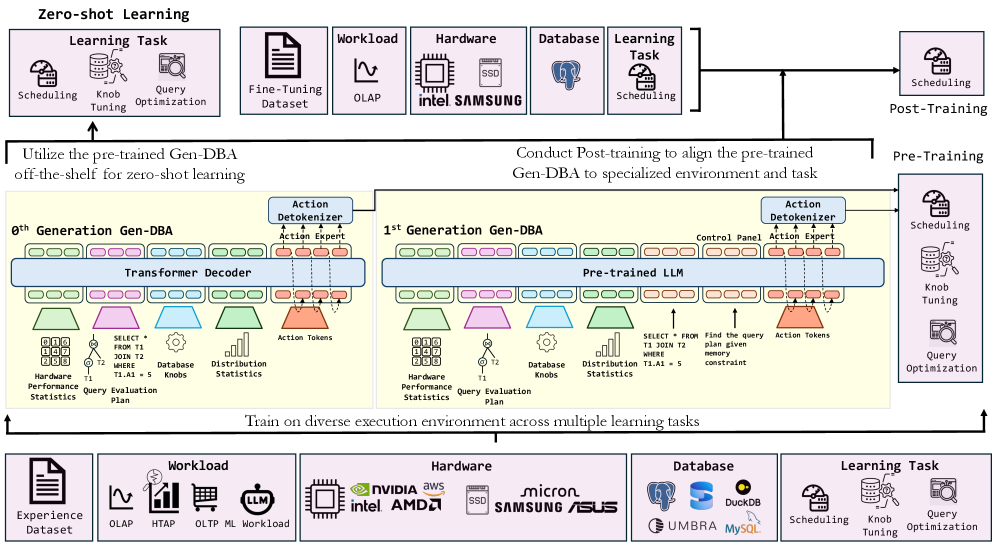
В статье представлена концепция Generative Database Agents (Gen-DBA) — генеративных агентов для баз данных, использующих унифицированный фреймворк обучения на основе фундаментальных моделей.
Несмотря на значительные успехи в области искусственного интеллекта, системы управления базами данных (СУБД) пока не демонстрируют прорывных стратегий, выходящих за рамки традиционных подходов. В данной работе, ‘Gen-DBA: Generative Database Agents (Towards a Move 37 for Databases)’, предлагается новый подход к оптимизации СУБД, основанный на использовании генеративных моделей и единой парадигмы обучения, способной к самостоятельному поиску эффективных решений. Ключевой элемент предлагаемого подхода — Generative Database Agent (Gen-DBA), использующий, в частности, токенизацию, ориентированную на аппаратные возможности, и двухэтапное обучение на основе предсказания следующего токена. Сможет ли Gen-DBA совершить революцию в области AI4DB и открыть новую эру автоматической оптимизации баз данных, подобно прорыву Move 37 в игре Го?
За гранью традиционных подходов: Возможности AI4DB
Традиционные системы управления базами данных (СУБД) сталкиваются со значительными трудностями при обработке современных, постоянно усложняющихся рабочих нагрузок. В отличие от прошлого, когда заранее определенные правила и оптимизации могли эффективно справляться с большинством задач, текущие объемы данных, разнообразие запросов и динамически меняющиеся условия требуют постоянной ручной настройки. Эта настройка включает в себя оптимизацию индексов, перепланировку запросов, управление памятью и другие параметры, что является трудоемким и ресурсозатратным процессом. Неспособность эффективно адаптироваться к меняющимся условиям приводит к снижению производительности, увеличению задержек и, в конечном итоге, к неэффективному использованию ценных вычислительных ресурсов. В связи с этим, возникает необходимость в автоматизированных решениях, способных самостоятельно анализировать и оптимизировать работу баз данных.
В связи с растущей сложностью современных рабочих нагрузок и ограниченными возможностями традиционных систем управления базами данных, возникло направление AI4DB — искусственный интеллект для баз данных. Данное направление использует методы машинного обучения для автоматической оптимизации и управления базами данных, что позволяет значительно повысить их производительность и эффективность. Вместо ручной настройки и администрирования, системы AI4DB способны самостоятельно анализировать данные, выявлять узкие места и адаптировать параметры базы данных для достижения оптимальной работы. Это включает в себя автоматическую настройку индексов, оптимизацию запросов, управление ресурсами и даже прогнозирование будущих потребностей, обеспечивая более гибкое и интеллектуальное управление данными.
Вдохновлённые прорывными достижениями, такими как знаменитый «ход 37» в AlphaGo, исследователи в области AI4DB стремятся к поиску нестандартных решений, выходящих за рамки традиционных правил оптимизации баз данных. Этот подход предполагает отказ от жёстко заданных алгоритмов в пользу систем, способных к творческому поиску и внедрению инновационных стратегий, аналогично тому, как программа AlphaGo предложила неожиданный и эффективный ход, который не был очевиден даже опытным игрокам в го. Такой креативный подход к управлению базами данных позволяет не только улучшить производительность, но и адаптироваться к постоянно меняющимся требованиям современных рабочих нагрузок, открывая новые горизонты для автоматизации и интеллектуального управления данными.
Современный сдвиг в парадигме управления базами данных требует разработки нового поколения автономных агентов, способных к самостоятельному обучению и адаптации. Эти агенты должны не просто реагировать на изменения в рабочей нагрузке, но и предвидеть их, оптимизируя производительность и ресурсы базы данных без вмешательства человека. В отличие от традиционных систем, требующих ручной настройки, интеллектуальные агенты способны к самообучению на основе исторических данных и текущих тенденций, постоянно совершенствуя свои алгоритмы и стратегии. Такой подход позволяет значительно повысить эффективность работы базы данных, снизить операционные издержки и обеспечить её устойчивость к непредсказуемым нагрузкам, открывая новые возможности для анализа данных и принятия решений.
Gen-DBA: Генеративный агент для баз данных
Gen-DBA представляет собой новую генеративную модель, разработанную для объединения различных задач обучения баз данных в единый фреймворк. В отличие от традиционных подходов, требующих отдельных моделей для каждой задачи, такой как оптимизация запросов, генерация SQL или обнаружение аномалий, Gen-DBA использует единую архитектуру для решения широкого спектра проблем. Это достигается за счет использования генеративного подхода, позволяющего модели прогнозировать последовательности действий, необходимых для выполнения конкретной задачи, и адаптации к различным типам баз данных и схемам. Единый фреймворк упрощает процесс разработки, обучения и развертывания моделей для управления базами данных, а также повышает их эффективность и масштабируемость.
Gen-DBA использует возможности больших языковых моделей (LLM) для анализа и логического обоснования операций с базами данных. LLM позволяют агенту интерпретировать запросы на естественном языке, понимать структуру схемы базы данных и выводить оптимальные SQL-запросы для получения необходимой информации или выполнения требуемых изменений. Это достигается за счет предварительного обучения LLM на больших объемах текстовых и кодовых данных, что позволяет модели приобретать знания о синтаксисе SQL, семантике данных и распространенных шаблонах запросов. В результате, Gen-DBA способен не только выполнять стандартные операции, но и решать сложные задачи, требующие логического вывода и понимания контекста.
В основе Gen-DBA лежит архитектура Transformer, обеспечивающая возможность параллельной обработки данных и масштабируемость системы. Transformer использует механизм самовнимания (self-attention), позволяющий модели одновременно учитывать все элементы входной последовательности при обработке каждого элемента, что значительно ускоряет вычисления по сравнению с последовательными моделями, такими как рекуррентные нейронные сети. Параллельная обработка данных позволяет эффективно использовать многоядерные процессоры и графические ускорители, а архитектура Transformer спроектирована таким образом, чтобы эффективно обрабатывать большие объемы данных, необходимые для работы с базами данных. Масштабируемость достигается за счет возможности увеличения количества слоев и параметров модели без существенного снижения производительности, что позволяет адаптировать Gen-DBA к задачам, требующим обработки все более сложных и объемных баз данных.
Агент Gen-DBA обучается с использованием подхода, основанного на предсказании следующего токена, обусловленного целью (Goal-Conditioned Next Token Prediction). В процессе обучения модель получает на вход описание желаемой цели для базы данных и текущее состояние, а затем предсказывает следующее действие, которое, как ожидается, приведет к достижению этой цели. Оптимизация осуществляется путем максимизации вероятности правильного предсказания следующего токена, что фактически направляет агента на выбор действий, повышающих эффективность работы с базой данных. Этот метод позволяет агенту самостоятельно осваивать стратегии оптимизации, адаптируясь к различным задачам и структурам баз данных без явного программирования правил.
Обучение и данные: Основа возможностей Gen-DBA
Процесс обучения Gen-DBA состоит из двух последовательных фаз: предварительного обучения (pre-training) и последующего обучения (post-training). Фаза предварительного обучения направлена на ознакомление агента с общими концепциями баз данных и принципами их функционирования. Последующее обучение, в свою очередь, специализирует Gen-DBA для выполнения конкретных задач, используя специализированные наборы данных, что позволяет оптимизировать его производительность и точность в решении целевых проблем.
Фаза предварительного обучения Gen-DBA использует набор данных Experience Dataset, представляющий собой обширную коллекцию информации, предназначенную для ознакомления агента с базовыми концепциями, лежащими в основе работы с базами данных. Этот этап включает в себя знакомство с различными типами баз данных, структурами данных, языком SQL и основными операциями, такими как выборка, вставка, обновление и удаление данных. Experience Dataset обеспечивает широкий охват тем, позволяя Gen-DBA сформировать общую базу знаний и понимание принципов функционирования баз данных перед переходом к специализированному обучению.
В процессе постобучения, Gen-DBA адаптируется к решению конкретных задач за счет использования специализированных наборов данных. Этот этап позволяет агенту совершенствовать навыки, необходимые для выполнения определенных операций с базами данных, таких как оптимизация запросов, обнаружение аномалий или управление транзакциями. Специализированные наборы данных содержат информацию, релевантную для целевых задач, что обеспечивает более точную настройку и повышение эффективности Gen-DBA в конкретных сценариях использования. В результате, постобучение позволяет значительно улучшить производительность и точность агента по сравнению с общими знаниями, полученными на этапе предварительного обучения.
В основе работы Gen-DBA лежит интеграция DB-Token — набора данных о производительности аппаратного обеспечения, предоставляемых в режиме реального времени. Эти данные включают в себя метрики, такие как время отклика диска, загрузка процессора, использование памяти и пропускная способность сети. DB-Token используется для динамической оптимизации запросов и планов выполнения, позволяя Gen-DBA адаптироваться к изменяющимся условиям работы и максимизировать эффективность работы с базой данных. Обратная связь на основе DB-Token позволяет агенту оценивать эффективность предпринятых действий и корректировать свою стратегию для обеспечения оптимальной производительности.
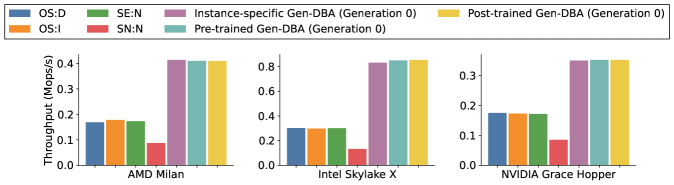
Демонстрация возможностей Gen-DBA: Планирование пространственных запросов и не только
Успешное применение Gen-DBA в задаче пространственного планирования запросов демонстрирует его возможности в оптимизации размещения операций с индексами — сложной проблеме, требующей учета особенностей многопроцессорных архитектур. Эта задача, по сути, представляет собой поиск наиболее эффективного способа организации доступа к данным, хранящимся в различных частях системы. Gen-DBA, используя генеративный подход, способен самостоятельно находить оптимальные решения, значительно превосходящие традиционные методы. Практическая реализация показала, что Gen-DBA эффективно справляется с комплексностью NUMA-архитектур, максимизируя скорость обработки пространственных запросов и открывая новые перспективы для повышения производительности баз данных.
Архитектура NUMA (Non-Uniform Memory Access) представляет собой сложную задачу для современных баз данных, поскольку скорость доступа к памяти варьируется в зависимости от её расположения относительно процессора. Система Gen-DBA демонстрирует способность эффективно ориентироваться в этих сложностях, оптимизируя размещение данных и операций таким образом, чтобы минимизировать задержки доступа к памяти. Благодаря этому подходу, Gen-DBA обеспечивает максимальную производительность в задачах, связанных с интенсивным доступом к данным, таких как пространственные запросы. В процессе оптимизации система учитывает топологию NUMA, локальность данных и паттерны доступа, что позволяет ей динамически адаптироваться к изменяющимся условиям и обеспечивать стабильно высокую производительность даже в сложных многосерверных средах.
Генеративные возможности Gen-DBA не ограничиваются планированием пространственных запросов, но и распространяются на ключевые компоненты современных баз данных, такие как Learned Index и Cardinality Estimator. Данный подход позволяет системе самостоятельно разрабатывать и оптимизировать эти критически важные элементы, что приводит к существенному повышению эффективности работы базы данных. Вместо ручной настройки и оптимизации, Gen-DBA способен генерировать оптимальные структуры индекса и алгоритмы оценки кардинальности, адаптированные к конкретным характеристикам данных и рабочей нагрузке. Такая автоматизация не только упрощает администрирование базы данных, но и открывает возможности для достижения более высокой производительности и лучшего использования ресурсов, особенно в сложных и динамичных средах.
Экспериментальные результаты демонстрируют значительное повышение производительности при использовании Gen-DBA в задачах планирования пространственных запросов. В частности, уже первое поколение Gen-DBA обеспечивает ускорение в 2.51 раза по сравнению со стандартными операционными системами при работе с нагрузкой YCSB. Более того, предварительное обучение моделей на данных, собранных с нескольких серверов, позволяет добиться дополнительного улучшения производительности на 2.17%. И, наконец, последующая донастройка моделей, выполненная на сервере Intel Skylake X, приводит к еще одному увеличению производительности — на 0.56%. Эти данные свидетельствуют о высокой эффективности Gen-DBA в оптимизации сложных задач управления базами данных и раскрывают потенциал для дальнейшего повышения производительности за счет использования более продвинутых методов обучения.
Gen-DBA представляет собой принципиально новый подход к управлению базами данных, открывающий перспективы для полной автоматизации процесса оптимизации. Система способна самостоятельно адаптироваться к изменяющимся условиям нагрузки и аппаратной конфигурации, эффективно используя доступные ресурсы. Благодаря генеративным возможностям, Gen-DBA не просто реагирует на проблемы, а предвосхищает их, динамически настраивая параметры базы данных для достижения максимальной производительности и снижения затрат. Этот механизм самооптимизации позволяет существенно повысить эффективность использования серверного оборудования, минимизируя ручное вмешательство администраторов и обеспечивая стабильно высокую производительность даже в условиях возрастающей нагрузки и сложности запросов. Подобный уровень автоматизации знаменует собой переход к новому поколению систем управления базами данных, способных к самостоятельному развитию и адаптации.
Исследование, представленное в данной работе, демонстрирует потенциал генеративных агентов для выхода за рамки традиционных методов оптимизации баз данных. Подобно тому, как системы неизбежно стареют, требуя постоянной адаптации, базы данных также нуждаются в инновационных подходах для поддержания эффективности. Кен Томпсон однажды заметил: «Простота — это, возможно, самая сложная часть». Это наблюдение перекликается с идеей о том, что кажущиеся простыми решения часто таят в себе скрытые сложности, и что достижение истинной оптимизации требует глубокого понимания взаимосвязей внутри системы. Gen-DBA, стремясь к ‘Move 37’, фактически предлагает способ автоматического выявления этих неочевидных стратегий, которые могли бы остаться незамеченными для человека-оптимизатора. Таким образом, система не просто реагирует на изменения, но и предвосхищает их, адаптируясь к динамичной среде.
Что дальше?
Представленная работа, стремящаяся к своего рода «ходу 37» в области баз данных, поднимает вопрос не столько о достижении абсолютной оптимизации, сколько о признании неизбежности её относительности. Системы, подобно живым организмам, учатся стареть достойно, а не бороться с энтропией. Попытки форсировать этот процесс, ускорить обучение агентов, могут оказаться контрпродуктивными. Иногда наблюдение за эволюцией стратегий, выработанных генеративными агентами, — единственная форма участия.
Очевидным ограничением текущего подхода является зависимость от объёма и качества данных, используемых для обучения. Неизбежно возникнет потребность в методах, позволяющих агентам адаптироваться к меняющимся условиям, к новым типам данных и запросов, не требуя постоянной переподготовки. Мудрые системы не стремятся к универсальности — они учатся находить баланс между обобщением и специализацией.
В конечном итоге, успех Generative Database Agents будет определяться не столько способностью превзойти человеческую интуицию, сколько умением признать её ценность. Задача заключается не в замене эксперта, а в создании инструмента, который позволит ему расширить границы своего понимания, увидеть закономерности, скрытые в потоке данных. Время — не метрика, а среда, в которой эти системы существуют и учатся.
Оригинал статьи: https://arxiv.org/pdf/2601.16409.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Квантовый скачок в обработке радиоастрономических данных
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
2026-01-26 12:48