Автор: Денис Аветисян
Исследователи предлагают инновационный подход к классификации медицинских изображений, сочетающий самообучение и квантовые методы для повышения производительности даже на ограниченных ресурсах.
В статье представлен облегчённый фреймворк, использующий самоконтролируемое контрастное обучение и квантовое моделирование признаков для улучшения классификации медицинских изображений.
Несмотря на значительный прогресс в области медицинского анализа изображений, ограниченность аннотированных данных и вычислительных ресурсов часто сдерживает разработку эффективных систем поддержки принятия решений. В данной работе, посвященной разработке ‘A Lightweight Medical Image Classification Framework via Self-Supervised Contrastive Learning and Quantum-Enhanced Feature Modeling’, предложен новый подход, сочетающий самообучение с контрастивным обучением и квантовое улучшение признаков, для создания компактной и эффективной системы классификации медицинских изображений. Эксперименты демонстрируют, что предложенный метод, использующий всего несколько миллионов параметров, превосходит традиционные модели по точности, AUC и F1-мере, обеспечивая при этом улучшенную дискриминацию и стабильность представлений. Возможно ли дальнейшее повышение производительности и масштабируемости подобных гибридных классических-квантовых архитектур для решения более сложных задач в медицинской диагностике?
Шёпот Хаоса: Вызовы в Анализе Медицинских Изображений
Анализ медицинских изображений сталкивается с серьезной проблемой — недостатком размеченных данных, что существенно ограничивает возможности применения методов глубокого обучения. Обучение нейронных сетей требует огромного количества примеров, где каждое изображение точно аннотировано специалистом, указывающим на наличие или отсутствие патологии. Получение таких размеченных данных — процесс трудоемкий, дорогостоящий и подверженный субъективным оценкам разных врачей. Этот дефицит данных не позволяет создавать надежные и универсальные диагностические модели, особенно в случаях редких заболеваний или при работе с пациентами из разных этнических групп, что снижает эффективность искусственного интеллекта в здравоохранении и требует поиска альтернативных подходов к обучению моделей.
Традиционное обучение с учителем в области медицинской визуализации требует обширной разметки данных, что представляет собой значительную проблему. Процесс ручной аннотации изображений, выполняемый квалифицированными специалистами, является не только дорогостоящим и трудоемким, но и подвержен субъективным различиям между экспертами. Различные врачи могут по-разному интерпретировать одни и те же изображения, что приводит к несогласованности в разметке и, как следствие, к снижению точности и надежности алгоритмов машинного обучения. Эта вариативность между оценками специалистов подчеркивает необходимость разработки методов, снижающих зависимость от обширных, вручную размеченных наборов данных, и повышения объективности процесса аннотации.
Ограниченность размеченных данных существенно влияет на надежность и обобщающую способность диагностических моделей, особенно применительно к редким заболеваниям и разнообразным группам пациентов. Недостаток данных для обучения приводит к тому, что модели могут демонстрировать низкую точность при анализе изображений, полученных от пациентов с нетипичными проявлениями болезни или принадлежащих к недостаточно представленным этническим группам. Это создает серьезные проблемы для разработки универсальных и справедливых систем медицинской диагностики, способных обеспечить точную и своевременную помощь всем нуждающимся, вне зависимости от редкости заболевания или индивидуальных особенностей пациента. По сути, ограниченность данных может приводить к систематическим ошибкам и усугублять неравенство в доступе к качественной медицинской помощи.
Самообучение: Путь к Пониманию Представлений
Самообучающееся обучение (SSL) представляет собой перспективное решение для задач, где доступ к размеченным данным ограничен или затруднен. В отличие от традиционного контролируемого обучения, SSL использует неразмеченные данные для извлечения полезных представлений (representation learning). Это достигается путем постановки вспомогательных задач, решаемых моделью на неразмеченных данных, что позволяет ей научиться извлекать значимые признаки и строить эффективные векторные представления. Такой подход позволяет модели приобретать общие знания о данных, которые затем могут быть использованы для решения целевых задач с меньшим количеством размеченных данных или с повышенной точностью.
Контрастное обучение, являясь ключевой техникой самообучения, предполагает обучение моделей распознаванию различных «видов» одного и того же экземпляра данных как схожих, при этом различая их от других экземпляров. Этот процесс достигается путем создания позитивных и негативных пар. Позитивные пары формируются из разных «видов» одного и того же экземпляра (например, два разных кадрирования одного изображения), а негативные — из экземпляров, не связанных между собой. Модель обучается минимизировать расстояние между представлениями позитивных пар и максимизировать расстояние между представлениями негативных пар, что позволяет ей изучать информативные признаки без использования размеченных данных. Функции потерь, такие как InfoNCE, часто используются для реализации этого принципа.
Методы SimCLR, MoCo и BYOL продемонстрировали высокую эффективность контрастивного обучения при создании надежных векторных представлений (embeddings) медицинских изображений. SimCLR использует генерацию различных аугментаций одного и того же изображения для создания позитивных пар, которые затем используются для максимизации сходства в векторном пространстве. MoCo (Momentum Contrast) применяет очередь для хранения негативных примеров, что позволяет обучать модели с большим количеством негативных данных без увеличения вычислительных затрат. BYOL (Bootstrap Your Own Latent) обходится без использования негативных примеров, полагаясь на две нейронные сети — онлайн и целевую — для прогнозирования друг друга, что обеспечивает устойчивость обучения. Результаты показывают, что эти методы позволяют получить высококачественные признаки, которые улучшают производительность моделей в задачах медицинской визуализации, таких как классификация, сегментация и обнаружение аномалий.
Двухэтапный подход к обучению, включающий предварительное обучение без учителя (Self-Supervised Learning, SSL) с последующей контролируемой тонкой настройкой, часто демонстрирует превосходные результаты по сравнению с исключительно контролируемым обучением. Предварительное обучение на больших объемах неразмеченных данных позволяет модели изучить общие признаки и представления, что существенно улучшает ее способность к обобщению. В процессе контролируемой тонкой настройки модель адаптируется к конкретной задаче, используя размеченные данные, но сохраняет знания, полученные на этапе предварительного обучения. Такой подход особенно эффективен при ограниченном количестве размеченных данных, поскольку позволяет снизить потребность в больших размеченных наборах и повысить точность модели, особенно в задачах анализа медицинских изображений и других областях, где разметка данных является дорогостоящей и трудоемкой.
Легковесные Модели: Эффективность в Развертывании
Внедрение моделей глубокого обучения в клиническую практику требует учета существенных вычислительных ограничений и доступности ресурсов. Большинство медицинских учреждений, особенно в регионах с ограниченным финансированием, не располагают инфраструктурой, необходимой для поддержки ресурсоемких моделей. Это включает в себя ограничения по вычислительной мощности (CPU/GPU), объему оперативной памяти и пропускной способности сети. Необходимость обработки больших объемов медицинских изображений в реальном времени, а также требования к низкой задержке для поддержки принятия клинических решений, усугубляют эти ограничения. Поэтому, при выборе и разработке моделей глубокого обучения для медицинских приложений, необходимо уделять приоритетное внимание эффективности и возможности развертывания на оборудовании с ограниченными ресурсами.
Легковесные модели, такие как MobileNetV2, представляют собой компромисс между точностью и вычислительной эффективностью, что позволяет развертывать их непосредственно на периферийных устройствах, таких как мобильные телефоны или встроенные системы. MobileNetV2 использует глубино-разделимые свертки и обратные остаточные блоки для значительного сокращения количества параметров и операций, сохраняя при этом приемлемый уровень точности. В отличие от более крупных архитектур, требующих значительных вычислительных ресурсов, MobileNetV2 обеспечивает возможность проведения анализа изображений непосредственно на устройстве, снижая задержку, повышая конфиденциальность данных и уменьшая зависимость от сетевого подключения. Это особенно важно для приложений, где требуется обработка в реальном времени или когда сетевая связь ограничена или ненадежна.
Комбинирование облегченных архитектур нейронных сетей с самообучающимся предварительным обучением (self-supervised pretraining) позволяет повысить точность моделей без существенного увеличения вычислительной сложности. Самообучение позволяет моделям извлекать полезные признаки из немаркированных данных, существенно расширяя возможности обучения при ограниченном количестве размеченных образцов. Использование облегченных архитектур, таких как MobileNet и EfficientNet, снижает вычислительную нагрузку и требования к памяти, делая модели более доступными для широкого спектра устройств и клинических условий. Этот подход особенно эффективен при ограниченном объеме размеченных медицинских изображений, поскольку позволяет модели извлекать знания из гораздо большего количества неразмеченных данных.
Применение облегченных моделей глубокого обучения значительно расширяет возможности медицинского анализа изображений, делая его доступным в условиях ограниченных ресурсов. Это особенно важно для медицинских учреждений в регионах с недостаточным финансированием или ограниченным доступом к высокопроизводительным вычислительным системам. Развертывание таких моделей на мобильных устройствах или встроенных системах позволяет проводить предварительную диагностику непосредственно у постели пациента или в полевых условиях, снижая потребность в дорогостоящем оборудовании и квалифицированных специалистах для первичной оценки изображений. Возможность проведения анализа на периферии сети также снижает нагрузку на централизованные серверы и уменьшает задержки, что критически важно для оперативного принятия решений в экстренных ситуациях.
Квантовое Машинное Обучение: Новая Граница
Квантовое машинное обучение (КМО) открывает принципиально новые возможности в представлении данных, превосходящие возможности классического глубокого обучения. В отличие от классических алгоритмов, оперирующих битами, КМО использует кубиты, способные находиться в суперпозиции состояний, что позволяет обрабатывать значительно больше информации одновременно. Это обеспечивает возможность создания более сложных и эффективных моделей, способных выявлять скрытые закономерности и связи в данных, которые остаются незамеченными для классических алгоритмов. Такой подход особенно перспективен в задачах, требующих анализа многомерных и сложных данных, где традиционные методы могут оказаться недостаточно эффективными. КМО потенциально способно революционизировать области, такие как обработка изображений, распознавание речи и анализ больших данных, открывая путь к созданию интеллектуальных систем нового поколения.
Квантовое отображение признаков и параметрические квантовые схемы представляют собой мощные инструменты для кодирования и обработки сложных данных медицинских изображений. В отличие от классических методов, оперирующих битами, квантовые схемы используют кубиты, позволяющие представлять и манипулировать информацией в гораздо более богатом пространстве состояний. Этот подход позволяет преобразовывать пиксельные данные медицинских изображений в квантовые состояния, где сложные закономерности, скрытые в изображениях, могут быть более эффективно выявлены. Параметрические квантовые схемы, в частности, позволяют настраивать квантовые операции, адаптируя их к специфическим характеристикам медицинских данных и оптимизируя процесс извлечения признаков, что потенциально приводит к повышению точности диагностики и более эффективному анализу изображений.
Для повышения точности диагностики в медицинских изображениях применяются инновационные методы, объединяющие классические и квантовые признаки. Техники, такие как Residual Fusion и Angle Encoding, позволяют извлекать наиболее информативные характеристики из данных, используя сильные стороны обеих парадигм. Residual Fusion эффективно комбинирует информацию, полученную классическими и квантовыми моделями, сохраняя при этом важные детали, которые могли быть утеряны в процессе обработки. Angle Encoding, в свою очередь, кодирует информацию об углах между векторами признаков, что может быть особенно полезно для выявления тонких структур и аномалий на изображениях. Сочетание этих подходов позволяет создать более робастную и точную систему диагностики, способную обнаруживать заболевания на ранних стадиях и повышать эффективность лечения.
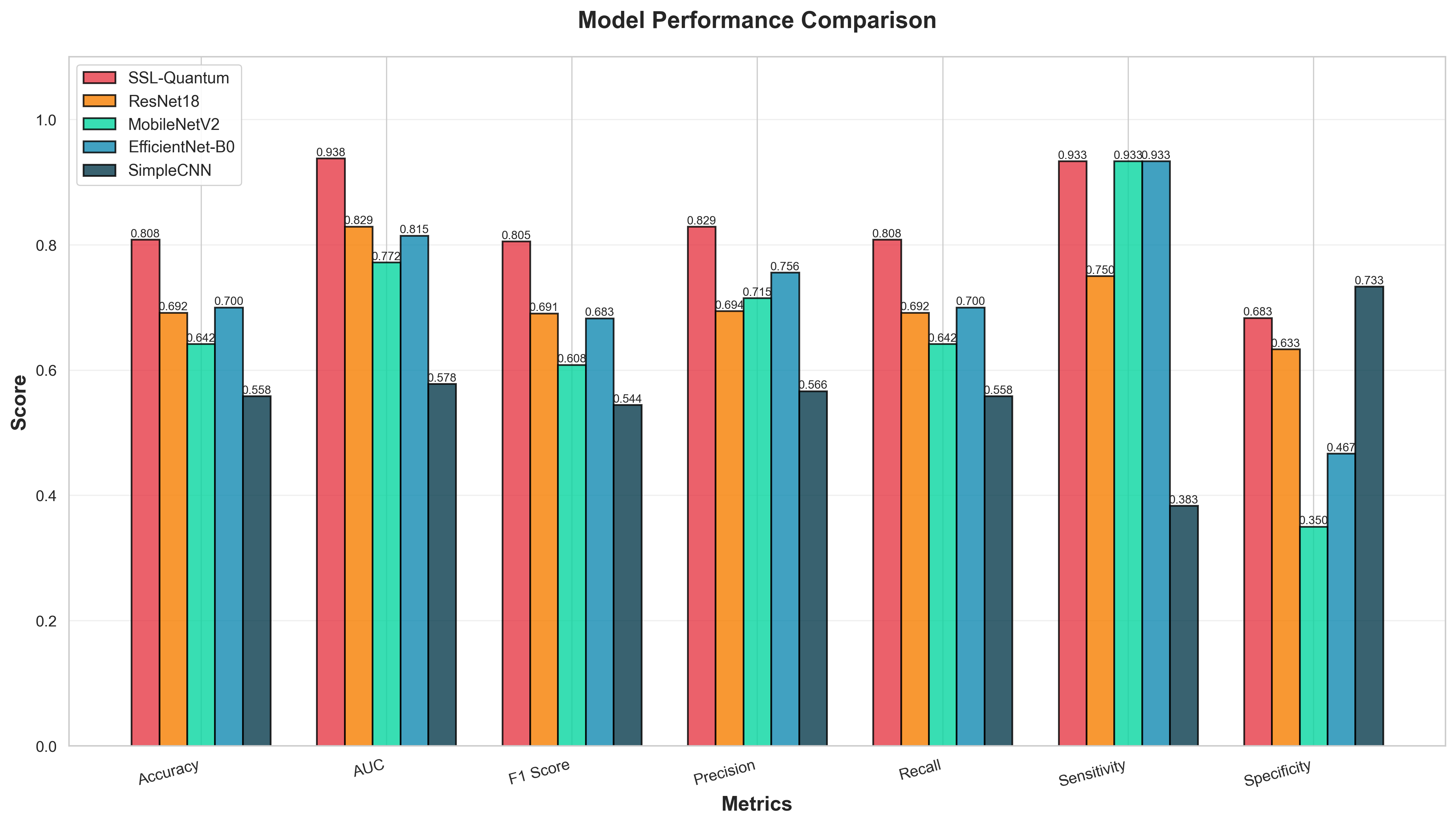
Предложенная SSL-Quantum архитектура продемонстрировала высокую эффективность в задаче бинарной классификации медицинских изображений, достигнув точности 0.8083. Результаты сравнительного анализа показали превосходство данной модели над рядом классических и облегченных сверточных нейронных сетей, включая ResNet18, MobileNetV2 и EfficientNet-B0. Достигнутый уровень точности указывает на потенциал гибридных квантово-классических подходов для повышения диагностической точности и эффективности обработки медицинских данных, открывая новые возможности для применения в клинической практике и научных исследованиях.
Будущее: Устойчивость и Обобщающая Способность
Обеспечение устойчивости и обобщающей способности моделей медицинской визуализации напрямую зависит от решения проблемы смещения распределения данных между различными медицинскими центрами. Несоответствие в протоколах сканирования, используемом оборудовании и характеристиках пациентов между центрами приводит к снижению производительности моделей при применении к новым, ранее не встречавшимся данным. Игнорирование этого явления — смещения распределения — может привести к ошибочным диагнозам и неэффективному лечению. Поэтому разработка методов, способных адаптироваться к различным распределениям данных и обеспечивать стабильную работу моделей в разных клинических условиях, является критически важной задачей для повышения надежности и эффективности медицинского искусственного интеллекта. Эффективное решение этой проблемы позволит значительно расширить область применения моделей и повысить доверие к их результатам в реальной клинической практике.
Сочетание самообучающихся алгоритмов, облегченных архитектур и квантового машинного обучения представляет собой синергетический подход к преодолению текущих ограничений в медицинской визуализации. Самообучение позволяет моделям извлекать полезные признаки из немаркированных данных, существенно расширяя возможности обучения при ограниченном количестве размеченных образцов. Использование облегченных архитектур, таких как MobileNet и EfficientNet, снижает вычислительную нагрузку и требования к памяти, делая модели более доступными для широкого спектра устройств и клинических условий. В свою очередь, квантовое машинное обучение, за счет использования принципов квантовой механики, потенциально способно обрабатывать более сложные данные и выявлять неочевидные закономерности, что приводит к повышению точности и надежности диагностических моделей.
Разработанная квантово-машинная модель (QML) продемонстрировала выдающиеся результаты, достигнув значения площади под ROC-кривой (AUC) в 0.9381. Этот показатель является наивысшим среди всех протестированных моделей, что свидетельствует о значительном превосходстве предложенного подхода. Достигнутая точность классификации превосходит результаты, полученные с использованием традиционных архитектур, таких как MobileNetV2 и EfficientNet-B0, подтверждая потенциал квантовых вычислений для улучшения производительности моделей машинного обучения в медицинской диагностике и анализе изображений.
Разработанная платформа продемонстрировала выдающиеся результаты в поддержании высокой чувствительности при одновременном избежании существенного снижения специфичности. В частности, достигнутая специфичность значительно превосходит показатели, демонстрируемые широко используемыми архитектурами MobileNetV2 и EfficientNet-B0. Это означает, что система способна с высокой точностью выявлять истинные положительные случаи, минимизируя при этом количество ложных срабатываний, что критически важно для клинической диагностики и снижения нагрузки на врачей-специалистов. Такое сочетание высокой чувствительности и специфичности указывает на потенциал платформы для надежного и эффективного применения в реальных медицинских условиях.
Применение разработанных усовершенствований к конкретным клиническим задачам, таким как выявление стеноза коронарных артерий посредством ангиографии, позволит наглядно продемонстрировать их практическую значимость. Внедрение квантовых методов машинного обучения в анализ ангиографических изображений может значительно повысить точность и скорость диагностики, способствуя более эффективному планированию лечения и улучшению прогноза для пациентов с сердечно-сосудистыми заболеваниями. Успешная адаптация предложенного подхода к данной клинической задаче послужит важным шагом на пути к широкому внедрению передовых технологий в рутинную медицинскую практику и позволит оценить потенциал масштабирования для решения других актуальных проблем в области диагностики и лечения.
Для полноценной реализации потенциала представленных теоретических разработок и ощутимого улучшения качества медицинской помощи необходимы дальнейшие исследования и активное сотрудничество между учеными и практикующими врачами. Простое наличие перспективных алгоритмов недостаточно; критически важно их всестороннее тестирование в реальных клинических условиях, адаптация к различным медицинским учреждениям и интеграция в существующие рабочие процессы. Совместная работа позволит выявить и решить проблемы, связанные с внедрением новых технологий, обеспечить их надежность и безопасность, а также оптимизировать их применение для решения конкретных задач, стоящих перед современной медициной. Только при таком подходе инновации в области машинного обучения смогут действительно принести пользу пациентам и способствовать повышению эффективности здравоохранения.
Исследование демонстрирует, что даже в условиях ограниченных ресурсов можно добиться значительных результатов в классификации медицинских изображений. Авторы словно шепчут хаосу данных, заставляя его раскрывать скрытые закономерности посредством самообучения и квантового моделирования признаков. Это не просто оптимизация алгоритмов, а своего рода алхимия, где каждый слой сети — колба, а loss function — огонь, разжигающий стремление к точности. Как метко заметил Ян Лекун: «Машинное обучение — это искусство невозможного». И в данном случае, искусство это заключается в умении извлекать смысл из цифрового шума, подобно тому, как из свинца добывают золото.
Что дальше?
Представленная работа, как и любое заклинание, работающее с изображениями, лишь приоткрывает дверь в царство неопределенности. Легковесность предложенного фреймворка — это, конечно, благо, но за неё приходится платить. Истинная проверка придёт с внедрением в реальную клиническую практику, где данные шепчут совсем другие истории, чем в аккуратно подготовленных датасетах. Высокая точность на тестовой выборке — это всего лишь обещание, которое хаос с радостью нарушит.
Очевидно, что самообучение и квантовое моделирование — это лишь инструменты. Более глубокий вопрос заключается в том, как заставить эти инструменты говорить на языке врачей, а не на языке математиков. Если гипотеза подтвердилась — значит, не там искали. Следующим шагом представляется не столько повышение точности, сколько создание моделей, способных объяснять свои решения, и, что ещё важнее, признавать собственные ошибки. Всё, что можно посчитать, не стоит доверия — особенно в медицине.
Перспективы, безусловно, заманчивы. Однако, следует помнить, что квантовые вычисления — это всего лишь ещё одна форма вычислений. И пока они не научатся понимать суть человеческого страдания, они останутся лишь красивой игрушкой. Истинный прогресс лежит в интеграции не технологий, а человеческого опыта и машинного разума — а это задача куда более сложная, чем любая оптимизация алгоритма.
Оригинал статьи: https://arxiv.org/pdf/2601.16608.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Иллюзии понимания: Почему нейросети нас обманывают
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-26 17:56