Автор: Денис Аветисян
Новая реализация алгоритма Selected Basis Diagonalization на GPU с использованием библиотеки Thrust значительно повышает скорость расчетов для задач, связанных со сильно коррелированными квантовыми системами.
Представлена GPU-ускоренная реализация алгоритма Selected Basis Diagonalization с использованием библиотеки Thrust для крупномасштабных гибридных квантово-классических вычислений, основанных на Sample-based Quantum Diagonalization.
Вычислительные ограничения существенно замедляют прогресс в моделировании сильно коррелированных квантовых систем. В данной работе, посвященной ‘GPU-Accelerated Selected Basis Diagonalization with Thrust for SQD-based Algorithms’, представлена реализация ускоренного на графических процессорах (GPU) алгоритма диагонализации в выбранном базисе (SBD) с использованием библиотеки Thrust. Предложенный подход, оптимизированный для современных GPU-архитектур, обеспечивает ускорение до \sim 40\times по сравнению с CPU-вычислениями и существенно сокращает время итераций в алгоритмах Sample-based Quantum Diagonalization (SQD). Не откроет ли это путь к более масштабным и точным расчетам в области квантовой химии и материаловедения?
Преодолевая Границы: Вычислительные Вызовы Электронной Структуры
Точное вычисление электронной структуры является фундаментальным для понимания свойств материалов, однако сложность этой задачи экспоненциально возрастает с увеличением размера рассматриваемой системы. Это означает, что даже небольшое увеличение числа электронов и атомных ядер приводит к резкому увеличению вычислительных ресурсов, необходимых для получения точного решения уравнения Шрёдингера H\Psi = E\Psi. В результате, моделирование сложных материалов, таких как высокотемпературные сверхпроводники или биологические молекулы, становится чрезвычайно затруднительным, поскольку требуемые вычислительные мощности быстро становятся недоступными. Поэтому, разработка эффективных и масштабируемых методов, способных описывать электронную структуру сложных систем, представляет собой одну из ключевых задач современной квантовой химии и физики конденсированного состояния.
Традиционные методы расчета электронной структуры, такие как полная конфигурационная интеграция (FCI), сталкиваются с серьезными ограничениями по вычислительным ресурсам даже при рассмотрении систем умеренного размера. Этот подход, хотя и обеспечивает точное решение уравнения Шрёдингера, требует экспоненциального роста вычислительных затрат с увеличением числа электронов и атомных орбиталей. Например, для описания молекулы, состоящей всего из нескольких десятков атомов, требуется колоссальное количество вычислительной мощности и памяти, что делает FCI практически неприменимым для исследования сложных материалов и химических процессов. В связи с этим, активно разрабатываются инновационные подходы, такие как методы теории возмущений, кластерные методы и тензорные сети, направленные на эффективное представление многоэлектронной волновой функции и снижение вычислительной сложности, сохраняя при этом приемлемый уровень точности. Эти альтернативные методы позволяют исследовать более крупные и реалистичные системы, открывая новые возможности для материаловедения и квантовой химии.
Эффективное представление и манипулирование многочастичной волновой функцией является фундаментальной задачей в квантовой химии. Волновая функция, описывающая состояние системы многих электронов, содержит в себе всю информацию о ее свойствах, однако её точное вычисление сталкивается с экспоненциальным ростом сложности с увеличением числа частиц. Это связано с необходимостью учитывать все возможные корреляции между электронами, что требует огромного объема вычислительных ресурсов и памяти. Разработка методов, позволяющих компактно представлять волновую функцию и эффективно выполнять над ней операции, таких как вычисление энергии или вероятности различных процессов, является ключевой областью исследований, направленных на преодоление ограничений традиционных подходов и моделирование более сложных систем. Альтернативные представления, включающие детерминантные и тензорные подходы, активно изучаются для снижения вычислительной нагрузки, сохраняя при этом приемлемую точность результатов.
Учет электронной корреляции, определяющей поведение многоэлектронных систем, представляет собой фундаментальную сложность в квантовой химии и физике материалов. Точное описание взаимодействия между электронами требует экспоненциального увеличения вычислительных ресурсов с ростом числа частиц, что делает полные методы, такие как FCI, практически неприменимыми для систем, выходящих за рамки нескольких атомов. Поэтому, разработка методов, позволяющих достичь приемлемого баланса между точностью и вычислительной эффективностью, является ключевой задачей. Современные подходы, такие как теория возмущений, методы Хартри-Фока и различные варианты теории функционала плотности, стремятся аппроксимировать сложные взаимодействия, жертвуя некоторой точностью ради возможности моделирования более крупных и реалистичных систем. Успех этих методов зависит от тщательно подобранных приближений и эффективных алгоритмов, позволяющих получить надежные результаты при разумных затратах вычислительного времени и ресурсов.
Сэмплирование Квантовой Диагонализации: Гибридный Подход
Гибридные квантово-классические алгоритмы представляют собой перспективное направление в вычислительной науке, объединяющее преимущества квантовых и классических вычислений. Квантовые компьютеры, благодаря принципам суперпозиции и запутанности, способны эффективно решать определенные классы задач, недоступные классическим компьютерам. Однако, текущие квантовые компьютеры ограничены в ресурсах и подвержены ошибкам. Гибридные алгоритмы позволяют делегировать наиболее ресурсоемкие и сложные вычисления квантовой части, в то время как классические компьютеры используются для обработки данных, управления квантовым процессом и минимизации ошибок, обеспечивая более эффективное и надежное решение задач, чем использование только квантовых или только классических методов.
Метод выборочной квантовой диагонализации (SQD) предполагает итеративное уточнение подпространства конфигураций на основе выборок, полученных из квантовой схемы. В каждой итерации квантовая схема генерирует набор состояний, которые затем используются для оценки собственных значений и собственных векторов гамильтониана в выбранном подпространстве. На основе этих оценок формируется новое, более точное подпространство, которое используется в следующей итерации. Этот процесс повторяется до достижения необходимой точности, позволяя эффективно аппроксимировать собственные значения гамильтониана, не требуя полного перебора всех возможных конфигураций.
Эффективность метода Sample-Based Quantum Diagonalization (SQD) напрямую зависит от метода Selected Basis Diagonalization (SBD), который заключается в решении пониженной собственной задачи (reduced eigenproblem) в выбранном конфигурационном пространстве. SBD позволяет существенно снизить вычислительную сложность, поскольку вместо работы со всем гильбертовым пространством, вычисления проводятся только в подпространстве, сформированном на основе отобранных конфигураций. Решение пониженной собственной задачи выполняется с использованием стандартных алгоритмов линейной алгебры, таких как LU-разложение или итеративные методы, что делает SBD вычислительно эффективным шагом в рамках SQD. Выбор оптимального подпространства конфигураций является ключевым фактором, определяющим точность и скорость сходимости алгоритма.
Метод Sample-Based Quantum Diagonalization (SQD) обеспечивает существенное снижение вычислительных затрат по сравнению с традиционными методами диагонализации матриц, сохраняя при этом высокую степень точности. Это достигается за счет итеративного построения подпространства конфигураций, основанного на выборках, полученных из квантовой схемы, и применения метода Selected Basis Diagonalization (SBD) для решения результирующей, значительно уменьшенной, собственной задачи. Вместо работы со всей матрицей, SQD оперирует лишь с выбранным подпространством, что снижает сложность вычислений с O(N^3) до O(k^3), где k — размерность выбранного подпространства, при этом, при корректном выборе подпространства, точность вычисления собственных значений сохраняется на уровне, сопоставимом с традиционными методами.
Ускорение GPU и Реализация SBD
Использование GPU-ускорителей является критически важным для раскрытия всего потенциала метода SBD, поскольку позволяет значительно распараллелить вычислительные задачи. Метод SBD требует решения больших систем линейных уравнений и выполнения операций над матрицами, которые идеально подходят для параллельной обработки на GPU. Благодаря архитектуре GPU, содержащей тысячи ядер, можно одновременно обрабатывать множество элементов данных, что приводит к существенному сокращению времени вычислений по сравнению с традиционными CPU-ориентированными подходами. Масштабируемость вычислений на GPU позволяет эффективно обрабатывать задачи, требующие высокой вычислительной мощности, такие как моделирование сложных физических процессов и анализ больших объемов данных.
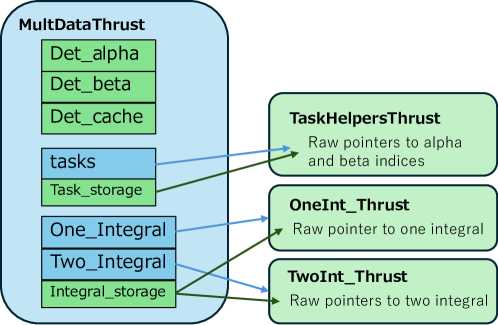
Для реализации высокопроизводительного бэкенда SBD был разработан полностью GPU-ориентированный модуль с использованием библиотеки Thrust C++. Thrust позволила эффективно реализовать параллельные алгоритмы, необходимые для SBD, и оптимизировать операции с данными. Особое внимание уделялось минимизации накладных расходов на передачу данных между CPU и GPU, что критически важно для достижения максимальной производительности. Использование Thrust позволило избежать ручной реализации параллельных циклов и управления памятью, упростив разработку и повысив надежность кода.
В ходе оценки методов диагонализации были рассмотрены два подхода: явная сборка и безматричный метод. Явная сборка предполагает предварительное вычисление полной матрицы Гамильтона H, что позволяет использовать стандартные алгоритмы линейной алгебры для нахождения собственных значений и собственных векторов. Безматричный метод, напротив, избегает явного хранения матрицы H, вычисляя результат умножения матрицы-вектора непосредственно в процессе итерационного решения, что снижает требования к памяти, но может потребовать более сложных вычислительных процедур. Выбор оптимального метода зависит от размера решаемой задачи и доступных вычислительных ресурсов.
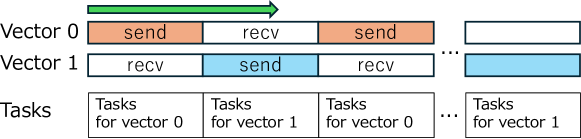
Для снижения накладных расходов на коммуникацию в распределенной памяти применялась техника двойной буферизации. Данный подход позволяет перекрывать операции MPI-коммуникации вычислениями на GPU, что существенно повышает общую производительность. В процессе работы, пока один буфер передается по сети посредством MPI, GPU параллельно обрабатывает данные из другого буфера. После завершения обработки, роли буферов меняются, обеспечивая непрерывную передачу данных и вычислений. Это позволяет минимизировать время простоя GPU, ожидающего поступления данных, и, следовательно, повысить эффективность использования ресурсов в распределенных вычислительных системах.
Оценка Производительности и Масштабируемость на Суперкомпьютерах
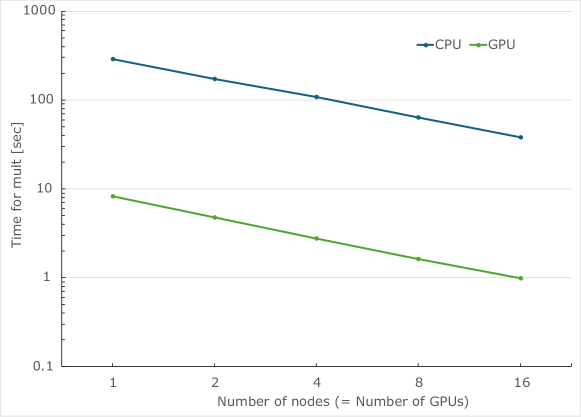
Реализация алгоритма SBD, ускоренная с помощью графических процессоров, была тщательно протестирована на суперкомпьютере Miyabi. В ходе исследования проводилось сравнение производительности с базовым вариантом, использующим центральные процессоры Grace. Данные тесты позволили оценить эффективность применения GPU для решения задач, требующих интенсивных вычислений. Полученные результаты продемонстрировали значительное увеличение скорости обработки данных по сравнению с традиционными CPU-реализациями, что подтверждает перспективность данного подхода для повышения производительности в высокопроизводительных вычислениях и расширения возможностей моделирования сложных систем.
Исследования показали существенное увеличение скорости вычислений при использовании графического процессора H200. В ходе тестирования на суперкомпьютере Miyabi, реализация алгоритма продемонстрировала ускорение в 35-39 раз на один вычислительный узел по сравнению с традиционными CPU-реализациями. Такое значительное увеличение производительности позволяет решать задачи, требующие интенсивных вычислений, значительно быстрее и эффективнее, открывая новые возможности для моделирования сложных систем и анализа больших объемов данных в различных областях науки и техники. Это ускорение является ключевым фактором для преодоления вычислительных ограничений в решении задач электронной структуры.
Для подтверждения корректности и эффективности разработанной реализации, была проведена валидация на примере кластера Fe4S4. Этот кластер, представляющий собой сложную систему с взаимодействующими частицами, позволил тщательно проверить способность алгоритма решать задачи электронной структуры с высокой точностью. Результаты, полученные на кластере Fe4S4, подтвердили не только точность вычислений, но и высокую эффективность реализации в плане использования ресурсов, что свидетельствует о ее потенциале для решения более сложных и масштабных задач в области материаловедения и химии.
Данная реализация позволяет решать задачи, включающие 3.6 \times 10^7 определителей, укладываясь в ограничения по памяти и времени работы современных графических ускорителей. Достигнута высокая эффективность сильного масштабирования, составившая 0.52 при использовании 16 узлов вычислений. Для сравнения, аналогичная задача на центральных процессорах при той же конфигурации продемонстрировала эффективность масштабирования в 0.48. Такая производительность открывает возможности для решения сложных задач электронной структуры, которые ранее были недоступны из-за вычислительных ограничений, и позволяет существенно расширить границы исследуемых систем.
Полученные результаты демонстрируют перспективность предложенного подхода для решения сложных задач электронной структуры, которые ранее были недоступны для традиционных методов. Значительное ускорение, достигающее 35-39 раз на узел благодаря использованию GPU H200, открывает возможности для моделирования систем, требующих огромных вычислительных ресурсов. Возможность обработки задач, включающих 3.6 \times 10^7 определителей, в рамках ограничений по памяти и времени выполнения современных GPU-узлов, существенно расширяет границы применимости данного метода. Эффективность масштабирования, подтвержденная на кластерах Miyabi и Fe4S4, позволяет прогнозировать успешное решение еще более масштабных и сложных задач в области материаловедения и химии, ранее считавшихся неразрешимыми.
Исследование, представленное в данной работе, демонстрирует стремление к оптимизации вычислительных процессов в квантовых алгоритмах. Авторы, используя возможности GPU и библиотеки Thrust, существенно ускорили процедуру диагонализации, что открывает новые перспективы для изучения сильно коррелированных квантовых систем. Это созвучно высказыванию Давида Гильберта: «Мы должны знать. Мы должны знать, что мы можем знать». В контексте данной работы, это означает непрерывное стремление к совершенствованию методов, расширению границ познания и разработке более эффективных инструментов для исследования сложнейших квантовых явлений. Подобный подход позволяет не просто решать текущие задачи, но и закладывать основу для будущих открытий в области квантовых вычислений.
Что же дальше?
Представленная работа, как и любая попытка ускорить неизбежное, лишь отодвигает момент, когда фундаментальные ограничения аппаратной части станут непреодолимым препятствием. Ускорение диагонализации на графических процессорах — это, безусловно, победа в текущем раунде, но каждый выигрыш времени лишь подчеркивает конечность ресурсов. Каждый найденный баг в реализации — это момент истины на временной кривой, указывающий на хрупкость любой системы, даже самой оптимизированной. Очевидно, что дальнейший прогресс потребует не только улучшения алгоритмов и аппаратного обеспечения, но и переосмысления самой парадигмы вычислений.
Технический долг, накопленный в процессе оптимизации, — это закладка прошлого, которую придётся оплатить в будущем. Попытки обойти ограничения, связанные с памятью и пропускной способностью, неизбежно приводят к усложнению кода и увеличению вероятности ошибок. Поэтому, вероятно, наиболее перспективным направлением является разработка принципиально новых методов, позволяющих эффективно работать с сильно коррелированными квантовыми системами, не прибегая к полному перебору состояний. Или, возможно, стоит смириться с тем, что некоторые проблемы просто не поддаются решению в рамках существующих парадигм.
В конечном счете, каждый алгоритм, как и каждая система, стареет. Вопрос лишь в том, делает ли он это достойно. Время — не метрика, а среда, в которой существуют системы, и любое ускорение — это лишь попытка задержать неизбежное течение времени. Будущие исследования, вероятно, будут сосредоточены на поиске способов не просто ускорить вычисления, а изменить саму природу вычислений.
Оригинал статьи: https://arxiv.org/pdf/2601.16637.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Иллюзии понимания: Почему нейросети нас обманывают
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-26 22:49