Автор: Денис Аветисян
Исследователи представили Mecellem — семейство языковых моделей, разработанных с нуля и обученных на обширном корпусе турецкого юридического текста.
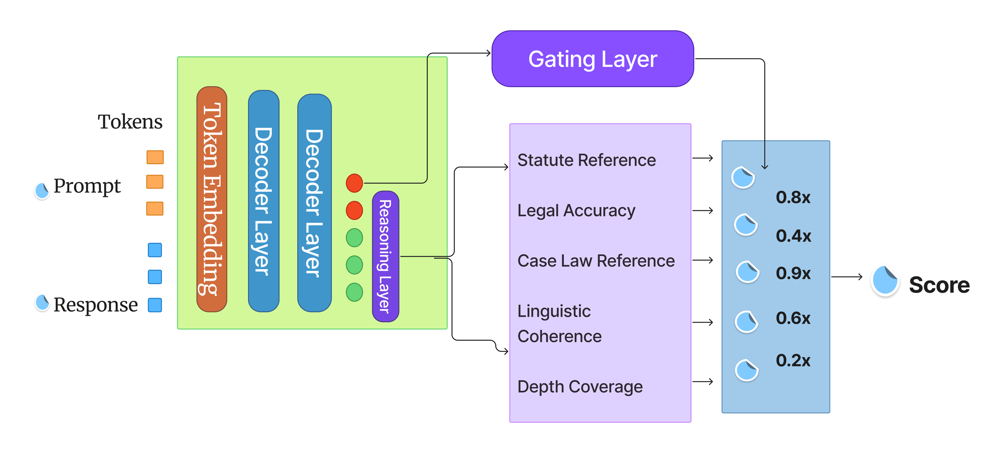
Представлена платформа Mecellem для создания и непрерывного обучения турецких языковых моделей, специализирующихся на обработке юридической информации и демонстрирующих улучшенные результаты в задачах информационного поиска.
Несмотря на значительные успехи в области больших языковых моделей, их адаптация к специфическим потребностям турецкого юридического домена остается сложной задачей. В данной работе представлены модели Mecellem, разработанные для решения этой проблемы посредством обучения с нуля и непрерывного предобучения. Мы демонстрируем, что предложенный подход позволяет достичь высокой производительности в задачах юридического информационного поиска, превосходя существующие модели по эффективности и требуя при этом меньше вычислительных ресурсов. Каковы перспективы дальнейшего развития моделей Mecellem для автоматизации юридических процессов и повышения доступности правовой информации?
Сложность турецкого права и вызов для языковых моделей
Применение архитектур больших языковых моделей (LLM) к задачам обработки естественного языка в турецком юридическом контексте сталкивается с рядом специфических трудностей. Турецкий язык, отличающийся агглютинативным строением и богатой морфологией, представляет собой значительный вызов для LLM, требуя более сложных и ресурсоемких моделей для эффективного анализа и понимания. К тому же, ограниченность доступных размеченных данных в юридической сфере, особенно на турецком языке, существенно сдерживает возможности обучения и адаптации LLM для решения специфических задач, таких как анализ контрактов, выявление правовых прецедентов или автоматическое составление юридических документов. В результате, существующие модели зачастую демонстрируют ограниченную точность и надежность при работе с юридическим текстом, что требует разработки новых подходов к обучению и адаптации LLM для турецкого юридического NLP.
Существующие модели обработки естественного языка, применяемые к турецкому юридическому тексту, часто демонстрируют ограниченные возможности в понимании тонкостей правовой аргументации и специфической терминологии. Это связано с тем, что юридический язык характеризуется высокой степенью абстракции, множеством исключений и особым контекстом, который требует глубокого понимания правовых принципов. Неспособность адекватно обрабатывать эти нюансы приводит к ошибкам в анализе, неверной интерпретации документов и, как следствие, снижает практическую ценность таких моделей для юристов и исследователей. Особенно сложно оказывается различение схожих терминов, обладающих различными юридическими последствиями, и выявление скрытых смысловых связей в сложных правовых конструкциях, что препятствует эффективному применению этих технологий в реальных юридических задачах.
ModernBERT: Базовая модель для турецкого языка
ModernBERT представляет собой мощную основу для обработки турецкого текста, построенную на архитектуре двунаправленного трансформатора. В основе обучения модели лежит метод MaskedLanguageModeling (MLM), заключающийся в случайной маскировке части слов во входном тексте и последующем предсказании замаскированных слов. Такой подход позволяет модели изучать контекстуальные зависимости и формировать глубокое понимание языка. Двунаправленность архитектуры позволяет учитывать как предшествующий, так и последующий контекст при анализе каждого токена, что существенно повышает точность и эффективность обработки турецкого языка по сравнению с однонаправленными моделями.
Для повышения качества предобучающих данных модели ModernBERT применяются методы FineWebQualityFiltering и SemHash. FineWebQualityFiltering позволяет отфильтровать данные низкого качества, в то время как SemHash используется для удаления семантически дублирующихся текстов. Комбинация этих методов обеспечивает значительное сокращение объема данных — до 50% — без потери качества, что приводит к более эффективному обучению модели и улучшению ее производительности. Это позволяет снизить вычислительные затраты и время обучения, сохраняя при этом адекватный уровень точности и обобщающей способности.
Предварительное обучение ModernBERT обеспечивает надежную отправную точку для обработки турецкого текста, однако для применения в юридической сфере требуется дополнительная доработка. Это связано с тем, что исходные данные для предварительного обучения могут содержать неспецифическую лексику и конструкции, нерелевантные для юридического дискурса. Дополнительная тонкая настройка на специализированном корпусе юридических текстов необходима для повышения точности и надежности модели при анализе правовых документов, извлечении информации и решении других юридических задач. Отсутствие такой адаптации может приводить к неверной интерпретации юридических понятий и, как следствие, к ошибкам в работе системы.
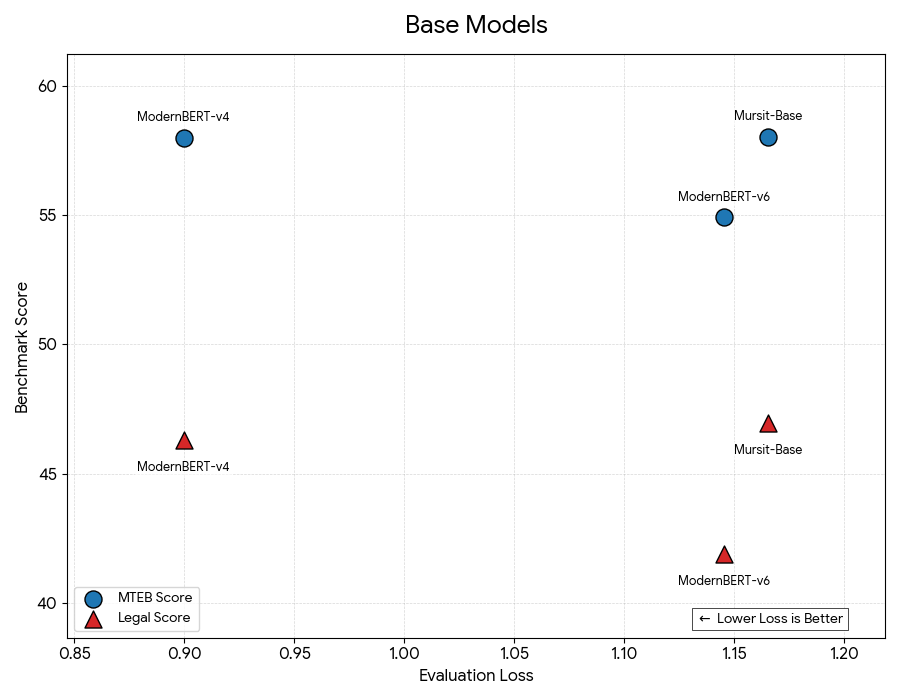
Qwen3: Непрерывное обучение для юридической экспертизы
Модель Qwen3, являющаяся декодер-онли языковой моделью, проходит процесс непрерывного предварительного обучения (Continual Pre-training) на корпусе турецких юридических текстов. Данный метод обучения позволяет модели последовательно усваивать информацию из специализированного домена, что значительно улучшает её понимание юридической терминологии, принципов и практики, характерных для турецкой правовой системы. В процессе непрерывного обучения модель адаптируется к новым данным, сохраняя при этом знания, полученные на предыдущих этапах, что способствует повышению её эффективности в решении юридических задач и анализе правовой информации на турецком языке.
Процесс обучения модели Qwen3 использует BF16MixedPrecision для повышения эффективности вычислений и снижения потребления памяти, что позволяет ускорить обучение без существенной потери точности. Кроме того, применяется CurriculumLearning — стратегия оптимизации расписания обучения, при которой модель последовательно обучается на примерах возрастающей сложности. Это позволяет модели сначала освоить базовые концепции, а затем переходить к более сложным задачам, что способствует улучшению обобщающей способности и повышению качества обучения в целом.
Для улучшения представления и извлечения юридических концепций в Qwen3 применяются методы InfoNCE и GISTEmbed. InfoNCE (Noise Contrastive Estimation) используется для обучения модели различить релевантные юридические документы от нерелевантных, оптимизируя качество векторных представлений. GISTEmbed, в свою очередь, фокусируется на создании компактных и информативных эмбеддингов, улавливающих ключевые аспекты юридического текста. Комбинация этих подходов позволяет Qwen3 более эффективно кодировать семантику юридической информации, что положительно сказывается на точности поиска и извлечения релевантных документов и понятий.
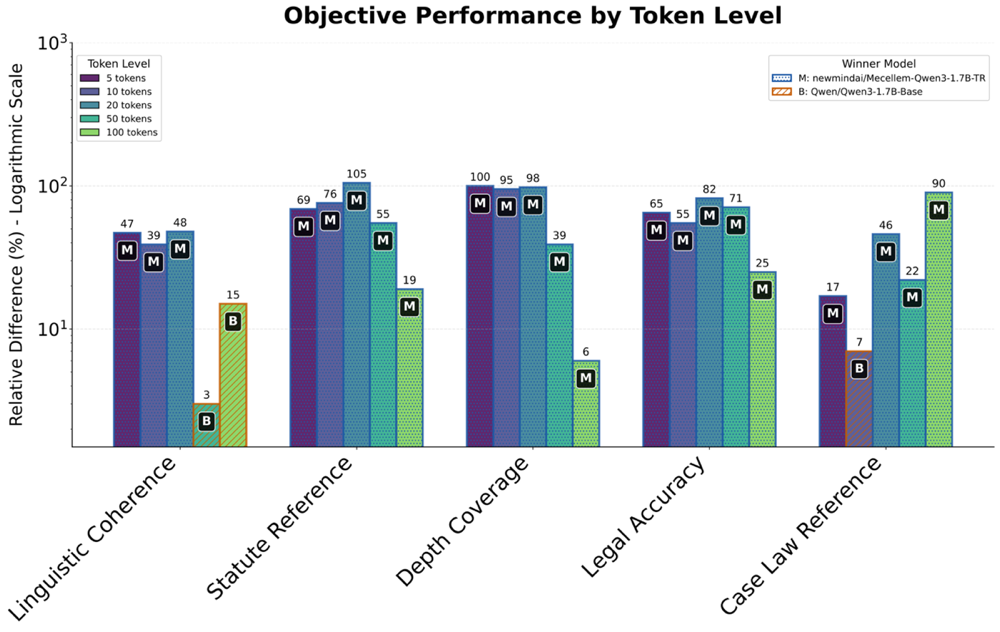
Повышение точности с помощью поиска и моделей вознаграждения
В основе повышения качества генерируемого юридического текста лежит концепция RetrievalAugmentedGeneration, использующая модели эмбеддингов для поиска релевантной информации. Суть подхода заключается в том, что при создании ответа система не полагается исключительно на собственные знания, а активно извлекает из внешних источников — обширных юридических баз данных и нормативных актов — наиболее подходящие фрагменты текста. Эти фрагменты, представленные в виде векторных эмбеддингов, служат контекстом для генерации, значительно повышая точность, согласованность и, что особенно важно, соответствие с действующим законодательством. Благодаря этому, генерируемый текст становится более обоснованным, содержательным и лишенным фактических ошибок, что критически важно в юридической сфере.
Многокритериальная модель вознаграждения, известная как Muhakim, представляет собой ключевой элемент в оценке генерируемых юридических текстов. В отличие от традиционных методов, фокусирующихся на едином показателе, Muhakim комплексно анализирует выходные данные по нескольким параметрам: точности фактических данных, связности и логичности изложения, а также соответствию действующему законодательству. Такой подход позволяет не просто определить, правильно ли сформулирован ответ, но и оценить его юридическую обоснованность и удобочитаемость. Оценка по каждому критерию вносит вклад в итоговый балл, что обеспечивает более объективное и всестороннее суждение о качестве сгенерированного текста, приближая его к уровню, требуемому в профессиональной юридической практике.
Результаты экспериментов демонстрируют выдающиеся показатели разработанного подхода. Модель Mursit-Base-TR-Retrieval, содержащая 155 миллионов параметров, достигла значения Legal Score в 47.52, что свидетельствует о высокой точности генерируемого юридического текста. Более крупная модель, Mursit-Large-TR-Retrieval, с 403 миллионами параметров, превзошла этот результат, показав значение MTEB Score в 56.43. Эти данные подтверждают, что предложенная архитектура, сочетающая в себе поиск релевантной информации и оптимизацию по нескольким критериям, обеспечивает передовые результаты в области автоматизированной генерации юридических документов и превосходит существующие аналоги.
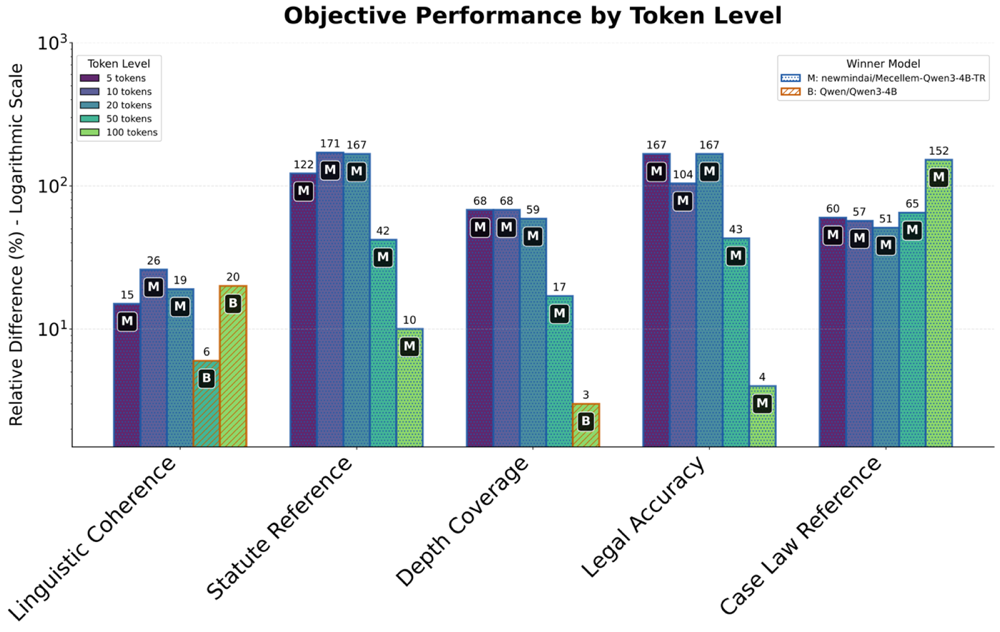
Перспективы развития и масштабируемость
Обучение современных языковых моделей требует колоссальных вычислительных мощностей, что наглядно демонстрируется использованием инфраструктуры MareNostrum5. Этот суперкомпьютер, обладающий выдающейся производительностью, позволяет обрабатывать огромные объемы данных и выполнять сложные вычисления, необходимые для оптимизации параметров моделей. Подобные ресурсы становятся критически важными для достижения высокой точности и эффективности в задачах обработки естественного языка, а также для разработки новых, более сложных архитектур. Вложение в передовую вычислительную инфраструктуру, как в данном случае, является определяющим фактором для продвижения исследований в области искусственного интеллекта и реализации его потенциала в различных сферах применения.
Непрерывные исследования направлены на совершенствование процедур обучения и поиск инновационных архитектур, способствующих повышению эффективности и точности моделей. Ученые активно изучают методы квантования, дистилляции знаний и разреженных вычислений для снижения вычислительных затрат и требований к памяти. Особое внимание уделяется разработке новых алгоритмов оптимизации, позволяющих ускорить процесс обучения без потери качества. Параллельно исследуются альтернативные архитектуры, такие как трансформеры с разреженным вниманием и модели, основанные на state space models, которые демонстрируют перспективные результаты в задачах обработки естественного языка и способны к более эффективному использованию вычислительных ресурсов.
Достижение производственной эффективности в 94.38% является ключевым показателем, демонстрирующим практическую применимость современных языковых моделей. В частности, модель newmindai/bge-m3-stsb, насчитывающая 567 миллионов параметров, способна эффективно функционировать в реальных условиях, не требуя чрезмерных вычислительных ресурсов. Этот результат открывает перспективы для широкого внедрения подобных моделей в различные сферы, такие как автоматизированная юридическая помощь и анализ контрактов, где требуется глубокое понимание естественного языка.
Проведенные исследования закладывают прочную основу для автоматизации процессов в юридической сфере, включая помощь в правовых консультациях и анализе договоров. Возможности, продемонстрированные моделью, открывают перспективы для создания интеллектуальных систем, способных обрабатывать сложные юридические тексты, выявлять ключевые положения и оценивать риски с высокой точностью. Помимо юриспруденции, подобные разработки найдут применение в широком спектре областей, требующих глубокого понимания естественного языка — от анализа финансовых отчетов до обработки медицинской документации, позволяя автоматизировать рутинные задачи и повысить эффективность работы специалистов.
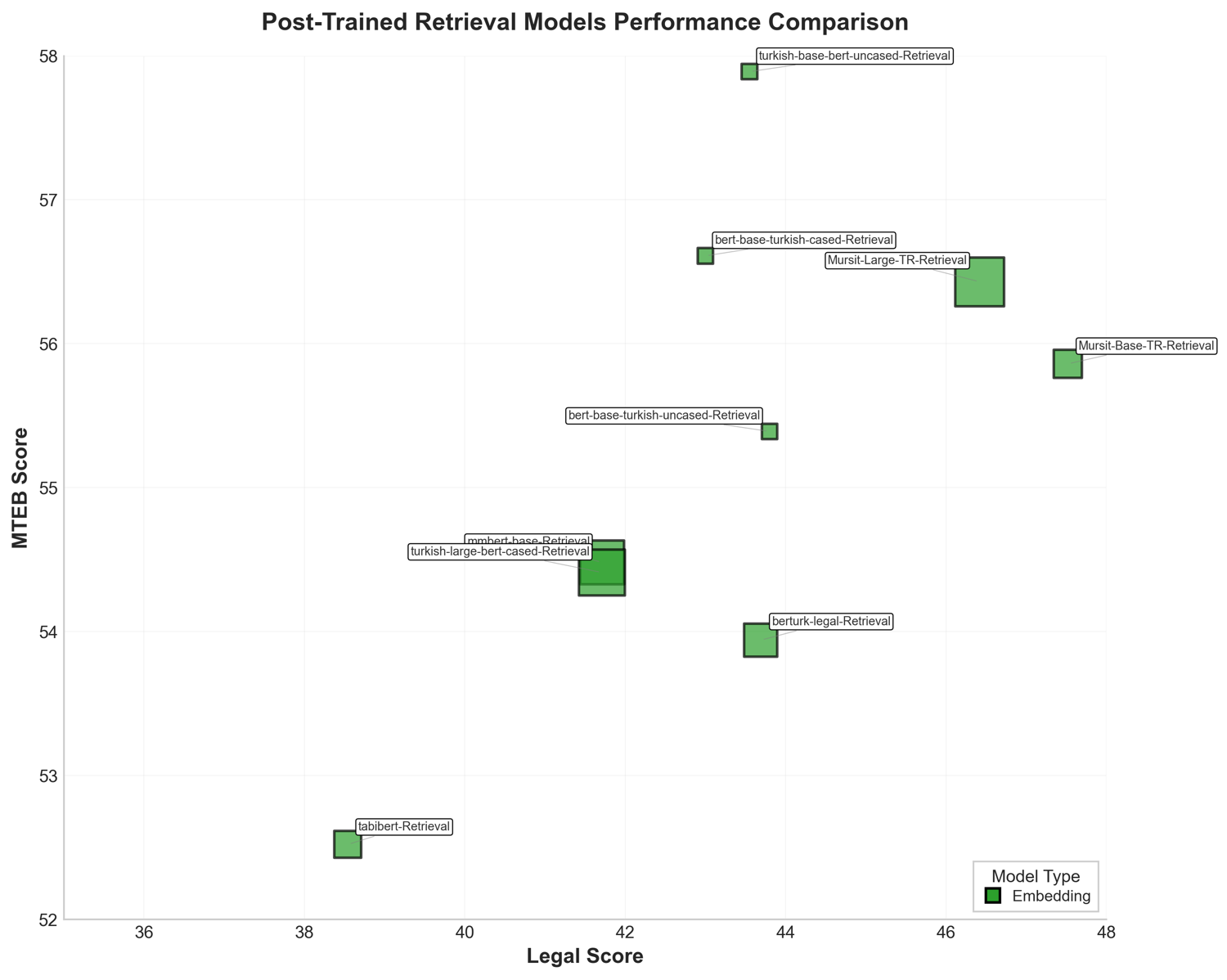
Представленная работа демонстрирует стремление к созданию эффективных языковых моделей для специфической области — юриспруденции. Авторы Mecellem, фокусируясь на предварительном и непрерывном обучении, стремятся к достижению оптимальной простоты и точности в обработке юридической информации. Как однажды заметил Алан Тьюринг: «Самое важное — это не то, что машина может думать, а то, что она может делать». Данный подход к разработке Mecellem — это не просто создание сложной системы, а поиск наиболее лаконичного и действенного решения для задач извлечения юридической информации, что соответствует принципу упрощения без потери функциональности. Подобный подход к непрерывному обучению позволяет модели адаптироваться и совершенствоваться, оставаясь актуальной и полезной в постоянно меняющейся юридической сфере.
Что дальше?
Представленная работа, сконцентрировавшись на создании и непрерывном обучении языковых моделей для турецкого юридического домена, неизбежно наталкивается на фундаментальную сложность: юридический язык — это не просто набор слов, но и система интерпретаций, меняющаяся во времени. Попытка зафиксировать эту изменчивость в статических эмбеддингах — это, по сути, попытка остановить реку. Будущие исследования должны сместить фокус с увеличения масштаба моделей на разработку механизмов, позволяющих им адаптироваться к меняющимся правовым нормам и прецедентам, возможно, через интеграцию с системами формальной логики или динамическими базами знаний.
Важным ограничением остается зависимость от доступных данных. Юридические тексты, даже в турецком сегменте интернета, часто фрагментированы, не структурированы и содержат устаревшую информацию. Истинным прогрессом станет не создание более крупных моделей, а разработка методов автоматической очистки, структурирования и верификации юридических данных, превращение хаоса информации в стройную систему. Иначе, все усилия по обучению моделей останутся лишь упражнением в статистическом моделировании шума.
Наконец, необходимо признать, что эффективность системы Retrieval-Augmented Generation (RAG) напрямую зависит от качества и релевантности извлекаемой информации. Простое увеличение объема извлекаемых документов не решит проблему, если алгоритмы не способны отличить существенное от несущественного. Поиск истины в юридическом тексте — задача, требующая не только вычислительной мощности, но и глубокого понимания контекста и логики правового мышления. Это не просто задача для алгоритмов, это вызов для интеллекта как такового.
Оригинал статьи: https://arxiv.org/pdf/2601.16018.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Иллюзии понимания: Почему нейросети нас обманывают
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-27 00:29