Автор: Денис Аветисян
Представлен AgentDrive — масштабный набор данных и платформа для оценки возможностей искусственного интеллекта в автономном вождении, созданная на базе сценариев, генерируемых большими языковыми моделями.

AgentDrive — это комплексный инструмент для бенчмаркинга и анализа способностей агентов ИИ, управляющих автомобилями, в условиях реалистичных симуляций и сложных сценариев.
Несмотря на быстрый прогресс в области больших языковых моделей (LLM), оценка и обучение моделей агентного ИИ для автономных систем остается сложной задачей из-за отсутствия масштабных и структурированных бенчмарков. В данной работе представлена AgentDrive: Открытый набор данных для бенчмаркинга агентного ИИ, основанного на сценариях, сгенерированных LLM, для автономных систем. AgentDrive включает 300 000 сценариев вождения и набор из 100 000 вопросов с множественным выбором, предназначенных для оценки как возможностей симуляции, так и рассуждений моделей. Позволит ли этот комплексный набор данных ускорить разработку и оценку агентного ИИ для беспилотного транспорта и открыть новые горизонты в области автономных систем?
Вызов Автономного Вождения: Тонкости Рассуждений
Современные автономные системы испытывают значительные трудности в сложных дорожных ситуациях, требующих не просто распознавания объектов, но и тонкой интерпретации намерений других участников движения и заблаговременного принятия решений. Эти системы часто не способны адекватно реагировать на неоднозначные ситуации, например, когда пешеход начинает переходить дорогу, но еще не сделал этого полностью, или когда другой автомобиль совершает маневр, который трудно однозначно классифицировать. Проблема заключается в том, что для успешной навигации в реальном мире требуется не только обработка визуальной информации, но и способность к построению вероятностных сценариев развития событий и прогнозированию поведения других объектов, что выходит за рамки возможностей многих существующих алгоритмов машинного обучения. Отсутствие способности к подобному комплексному рассуждению ограничивает надежность и безопасность автономных транспортных средств в непредсказуемых условиях.
Традиционные системы, основанные на жестко заданных правилах, демонстрируют хрупкость и недостаточную приспособляемость к непредсказуемым условиям реального мира. Эти системы, хотя и эффективны в строго определенных сценариях, часто терпят неудачу при столкновении с ситуациями, выходящими за рамки заранее запрограммированных условий. Неспособность к адаптации проявляется в неэффективной реакции на неожиданные препятствия, изменение погодных условий или нетипичное поведение других участников дорожного движения. В отличие от человеческого мышления, которое позволяет быстро анализировать обстановку и находить оптимальные решения в новых ситуациях, системы, основанные на правилах, требуют постоянного обновления и перепрограммирования для учета каждого возможного сценария, что является непрактичным и неэффективным в динамичной среде автономного вождения.
Эффективное рассуждение в контексте автономного вождения требует неразрывного объединения восприятия окружающей среды, прогнозирования будущего поведения участников дорожного движения и планирования оптимальной траектории. Однако, существующие подходы часто оказываются недостаточными для одновременного решения всех этих задач. Многие системы демонстрируют высокую эффективность лишь в отдельных аспектах — например, в распознавании объектов или в генерации маршрута — но испытывают затруднения при интеграции этих компонентов в единый, когерентный процесс принятия решений. Сложность заключается в необходимости обработки неопределенной и постоянно меняющейся информации, а также в обеспечении надежности и безопасности в критических ситуациях. Разработка алгоритмов, способных к комплексному анализу и проактивному реагированию на непредсказуемые события, остается одной из ключевых задач в области автономного вождения.
AgentDrive: Всеобъемлющий Бенчмарк Рассуждений
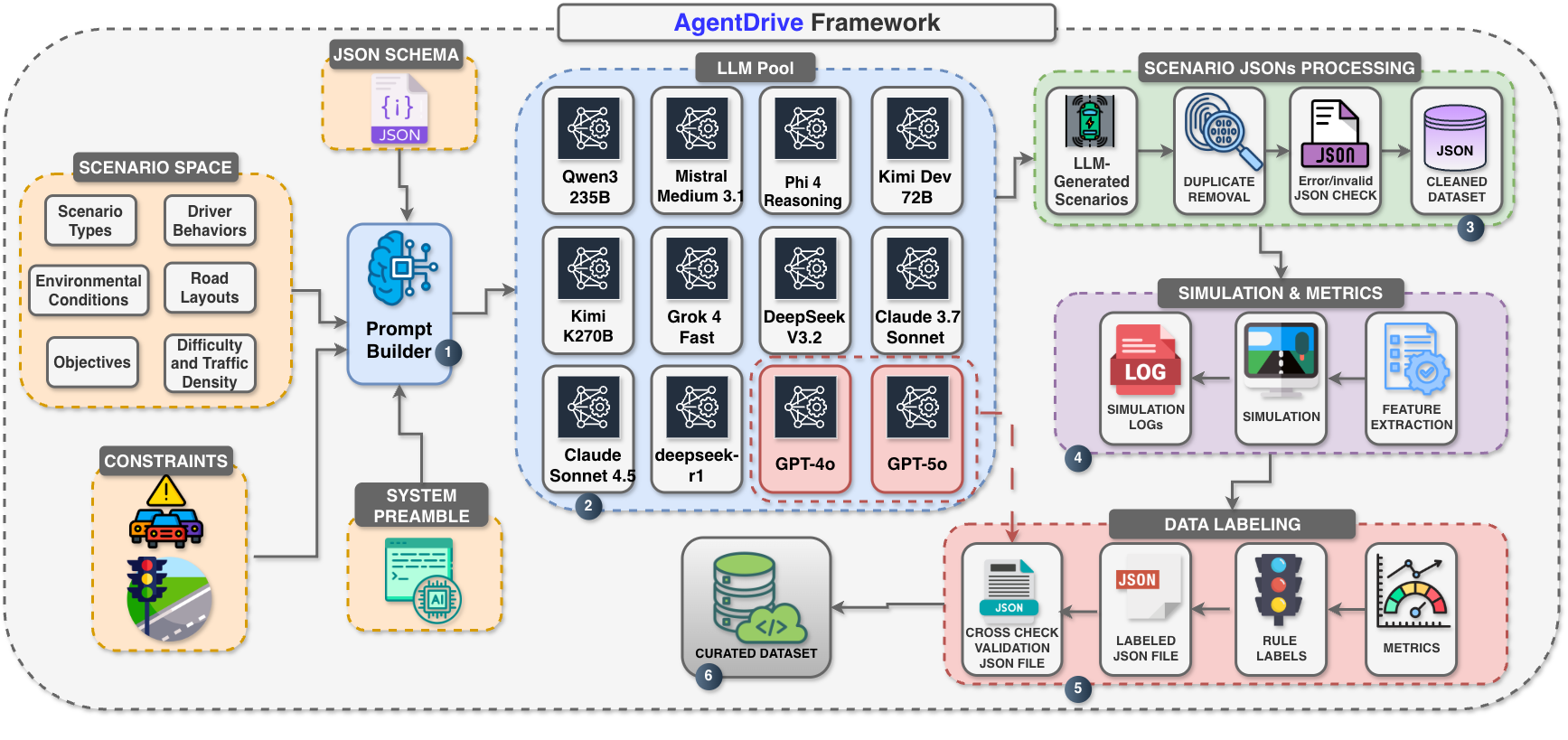
Набор данных AgentDrive содержит 300 000 сценариев вождения, сгенерированных с использованием больших языковых моделей (LLM). Этот масштаб позволяет обеспечить беспрецедентное покрытие разнообразных дорожных ситуаций, включая различные погодные условия, типы дорог, транспортные средства и поведение других участников движения. Генерация сценариев на основе LLM позволяет автоматически создавать широкий спектр ситуаций, которые было бы сложно или невозможно получить традиционными методами, такими как ручная разработка или сбор данных из реального мира. Разнообразие сценариев, представленных в AgentDrive, направлено на всестороннюю оценку возможностей систем автономного вождения в сложных и непредсказуемых условиях.
В основе AgentDrive лежит концепция “факторизованного пространства сценариев”, позволяющая систематически исследовать критически важные параметры вождения. Этот подход предполагает разделение сложных сценариев на отдельные, независимые факторы, такие как погодные условия, тип дороги, поведение других участников движения и наличие пешеходов. Комбинируя различные значения этих факторов, создается обширный набор сценариев, охватывающий широкий спектр возможных ситуаций на дороге. Такая методология гарантирует всестороннюю оценку возможностей агентов, поскольку позволяет проверить их поведение в различных, четко определенных условиях и выявить потенциальные слабые места в логике принятия решений. Использование факторизованного пространства позволяет не только генерировать большое количество сценариев, но и контролировать их разнообразие и релевантность для оценки ключевых аспектов автономного вождения.
В составе AgentDrive представлен бенчмарк AgentDrive-MCQ, состоящий из 100 000 вопросов с множественным выбором ответов, предназначенный для оценки когнитивных способностей агентов. Этот бенчмарк фокусируется на проверке способности агентов к рассуждению и принятию решений в различных дорожных ситуациях, представленных в датасете AgentDrive. Вопросы охватывают широкий спектр сценариев, требующих от агента понимания правил дорожного движения, прогнозирования поведения других участников движения и выбора оптимальной стратегии действий. AgentDrive-MCQ предназначен для количественной оценки когнитивных возможностей агентов и выявления областей, требующих дальнейшего улучшения.
Интеграция симуляционных прогонов является ключевым аспектом оценки производительности агентов в реалистичных условиях. Данный подход позволяет оценить безопасность и эффективность работы агента, подвергая его воздействию разнообразных сценариев, воспроизведенных в симуляторе. Использование симуляций позволяет проводить количественную оценку таких параметров, как частота столкновений, соблюдение правил дорожного движения, время прохождения маршрута и расход топлива, что невозможно при оценке только на основе ответов на вопросы. Прогоны в симуляции обеспечивают более надежную и объективную оценку способности агента адаптироваться к сложным и непредсказуемым ситуациям на дороге, выявляя потенциальные недостатки и области для улучшения.

Обоснование Рассуждений: Восприятие, Политика и Физика
Эффективное автономное вождение требует гибридного подхода к рассуждениям, объединяющего символические, численные и контекстуальные данные. Символические данные включают в себя правила дорожного движения и дорожные знаки, определяющие разрешенные действия. Численные данные охватывают физические параметры, такие как скорость, ускорение, масса и силы трения, необходимые для точного моделирования динамики транспортного средства. Контекстуальная информация, включающая данные от сенсоров (камер, лидаров, радаров) и карты, позволяет учитывать текущую дорожную обстановку, наличие других участников движения и особенности окружающей среды. Интеграция этих трех типов данных необходима для принятия обоснованных решений и обеспечения безопасного и эффективного движения транспортного средства в сложных условиях.
Критически важным аспектом функционирования автономных транспортных средств является способность к рассуждениям, основанным на нормативных требованиях. Для обеспечения соответствия законодательству необходимы модули извлечения правил дорожного движения, осуществляющие поиск и применение релевантных нормативных актов к текущей дорожной ситуации. Эти модули позволяют системе идентифицировать применимые правила, такие как ограничения скорости, правила приоритета и запреты на маневры, и учитывать их при планировании траектории и принятии решений. Эффективная реализация таких модулей требует доступа к структурированным базам данных нормативных актов и алгоритмов семантического поиска, способных точно интерпретировать юридическую терминологию и учитывать контекст дорожной обстановки.
Для обеспечения точного прогнозирования динамики транспортных средств и предотвращения столкновений, необходимо применение физически обоснованного рассуждения. Это предполагает моделирование сил, действующих на автомобиль — таких как тяга, сопротивление, сила трения и гравитация — и их влияние на траекторию движения. Точное предсказание требует учета F = ma (второго закона Ньютона) и других факторов, включая инерцию, угловую скорость и распределение массы. Системы, использующие физически обоснованное рассуждение, способны предвидеть поведение автомобиля в различных сценариях, таких как торможение, ускорение, повороты и взаимодействие с другими объектами, что критически важно для безопасного автономного вождения.
Интеграция мультимодальных данных посредством MAPLM (Multi-modal Attention and Perception Language Model), в сочетании с подходом DETR (DEtection TRansformer) к восприятию, значительно повышает способность большой языковой модели (LLM) к пониманию окружающей среды. MAPLM позволяет LLM эффективно обрабатывать и объединять информацию, поступающую из различных источников, таких как камеры, лидары и радары. DETR-стиль восприятия, основанный на архитектуре Transformer, обеспечивает точное обнаружение и отслеживание объектов на изображениях и видеопотоках. Комбинация этих технологий позволяет LLM формировать более полное и детализированное представление о ситуации, необходимое для принятия обоснованных решений в задачах автономного вождения и робототехники.
Обеспечение Безопасности и Надежности Продвинутыми Фреймворками
В рамках разработки и тестирования автономных систем, оценка безопасности является первостепенной задачей. Для этого широко используются так называемые “суррогатные метрики безопасности”, позволяющие количественно оценить эффективность работы агента в симулированной среде. Одним из ключевых показателей является время до столкновения (TTC), которое измеряет интервал времени, оставшийся до потенциального столкновения между транспортным средством и другими объектами. Низкое значение TTC указывает на критическую ситуацию, требующую немедленного вмешательства. Использование подобных метрик позволяет проводить масштабные испытания в виртуальной среде, выявлять слабые места алгоритмов управления и оптимизировать их для повышения безопасности дорожного движения, значительно превосходя по эффективности и экономичности традиционные методы реальных испытаний.
Метод классификации симуляционных прогонов на основе чётких правил позволяет проводить детальный анализ поведения автономных систем. Вместо полагаться на неинтерпретируемые метрики, данный подход предполагает определение конкретных критериев — например, наличие столкновений, нарушение правил дорожного движения или неоптимальное планирование траектории — для автоматической маркировки каждого прогона. Это значительно упрощает процесс отладки, поскольку позволяет быстро выявлять и изолировать проблемные сценарии. Более того, такая классификация способствует валидации системы, предоставляя возможность оценить её производительность в различных, чётко определенных ситуациях и удостовериться в соответствии заданным требованиям безопасности и надёжности. Возможность интерпретировать результаты, а не просто видеть числовые оценки, делает этот метод особенно ценным для разработчиков и инженеров, стремящихся к созданию безопасных и предсказуемых автономных систем.
Для обеспечения безопасной и надежной работы автомобилей, управляемых большими языковыми моделями (LLM), критически важна реализация комплексной системы, известной как Superalignment Framework. Эта структура выходит за рамки традиционных методов обеспечения безопасности, сосредотачиваясь на строгом соблюдении политик конфиденциальности данных и предотвращении несанкционированного доступа. Superalignment Framework позволяет контролировать и верифицировать весь жизненный цикл данных, используемых LLM, начиная от сбора и обработки, и заканчивая принятием решений. Особое внимание уделяется защите персональной информации пользователей и предотвращению утечек данных, что особенно важно в контексте автономного вождения. Благодаря реализации принципов Superalignment, LLM-управляемые автомобили не просто демонстрируют высокую производительность, но и гарантируют соответствие самым строгим требованиям по безопасности и соблюдению нормативных актов, формируя доверие к новым технологиям автономного транспорта.
Разработанная платформа Bench2ADVLM представляет собой замкнутую систему оценки, предназначенную для всестороннего тестирования моделей автономного вождения, использующих комбинацию зрения и обработки естественного языка. В отличие от традиционных подходов, Bench2ADVLM позволяет проводить испытания в интерактивной среде, имитирующей реальные дорожные условия и сложные сценарии. В процессе оценки система выявляет слабые места и потенциальные уязвимости в работе моделей, такие как неверная интерпретация визуальной информации или неспособность адекватно реагировать на меняющиеся обстоятельства. Полученные данные не только помогают разработчикам улучшить надежность и безопасность систем автономного вождения, но и способствуют созданию более устойчивых и предсказуемых алгоритмов принятия решений, критически важных для обеспечения безопасности на дорогах.
К Надежным и Адаптивным Автономным Системам
Разработка DriVLMe знаменует собой важный прорыв в создании автономных агентов для вождения, основанных на больших языковых моделях (LLM). В отличие от традиционных систем, ориентированных исключительно на технические аспекты управления автомобилем, DriVLMe стремится к интеграции воплощенного и социального опыта в процесс принятия решений. Это означает, что агент не просто реагирует на дорожную ситуацию, но и учитывает контекст взаимодействия с другими участниками движения, предвидит их поведение и адаптируется к различным социальным нормам. Такой подход позволяет создать более безопасные и предсказуемые системы автономного вождения, способные эффективно функционировать в сложных и динамичных городских условиях, приближая реальность к интуитивному вождению, характерному для человека.
Дальнейшие исследования и разработки в областях гибридного рассуждения и мультимодального восприятия представляются ключевыми для достижения качественно нового уровня автономности и безопасности систем. Гибридное рассуждение, объединяющее символические и нейронные подходы, позволит агентам не только оперировать данными, но и формировать логические заключения, учитывая контекст и правила. Мультимодальное восприятие, включающее обработку информации из различных источников — визуальных данных, лидаров, радаров и других сенсоров — обеспечит более полное и точное понимание окружающей среды. Сочетание этих подходов позволит создавать системы, способные адекватно реагировать на сложные и непредсказуемые ситуации, минимизируя риски и повышая надежность функционирования в реальных условиях. В перспективе, подобные разработки позволят создать автономные системы, способные не только самостоятельно передвигаться, но и взаимодействовать с другими участниками дорожного движения и окружающей средой, обеспечивая безопасное и эффективное функционирование.
Разработанный комплексный бенчмарк AgentDrive представляет собой ключевую платформу для непрерывной оценки и усовершенствования автономных систем, управляемых большими языковыми моделями (LLM). В рамках исследования были протестированы 50 передовых LLM, что позволило получить ценные данные об их возможностях в различных сценариях вождения. Этот подход обеспечивает систематизированную оценку и выявление областей для улучшения, способствуя развитию более надежных и безопасных автономных систем. Полученные результаты не только демонстрируют текущий уровень развития технологий, но и служат основой для дальнейших исследований и инноваций в области автономного транспорта.
В ходе тестирования на бенчмарке AgentDrive модель ChatGPT-4o продемонстрировала выдающиеся результаты, достигнув общей точности в 82,5%, что является наивысшим показателем среди 50 протестированных моделей. Особенно примечательно, что в области логики принятия решений — планировании и следовании политикам — модель показала безупречную точность, что свидетельствует о её способности к последовательному и обоснованному управлению в сложных ситуациях. Данный результат указывает на значительный прогресс в создании автономных систем на основе больших языковых моделей и открывает перспективы для разработки более безопасных и эффективных решений в области беспилотного транспорта и робототехники.
Модель Qwen3 235B A22B демонстрирует передовые результаты среди открытых исходных кодов в области автономного вождения, достигая общей точности в 81.0%. Особо выделяется способность модели к физическому рассуждению, где она показала результат в 67.5%, что указывает на её потенциал в сложных сценариях, требующих понимания законов физики и прогнозирования поведения объектов. Данные показатели подтверждают, что Qwen3 235B A22B представляет собой значительный прогресс в разработке доступных и эффективных систем автономного управления, открывая новые возможности для исследований и практического применения в данной сфере.
Представленный труд демонстрирует стремление к созданию надежных систем автономного вождения, что находит отклик в принципах, отстаиваемых Линусом Торвальдсом. Он однажды сказал: «Плохой код похож на рак: он быстро распространяется и трудно поддается лечению». AgentDrive, как комплексный набор данных и оценочная база, направлена на обеспечение корректности и предсказуемости поведения агентов, управляющих автономными транспортными средствами. В отличие от эвристических подходов, полагающихся на «работающие» тесты, эта работа акцентирует внимание на формальной верификации и создании доказуемо корректных алгоритмов. Точность и надежность, лежащие в основе AgentDrive, являются критически важными для обеспечения безопасности и эффективности автономных систем, и соответствуют строгим стандартам качества кода, которые ценит Торвальдс.
Что Дальше?
Представленный набор данных AgentDrive, безусловно, является шагом вперед в оценке агентного ИИ для автономного вождения. Однако, необходимо помнить, что любое benchmark-оценивание — это лишь снимок текущего состояния, а не гарантия прогресса. Существующие сценарии, сгенерированные языковыми моделями, неизбежно отражают предвзятости и ограничения этих самых моделей. Оптимизация алгоритмов под эти конкретные сценарии без глубокого анализа лежащих в их основе причинно-следственных связей — это самообман и ловушка для неосторожного разработчика.
Будущие исследования должны сосредоточиться на создании принципиально новых методов генерации сценариев, основанных не на статистических закономерностях, а на формальных моделях поведения и взаимодействии участников дорожного движения. Крайне важно разработать метрики, оценивающие не только успешность выполнения задачи, но и надежность, предсказуемость и объяснимость принимаемых агентом решений. В конечном счете, истинный тест для агентного ИИ — это не способность пройти набор тестов, а способность адаптироваться к неожиданным и непредсказуемым ситуациям.
Следует признать, что создание «идеального» benchmark-а — это недостижимая цель. Мир реального дорожного движения слишком сложен и многообразен, чтобы быть полностью отражен в любом наборе данных. Поэтому, ключевым направлением исследований должно стать развитие методов непрерывной оценки и адаптации агентного ИИ в процессе эксплуатации, а не только в лабораторных условиях.
Оригинал статьи: https://arxiv.org/pdf/2601.16964.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Иллюзии понимания: Почему нейросети нас обманывают
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-27 02:11