Автор: Денис Аветисян
Новая система VibeTensor демонстрирует возможность полной автоматической генерации стека программного обеспечения для глубокого обучения с использованием ИИ-агентов.
Разработана полная система, включающая Python-интерфейс и CUDA-ядра, с подтвержденной работоспособностью посредством автоматизированных сборок и тестов.
Разработка системного программного обеспечения для глубокого обучения традиционно требует значительных усилий и экспертизы. В данной работе представлена система ‘VibeTensor: System Software for Deep Learning, Fully Generated by AI Agents’, представляющая собой полноценный программный стек, созданный исключительно с помощью агентов на базе больших языковых моделей под минимальным контролем человека. Достигнута возможность автоматической генерации и верификации компонентов, начиная с ядра на C++20 (CPU+CUDA) и заканчивая Python-интерфейсом и оптимизированными GPU-ядрами, подтвержденная результатами бенчмарков и обучения на современных ускорителях NVIDIA. Не откроет ли это путь к радикально новому подходу к разработке и эволюции программного обеспечения для искусственного интеллекта?
Архитектура Гибкого Вычисления: Основы VibeTensor
Современные платформы глубокого обучения зачастую демонстрируют недостаточную гибкость и производительность при работе с новыми типами задач, особенно когда речь идет о динамических графах. Традиционные фреймворки, оптимизированные для статических вычислений, испытывают трудности при обработке данных, структура которых меняется в процессе обучения или инференса. Это приводит к увеличению времени вычислений, повышенным требованиям к памяти и, как следствие, к ограничению возможностей использования глубокого обучения в таких областях, как обработка естественного языка, компьютерное зрение и анализ графов знаний, где динамические структуры данных являются нормой. Неспособность эффективно обрабатывать динамические графы становится серьезным препятствием для развития и применения передовых моделей искусственного интеллекта.
VibeTensor представляет собой инновационную среду выполнения для глубокого обучения, использующую возможности искусственного интеллекта для преодоления ограничений существующих фреймворков. Разработанная с акцентом на гибкость и производительность, эта система способна эффективно обрабатывать динамические графы и сложные вычисления, что особенно важно для новых рабочих нагрузок. В отличие от традиционных подходов, VibeTensor динамически оптимизирует процесс выполнения, адаптируясь к конкретным задачам и аппаратным характеристикам. Это достигается за счет использования алгоритмов машинного обучения, которые анализируют и предсказывают оптимальные стратегии выполнения операций, минимизируя задержки и максимизируя пропускную способность. Таким образом, VibeTensor обеспечивает значительное повышение эффективности и расширяет возможности применения глубокого обучения в различных областях, от обработки естественного языка до компьютерного зрения.

Реализация Ядра и Зависимости
Ядро VibeTensor реализовано преимущественно на языке C++, что обеспечивает основу для высокой производительности и детального контроля над вычислительными процессами. Использование C++ позволяет эффективно управлять памятью, оптимизировать критически важные участки кода и предоставлять низкоуровневый доступ к аппаратным ресурсам. Такой подход критически важен для выполнения ресурсоемких операций, таких как матричные вычисления и обработка тензоров, и позволяет добиться максимальной скорости выполнения и минимизировать задержки. В частности, это обеспечивает возможность тонкой настройки и оптимизации для различных аппаратных платформ и рабочих нагрузок.
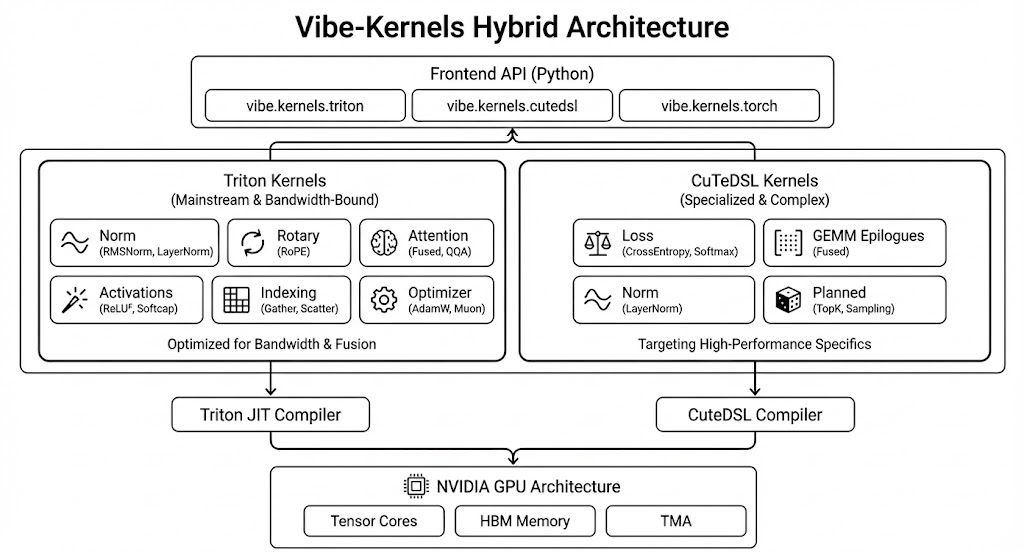
VibeTensor использует CUDA для аппаратного ускорения вычислений на графических процессорах, что позволяет значительно повысить производительность операций над тензорами. Помимо этого, реализована поддержка DLPack, обеспечивающая возможность обмена тензорами с другими фреймворками глубокого обучения без копирования данных. Это достигается за счет использования общей памяти и форматов данных, что снижает накладные расходы и повышает эффективность взаимодействия между различными библиотеками и платформами. DLPack позволяет VibeTensor беспрепятственно интегрироваться с такими фреймворками, как TensorFlow и PyTorch, минимизируя затраты на передачу данных и обеспечивая высокую скорость выполнения задач.
Автоматическое дифференцирование в VibeTensor реализовано посредством Autograd Engine, который обеспечивает вычисление градиентов для операций с тензорами, необходимое для обучения моделей машинного обучения. Для оптимизации производительности и поддержки различных аппаратных платформ используется Triton, компилятор, генерирующий высокооптимизированный код для целевого оборудования. Triton позволяет компилировать и выполнять кастомные ядра, что значительно ускоряет операции, особенно при работе с нестандартными операциями или сложными архитектурами нейронных сетей. Совместное использование Autograd Engine и Triton обеспечивает как гибкость в определении операций, так и высокую скорость их выполнения.
Оптимизации Производительности и Масштабируемости
VibeTensor использует библиотеку CUTLASS, предназначенную для высокопроизводительных матричных умножений, для ускорения основных вычислительных операций. CUTLASS предоставляет набор оптимизированных ядер, реализующих различные алгоритмы матричного умножения и конволюции, что позволяет добиться значительного повышения производительности в задачах глубокого обучения. Реализация CUTLASS в VibeTensor обеспечивает поддержку различных типов данных и архитектур GPU NVIDIA, включая современные поколения, такие как Hopper и Blackwell, что позволяет эффективно использовать аппаратные ресурсы и минимизировать задержки при выполнении ключевых операций.
Подсистема Fabric, находящаяся на стадии экспериментальной разработки, предназначена для оптимизации коммуникации между несколькими графическими процессорами (GPU) и повышения масштабируемости системы VibeTensor. Целью разработки является снижение задержек и увеличение пропускной способности при обмене данными между GPU, что критически важно для обучения и инференса больших моделей на распределенных системах. Текущая реализация Fabric использует специализированные протоколы и алгоритмы для эффективной передачи данных, позволяя потенциально снизить накладные расходы, связанные с традиционными методами межпроцессорного взаимодействия.
Система разработана и протестирована на GPU NVIDIA, включая архитектуры H100 (SM90) и Blackwell (SM103). При использовании Fused Attention на Hopper H100 наблюдается ускорение в 1.54x при прямом проходе и 1.26x при обратном, по сравнению с PyTorch SDPA/FlashAttention. Однако, при обработке небольших пакетов данных, производительность снижается до 0.67x при прямом проходе и 0.66x при обратном, по сравнению с FlashAttention.
Валидация и Поддержка Системы
Функциональность VibeTensor подвергается всесторонней проверке с использованием двух основных фреймворков тестирования: CTests, разработанного для C++, и pytest, применяемого в среде Python. CTests обеспечивает проверку низкоуровневых компонентов и производительности критически важных участков кода, в то время как pytest используется для модульного и интеграционного тестирования высокоуровневых API и функциональности, написанной на Python. Совместное использование этих двух фреймворков позволяет охватить широкий спектр тестов, включая юнит-тесты, интеграционные тесты и тесты производительности, обеспечивая надежность и стабильность системы.
Для обеспечения совместимости с существующими фреймворками, такими как PyTorch, в VibeTensor реализован инструмент проверки паритета API. Этот инструмент автоматически сравнивает API VibeTensor с API PyTorch, гарантируя, что функции и параметры соответствуют ожиданиям пользователей, переходящих с PyTorch. Проверка охватывает сигнатуры функций, типы данных и семантику, выявляя любые расхождения, которые могут привести к проблемам совместимости или потребовать адаптации кода. Это позволяет разработчикам использовать VibeTensor с минимальными изменениями в существующем коде, написанном для PyTorch.
Система VibeTensor разработана для работы в среде Linux на архитектуре x86_64 и поддерживает пользовательские интерфейсы, написанные как на Python, так и на Node.js. На текущий момент скорость обучения составляет 1,7-6,2 раза ниже, чем у PyTorch. Тем не менее, продемонстрирована масштабируемость на нескольких GPU (до четырех) на архитектуре Blackwell при использовании слабого масштабирования (fixed per-GPU batch), что позволяет увеличить общую пропускную способность системы.
Представленная работа демонстрирует, что создание полноценного стека программного обеспечения для глубокого обучения, от Python-интерфейсов до CUDA-ядер, может быть автоматизировано с помощью искусственного интеллекта. Это подчеркивает важность понимания системы как единого целого, где изменения в одной части неизбежно влияют на другие. Как отмечал Марвин Минский: «Искусственный интеллект не может решить все проблемы, но он может помочь нам лучше понять их.» В данном исследовании, автоматическая генерация кода и последующее тестирование подтверждают, что элегантность и эффективность системы рождаются из простоты и ясности структуры, а не из сложности отдельных компонентов. Именно целостный подход к архитектуре, где каждый элемент взаимосвязан, позволяет создавать надежные и масштабируемые решения в области глубокого обучения.
Куда Далее?
Представленная работа демонстрирует принципиальную возможность автоматической генерации стека программного обеспечения для глубинного обучения. Однако, следует признать, что элегантность этой автоматизации пока скрыта за сложностью самой задачи. Успех не означает отсутствие компромиссов; скорее, он указывает на необходимость более глубокого понимания того, что именно мы оптимизируем. В стремлении к автоматизации, легко упустить из виду фундаментальные ограничения аппаратного обеспечения и алгоритмические особенности, которые определяют реальную производительность.
Дальнейшие исследования должны быть сосредоточены не только на улучшении алгоритмов генерации кода, но и на разработке более эффективных методов верификации и валидации сгенерированного программного обеспечения. Автоматизированные тесты, безусловно, важны, но они не могут заменить глубокий анализ архитектуры и её соответствия поставленным задачам. Зависимость от автоматизации — это цена свободы от рутинной работы, но эта цена может оказаться непомерно высокой, если не учитывать потенциальные риски.
В конечном счёте, истинный прогресс заключается не в создании более сложных систем, а в разработке более простых и понятных решений. Хорошая архитектура незаметна, пока не ломается, и только время покажет, насколько устойчива и масштабируема предложенная система. Необходимо помнить, что простота масштабируется, изощрённость — нет.
Оригинал статьи: https://arxiv.org/pdf/2601.16238.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Иллюзии понимания: Почему нейросети нас обманывают
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-27 03:55