Автор: Денис Аветисян
Исследователи представили ChartVerse — инновационную систему для генерации сложных данных, позволяющую обучать модели машинного обучения, превосходящие существующие решения в интерпретации графиков и диаграмм.
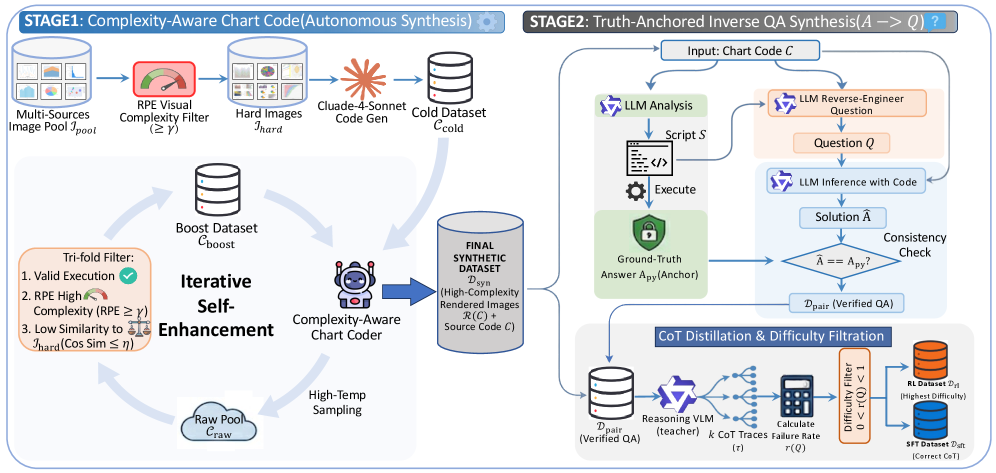
ChartVerse использует надежный программный синтез для создания высококачественных данных, необходимых для обучения визуально-языковых моделей (VLM) в задачах анализа графиков.
Несмотря на значительные успехи в области мультимодальных моделей, обучение надежному пониманию графиков остается сложной задачей из-за нехватки качественных обучающих данных. В данной работе представлена система ‘ChartVerse: Scaling Chart Reasoning via Reliable Programmatic Synthesis from Scratch’, предлагающая масштабируемый подход к синтезу сложных графиков и соответствующих вопросов-ответов с обоснованными рассуждениями. Ключевым нововведением является генерация данных на основе детерминированных ответов, извлеченных из исходного кода, что позволяет создавать сложные примеры и обеспечивать согласованность. Может ли предложенный подход к синтезу данных стать основой для создания новых, более эффективных моделей визуального рассуждения?
Вызов понимания графиков: Преодоление сложностей визуализации данных
Современные системы ответов на вопросы, основанные на анализе графиков, демонстрируют существенные трудности при работе со сложными визуализациями данных. Для достижения приемлемого уровня производительности этим системам требуются колоссальные объемы обучающих данных, что связано с необходимостью обработки огромного количества примеров. Проблема заключается не только в объеме, но и в сложности: системы испытывают трудности с интерпретацией взаимосвязей, представленных в многослойных графиках, и часто допускают ошибки при анализе данных, требующих нетривиальных логических выводов. В результате, даже при наличии больших данных, обобщающая способность таких систем остается ограниченной, что препятствует их эффективному применению в реальных задачах анализа информации.
Существующие наборы данных для обучения систем ответов на вопросы по графикам часто оказываются недостаточно разнообразными и сложными, что серьезно ограничивает их способность к обобщению и применению в реальных условиях. Большинство этих наборов данных содержат упрощенные визуализации и вопросы, не отражающие всего спектра сложности, встречающейся в реальных информационных графиках и отчетах. В результате, системы, хорошо работающие на этих ограниченных наборах, демонстрируют значительное снижение производительности при столкновении с более сложными и неструктурированными данными. Эта проблема особенно актуальна для задач, требующих не просто извлечения данных, но и логического анализа, сопоставления информации и вывода новых знаний на основе визуализации, что существенно ограничивает потенциал автоматизированного анализа данных.
Существенным препятствием для развития систем, способных отвечать на вопросы по диаграммам, является недостаток методов для генерации обучающих данных, охватывающих широкий спектр сложности визуализаций и типов вопросов. В настоящее время создание достаточного количества разнообразных и сложных примеров для обучения моделей требует значительных усилий и ресурсов. Ограниченность существующих подходов к генерации данных приводит к тому, что модели часто демонстрируют низкую обобщающую способность и испытывают трудности при анализе диаграмм, отличающихся от тех, на которых они были обучены. Разработка автоматизированных и эффективных методов генерации обучающих данных, способных создавать сложные сценарии и вопросы различного типа, представляется ключевой задачей для достижения существенного прогресса в области понимания диаграмм и создания интеллектуальных систем анализа данных.

ChartVerse: Синтез данных для надежного рассуждения
Фреймворк ChartVerse разработан для преодоления ограничений существующих наборов данных для рассуждений на основе графиков, в частности, недостаточного масштаба, разнообразия и сложности. Существующие наборы данных часто не обеспечивают достаточного количества примеров для эффективного обучения моделей, что ограничивает их обобщающую способность. Кроме того, они могут быть недостаточно разнообразными в плане типов графиков, представленных данных и требуемых рассуждений. ChartVerse решает эти проблемы путем синтеза данных, что позволяет создавать практически неограниченное количество обучающих примеров с контролируемыми характеристиками сложности и распределения данных, обеспечивая более надежное и точное обучение моделей.
В основе ChartVerse лежит генерация графиков посредством программного кода, что позволяет осуществлять точный контроль над их сложностью и распределением данных. Сложность и разнообразие генерируемых графиков количественно оценивается с помощью метрики Rollout Posterior Entropy (RPE) — RPE — которая измеряет неопределенность, связанную с последовательностью действий, необходимых для создания графика. Использование RPE позволяет систематически варьировать сложность и распределение данных, обеспечивая создание наборов данных с контролируемыми характеристиками и преодолевая ограничения, связанные с ручной аннотацией и естественным распределением данных в существующих наборах данных.
Использование синтетических данных в ChartVerse позволяет генерировать практически неограниченное количество обучающих примеров, устраняя зависимость от трудоемкой и дорогостоящей ручной аннотации. Этот подход позволил модели ChartVerse-8B превзойти свою учительскую модель, Qwen3-VL-30B-A3B-Thinking, что демонстрирует эффективность масштабируемого обучения на сгенерированных данных. Отсутствие ограничений, связанных с ручным сбором данных, обеспечивает возможность обучения моделей на более широком и разнообразном наборе примеров, что способствует повышению их обобщающей способности и производительности в задачах анализа графиков.
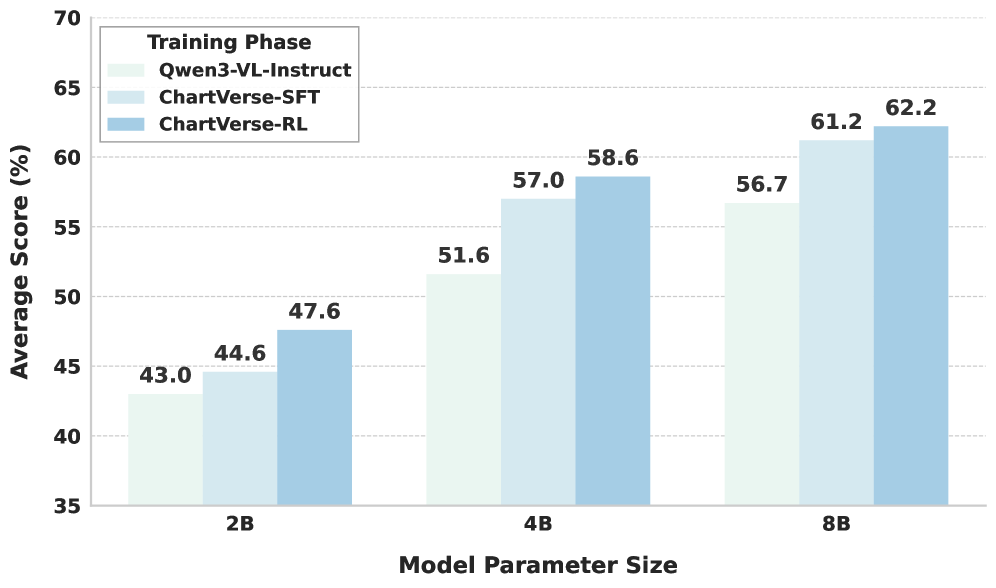
Улучшение рассуждений с помощью обучения, учитывающего сложность
ChartVerse использует модуль кодирования диаграмм с учетом сложности (Complexity-Aware Chart Coder), управляемый метрикой RPE (Reasoning Path Estimation). Этот модуль предназначен для автоматической генерации обучающих диаграмм, сложность которых постепенно увеличивается в процессе тренировки модели. RPE оценивает когнитивную нагрузку, необходимую для решения задачи на основе диаграммы, что позволяет системе создавать диаграммы, требующие все более сложных рассуждений. Автоматическая генерация данных с контролируемым уровнем сложности позволяет эффективно обучать модели решению задач, требующих анализа визуальной информации и логических выводов, без необходимости ручной разработки сложных сценариев.
В основе ChartVerse лежит генерация данных, обеспечивающая их высокое качество и развитие навыков логического мышления. Для этого используются методы Truth-Anchored Inverse QA Synthesis и CoT Distillation. Truth-Anchored Inverse QA Synthesis позволяет создавать вопросы, ответы на которые однозначно определяются данными на графике, что обеспечивает соответствие с фактами. CoT Distillation (Distillation Chain of Thought) использует знания, полученные от более крупных моделей, для обучения более компактных моделей формированию цепочек рассуждений, необходимых для решения задач на основе графиков. Комбинация этих подходов позволяет создавать обучающие данные, стимулирующие развитие надёжных навыков логического вывода.
Крупные языковые модели, такие как Qwen3-VL-30B-A3B-Thinking, играют ключевую роль в процессе обучения ChartVerse, выполняя две основные функции: оценку сложности графиков и роль модели-учителя для дистилляции знаний. В ходе экспериментов, модель ChartVerse-8B, обученная с использованием данной инфраструктуры, продемонстрировала средний результат в 64.1 балла по ряду бенчмарков, что превосходит показатель Qwen3-VL-30B-A3B-Thinking, составивший 62.9 балла. Это указывает на эффективность подхода, основанного на использовании крупных моделей для оценки сложности данных и передачи знаний в процессе обучения.

Широкое влияние и будущие направления
Разработанная платформа ChartVerse успешно протестирована на разнообразных наборах данных, включая ChartBench, ChartX, CharXiv, ChartMuseum и EvoChart, что наглядно демонстрирует её универсальность и масштабируемость. Успешное применение к этим различным источникам данных подтверждает способность ChartVerse эффективно анализировать и интерпретировать информацию, представленную в графическом виде, независимо от специфики или сложности диаграмм. Такая адаптивность позволяет использовать платформу в широком спектре научных и практических задач, требующих автоматизированного понимания визуальных данных, и закладывает основу для дальнейшего расширения её функциональности и применения в новых областях.
В основе разработанной системы оценки лежит использование больших языковых моделей (LLM) в качестве автоматизированного судьи, что обеспечивает надежный и воспроизводимый процесс проверки корректности ответов. Применение данной методики к датасету CharXiv, с использованием данных, отобранных методом RPE (Retrieval-based Performance Estimation), позволило достичь показателя точности в 78.6%. Этот подход значительно упрощает и ускоряет процесс оценки, исключая необходимость ручной проверки и обеспечивая объективность результатов, что особенно важно при работе с большими объемами данных и сложными задачами анализа графической информации.
Дальнейшие исследования направлены на усовершенствование методов обучения модели ChartVerse, включая применение обучения с подкреплением (RL) и контролируемой тонкой настройки (SFT). Анализ данных, отобранных методом RPE, показывает, что текущий уровень ошибок составляет 27.6%, что несколько выше, чем при использовании VLM-as-Judge — 21.1%. Оптимизация этих методов позволит повысить не только общую производительность, но и надежность логических заключений модели, что критически важно для точной интерпретации графических данных и обеспечения достоверности получаемых результатов. Ожидается, что применение более продвинутых техник обучения существенно снизит количество ошибок и повысит уверенность в правильности ответов модели ChartVerse.

Представленная работа демонстрирует стремление к математической чистоте в области визуального анализа данных. ChartVerse, как фреймворк для генерации данных для обучения моделей, акцентирует внимание на создании надежного и непротиворечивого синтеза данных, что является ключевым для достижения высокой производительности в задачах анализа диаграмм. Как однажды заметил Эндрю Ын: «Машинное обучение — это процесс автоматизации обучения, а не замена интеллекта». Данный подход к синтезу данных позволяет создавать более сложные и реалистичные сценарии, необходимые для обучения моделей, способных к надежному решению задач, связанных с интерпретацией графиков и диаграмм.
Куда Далее?
Представленная работа, бесспорно, демонстрирует возможность конструирования синтетических данных, способных улучшить производительность моделей в задаче интерпретации графиков. Однако, триумф над текущими бенчмарками не должен заслонять более фундаментальный вопрос: действительно ли текущие метрики отражают истинное понимание, или же это лишь иллюзия, созданная искусственно подобранными примерами? Неизбежно возникает потребность в более строгих, формально верифицируемых задачах, где решение должно быть доказуемо корректным, а не просто «работать» на тестовом наборе.
Очевидным направлением для дальнейших исследований представляется минимизация избыточности в процессе генерации данных. Каждый дополнительный параметр, каждый случайный элемент — это потенциальная точка отказа, возможность привнесения ошибки. Алгоритм должен быть элегантным в своей простоте, а не перегруженным ненужными деталями. Необходимо стремиться к созданию данных, которые требуют от модели не просто распознавания паттернов, но и способности к абстрактному мышлению и логическому выводу.
В конечном счете, успех в области интерпретации графиков зависит не от количества синтезированных данных, а от качества алгоритмов, лежащих в их основе. Необходимо переходить от эмпирических подходов к формальным методам, от «черных ящиков» к прозрачным и доказуемо корректным системам. Иначе, все усилия рискуют оказаться лишь временным улучшением, а не принципиальным прорывом.
Оригинал статьи: https://arxiv.org/pdf/2601.13606.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Иллюзии понимания: Почему нейросети нас обманывают
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-27 05:28