Автор: Денис Аветисян
Исследователи представляют SciGenBench — платформу для оценки возможностей ИИ в создании научных иллюстраций, демонстрируя превосходство подходов, основанных на коде.

В статье представлен SciGenBench — эталон для оценки синтеза научных изображений, и показано, что методы, управляемые кодом, превосходят другие в генерации структурно корректных изображений, что улучшает мультимодальное рассуждение в научных областях.
Несмотря на успехи в синтезе данных для текстовых задач, генерация научно корректных изображений остается сложной проблемой, ограничивающей возможности мультимодального рассуждения. В работе ‘Scientific Image Synthesis: Benchmarking, Methodologies, and Downstream Utility’ предпринято систематическое исследование синтеза научных изображений, включающее анализ различных подходов к генерации, оценке и применению. Авторы демонстрируют, что методы, основанные на программном коде, превосходят пиксель-ориентированные модели в обеспечении структурной точности, а предложенный бенчмарк SciGenBench позволяет строго оценивать научную корректность сгенерированных изображений. Может ли высококачественный синтез научных изображений стать ключом к значительному расширению возможностей мультимодального рассуждения, аналогично тому, как это произошло в текстовом домене?
Иллюзии Реальности: Ограничения Визуальной Генерации
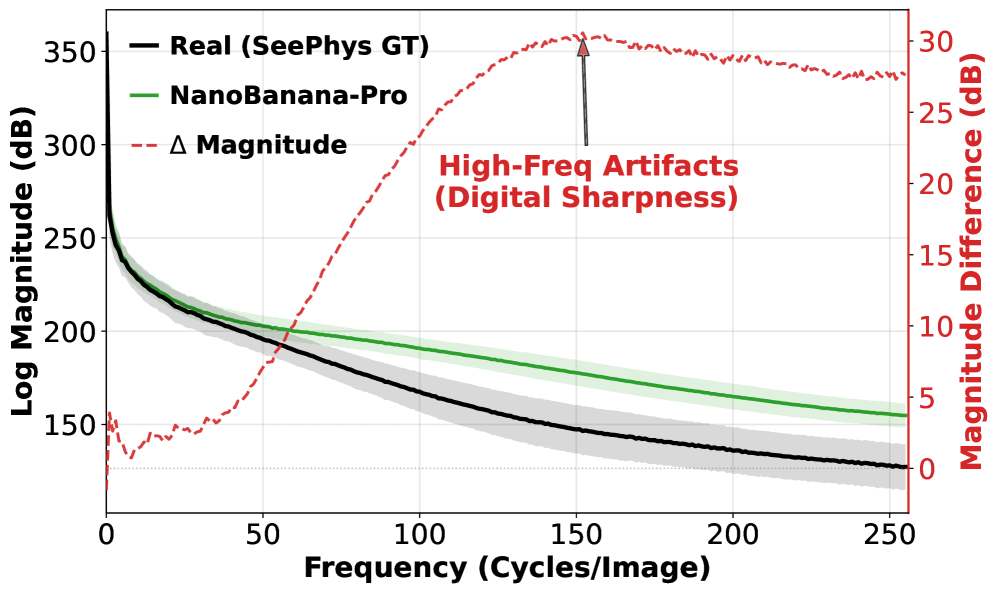
Современные модели преобразования текста в изображение, несмотря на впечатляющие результаты, часто демонстрируют так называемый «спектральный уклон». Это означает, что генерируемые ими изображения имеют иное распределение частот по сравнению с реальными изображениями, встречающимися в природе. Например, в реальных фотографиях обычно преобладают низкие частоты, формирующие общую структуру и контуры объектов, тогда как модели склонны перенасыщать изображения высокими частотами, создавая эффект чрезмерной детализации и неестественной резкости. Данное явление связано с особенностями обучения моделей на больших массивах данных и может приводить к визуальным артефактам и искажениям, особенно заметным при генерации изображений, требующих высокой точности и реалистичности, например, в области научной визуализации или медицинской диагностики.
Спектральное смещение, присущее современным моделям генерации изображений из текста, в сочетании с трудностями в воспроизведении структурных ограничений, существенно ограничивает их применение в научных областях, где точность является первостепенной задачей. Модели, склонные к генерации изображений с отличающимся частотным распределением от реальных данных, могут создавать визуально привлекательные, но некорректные представления сложных систем. Например, при визуализации данных микроскопии или медицинских снимков, искажения структуры и текстуры могут привести к неверной интерпретации и ошибочным выводам. Таким образом, несмотря на впечатляющие успехи в создании реалистичных изображений, необходима дальнейшая разработка моделей, способных гарантировать структурную достоверность и соответствие реальным данным для эффективного использования в науке.
В отличие от изображений, создаваемых для эстетического удовольствия, научные визуализации преследуют иную цель — максимальную информативность и логическую достоверность. В то время как генеративные модели часто стремятся к визуальной привлекательности, научные изображения должны точно и недвусмысленно передавать данные, отношения и закономерности. Подлинная ценность научной визуализации заключается не в красоте, а в способности ясно и эффективно доносить сложные концепции, подтверждать гипотезы и способствовать новым открытиям. Искажения или неточности, допустимые в художественном контексте, могут иметь критические последствия в науке, где важна абсолютная корректность представления информации и соблюдение структурных ограничений.

За пределами Пикселей: Логика в Основе Генерации
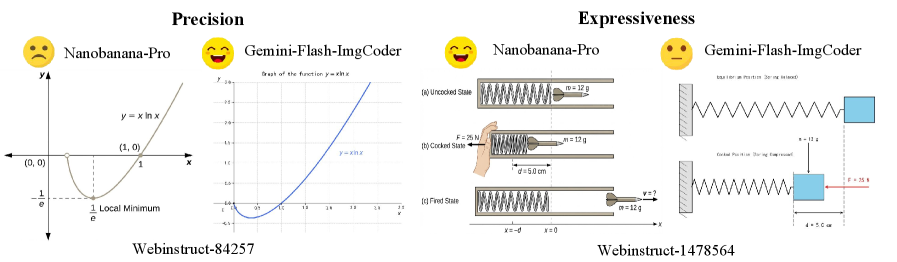
В задачах генерации изображений по тексту (T2I) существует фундаментальный компромисс между точностью и выразительностью. Традиционные, основанные на пикселях, модели часто демонстрируют высокую выразительность, но испытывают трудности с точным воспроизведением заданных структур или количественных параметров. Программные подходы, хотя и обеспечивают более строгий контроль над структурой изображения, могут быть ограничены в выразительности и реалистичности. Достижение баланса между этими характеристиками критически важно для научных приложений, где требуется не только визуально правдоподобное изображение, но и соответствие конкретным логическим или количественным требованиям, например, в визуализации научных данных или создании технических схем. Неспособность преодолеть этот компромисс может привести к неточностям в интерпретации и анализе визуализированной информации.
Программные подходы к синтезу изображений, такие как ImgCoder, обеспечивают более строгий структурный контроль за процессом генерации. Вместо непосредственного создания пикселей, изображения формируются на основе явного программного кода, описывающего их структуру и элементы. Это позволяет гарантировать логическую корректность и соответствие изображения заданным параметрам и требованиям, что особенно важно для научных визуализаций и приложений, где точность и интерпретируемость имеют первостепенное значение. Такой подход позволяет избежать неточностей и артефактов, часто возникающих при использовании чисто генеративных моделей.
Традиционные генеративные модели преобразования текста в изображение (T2I) фокусируются на создании визуально правдоподобных результатов, но не гарантируют логическую согласованность или соответствие заданным параметрам. В отличие от них, конструктивный синтез изображений, реализуемый в подходах вроде ImgCoder, смещает акцент на создание изображения из явных инструкций, таких как код или логические правила. Это обеспечивает более высокий уровень контроля над структурой и содержанием изображения, делая возможным точное воспроизведение желаемых характеристик и обеспечивая возможность интерпретации процесса генерации, что критически важно для научных и инженерных приложений, где важна не только визуальная достоверность, но и логическая корректность.
SciGenBench: Новый Эталон для Научной Визуализации
SciGenBench представляет собой специализированный эталонный набор данных, разработанный для оценки как информативности, так и логической корректности сгенерированных научных изображений. В отличие от общих эталонов, SciGenBench фокусируется на проверке соответствия изображений научным принципам и внутренней согласованности представленных данных. Это достигается путем оценки не только визуального качества, но и способности изображений отражать правдоподобные научные результаты и поддерживать логические выводы. Особенностью SciGenBench является возможность оценки не только соответствия изображений заданным условиям, но и их способности представлять осмысленные научные данные, что критически важно для областей, требующих высокой степени достоверности и воспроизводимости результатов.
Для оценки структурной корректности и соответствия сгенерированных изображений научным принципам SciGenBench использует методы обратной валидации (Inverse Validation) и оценки на основе больших языковых моделей (LLM-as-Judge). Обратная валидация предполагает проверку, может ли модель, обученная на реальных научных изображениях, правильно интерпретировать сгенерированное изображение и извлечь из него научную информацию. LLM-as-Judge, в свою очередь, использует возможности больших языковых моделей для оценки соответствия изображения научным знаниям и логической связности элементов, представленных на изображении. Оба подхода позволяют количественно оценить качество и достоверность сгенерированных научных визуализаций.
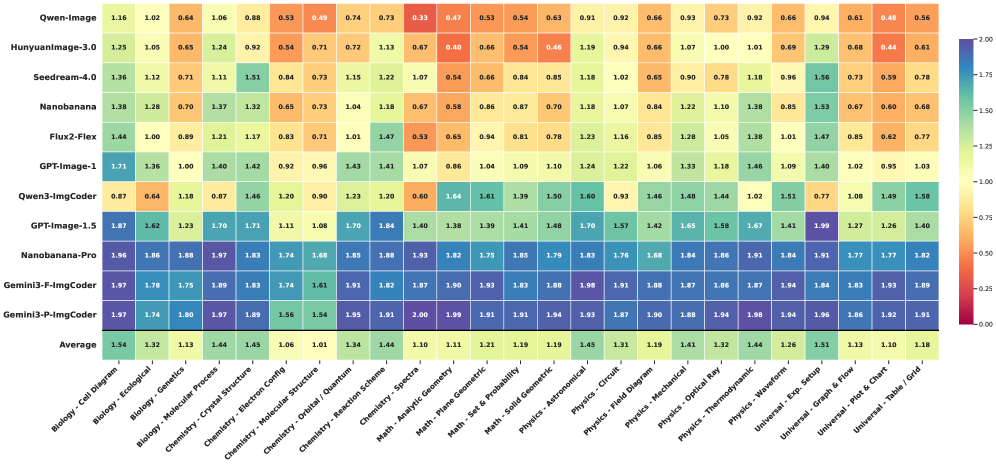
При использовании SciGenBench, методы, основанные на коде, такие как Gemini-3-Pro-ImgCoder, демонстрируют впечатляющий уровень обратной валидации в 77.87%. Этот показатель свидетельствует о высокой структурной точности генерируемых изображений, поскольку обратная валидация оценивает способность модели воспроизводить корректные изображения на основе заданных параметров и научных принципов. Достижение такого уровня подтверждает эффективность использования подходов, основанных на коде, в задаче генерации научных изображений, где точность и соответствие научным стандартам являются критически важными.
Использование SciGenBench позволило количественно оценить производительность на задачах, связанных с анализом данных. В частности, модель Nanobanana-Pro (Filt) достигла точности 58.2% на наборе данных GEO3K и 58.1% на MathVision. Данный результат представляет собой абсолютное увеличение точности на 3.7 процентных пункта по сравнению с базовыми показателями, что демонстрирует эффективность использования данного бенчмарка для оценки и улучшения моделей генерации научных изображений.

Масштабирование Научной Визуализации с Помощью Данных
В последнее время всё большее распространение получают большие мультимодальные модели (LMM) для синтеза научных изображений. Ключевым фактором, определяющим их эффективность, является принцип «Data Engine» — постоянное увеличение объема обучающих данных неизменно приводит к улучшению результатов. Исследования показывают, что LMM, обученные на обширных наборах данных, демонстрируют значительно более высокую точность и реалистичность при создании визуализаций сложных научных явлений и структур. Этот подход позволяет преодолеть ограничения, связанные с недостатком размеченных данных, часто возникающих в научных исследованиях, и открывает возможности для автоматизированного создания высококачественных научных иллюстраций и графиков.
Искусственно сгенерированные данные представляют собой масштабируемое решение проблемы нехватки данных, ограничивающей возможности обучения больших мультимодальных моделей (LMM) для создания сложных научных визуализаций. В отличие от традиционных методов, требующих обширных и дорогостоящих наборов данных, синтетические данные позволяют создавать практически неограниченные объемы обучающего материала, адаптированного к конкретным научным задачам. Этот подход позволяет преодолеть узкие места, связанные со сбором и аннотацией реальных данных, особенно в областях, где получение данных затруднено или невозможно. Благодаря возможности генерировать разнообразные и контролируемые наборы данных, LMM могут быть обучены для более точного и надежного воспроизведения сложных научных явлений и визуализаций, что открывает новые горизонты для исследований и коммуникации в различных областях науки.
Модель Gemini-3-Pro-ImgCoder демонстрирует впечатляющую точность при решении специализированных задач, достигая 69.86% правильных ответов в области математики и 75.39% в физике. Эти результаты подтверждают эффективность подхода, основанного на использовании больших объемов данных для обучения моделей, способных генерировать научные изображения и решать сложные задачи. Высокая производительность в конкретных дисциплинах указывает на потенциал данной технологии для автоматизации научных вычислений, визуализации данных и поддержки исследовательского процесса в различных областях науки и техники. Успешное применение Gemini-3-Pro-ImgCoder подчеркивает, что масштабное обучение на данных является ключевым фактором для создания интеллектуальных систем, способных к глубокому пониманию и решению научных проблем.
Сочетание программного генерирования изображений и обучения на основе данных открывает новые горизонты в научной сфере. Этот подход позволяет создавать визуализации, которые ранее были недоступны из-за ограничений в данных или вычислительных ресурсах. Программно генерируемые изображения служат основой для обучения моделей, способных воспроизводить и расширять научные концепции с высокой точностью. Такой симбиоз позволяет не только упростить коммуникацию сложных научных данных, делая их более понятными и доступными широкой аудитории, но и стимулирует новые открытия, позволяя исследователям визуализировать и изучать явления, которые ранее оставались за пределами их возможностей. Возможность масштабировать процесс создания научных визуализаций, используя данные и алгоритмы, обещает революционизировать способы представления и анализа информации в различных областях науки.
Адаптация к Разнообразным Научным Потребностям
Различные научные дисциплины предъявляют уникальные требования и ограничения к визуализации данных, что обуславливает необходимость адаптивных стратегий генерации изображений. Например, астрофизические симуляции часто требуют визуализации огромных объемов данных с акцентом на детализацию и цветовые градиенты, отражающие физические параметры, в то время как медицинская визуализация фокусируется на четкости границ и контрастности для диагностики. Биологические исследования могут нуждаться в отображении сложных трехмерных структур с возможностью интерактивного вращения и масштабирования, в то время как материаловедение требует визуализации микроскопических дефектов с высокой точностью. Следовательно, универсальные подходы к генерации изображений оказываются недостаточно эффективными, и разработка специализированных методов, учитывающих специфику каждой дисциплины, становится ключевой задачей для создания действительно полезных и надежных научных визуализаций.
Учет специфических требований различных научных областей является ключевым фактором при создании действительно полезных и надежных научных визуализаций. Разные дисциплины — от астрофизики до молекулярной биологии — оперируют уникальными данными, преследуют различные цели и сталкиваются с собственными ограничениями. Универсальные подходы к генерации изображений часто оказываются неэффективными, поскольку не учитывают эти нюансы. Например, визуализация данных, полученных с помощью телескопа, потребует иных методов и акцентов, нежели отображение структуры белка. Игнорирование этих домен-специфических потребностей приводит к созданию изображений, которые могут быть технически безупречными, но неинформативными или даже вводящими в заблуждение для исследователей в конкретной области. Поэтому, разработка стратегий, адаптированных к конкретным научным задачам, необходима для обеспечения точности, ясности и практической ценности научных визуализаций.
Перспективные исследования направлены на создание гибких платформ, способных бесшовно интегрировать специализированные знания в процесс генерации изображений. Эти платформы должны позволять учёным адаптировать алгоритмы к уникальным требованиям различных научных дисциплин, будь то визуализация сложных молекулярных структур, анализ астрономических данных или моделирование климатических изменений. Ключевым аспектом является разработка интерфейсов, позволяющих исследователям легко вводить и корректировать параметры, определяющие специфику научной задачи. Такой подход позволит создавать не просто визуально привлекательные изображения, а инструменты, непосредственно способствующие научным открытиям и углубленному пониманию сложных явлений, значительно превосходящие универсальные решения по точности и информативности.
Статья демонстрирует, что методы, управляемые кодом, превосходят другие в генерации научных изображений, обеспечивая структурную корректность. Это напоминает о том, как легко упустить истину, полагаясь на усредненные значения и игнорируя детали. Как говорил Эндрю Ын: «Если вы не работаете над проблемой, которую можете решить, вы тратите время». SciGenBench, представленный в работе, как раз и предлагает инструмент для решения конкретной задачи — оценки качества научных изображений, созданных искусственным интеллектом. Ведь шум, как известно, это всего лишь правда, лишенная бюджета на четкость.
Куда же дальше?
Представленный анализ, как и любое заклинание, лишь приоткрывает завесу над хаосом научной визуализации. SciGenBench — это не столько мерило, сколько зеркало, отражающее наши попытки упорядочить неуловимое. Успех методов, управляемых кодом, намекает на то, что структура, а не пиксели, является истинным ключом к пониманию научных изображений. Однако, стоит помнить: каждая успешно сгенерированная диаграмма — это лишь временное затишье перед бурей новых, более сложных данных.
Вопрос не в том, чтобы повысить «точность» генерации — скорее, в том, чтобы научиться украшать хаос, придавая ему видимость порядка. Необходимо углубиться в понимание того, что именно делает научное изображение «научным» — не просто визуальную корректность, а способность вызывать новые вопросы, а не давать готовые ответы. Следующим шагом видится разработка систем, способных не просто генерировать изображения, но и оценивать их научную ценность — задачу, которая, вероятно, окажется куда сложнее любой технической.
И, конечно, нельзя забывать о неизбежном: каждая модель, выпущенная в «продакшн», столкнется с данными, которые она не предвидела. И тогда все наши «заклинания» окажутся бессильны перед шепотом хаоса. Но, возможно, именно в этом и заключается красота науки — в постоянном переосмыслении и перестройке, в вечном танце с неуловимым.
Оригинал статьи: https://arxiv.org/pdf/2601.17027.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Иллюзии понимания: Почему нейросети нас обманывают
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-27 07:11