Автор: Денис Аветисян
В статье представлены строгие оценки ошибок, возникающих при использовании вычислительных графов распределений, что позволяет более точно оценивать и контролировать распространение погрешностей в сложных вычислениях.
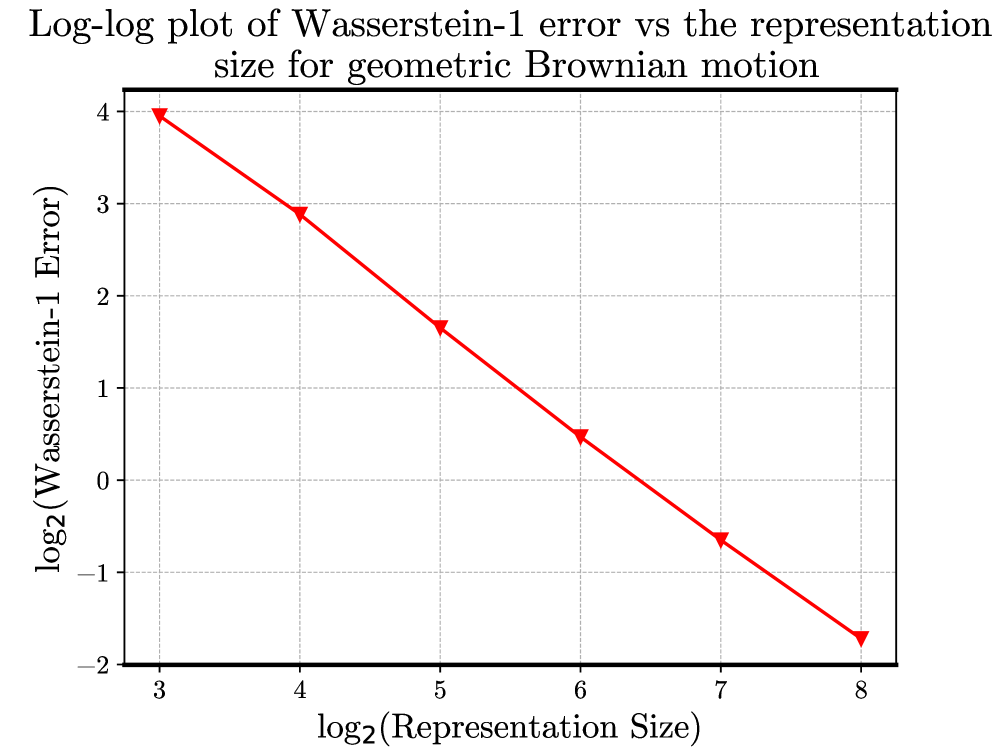
Исследование устанавливает условия для точного детерминированного приближения методов Монте-Карло на основе вычислительных графов распределений с использованием метрики Вассерштейна.
Несмотря на широкое применение вычислительных графов, оценка ошибок при работе с вероятностными распределениями в качестве входных данных остается сложной задачей. В работе ‘Distributional Computational Graphs: Error Bounds’ исследуется общий фреймворк распределительных вычислительных графов и анализируется погрешность дискретизации, возникающая при аппроксимации непрерывных распределений. Получены неасимптотические оценки ошибок в метрике Вассерштейна-1, не требующие каких-либо структурных предположений о графе. Каковы перспективы применения полученных результатов для разработки более надежных и эффективных методов Монте-Карло и приближенного детерминированного вычисления?
За пределами традиционных вычислений: распределенные графы вероятностей
Традиционные вычислительные графы, являясь основой многих современных алгоритмов, оперируют фиксированными значениями, что существенно ограничивает их применимость в задачах, где присутствует неопределенность. В реальном мире большинство данных и процессов характеризуются вероятностным характером: от шума в сенсорах и ошибок измерений до колебаний рыночных цен и вариативности поведения пользователей. Использование детерминированных значений в таких сценариях приводит к неточным результатам и неспособности адекватно оценить риски. Например, в задачах машинного обучения, игнорирование неопределенности может привести к переобучению модели и ее неэффективности на новых данных. Вследствие этого, возникает необходимость в более гибких моделях, способных оперировать не конкретными числами, а целыми распределениями вероятностей, отражающими степень уверенности в каждом значении.
Традиционные вычислительные графы, несмотря на свою эффективность в задачах с чётко определенными значениями, сталкиваются с существенными ограничениями при работе с неопределенностью, свойственной большинству реальных сценариев. Основная проблема заключается в неспособности напрямую представлять и обрабатывать вероятностные распределения. Это приводит к тому, что модели, основанные на фиксированных значениях, могут давать неоптимальные или даже ошибочные результаты в ситуациях, когда входные данные содержат шум или неполную информацию. Отсутствие встроенной поддержки для работы с вероятностями существенно затрудняет принятие надежных решений, особенно в областях, требующих оценки рисков и прогнозирования, поскольку модели не способны учитывать различные возможные исходы и их вероятности. В результате, даже незначительные отклонения во входных данных могут привести к значительным ошибкам в результатах, что снижает общую надежность и устойчивость системы.
Расширяя возможности традиционных вычислительных графов, распределительные вычислительные графы (Distributional Computational Graphs) работают непосредственно с вероятностными распределениями, а не с фиксированными значениями. Это позволяет моделировать и учитывать неопределенность, присущую многим реальным задачам, таким как распознавание образов, робототехника и принятие решений в условиях риска. Вместо того чтобы просто вычислять одно значение, эти графы оперируют целыми распределениями вероятностей, позволяя оценивать не только наиболее вероятный результат, но и диапазон возможных исходов и их соответствующие вероятности. Такой подход открывает новые возможности для вероятностного вывода и принятия более обоснованных решений, поскольку позволяет учитывать степень уверенности в каждом этапе вычислений и распространять эту неопределенность по всей вычислительной сети. P(x|y) = \frac{P(y|x)P(x)}{P(y)} — это лишь один пример вероятностной зависимости, которую можно эффективно моделировать с помощью данной структуры.
Аппроксимация и эффективность: квантование и сжатие
Представление непрерывных распределений вероятностей требует бесконечных вычислительных ресурсов для точного описания каждого возможного значения. На практике это недостижимо. Квантование предлагает решение данной проблемы путем дискретизации пространства возможных значений, то есть разбиения его на конечное число интервалов или «ячеек». Каждому интервалу присваивается определенное значение или вероятность, что позволяет аппроксимировать непрерывное распределение с использованием конечного числа параметров. Таким образом, квантование позволяет перейти от бесконечного пространства к конечному, делая вычисления практически реализуемыми, хотя и вносит определенную погрешность аппроксимации.
Непосредственное квантование, хотя и позволяет дискретизировать непрерывные вероятностные распределения, может приводить к существенной потере информации. Для минимизации этой потери и одновременного снижения вычислительных затрат используются алгоритмы сжатия данных. Эти алгоритмы стремятся к эффективному представлению квантованных данных, используя различные методы кодирования и отбрасывая избыточную информацию, что позволяет уменьшить объем памяти, необходимый для хранения и обработки данных, и ускорить вычисления, сохраняя при этом приемлемый уровень точности.
Комбинирование квантования и сжатия позволяет аппроксимировать вероятностные распределения с контролируемой погрешностью. В частности, для гауссовских распределений удается добиться границы погрешности, масштабирующейся как O(2-n) с увеличением уровня квантования (n). Это означает, что при увеличении числа уровней квантования, погрешность аппроксимации экспоненциально уменьшается, обеспечивая более точное представление исходного распределения. Такой подход позволяет эффективно представлять непрерывные распределения, сохраняя приемлемый уровень точности при ограниченных вычислительных ресурсах. O(2^{-n}) обозначает асимптотическую сложность, указывающую на экспоненциальное уменьшение ошибки с ростом n.
Гарантия точности: границы ошибок и липшицева непрерывность
Схема Эйлера-Маруямы представляет собой итеративный метод решения стохастических дифференциальных уравнений в рамках распределительного подхода. Вместо вычисления точного решения в каждой точке времени, схема аппроксимирует решение как последовательность случайных переменных, определяемых рекуррентной формулой. Каждая итерация схемы производит новое приближение к распределению решения, которое затем используется для вычисления следующего приближения. Этот процесс повторяется до тех пор, пока не будет достигнута желаемая точность или не будет выполнено заданное количество итераций. Использование распределительного подхода позволяет учитывать неопределенность, связанную со стохастическими процессами, и получать статистически обоснованные результаты.
Точность схемы Эйлера-Маруямы, как и любого вычисления с распределениями, ограничена ошибками аппроксимации, возникающими на каждом шаге итерации. Поэтому разработка надежных границ ошибок является критически важной для обеспечения достоверности результатов. Эти границы позволяют оценить максимальное отклонение между истинным распределением и его аппроксимацией, полученной в результате численного решения. Наличие таких границ необходимо для валидации модели, контроля качества вычислений и определения требуемой точности аппроксимации, что особенно важно при работе с вероятностными моделями и стохастическими процессами. Например, границы ошибок позволяют определить минимальный шаг интегрирования или размер сетки, необходимые для достижения заданной точности.
Теоретически доказано, что расстояние Вассерштейна-1 между истинным и квантованным распределениями выходных данных масштабируется в соответствии с константами Липшица функций, присутствующих в графе. Данная зависимость формализуется выражением W1(μΔ, μΔ(n)) ≤ ∑s∈𝖲∑γ∈𝖯(s, Δ)W1(μs, μs(n)) ∏e∈γ‖fe+‖Lip, где W1 обозначает расстояние Вассерштейна-1, μΔ и μΔ(n) — истинное и квантованное распределения соответственно, 𝖲 — множество состояний, 𝖯(s, Δ) — множество путей, а ‖fe+‖Lip — константа Липшица функции fe. Для схемы Эйлера-Маруямы установлена граница ошибки, выражаемая как W1(μk, μk(n)) ≤ c(1+cnΔt)k / 2^n, где c — константа, Δt — шаг по времени, а k — количество итераций.
Извлечение закономерностей: статистики порядка и практические алгоритмы
Во многих областях науки и техники возникает необходимость в извлечении ключевых статистических характеристик из вероятностных распределений. Например, определение квантилей позволяет оценить вероятность наступления определенных событий, что критически важно в управлении рисками, финансовом моделировании и контроле качества. Поиск экстремальных значений, таких как максимальные или минимальные показатели, необходим для обнаружения аномалий, анализа надежности и оптимизации процессов. Эти статистические показатели, будь то медиана, процентили или выбросы, служат основой для принятия обоснованных решений и построения надежных прогнозов в самых разнообразных приложениях — от медицинской диагностики до анализа данных в социальных сетях.
Статистики порядка представляют собой мощный инструмент для анализа значений, характеризующих распределение вероятностей, таких как квантили или экстремальные значения. Однако, эффективность применения этого инструмента напрямую зависит от скорости и точности алгоритмов сортировки, особенно при работе с большими объемами данных. В то время как простейшие алгоритмы сортировки могут быть использованы для небольших выборок, для обработки значительных массивов информации необходимы более сложные и оптимизированные методы, позволяющие извлекать статистические характеристики в разумные сроки. Именно поэтому разработка и анализ эффективных алгоритмов сортировки является ключевым аспектом применения статистик порядка в практических задачах, связанных с обработкой и анализом данных.
Несмотря на свою простоту, алгоритм сортировки пузырьком играет ключевую роль в получении статистик порядка, служа отправной точкой для понимания более сложных методов анализа данных. Именно он демонстрирует базовые принципы организации и обработки информации, необходимые для определения квантилей, экстремальных значений и других важных характеристик распределений вероятностей. Хотя для больших объемов данных существуют значительно более эффективные алгоритмы, сортировка пузырьком позволяет наглядно представить процесс упорядочивания, что необходимо для дальнейшего изучения и разработки вычислительных методов в рамках распределительной вычислительной парадигмы. Этот алгоритм, по сути, является фундаментом, на котором строятся более сложные статистические анализы и инструменты.
Исследование, представленное в данной работе, демонстрирует, что вычислительные графы, оперирующие распределениями, подвержены накоплению ошибок, распространяющихся по всей структуре. Авторы предлагают строгие границы этих ошибок, что позволяет оценить точность детерминированных приближений методов Монте-Карло. В этой связи вспоминается высказывание Симоны де Бовуар: «Старение — это не физический процесс, а исторический». Подобно тому, как время влияет на человека, ошибки, накапливаясь в графе, изменяют его первоначальную форму, искажая результат. Понимание этих искажений, как и осознание течения времени, необходимо для построения адекватной модели и интерпретации полученных данных. Ключевым является не просто вычисление, а понимание того, как ошибки влияют на конечный результат.
Что дальше?
Представленная работа, как и любая попытка обуздать хаос вычислений, лишь демонстрирует, насколько точны наши иллюзии о предсказуемости. Строгие границы ошибок для распределённых вычислительных графов — это не триумф над неопределённостью, а скорее аккуратная фиксация момента, когда мы согласны признать её существование. Очевидно, что истинная проблема не в формализации ошибок, а в самой вере в то, что их можно исчерпывающе описать. Ведь каждая граница ошибки — это лишь условное соглашение, способ убедить себя, что случайность под контролем.
Перспективы, вероятно, лежат в области понимания того, как эти границы ошибок взаимодействуют с человеческим восприятием. Инфляция — это коллективное беспокойство о будущем, а погрешность вычислений — это индивидуальная тревога о правильности результата. Следующим шагом, возможно, станет изучение, как эти страхи влияют на выбор моделей и интерпретацию данных. Не стоит забывать, что даже самая точная модель — это всего лишь проекция наших надежд и предубеждений.
В конечном счёте, задача заключается не в создании идеальных алгоритмов, а в признании, что мир принципиально непредсказуем. И тогда, возможно, удастся построить системы, которые не стремятся к абсолютной точности, а адаптируются к неизбежной неопределённости, как это делает, собственно, сама жизнь.
Оригинал статьи: https://arxiv.org/pdf/2601.16250.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Иллюзии понимания: Почему нейросети нас обманывают
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-27 07:17