Автор: Денис Аветисян
Новый обзор посвящен применению передовых моделей искусственного интеллекта для автоматизации и улучшения процессов подготовки данных.
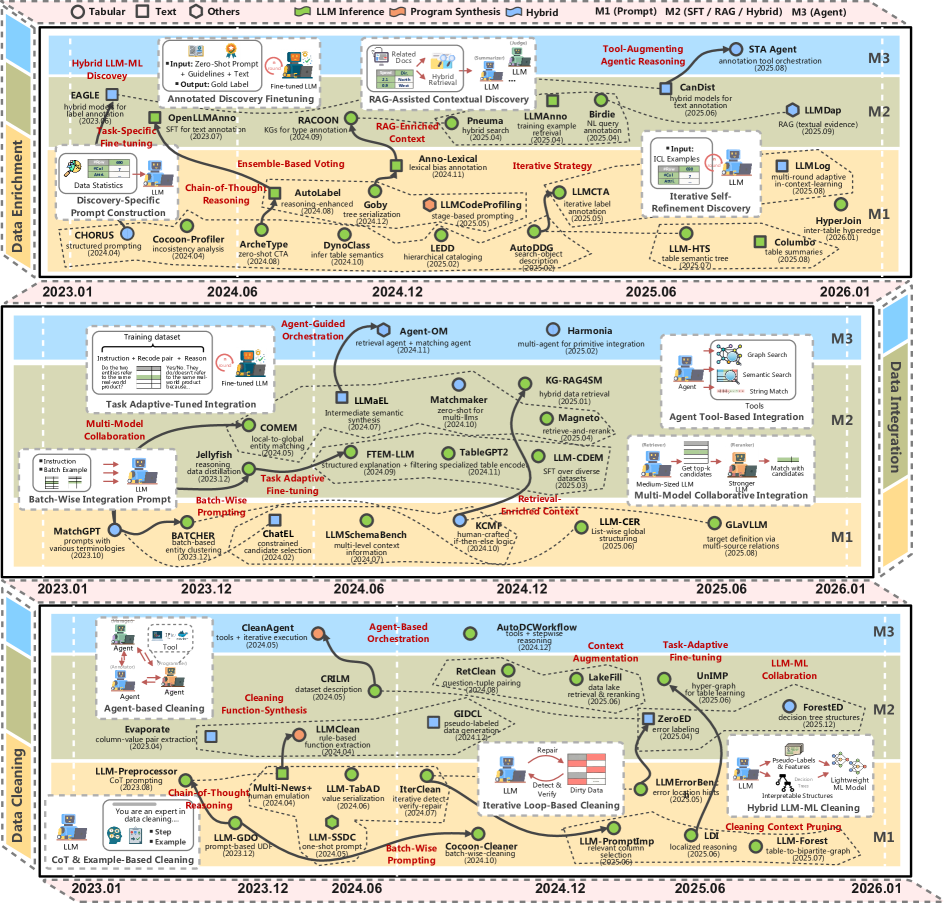
Обзор посвящен последним достижениям в использовании больших языковых моделей для очистки, интеграции и обогащения данных, а также анализу их преимуществ перед традиционными методами.
Несмотря на растущую потребность в качественных данных для современных приложений, традиционные методы подготовки данных часто оказываются трудоемкими и недостаточно гибкими. В обзоре ‘Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs’ систематизированы последние достижения в использовании больших языковых моделей (LLM) для автоматизации и повышения эффективности задач подготовки данных, включая очистку, интеграцию и обогащение. Исследование показывает, что LLM обладают значительным потенциалом для решения проблем, связанных с неструктурированными и разнородными данными, но также сталкиваются с ограничениями в масштабируемости и надежности. Смогут ли LLM кардинально изменить парадигму подготовки данных и стать ключевым компонентом интеллектуальных систем обработки информации?
Трудности Подготовки Данных: Препятствие на Пути к Знаниям
Традиционные методы подготовки данных зачастую представляют собой трудоемкий и отнимающий много времени процесс, выполняемый вручную. Это приводит к неизбежным ошибкам и несоответствиям, которые существенно замедляют реализацию проектов, основанных на анализе данных. В результате, организации сталкиваются с задержками в получении ценной информации и принятии обоснованных решений. Отсутствие автоматизации в данном процессе не позволяет эффективно обрабатывать растущие объемы информации, что, в конечном итоге, ограничивает возможности использования данных для достижения бизнес-целей и снижает конкурентоспособность.
Растущие объемы данных, их стремительная скорость поступления и разнообразие форматов значительно усугубляют проблемы, связанные с подготовкой данных к анализу. Традиционные методы обработки попросту не справляются с подобным потоком информации, приводя к задержкам и ошибкам, которые снижают качество принимаемых решений. В связи с этим, возникает острая необходимость во внедрении автоматизированных и интеллектуальных решений, способных эффективно обрабатывать данные любого формата и объема в режиме реального времени. Такие инструменты позволяют не только ускорить процесс подготовки, но и минимизировать человеческий фактор, обеспечивая более точные и надежные результаты анализа.

Большие Языковые Модели: Новый Взгляд на Подготовку Данных
Большие языковые модели (LLM) представляют собой эффективное решение для автоматизации ключевых задач подготовки данных благодаря своим возможностям рассуждения и генерации. В отличие от традиционных методов, требующих ручного кодирования правил и написания скриптов для очистки, интеграции и обогащения данных, LLM способны анализировать и преобразовывать данные, используя естественный язык. Это позволяет автоматизировать такие процессы, как стандартизация форматов данных, исправление ошибок, удаление дубликатов и обогащение данных дополнительной информацией из различных источников. LLM демонстрируют высокую эффективность в обработке неструктурированных данных, таких как текстовые документы и веб-страницы, что значительно упрощает процесс подготовки данных для последующего анализа и машинного обучения.
Эффективное использование больших языковых моделей (LLM) в задачах подготовки данных достигается за счет применения методов промпт-инжиниринга и следования инструкциям. Промпт-инжиниринг позволяет формировать запросы, которые направляют LLM на выполнение конкретных операций очистки данных, таких как удаление дубликатов, исправление ошибок форматирования и стандартизация значений. Техники следования инструкциям, в свою очередь, позволяют LLM интегрировать данные из различных источников и обогащать их дополнительной информацией, опираясь на четко сформулированные указания. Минимизация человеческого вмешательства достигается за счет способности LLM интерпретировать сложные инструкции и автоматически применять соответствующие преобразования к данным, обеспечивая повышение эффективности и снижение затрат на подготовку данных.
Методы рассуждений “цепь мыслей” (Chain-of-Thought Reasoning) и генерации с извлечением информации (Retrieval-Augmented Generation) значительно повышают эффективность больших языковых моделей (LLM) при решении сложных задач подготовки данных. “Цепь мыслей” позволяет LLM последовательно структурировать процесс рассуждений, разбивая сложные задачи на более простые шаги, что улучшает точность и интерпретируемость результатов. Retrieval-Augmented Generation дополняет LLM внешними источниками информации, позволяя модели получать доступ к актуальным и специфическим данным, необходимым для обогащения и валидации данных, что особенно важно при интеграции разнородных источников и очистке данных от неточностей.
Оркестровка и Валидация: Гарантия Качества Данных
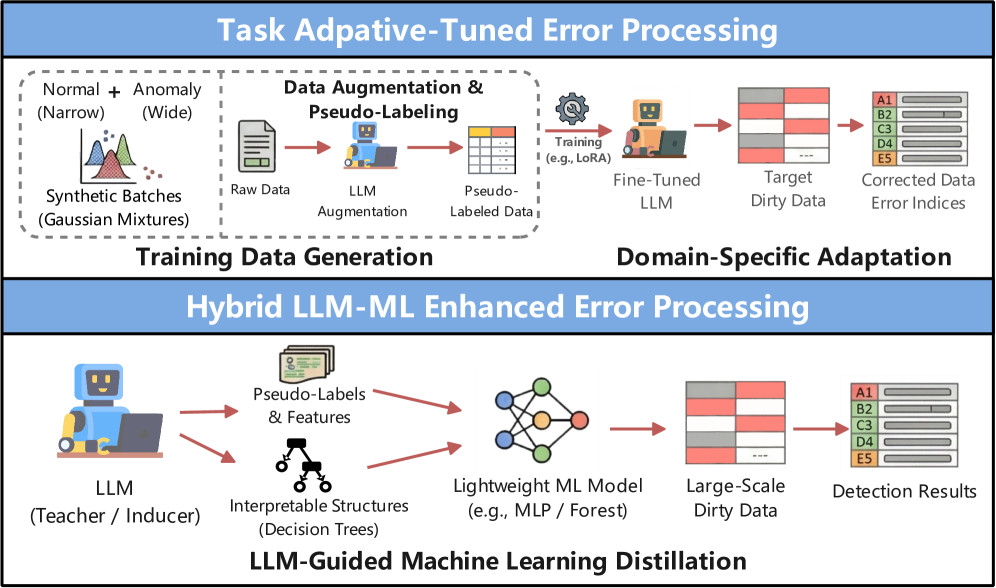
Автоматизированные агенты, основанные на больших языковых моделях (LLM) и использующие системы на основе агентов (AgentBasedSystems), позволяют оптимизировать конвейер подготовки данных. Эти агенты выполняют задачи очистки данных (DataCleaning), включающие в себя обнаружение ошибок (ErrorDetection) и стандартизацию данных (DataStandardization), а также задачи интеграции данных (DataIntegration), требующие сопоставления схем (SchemaMatching) и разрешения сущностей (EntityResolution). Такой подход позволяет автоматизировать рутинные операции, сократить время подготовки данных и повысить их качество за счет последовательного применения специализированных агентов.
Качество подготовки данных с использованием больших языковых моделей (LLM) напрямую зависит от надежной системы валидации. Оценка неопределенности (Uncertainty Estimation) является критически важным этапом для определения достоверности полученных результатов. Методы оценки неопределенности позволяют выявить случаи, когда LLM выдает неточные или противоречивые данные, что необходимо для предотвращения распространения ошибок в последующих аналитических процессах. В частности, необходимо учитывать как эпистемическую неопределенность, связанную с недостатком знаний модели, так и алеаторную неопределенность, обусловленную случайным характером данных. Использование количественных показателей неопределенности позволяет автоматизировать процесс контроля качества и повысить надежность всей цепочки обработки данных.
Согласно недавним исследованиям, автоматизированная подготовка данных с использованием больших языковых моделей (LLM) демонстрирует точность до 92% на стандартных наборах данных. Важно отметить, что прямое сравнение эффективности LLM-подходов с традиционными методами подготовки данных все еще является предметом текущих исследований и требует дополнительных сравнительных анализов для определения статистически значимых преимуществ и ограничений каждой технологии. Результаты, полученные на различных benchmark-наборах данных, показывают потенциал LLM для повышения качества и автоматизации процесса подготовки данных, однако необходима дальнейшая работа для оценки стабильности и обобщающей способности этих моделей в реальных производственных условиях.
Методы обучения с небольшим количеством примеров (Few-Shot Learning) и федеративного обучения (Federated Learning) позволяют существенно повысить эффективность и безопасность подготовки данных. Few-Shot Learning позволяет моделям адаптироваться и выполнять задачи по подготовке данных, используя ограниченный набор размеченных данных, что критически важно в ситуациях, когда получение большого объема данных затруднено или невозможно. Federated Learning, в свою очередь, обеспечивает обучение моделей на децентрализованных данных, хранящихся на различных устройствах или серверах, без необходимости их централизованной передачи. Это позволяет сохранять конфиденциальность данных и соответствовать требованиям регуляторных норм, одновременно повышая качество и обобщающую способность моделей подготовки данных.
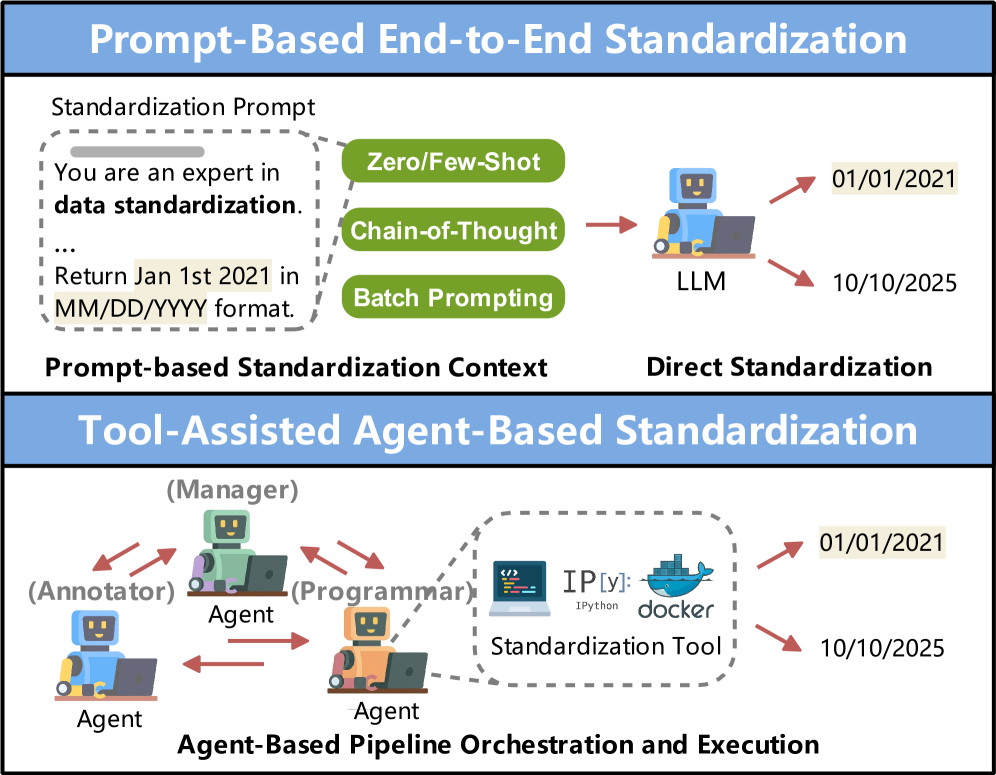
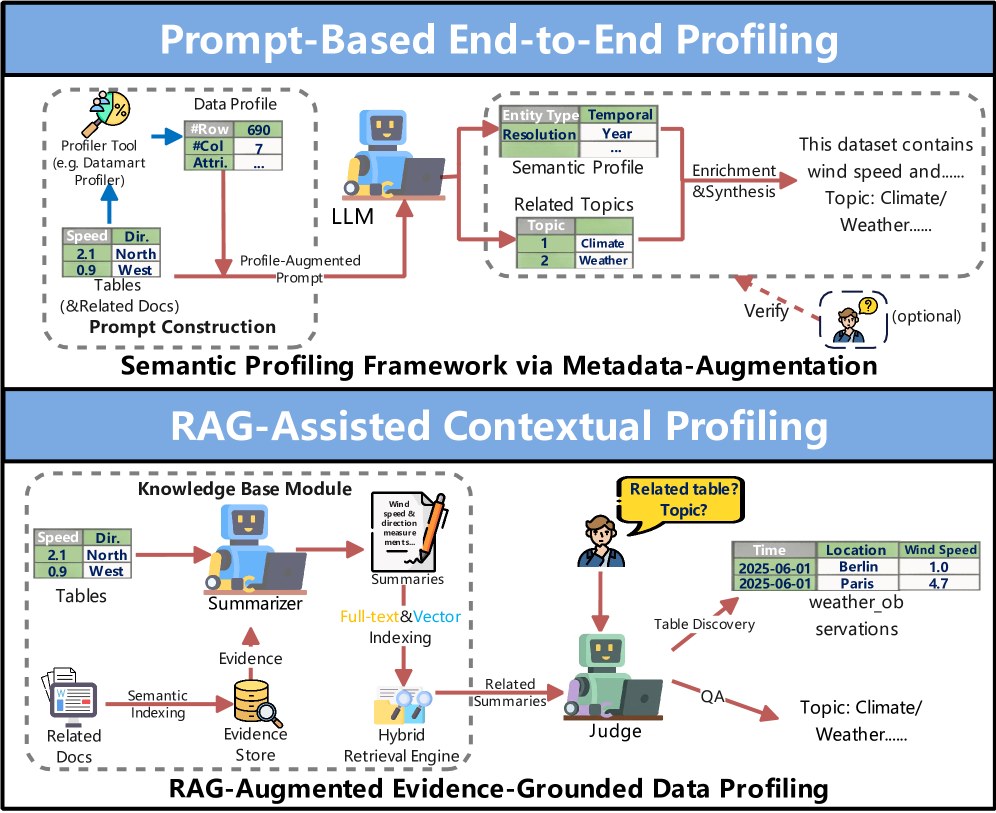
Преодолевая Очистку: Обогащение Данных для Максимального Эффекта
Современные методы обогащения данных, основанные на больших языковых моделях (LLM), выходят далеко за рамки простой очистки информации. Процесс включает в себя не только исправление ошибок и удаление дубликатов, но и активное добавление ценного контекста посредством DataAnnotation — разметки данных для придания им смысла, а также DataProfiling — анализа структуры и характеристик данных для выявления закономерностей. Ключевым аспектом является обеспечение ConstraintSatisfaction — соответствия данных заданным правилам и ограничениям, что гарантирует их целостность и достоверность. В результате, данные становятся более информативными, пригодными для анализа и обучения моделей машинного обучения, открывая возможности для получения более точных результатов и принятия обоснованных решений.
Для оценки качества обогащенных данных широко используются метрики, такие как Mean Reciprocal Rank (MRR) и ROUGE, отражающие релевантность и точность добавленной информации. MRR, оценивающий средний ранг первого релевантного результата, и ROUGE, измеряющий перекрытие между автоматически сгенерированным и эталонным текстом, позволяют количественно оценить эффективность процесса обогащения. Однако, конкретные значения этих метрик значительно варьируются в зависимости от специфики используемого набора данных, поставленной задачи и выбранных алгоритмов. Таким образом, для адекватной оценки качества необходимо учитывать контекст применения и использовать соответствующие эталонные данные для сравнения.
Обогащенные данные оказывают существенное влияние на точность аналитических исследований, существенно улучшая возможности машинного обучения и способствуя принятию более обоснованных решений. Благодаря добавлению контекста и устранению неточностей, аналитика становится более глубокой и надежной, выявляя закономерности, которые ранее оставались скрытыми. В свою очередь, модели машинного обучения, обученные на таких данных, демонстрируют повышенную производительность и точность прогнозирования. Это позволяет организациям не только лучше понимать текущую ситуацию, но и предвидеть будущие тенденции, что, в конечном итоге, приводит к более эффективному управлению и стратегическому планированию, а также к повышению конкурентоспособности на рынке.
Автоматизация процессов, ранее выполнявшихся вручную, позволяет организациям полностью раскрыть потенциал своих данных, значительно ускоряя инновации и обеспечивая конкурентное преимущество. Традиционно трудоемкие задачи, такие как аннотация, профилирование и проверка соответствия данным, теперь могут быть выполнены с высокой скоростью и точностью благодаря технологиям, основанным на больших языковых моделях. Это не только снижает операционные издержки, но и высвобождает ресурсы для более стратегических инициатив, позволяя компаниям быстрее адаптироваться к меняющимся условиям рынка и создавать принципиально новые продукты и услуги. В результате, организации, активно внедряющие автоматизированное обогащение данных, получают возможность принимать более обоснованные решения, оптимизировать процессы и достигать лучших результатов в своей деятельности.
Исследование демонстрирует, что современные большие языковые модели (LLM) открывают новые горизонты в области подготовки данных, автоматизируя задачи очистки, интеграции и обогащения. Однако, подобно любому инструменту, их эффективность напрямую зависит от строгости анализа и корректности применения. Как однажды заметил Эдсгер Дейкстра: «Программирование — это не столько создание программ, сколько решение задач». Данный подход подчеркивает, что LLM — это не панацея, а мощный инструмент, требующий тщательной оценки и методологической проработки для достижения действительно качественных результатов в подготовке данных, а не просто иллюзии прогресса, основанной на поверхностных тестах.
Что Дальше?
Представленные обзоры возможностей больших языковых моделей (LLM) в подготовке данных, несомненно, обнажают соблазнительную перспективу автоматизации рутинных операций. Однако, если решение представляется магией — значит, инвариант не раскрыт. Автоматизация ради автоматизации — занятие бесплодное. Настоящая ценность заключается в возможности доказать корректность преобразований, а не просто констатировать успешное прохождение тестов. Проблема остаётся прежней: как обеспечить надёжность и воспроизводимость результатов, когда «интеллект» модели зиждется на статистической вероятности, а не на логической дедукции?
Следующим этапом, очевидно, является переход от эмпирических наблюдений к формальной верификации. Необходимо разработать метрики, позволяющие объективно оценивать не только скорость и стоимость подготовки данных с использованием LLM, но и их устойчивость к шуму и искажениям. Более того, существенным ограничением является зависимость от качества и объема обучающих данных. Пока модель обучается на «грязных» данных, она лишь воспроизводит и увековечивает ошибки.
В конечном счёте, истинный прогресс потребует интеграции LLM с системами формальной логики и доказательства теорем. Автоматическое обнаружение и исправление ошибок в данных должно базироваться на чётких правилах и алгоритмах, а не на эвристических предположениях. Лишь в этом случае можно будет говорить о действительно интеллектуальной подготовке данных, способной превзойти традиционные методы и обеспечить надёжность анализа.
Оригинал статьи: https://arxiv.org/pdf/2601.17058.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Иллюзии понимания: Почему нейросети нас обманывают
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
2026-01-27 09:00