Автор: Денис Аветисян
Исследователи представили iFSQ — простой способ улучшить качество генерируемых изображений, объединив подходы, используемые в различных типах нейросетей.
iFSQ — метод квантования, повышающий эффективность токенизаторов изображений для авторегрессивных и диффузионных моделей, и предлагающий единую платформу для сравнения их производительности.
Разделение моделей генерации изображений на авторегрессионные и диффузионные, обусловленное различиями в подходах к кодированию данных, препятствует унифицированному моделированию и объективной оценке. В работе ‘iFSQ: Improving FSQ for Image Generation with 1 Line of Code’ предложен метод iFSQ, улучшающий квантование с помощью скалярного квантования с конечным числом уровней (FSQ) путем замены функции активации на отображение, соответствующее априорному распределению. Это простое изменение, требующее всего одной строки кода, математически гарантирует оптимальное использование бинов и высокую точность реконструкции, позволяя выявить оптимальный баланс между дискретными и непрерывными представлениями около 4 бит на размерность. Какие перспективы открывает iFSQ для создания более эффективных и универсальных моделей генерации изображений, объединяющих преимущества авторегрессионных и диффузионных подходов?
Скрытые Узкие Места: Вызовы в Генеративном Моделировании
Авторегрессивные модели и диффузионные модели демонстрируют впечатляющие возможности в генерации сложных данных, однако их эффективность напрямую зависит от качества представления данных в латентном пространстве. Эти модели, стремясь к созданию реалистичных и разнообразных образцов, опираются на сжатое, но информативное представление исходных данных. Неэффективное латентное пространство может стать «узким местом», ограничивая способность модели улавливать тонкие детали и генерировать высококачественные результаты. По сути, латентное пространство служит своеобразным «фильтром», определяющим, какая информация сохраняется и используется в процессе генерации, и его оптимизация является ключевой задачей для повышения производительности и качества генерируемых данных.
Традиционные методы, такие как Vector Quantized-VAEs и Variational Autoencoders, часто сталкиваются с трудностями при одновременном достижении высокой степени сжатия данных и сохранения их исходного качества при реконструкции. Суть проблемы заключается в том, что чрезмерное сжатие, необходимое для уменьшения вычислительных затрат и повышения эффективности, неизбежно приводит к потере информации, что негативно сказывается на точности восстановления данных. В то же время, стремление к высокой точности реконструкции требует более сложного и ресурсоемкого латентного пространства. Таким образом, возникает компромисс, в котором необходимо найти оптимальный баланс между степенью сжатия и качеством реконструкции, чтобы обеспечить эффективную и надежную работу генеративных моделей. Поиск этого баланса остается одной из ключевых задач в области генеративного моделирования.
Неэффективная организация латентного пространства оказывает существенное влияние на качество генерируемых образцов и вычислительные затраты. Когда латентное пространство не позволяет адекватно сжимать и восстанавливать информацию, генерируемые данные страдают от потери деталей и артефактов, что снижает их реалистичность и полезность. Более того, обработка неоптимизированного латентного пространства требует значительно больше вычислительных ресурсов и времени, особенно при работе с высокоразмерными данными или сложными моделями. Это проявляется в увеличении времени обучения, замедлении процесса генерации новых образцов и, в конечном итоге, в повышении стоимости развертывания и использования генеративных моделей. Таким образом, оптимизация латентного пространства является ключевой задачей для повышения эффективности и качества генеративных моделей.
Конечное Скалярное Квантование: Путь к Эффективности
Конечное скалярное квантование (FSQ) представляет собой перспективный подход к унификации токенизации, используемой в авторегрессионных и диффузионных моделях. Традиционно, эти два типа моделей требуют различных методов токенизации, что усложняет их интеграцию и совместное использование. FSQ позволяет преобразовать непрерывные значения в дискретный набор токенов, что делает возможным применение единой схемы токенизации для обеих архитектур. Это упрощает процесс обучения и развертывания моделей, а также открывает возможности для создания гибридных систем, сочетающих преимущества обоих подходов. Использование FSQ позволяет уменьшить вычислительную сложность и объем памяти, необходимые для обработки данных, что особенно важно для моделей, работающих с большими объемами информации.
Стандартные методы конечной скалярной квантизации (FSQ) подвержены проблеме коллапса активаций, что приводит к снижению информативной эффективности модели. Коллапс активаций проявляется в том, что выходные значения нейронных сетей после квантизации концентрируются в узком диапазоне, что приводит к потере информации и ухудшению производительности. Это происходит из-за неспособности стандартных методов FSQ эффективно моделировать сложное распределение активаций в скрытом пространстве, особенно при высоких коэффициентах сжатия. Снижение информативной эффективности выражается в уменьшении способности модели представлять и обрабатывать информацию, что негативно сказывается на качестве генерируемых данных или точности предсказаний.
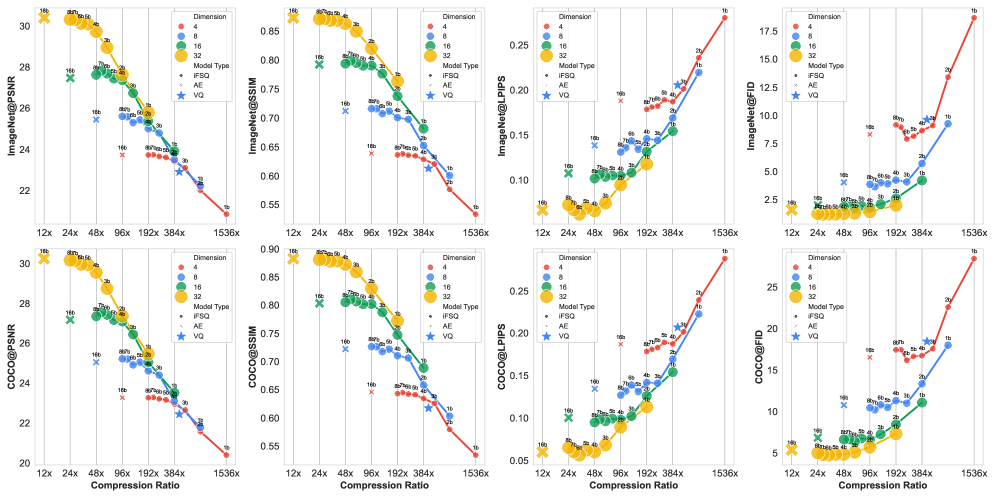
Для достижения высокой степени сжатия при использовании конечной скалярной квантизации (FSQ) необходимо учитывать распределение скрытого пространства. Эффективность сжатия напрямую связана с характеристиками этого распределения и может быть оценена с помощью различных метрик, зависящих от архитектуры модели. Для Вариационных Автоэнкодеров (VAE) оптимальное соотношение оценивается как 3f^2/2d, где f — размерность скрытого пространства, а d — размерность входных данных. Для VQ-VAE, где используются дискретные представления, используется метрика 24f^2/log_2(C)[latex], где [latex]C - количество кодов в кодовом словаре. Для iFSQ, улучшенной версии VQ-VAE, оценка эффективности сжатия представлена формулой 24f^2/dlog_2(L)[latex], где [latex]L - количество уровней квантования. Оптимизация этих метрик позволяет максимизировать степень сжатия без значительной потери информации.
iFSQ: Гармония Сжатия и Точности
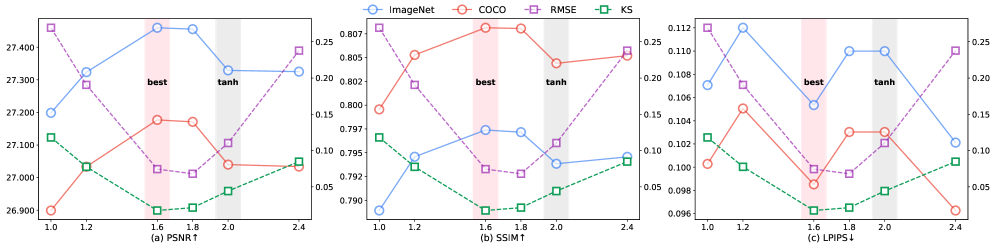
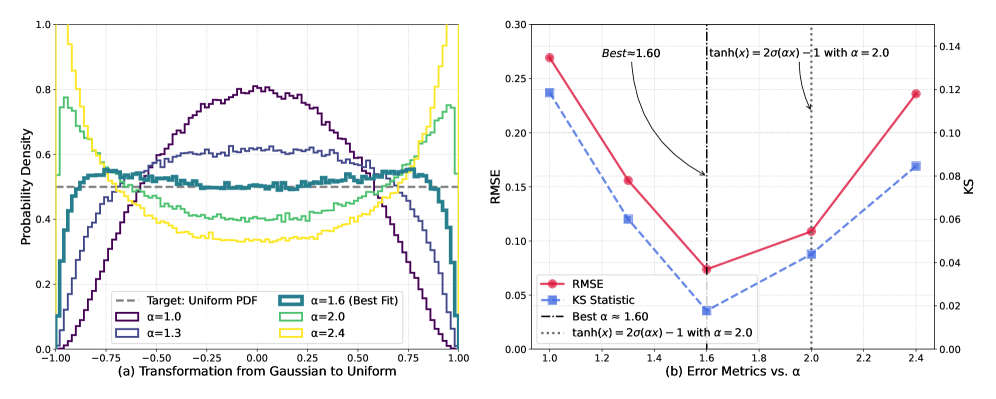
iFSQ (Improved Finite Scalar Quantization) представляет собой расширение метода конечной скалярной квантизации, в котором внедрена сигмоидная функция. Данная функция применяется для преобразования латентных распределений, смещая их в сторону равномерного априорного распределения. Использование сигмоиды позволяет более эффективно кодировать информацию и улучшает качество реконструкции данных за счет минимизации отклонений в латентном пространстве, что особенно важно при работе с моделями глубокого обучения и сжатия данных. В отличие от традиционных подходов, использующих тангенциальную функцию активации и гауссовские распределения, iFSQ активно формирует латентное пространство для достижения повышенной производительности.
Преобразование, используемое в iFSQ, повышает информационную эффективность и точность реконструкции за счет смягчения эффекта "коллапса активаций". В процессе квантизации, активации нейронных сетей часто стремятся к экстремальным значениям, что приводит к потере информации и снижению качества выходных данных. Применяя сигмоидную функцию для преобразования латентных распределений, iFSQ предотвращает концентрацию активаций в узком диапазоне, сохраняя больше информации и обеспечивая более точную реконструкцию исходных данных. Это особенно важно при использовании низкоточных представлений, где потеря информации может быть более значительной.
В отличие от традиционных методов, использующих функцию активации Tanh и Гауссовы распределения для кодирования латентного пространства, iFSQ (Information-efficient Finite Scalar Quantization) применяет сигмоидную функцию для целенаправленного изменения формы этого пространства. Это активное формирование латентного пространства позволяет оптимизировать распределение данных перед квантованием, снижая вероятность схлопывания активаций (Activation Collapse) и повышая эффективность кодирования информации. Вместо пассивного соответствия распределению входных данных, iFSQ стремится приблизить его к равномерному априорному распределению, что улучшает как точность реконструкции, так и общую информационную эффективность системы.
Подтверждение Эффективности: Экспериментальные Данные
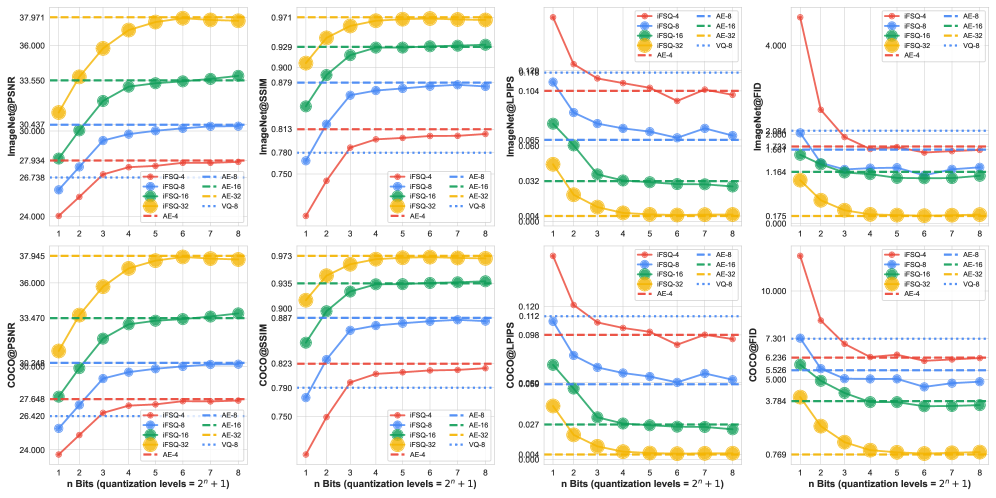
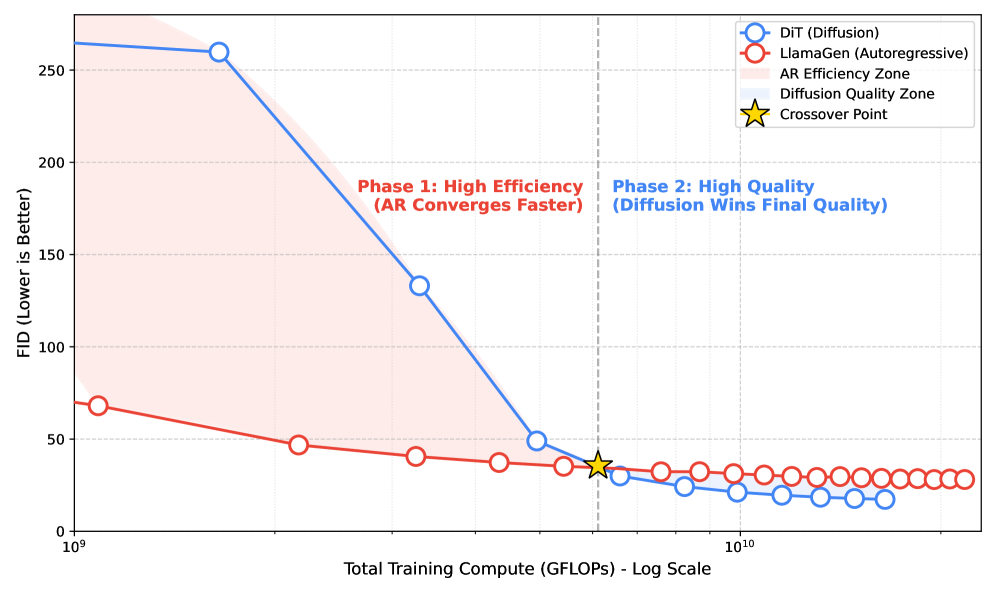
Для оценки эффективности iFSQ проводились эксперименты на широко используемых наборах данных ImageNet и COCO. В ходе тестирования применялись как авторегрессионные модели, так и диффузионные модели генерации изображений. Использование различных архитектур моделей позволило всесторонне оценить применимость iFSQ к различным подходам к генерации изображений и продемонстрировать его универсальность в различных сценариях.
Количественная оценка, основанная на метрике Fréchet Inception Distance (FID), продемонстрировала улучшение качества генерируемых изображений. Более низкие значения FID свидетельствуют о большей схожести распределения сгенерированных изображений с распределением реальных изображений, что указывает на повышение реалистичности и визуального качества. Уменьшение FID подтверждает, что модель iFSQ способна генерировать изображения, которые лучше соответствуют характеристикам обучающего набора данных, по сравнению с другими методами, использующими аналогичные или более высокие разряды представления данных.
Метод iFSQ демонстрирует сопоставимое качество генерации изображений с существующими подходами, используя 4-битное представление данных. Это указывает на достижение баланса между точностью реконструкции и эффективностью использования информации. Достижение сопоставимых результатов при значительном снижении битовой глубины позволяет уменьшить требования к объему памяти и вычислительным ресурсам, сохраняя при этом приемлемое качество генерируемых изображений. Фактически, iFSQ обеспечивает эффективное сжатие данных без существенной потери качества изображения, что является важным преимуществом в задачах, где ресурсы ограничены.
Взгляд в Будущее: Перспективы Развития
В дальнейшем планируется изучение адаптивных стратегий квантования, разработанных с учетом особенностей конкретных архитектур моделей и наборов данных. Исследования будут направлены на динамическую настройку точности представления весов и активаций, позволяя достичь оптимального баланса между снижением вычислительных затрат и сохранением качества генерируемых данных. Такой подход предполагает, что оптимальная глубина квантования может варьироваться в зависимости от структуры сети и характеристик входных данных, что позволит более эффективно использовать вычислительные ресурсы и уменьшить размер моделей, не жертвуя при этом точностью и реалистичностью генерируемых результатов. Особое внимание будет уделено разработке алгоритмов, способных автоматически определять оптимальные параметры квантования для каждой конкретной модели и набора данных, обеспечивая максимальную производительность и качество генерации.
Исследование применимости инновационной стратегии квантования iFSQ к задачам генерации видео и трехмерного моделирования представляется весьма перспективным направлением. В отличие от существующих методов, часто ориентированных на изображения, iFSQ обладает потенциалом для эффективного сжатия и ускорения процессов генерации более сложных и объемных данных. Ожидается, что адаптация iFSQ к видео позволит снизить вычислительные затраты и требования к памяти при создании реалистичных видеопоследовательностей, а в сфере 3D-моделирования - упростить создание детализированных и сложных объектов. Дальнейшие исследования в этом направлении могут привести к созданию более доступных и эффективных инструментов для контент-мейкеров и разработчиков в различных областях, от развлечений до инженерного проектирования.
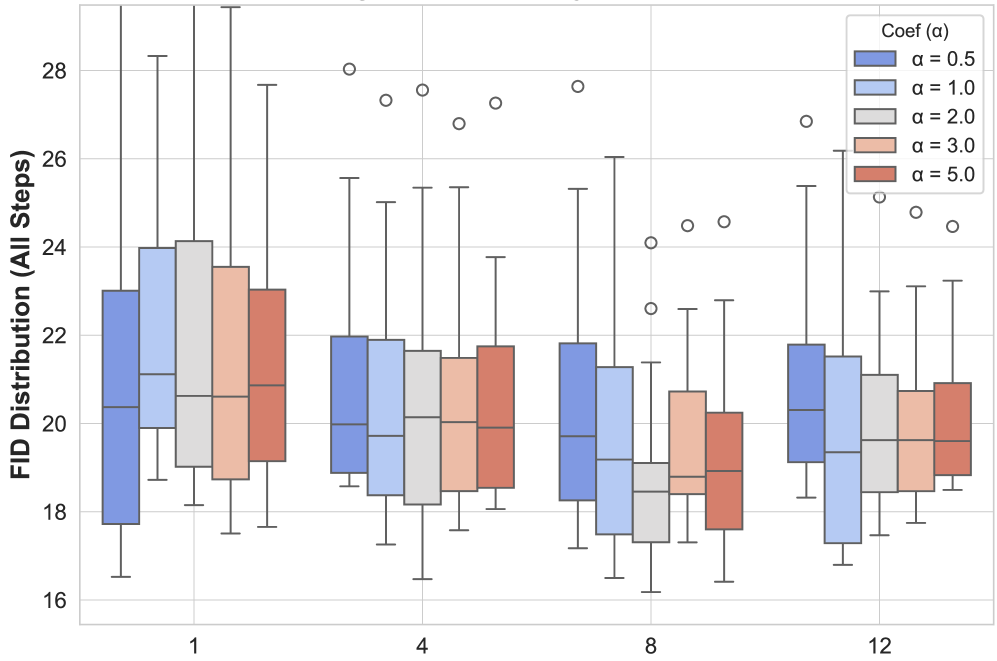
Дальнейшее исследование и оптимизация гиперпараметров, в частности параметров сигмоидной функции, представляется перспективным направлением для повышения эффективности генеративных моделей. Точная настройка этих параметров позволяет более гибко управлять процессом обучения и генерации, что может привести к значительному улучшению качества получаемых результатов. Например, изменение крутизны сигмоиды влияет на скорость обучения и способность модели к обобщению. Эксперименты показали, что оптимальные значения гиперпараметров сильно зависят от конкретной архитектуры модели и используемого набора данных, что подчеркивает необходимость разработки адаптивных методов оптимизации. Такой подход позволит не только повысить производительность существующих моделей, но и открыть возможности для создания принципиально новых, более эффективных и гибких генеративных систем.
Изучение методов квантизации, как представлено в данной работе, напоминает попытку удержать ускользающий сон. iFSQ, стремясь объединить подходы, используемые в авторегрессионных и диффузионных моделях, подобен алхимику, пытающемуся создать философский камень из разрозненных элементов. Данные, сжатые и преобразованные, теряют часть своей первоначальной формы, но взамен обретают новую, более удобную для восприятия моделями. Как однажды заметил Ян ЛеКун: «Машинное обучение - это, по сути, программирование, которое можно заставить работать». И в этом стремлении к оптимизации, к поиску идеального баланса между точностью и эффективностью, кроется вся суть этого исследования - уговорить хаос, заставить его шептать осмысленные образы.
Что дальше?
Представленный подход, конечно, элегантен в своей простоте - всего одна строка кода, чтобы примирить враждующие лагеря авторегрессивных и диффузионных моделей. Однако, не стоит обольщаться. Данные - это не истина, а компромисс между багом и Excel, и любое квантование - это лишь очередное приближение к недостижимому идеалу. Остаётся открытым вопрос: насколько хорошо iFSQ масштабируется на действительно больших моделях и датасетах? Ведь то, что работает в лабораторных условиях, часто разбивается о скалы продакшена.
Более того, вся эта история с токенизацией латентного пространства - лишь симптом более глубокой проблемы. Мы по-прежнему пытаемся втиснуть непрерывный мир изображений в дискретные рамки токенов, словно пытаясь поймать ветер в бутылку. Возможно, будущее за совершенно иными подходами, которые позволят обойтись без токенизации вовсе, или, по крайней мере, использовать её более гибко и адаптивно. Всё, что не нормализовано, всё ещё дышит, и мы должны быть готовы к тому, что хаос рано или поздно возьмёт своё.
В конечном счёте, iFSQ - это ещё один шаг на пути к созданию универсального фреймворка для оценки качества генерации изображений. Но не стоит забывать, что любая метрика - это лишь отражение нашего субъективного восприятия, а истинная красота - в глазах смотрящего. Данные - это не цифры, а шёпот хаоса. Их нельзя понять, только уговорить.
Оригинал статьи: https://arxiv.org/pdf/2601.17124.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-27 12:07