Автор: Денис Аветисян
Новый подход к систематическим обзорам позволяет исследователям активно верифицировать утверждения и контролировать процесс анализа, а не полагаться на автоматическую генерацию данных.
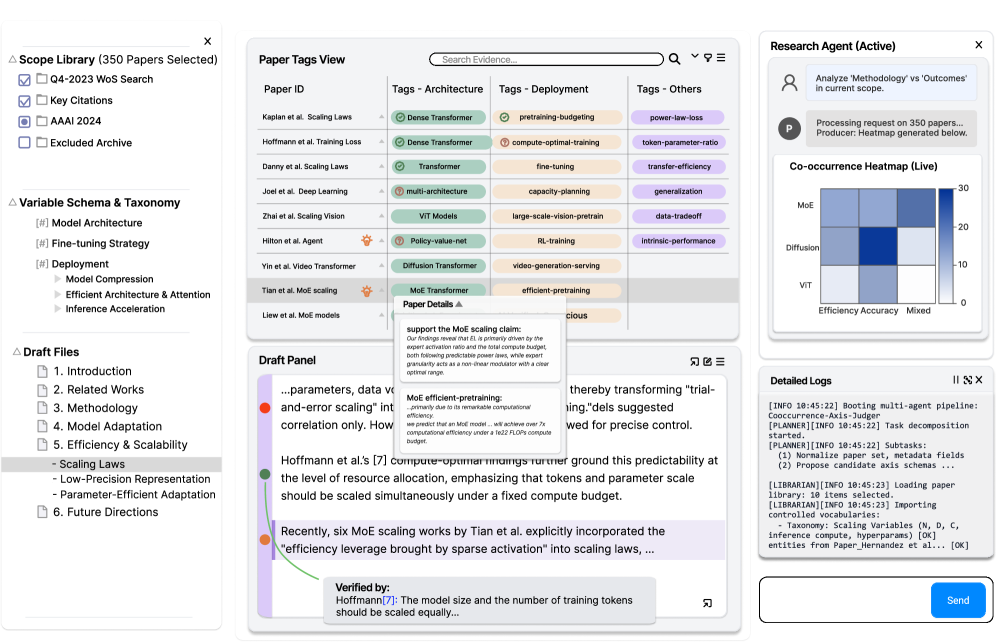
В статье представлена Research IDE — среда разработки для научных исследований, использующая принципы отладки кода для повышения rigor и интеллектуальной целостности мета-анализа.
Несмотря на растущую автоматизацию, строгий анализ обширной научной литературы для мета-анализа и систематических обзоров требует глубокого логического мышления. В статье ‘Probing the Future of Meta-Analysis: Eliciting Design Principles via an Agentic Research IDE’ представлена среда Research IDE, реализующая концепцию «исследования как отладки кода» с использованием многоагентной системы. Разработанный инструмент позволяет исследователям активно проверять утверждения непосредственно в процессе написания, сохраняя интеллектуальную собственность и контроль над процессом. Может ли подобный подход, сочетающий возможности ИИ и экспертные знания, существенно повысить эффективность и надежность научных исследований будущего?
Преодолевая границы: От литературы к осмыслению
Традиционные систематические обзоры литературы, несмотря на свою важность, зачастую требуют колоссальных временных затрат и подвержены влиянию субъективных факторов, связанных с интерпретацией исследователем первичных данных. Этот процесс, включающий ручной поиск, отбор и анализ сотен, а порой и тысяч публикаций, неизбежно сопряжен с риском упущения релевантной информации или предвзятого выбора исследований, соответствующих определенной точке зрения. В результате, синтез знаний может оказаться неполным или искаженным, ограничивая возможность формирования объективных и всесторонних выводов, необходимых для принятия обоснованных решений в различных областях науки и практики. Именно поэтому актуальны разработки автоматизированных подходов к анализу научной литературы, способных минимизировать человеческий фактор и обеспечить более надежную и эффективную обработку больших объемов данных.
Современный научный ландшафт характеризуется экспоненциальным ростом объема публикуемых исследований, что создает значительные трудности для выявления действительно релевантной информации. Попытки вручную проанализировать тысячи статей для формирования надежных выводов становятся не только чрезвычайно трудоемкими, но и подвержены субъективным ошибкам. Этот информационный перегруз препятствует возможности исследователей комплексно оценить существующие знания, выявить пробелы в исследованиях и, как следствие, замедляет прогресс в различных областях науки. В результате, даже при наличии большого количества данных, формирование обоснованных и надежных заключений часто оказывается затруднительным, требуя разработки новых методов и инструментов для эффективной обработки и анализа научной литературы.
Современные методы анализа научной литературы зачастую ограничиваются поверхностным изучением, не позволяя выявить сложные взаимосвязи и тонкие нюансы в исследуемой области. Вместо глубокого понимания механизмов, лежащих в основе наблюдаемых явлений, преобладают обобщения, основанные на прямых корреляциях. Такой подход препятствует открытию скрытых закономерностей и ограничивает возможности для формирования действительно новых гипотез. Исследования, фокусирующиеся лишь на наиболее очевидных результатах, рискуют упустить из виду критически важные факторы, влияющие на изучаемые процессы, и тем самым создают неполную и, возможно, искаженную картину реальности. Для преодоления этих ограничений требуется разработка более сложных аналитических инструментов, способных учитывать контекст, неоднозначность и многомерность научных данных.
Research IDE: Исследование как код
Концепция «Исследования как кода» в Research IDE предполагает рассмотрение проверки гипотез как итеративного процесса отладки, аналогичного разработке программного обеспечения. В этом подходе, исследовательские вопросы формулируются как утверждения, а сбор и анализ данных рассматриваются как шаги, необходимые для подтверждения или опровержения этих утверждений. Подобно отладке кода, исследователь может последовательно тестировать отдельные компоненты гипотезы, выявлять несоответствия между ожидаемыми и фактическими результатами, и вносить коррективы в исходные предположения. Итеративный характер этого процесса позволяет более эффективно исследовать сложные проблемы и избегать когнитивных искажений, свойственных традиционным методам исследования.
В основе Research IDE лежит многоагентная серверная архитектура, предназначенная для автоматизации процессов рассуждений и синтеза доказательств. Данная архитектура позволяет развертывать и координировать взаимодействие между различными агентами, каждый из которых отвечает за определенную задачу, например, поиск релевантной литературы, извлечение ключевой информации или проверку логической связности аргументов. Взаимодействие между агентами осуществляется посредством стандартизированных протоколов обмена данными, что обеспечивает масштабируемость и гибкость системы. Автоматизация этих процессов позволяет исследователям сосредоточиться на интерпретации результатов и формировании новых гипотез, а не на рутинном сборе и анализе данных.
Интерактивные точки останова гипотез позволяют исследователям приостанавливать процесс и непосредственно верифицировать утверждения, сопоставляя их с подтверждающей литературой. В ходе недельного лонгитюдного исследования с участием восьми испытуемых было зафиксировано 105 таких точек останова. Данный функционал обеспечивает возможность детального анализа и проверки каждого этапа исследования, позволяя исследователям оперативно подтверждать или опровергать выдвинутые предположения на основе доступных научных данных.
В основе разработки IDE лежит принцип сохранения интеллектуальной собственности исследователя, что выражается в поддержании его когнитивного контроля на протяжении всего процесса. Система не заменяет аналитическое мышление исследователя, а предоставляет инструменты для структурирования и верификации гипотез, позволяя ему оставаться активным участником исследования и принимать осознанные решения на каждом этапе. В отличие от полностью автоматизированных систем, IDE предоставляет полный контроль над процессом анализа, обеспечивая возможность критической оценки полученных результатов и корректировки исследовательских стратегий по мере необходимости. Такой подход позволяет избежать «черного ящика» и гарантирует, что все выводы основаны на обоснованных аргументах и подтверждаются соответствующими доказательствами, выбранными и интерпретированными самим исследователем.
Автоматизированное рассуждение: Сила специализированных агентов
Агент планирования выполняет декомпозицию запросов пользователя, представляющих собой утверждения, на ряд проверяемых подвопросов. Этот процесс значительно упрощает и ускоряет исследовательский цикл, позволяя системе фокусироваться на конкретных аспектах проблемы. Вместо обработки сложного первоначального запроса, система разбивает его на более мелкие, отдельные задачи, что повышает эффективность поиска релевантной информации и снижает когнитивную нагрузку на исследователя. В ходе развертывания системы, агент планирования использовался для обработки запросов, основанных на анализе 548 научных публикаций.
Агент-библиотекарь использует технологию Retrieval-Augmented Generation (RAG) для эффективного поиска релевантных доказательств. RAG предполагает извлечение информации из внешних источников знаний на основе запроса пользователя, а затем использование этой информации для генерации ответа. Этот подход позволяет системе не только находить факты, но и синтезировать их в более понятную форму, избегая ограничений, присущих традиционным методам поиска. В процессе работы с 548 статьями, система, использующая RAG, позволила исследователям значительно ускорить процесс поиска и анализа данных.
Агент Рассуждений выполняет кросс-документальный анализ, выявляя согласованность или разногласия между несколькими источниками информации. Этот процесс предполагает сопоставление утверждений, представленных в различных документах, для определения степени их взаимоподдержки или противоречия. Агент не просто извлекает информацию, но и оценивает её надежность и достоверность, учитывая, насколько часто определенное утверждение подтверждается в разных источниках. В ходе развертывания системы, этот агент использовался для анализа 548 научных работ, что позволило выявить общие тенденции и спорные моменты в исследуемой области.
Агент-синтезатор (Producer Agent) осуществляет обобщение полученных данных и визуализацию доказательств, представляя результаты в ясной и лаконичной форме. В процессе практического применения системы исследователи использовали ее для категоризации 548 научных статей, что демонстрирует ее эффективность в обработке и структурировании больших объемов информации. Данный этап позволяет преобразовывать результаты анализа в удобный для восприятия формат, облегчая интерпретацию и использование полученных знаний.
Расширение возможностей синтеза знаний и автоматизации
Построение таксономии играет ключевую роль в поддержке многоагентной системы, обеспечивая структурированный каркас для организации научной литературы. Этот процесс подразумевает не просто категоризацию, но и иерархическое упорядочение источников по темам, понятиям и взаимосвязям, что позволяет системе эффективно извлекать, анализировать и сопоставлять информацию. Такая организация позволяет автоматизировать поиск релевантных исследований, выявлять пробелы в знаниях и синтезировать новые идеи, значительно ускоряя процесс научных открытий. Фактически, таксономия служит своеобразным «картотечным шкафом» для огромного массива научных данных, делая его доступным и понятным для автоматизированной обработки.
Функциональная автоматизация значительно упрощает исследовательский процесс, беря на себя рутинные задачи, такие как форматирование текста и создание ссылок между источниками. Это не просто экономия времени, но и снижение вероятности ошибок, которые часто возникают при выполнении монотонной работы вручную. Автоматизированные инструменты позволяют исследователям сосредоточиться на анализе данных и формировании выводов, а не на технических деталях оформления. В результате повышается общая эффективность исследований, и ускоряется процесс публикации научных результатов. Такой подход особенно ценен при работе с большими объемами информации, где даже небольшая автоматизация может привести к существенному приросту производительности.
Эпистемическая автоматизация представляет собой следующий этап в развитии автоматизации научных исследований, выходящий за рамки простой обработки и организации информации. Она заключается в создании систем, способных самостоятельно проводить логические умозаключения на основе существующих знаний и генерировать новые гипотезы или выводы. Вместо простого поиска релевантных статей, подобные системы анализируют взаимосвязи между различными научными концепциями, выявляют закономерности и предлагают новые направления для исследований. Этот подход позволяет значительно ускорить процесс научного открытия, поскольку автоматизирует трудоемкие задачи, связанные с анализом больших объемов данных и построением логических цепочек. Реализация эпистемической автоматизации требует разработки сложных алгоритмов и моделей, способных имитировать процессы человеческого мышления, но потенциальные выгоды для науки огромны.
Интегрированный подход, сочетающий в себе автоматизацию синтеза знаний и методологию «Исследование через проектирование», значительно расширяет возможности исследователей в изучении сложных тем. Участники исследований продемонстрировали готовность полагаться на автоматизированные инструменты при достижении порога точности в 70-80%, что позволяет оперативно проверять гипотезы и проводить итеративные улучшения. Такая комбинация обеспечивает не только ускорение исследовательского процесса, но и повышение его строгости, позволяя ученым более эффективно анализировать большие объемы информации и выявлять новые закономерности. Возможность быстрой проверки результатов, обеспечиваемая приемлемым уровнем точности, является ключевым фактором, способствующим динамичному развитию исследований и более глубокому пониманию сложных явлений.
Исследование, представленное в статье, рассматривает процесс мета-анализа через призму отладки кода, что наводит на мысль о неизбежном течении времени и необходимости постоянного рефакторинга. Как заметила Ада Лавлейс: «Я считаю, что машиной можно управлять так, чтобы она выполняла любые операции». В данном контексте, ‘машина’ — это не только вычислительное устройство, но и сам исследовательский процесс. Research IDE, предлагаемый авторами, позволяет исследователю активно верифицировать утверждения, подобно отладке кода, и таким образом, поддерживать интеллектуальное владение процессом. Версионирование, как форма памяти, позволяет отслеживать эволюцию исследования, а стрела времени всегда указывает на необходимость рефакторинга — пересмотра и улучшения исходных предположений и методов, чтобы обеспечить надежность и точность результатов.
Что дальше?
Представленная работа, по сути, лишь зафиксировала неизбежное — старение методов мета-анализа. Иллюзия всеохватывающей объективности, порожденная автоматизацией, рассеивается, обнажая фундаментальную истину: любая система, стремящаяся к синтезу знаний, обречена на столкновение с несовершенством исходных данных и предвзятостью интерпретаций. Research IDE, в этом контексте, не панацея, а инструмент замедления энтропии, способ поддержания интеллектуальной честности в эпоху алгоритмической перегрузки.
Очевидным ограничением остается зависимость от качества исходных утверждений и четкости формулировок. Каждый сбой — это сигнал времени, напоминание о том, что даже самые изящные алгоритмы бессильны перед неясностью человеческой мысли. Будущие исследования должны быть направлены на разработку методов формализации неформальных знаний, на создание «мостиков» между интуицией и логикой, а не на попытки заменить одно другим.
Рефакторинг — это диалог с прошлым, переосмысление накопленного опыта. Следующим шагом видится разработка систем, способных не просто выявлять противоречия, но и предлагать альтернативные интерпретации, основанные на принципах абдуктивного рассуждения. И, возможно, самое важное — признание того, что поиск истины — это бесконечный процесс, а не достижимая цель. Именно в этой постоянной ревизии и заключается достоинство любой системы.
Оригинал статьи: https://arxiv.org/pdf/2601.18239.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-27 12:11